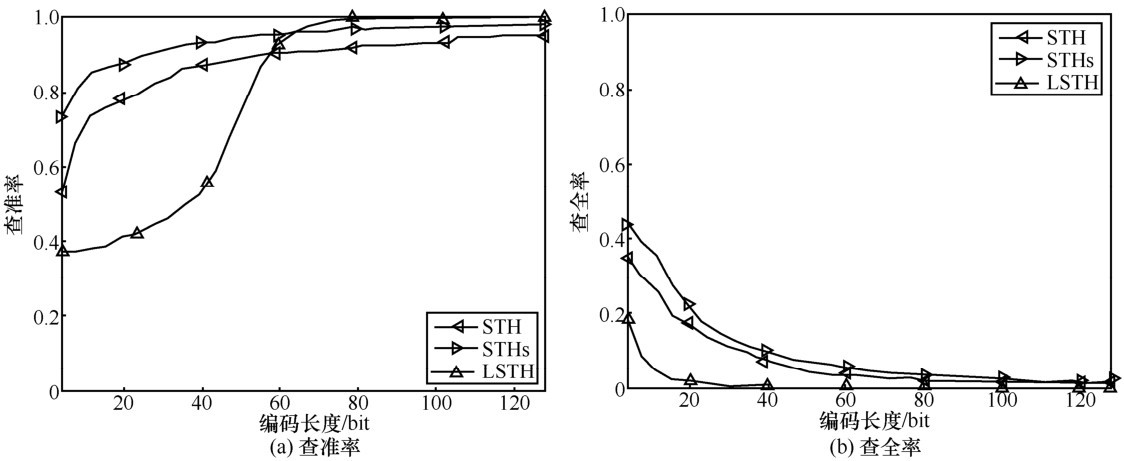
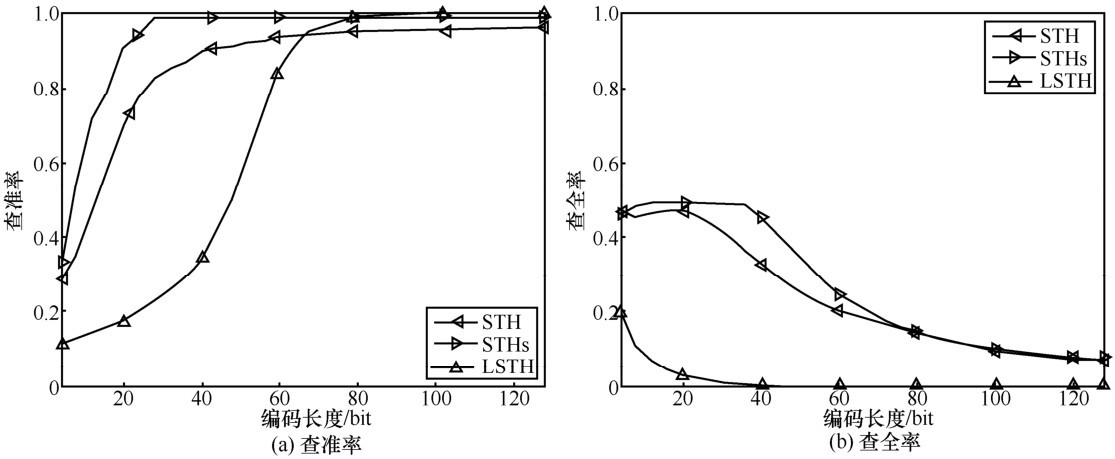
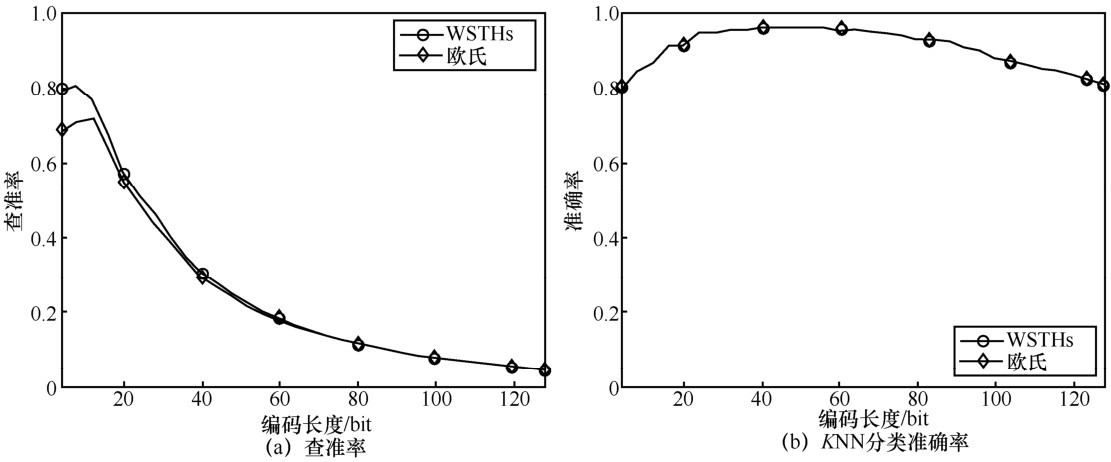
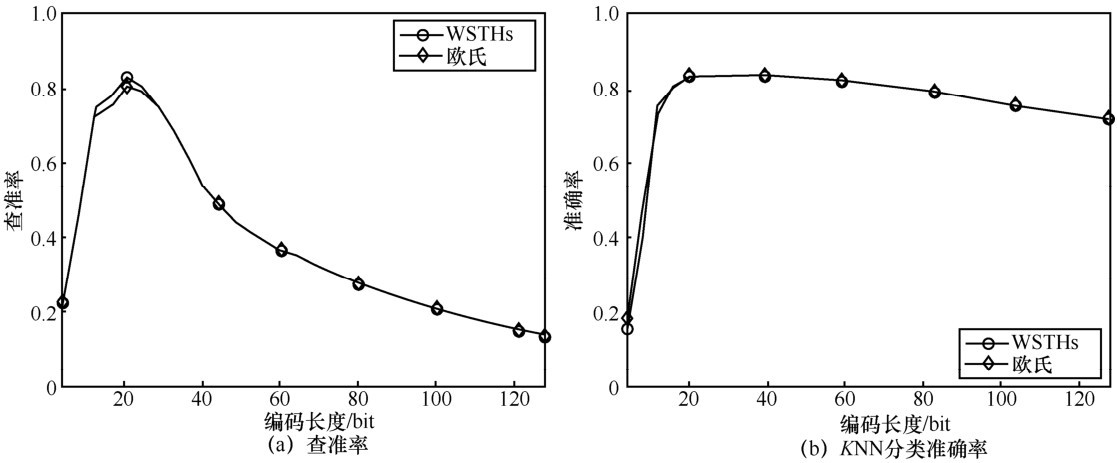
| [1] |
HE J , LIU W , CHANG S F . Scalable similarity search with optimized kernel hashing[C]// The 16th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD),July 25-28,2010,Washington,DC,USA. New York:ACM Press, 2010: 1129-1138.
|
| [2] |
吴军 . 大数据和机器智能对未来社会的影响[J]. 电信科学, 2015,31(2): 7-16.
|
|
WU J . Big data,machine intelligence and their impacts to the future World[J]. Telecommunications Science, 2015,31(2): 7-16.
|
| [3] |
ZHANG D , WANG F , SI L . Composite hashing with multiple information sources[C]// The International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR 2011,July 24-28,2011,Beijing,China. New York:ACM Press, 2011: 225-234.
|
| [4] |
尤海浪, 钱锋, 黄祥为 ,等. 基于大数据挖掘构建游戏平台个性化推荐系统的研究与实践[J]. 电信科学, 2014,30(10): 27-32.
|
|
YOU H L , QIAN F , HUANG X W ,et al. Research and practice of building a personalized recommendation system for mobile game platform based on big data mining[J]. Telecommunica-tions Science, 2014,30(10): 27-32.
|
| [5] |
徐雅斌, 刘超, 武装 ,等. 基于用户兴趣和推荐信任域的微博推荐[J]. 电信科学, 2015,31(1): 13-20.
|
|
XU Y B , LIU C , WU Z ,et al. Micro-blog recommendation based on user interests and recommendation trust domain[J]. Telecommunications Science, 2015,31(1): 13-20.
|
| [6] |
KONG W , LI W J . Isotropic hashing[J]. Advances in Neural Information Processing Systems, 2012(2): 1646-1654.
|
| [7] |
GONG Y , LAZEBNIK S , GORDO A ,et al. Iterative quantization:a procrustean approach to learning binary codes for large-scale image retrieval[J]. IEEE Transactions on Pattern Analysis Machine Intelligence, 2013(35): 2916-2929.
|
| [8] |
JIANG Q Y , LI W J . Scalable graph hashing with feature transformation[C]// International Conference on Artificial Intelligence,July 25-31,2015,Buenos Aires,Argentina. New York:ACM Press, 2015: 2248-2254.
|
| [9] |
WANG J , KUMAR S , CHANG S F . Semi-supervised hashing for large-scale search[J]. IEEE Transactions on Pattern Analysis Machine Intelligence, 2012,34(12): 2393-2406.
|
| [10] |
NOROUZI M E , FLEET D J . Minimal loss hashing for compact binary codes[C]// International Conference on Machine Learning,June 28-July 1,2011,Bellevue,Washington,USA.[S.l.:s.n]. 2011: 353-360.
|
| [11] |
LIU W , WANG J , JI R ,et al. Supervised hashing with kernels[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),June 16-21,2012,Kingston,USA. New Jersey:IEEE Press, 2012: 2074-2081.
|
| [12] |
LI W J , WANG S , KANG W C . Feature learning based deep supervised hashing with pairwise labels[J]. arXiv preprint arXiv:1511.03855, 2015.
|
| [13] |
KANG W C , LI W J , ZHOU Z H . Column sampling based discrete supervised hashing[C]// AAAI,February 12-17,2016,Phoenix,Arizona,USA.[S.l.:s.n]. 2016: 1230-1236.
|
| [14] |
BENTLEY J L , . K-d trees for semi dynamic point sets[C]// Symposium on Computational Geometry,June 7-9,1990,Berkley,California,USA. New York:ACM Press, 1990: 187-197.
|
| [15] |
AHMED M , MAHAR K , ABDELKADER H ,et al. Combining R-Tree and B-Tree to enhance spatial queries[C]// International Conference on Computer Theory and Applications,Oct 8-11,2013,Alexandria,Egypt.[S.l.:s.n]. 2013.
|
| [16] |
SHRIVASTAVA A , LI P . Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS)[J]. Advances in Neural Information Processing Systems, 2014(3): 2321-2329.
|
| [17] |
ANDONI A , INDYK P , LAARHOVEN T ,et al. Practical and optimal LSH for angular distance[J].Computer Science,2015. Computer Science, 2015.
|
| [18] |
QIAN J , ZHU Q , CHEN H . Multi-granularity locality-sensitive bloom filter[J]. IEEE Transactions on Computers, 2015,64(12): 3500-3514.
|
| [19] |
HUANG Q , FENG J , ZHANG Y ,et al. Query-aware locality-sensitive hashing for approximate nearest neighbor search[J]. Proceedings of the VLDB Endowment, 2015,9(1): 1-12.
|
| [20] |
LIU Y , CUI J , HUANG Z ,et al. SK-LSH:an efficient index structure for approximate nearest neighbor search[J]. Proceedings of the VLDB Endowment, 2014,7(9): 745-756.
|
| [21] |
SHUM H Y , ZHANG L , ZHANG X . QsRank:query-sensitive hash code ranking for efficient ?-neighbor search[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),June 16-21,2012,Kingston,Rhode Island,USA. New York:ACM Press, 2012: 2058-2065.
|
| [22] |
ZHANG L , ZHANG Y , TANG J ,et al. Binary code ranking with weighted hamming distance[C]// 2013 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),June 23-28,2013,Portland,Oregon,USA. New York:ACM Press, 2013: 1586-1593.
|
| [23] |
ZHANG D , WANG J , CAI D ,et al. Self-taught hashing for fast similarity search[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval,July 19-23,2010,Geneva,Switzerland. New York:ACM Press, 2010: 18-25.
|
| [24] |
袁培森, 沙朝锋, 王晓玲 ,等. 一种基于学习的高维数据 c-近似最近邻查询算法[J]. 软件学报, 2012,23(8): 2018-2031.
|
|
YUAN P S , SHA Z F , WANG X L ,et al. A high dimensional data c-approximate nearest neighbor query algorithm based on learning[J]. Journal of Software, 2012,23(8): 2018-2031.
|
| [25] |
殷良鹰 . 非线性度量学习算法研究[D]. 北京:北京理工大学, 2016.
|
|
YIN L Y . Research of nonlinear metric learning algorithm[D]. Beijing:Beijing Institute of Technology, 2016.
|
| [26] |
姜丹 . 信息论与编码[M]. 北京: 中国科学技术大学出版社, 2004.
|
|
JIANG D . Information theory and coding[M]. Beijing: Univer-sity of Science & Technology China PressPress, 2004.
|
| [27] |
魏书堤, 姜小奇 . 一种利用信息熵确定属性权重的模糊单因素评价方法[J]. 计算机工程与科学, 2010,32(7): 93-94.
|
|
WEI S D , JIANG X Q . A fuzzy single factor evaluation method based on entropy to determine the weight of attributes[J]. Computer Engineering& Science, 2010,32(7): 93-94.
|
| [28] |
BELKIN M , NIYOGI P . Laplacian eigenmaps for dimensionality reduction and data representation[J]. Neural Computation, 2003,15(6): 1373-1396.
|
| [29] |
FAN R E , CHANG K W , HSIEH C J ,et al. Liblinear:a library for large linear classification[J]. Journal of Machine Learning Research, 2008,9(9): 1871-1874.
|
| [30] |
周志华 . 机器学习[M]. 北京: 清华大学出版社, 2016.
|
|
ZHOU Z H . Machine learning[M]. Beijing: Tsinghua University PressPress, 2016.
|

 ),陈华辉,董一鸿
),陈华辉,董一鸿