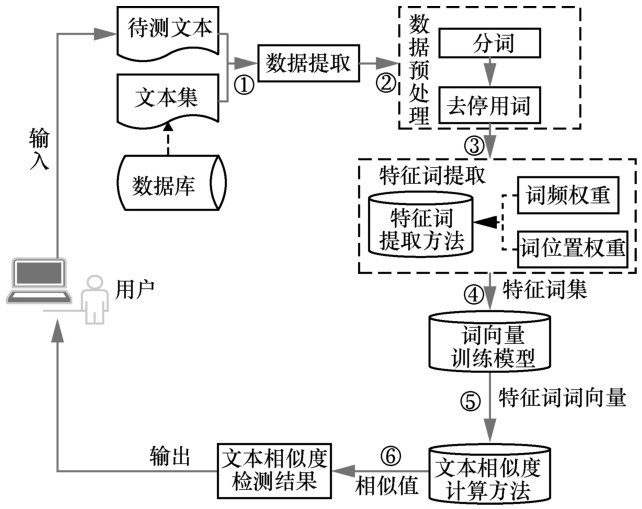
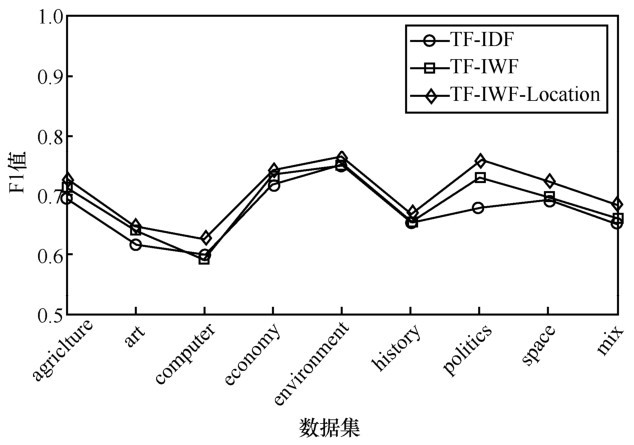
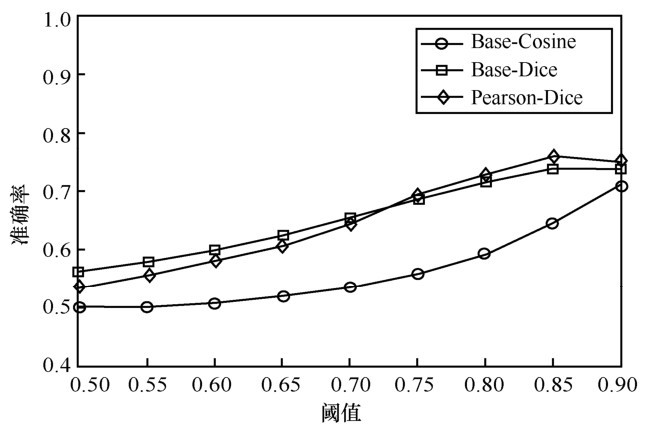
| [1] |
YANG Z X , CHEN Z F , ZHANG P ,et al. An information intelligent search method for computer forensics based on text similarity[C]// Proceedings of Proceedings of the 2020 4th International Conference on Cryptography,Security and Privacy. New York:ACM Press, 2020: 79-83.
|
| [2] |
ALMEIDA C , SANTOS D . Text similarity using word embeddings to classify misinformation[J]. arXiv Preprint,arXiv:2003.06634, 2020: 63-68.
|
| [3] |
SEKI K . Cross-lingual text similarity exploiting neural machine translation models[J]. Journal of Information Science, 2021,47(3): 404-418.
|
| [4] |
LIANG H Z , LIN K B , ZHU S Z . Short text similarity hybrid algorithm for a Chinese medical intelligent question answering system[C]// Technology-Inspired Smart Learning for Future Education. Singapore:Springer, 2020: 129-142.
|
| [5] |
PRAKOSO D W , ABDI A , AMRIT C . Short text similarity measurement methods:a review[J]. Soft Computing, 2021,25(6): 4699-4723.
|
| [6] |
IRVING R W , FRASER C B . Two algorithms for the longest common subsequence of three (or more) strings[C]// Combinatorial Pattern Matching. Berlin:Springer, 1992: 214-229.
|
| [7] |
DAMERAU F J . A technique for computer detection and correction of spelling errors[J]. Communications of the ACM, 1964,7(3): 171-176.
|
| [8] |
JACCARD P . The distribution of the flora in the alpine zone.1[J]. New Phytologist, 1912,11(2): 37-50.
|
| [9] |
DICE L . Measures of the amount of ecologic association between species[J]. Ecology, 1945,26(3): 297-302.
|
| [10] |
DEZA M M , DEZA E . Encyclopedia of distances[M]. Berlin: Springer, 2009.
|
| [11] |
CHANDRASEKARAN D , MAGO V . Evolution of semantic similarity—A survey[J]. ACM Computing Surveys, 2021,54(2): 1-37.
|
| [12] |
陈二静, 姜恩波 . 文本相似度计算方法研究综述[J]. 数据分析与知识发现, 2017,1(6): 1-11.
|
|
CHEN E J , JIANG E B . Review of studies on text similarity measures[J]. Data Analysis and Knowledge Discovery, 2017,1(6): 1-11.
|
| [13] |
黄文彬, 车尚锟 . 计算文本相似度的方法体系与应用分析[J]. 情报理论与实践, 2019,42(11): 128-134.
|
|
HUANG W B , CHE S K . Methodological system and application scenarios on text similarity calculation[J]. Information Studies:Theory &Application, 2019,42(11): 128-134.
|
| [14] |
LUHN H P . A statistical approach to mechanized encoding and searching of literary information[J]. IBM Journal of Research and Development, 1957,1(4): 309-317.
|
| [15] |
BLEI D M , NG A Y , JORDAN M I . Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2001,3: 601-608.
|
| [16] |
MIHALCEA R , TARAU P . Textrank:bringing order into text[C]// Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing.[S.n.:s.l.], 2004: 404-411.
|
| [17] |
王小林, 杨林, 王东 ,等. 改进的TF-IDF关键词提取方法[J]. 计算机科学与应用, 2013,3(1): 64-68.
|
|
WANG X L , YANG L , WANG D ,et al. Improved TF-IDF keyword extraction algorithm[J]. Computer Science and Application, 2013,3(1): 64-68.
|
| [18] |
KIM S W , GIL J M . Research paper classification systems based on TF-IDF and LDA schemes[J]. Human-Centric Computing and Information Sciences, 2019,9(1): 30.
|
| [19] |
CHEN W , YU Z T , XIAN Y T ,et al. Mining keywords from short text based on LDA-based hierarchical semantic graph model[J]. International Journal of Information Systems in the Service Sector, 2020,12(2): 76-87.
|
| [20] |
PUSPANINGRUM E Y , NUGROHO B , SETIAWAN A ,et al. Detection of text similarity for indication plagiarism using winnowing algorithm based K-gram and jaccard coefficient[J]. Journal of Physics:Conference Series,, 20201569: 022044.
|
| [21] |
郭庆琳, 李艳梅, 唐琦 . 基于VSM的文本相似度计算的研究[J]. 计算机应用研究, 2008,25(11): 3256-3258.
|
|
GUO Q L , LI Y M , TANG Q . Similarity computing of documents based on VSM[J]. Application Research of Computers, 2008,25(11): 3256-3258.
|
| [22] |
BAO X A , DAI S C , ZHANG N ,et al. Large-scale text similarity computing with spark[J]. International Journal of Grid and Distributed Computing, 2016,9(4): 95-100.
|
| [23] |
LIU Y , LI D M , DAI C . Short text similarity measure based on double vector space model[J]. International Journal of Database Theory and Application, 2016,9(10): 33-46.
|
| [24] |
WANG J Y , XU W H , YAN W H ,et al. Text similarity calculation method based on hybrid model of LDA and TF-IDF[C]// Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence.[S.n.:s.l.], 2019: 1-8.
|
| [25] |
LIU Y Q , LI Z J . Semantic based text similarity computation[C]// Lecture Notes in Electrical Engineering. Singapore:Springer, 2017: 343-348.
|
| [26] |
WANG X L , DONG X T , CHEN S X . Text duplicated-checking algorithm implementation based on natural language semantic analysis[C]// Proceedings of 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC). Piscataway:IEEE Press, 2020: 732-735.
|
| [27] |
王春柳, 杨永辉, 邓霏 ,等. 文本相似度计算方法研究综述[J]. 情报科学, 2019,37(3): 158-168.
|
|
WANG C L , YANG Y H , DENG F ,et al. A review of text similarity approaches[J]. Information Science, 2019,37(3): 158-168.
|
| [28] |
WANG J P , DONG Y H . Measurement of text similarity:a survey[J]. Information, 2020,11(9): 421.
|
| [29] |
SHAHMIRZADI O , LUGOWSKI A , YOUNGE K . Text similarity in vector space models:a comparative study[C]// Proceedings of 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA). Piscataway:IEEE Press, 2019: 659-666.
|
| [30] |
李琳, 李辉 . 一种基于概念向量空间的文本相似度计算方法[J]. 数据分析与知识发现, 2018,2(5): 48-58.
|
|
LI L , LI H . Computing text similarity based on concept vector space[J]. Data Analysis and Knowledge Discovery, 2018,2(5): 48-58.
|
| [31] |
陈福, 林闯, 薛超 ,等. 短句语义向量计算方法[J]. 通信学报, 2016,37(2): 11-19.
|
|
CHEN F , LIN C , XUE C ,et al. Vector semantic computing method study for short sentence[J]. Journal on Communications, 2016,37(2): 11-19.
|
| [32] |
MIKOLOV T , CHEN K , CORRADO G ,et al. Efficient estimation of word representations in vector space[J]. arXiv Preprint,arXiv:1301.3781, 2013.
|
| [33] |
张宇, 刘雨东, 计钊 . 向量相似度测度方法[J]. 声学技术, 2009,28(4): 532-536.
|
|
ZHANG Y , LIU Y D , JI Z . Vector similarity measurement method[J]. Technical Acoustics, 2009,28(4): 532-536.
|
| [34] |
邹学强, 包秀国, 黄晓军 ,等. 基于层次分析的微博短文本特征计算方法[J]. 通信学报, 2016,37(12): 50-55.
|
|
ZOU X Q , BAO X G , HUANG X J ,et al. Calculating the feature method of short text based on analytic hierarchy process[J]. Journal on Communications, 2016,37(12): 50-55.
|
| [35] |
许树柏 . 实用决策方法:层次分析法原理[M]. 天津: 天津大学出版社, 1988.
|
|
XU S B . Practical decision-making method:the principle of analytic hierarchy process[M]. Tianjin: Tianjin University Press, 1988.
|
| [36] |
ZHELEZNIAK V , SAVKOV A , SHEN A ,et al. Correlation coefficients and semantic textual similarity[J]. arXiv Preprint,arXiv:1905.07790, 2019.
|
| [37] |
WESTON J , CHOPRA S , ADAMS K . #TagSpace:semantic embeddings from hashtags[C]// Proceedings of Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).[S.n.:s.l.], 2014: 1822-1827.
|