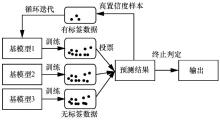
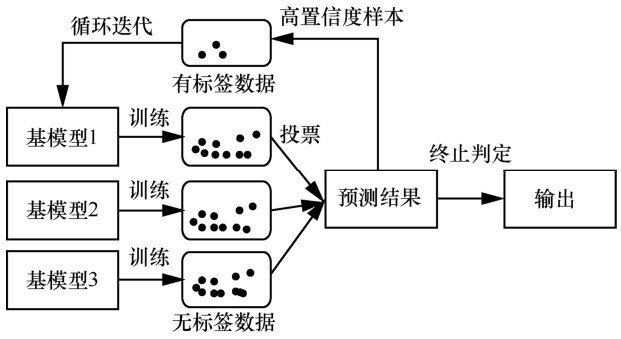
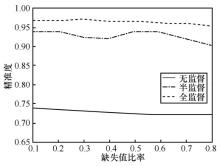
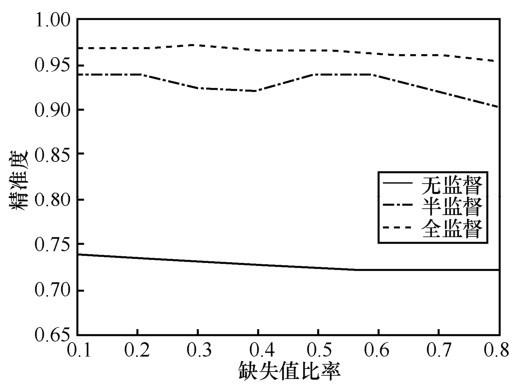
| [1] |
麻瓯勃, 刘雪娇, 唐旭栋 ,等. 基于半监督学习的恶意 URL检测方法[J]. 计算机系统应用, 2020,29(11): 11-20.
|
|
MA O B , LIU X J , TANG X D ,et al. Malicious URL detection based on semi-supervised learning[J]. Computer Systems &Applications, 2020,29(11): 11-20.
|
| [2] |
欧阳晔, 杨爱东, 孟凡语 . 一种博弈论辅助的机器学习算法检测用户流失行为[J]. 电信科学, 2020,36(6): 79-89.
|
|
OUYANG Y , YANG A D , MENG F Y . A game theory-assisted machine learning methodology for subscriber churn behaviors detection[J]. Telecommunications Science, 2020,36(6): 79-89.
|
| [3] |
张俊丽, 常艳丽, 师文 . 标签传播算法理论及其应用研究综述[J]. 计算机应用研究, 2013,30(1): 21-25.
|
|
ZHANG J L , CHANG Y L , SHI W . Overview on label propagation algorithm and applications[J]. Application Research of Computers, 2013,30(1): 21-25.
|
| [4] |
彭杰, 龚晓峰, 李剑 . LPA-SKFST 半监督特征提取方法[J]. 计算机应用研究, 2021,38(6): 1657-1661.
|
|
PENG J , GONG X F , LI J . Semi-supervised feature extraction method based on LPA-SKFST[J]. Application Research of Computers, 2021,38(6): 1657-1661.
|
| [5] |
周志华 . 基于分歧的半监督学习[J]. 自动化学报, 2013,39(11): 1871-1878.
|
|
ZHOU Z H . Disagreement-based Semi-supervised Learning[J]. Acta Automatica Sinica, 2013,39(11): 1871-1878.
|
| [6] |
ZHOU Z H , LI M . Tri-training:exploiting unlabeled data using three classifiers[J]. IEEE Transactions on Knowledge and Data Engineering, 2005,17(11): 1529-1541.
|
| [7] |
HUANG H J , QIAN L , WANG Y J . A SVM-based technique to detect phishing URLs[J]. Information Technology Journal, 2012,11(7): 921-925.
|
| [8] |
NIGAM K , GHANI R . Analyzing the effectiveness and applicability of co-training[C]// Proceedings of the ninth international conference on Information and knowledge management.[S.l.:s.n.], 2000: 86-93.
|
| [9] |
ZHOU Z H . Disagreement-based semi-supervised Learning[J]. Acta Automatica Sinica, 2013,39(11): 1871.
|
| [10] |
MCCLOSKY D , CHARNIAK E , JOHNSON M . Effective self-training for parsing[C]// Proceedings of the main conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics. Piscataway:IEEE Press, 2006.
|
| [11] |
ROSENBERG C , HEBERT M , SCHNEIDERMAN H . Semi-supervised self-training of object detection models[C]// Proceedings of 2005 Seventh IEEE Workshops on Applications of Computer Vision. Piscataway:IEEE Press, 2005: 29-36.
|
| [12] |
黎隽男 . 半监督自训练方法的研究[D]. 重庆:重庆师范大学, 2018.
|
|
LI J N . Research on semi-supervised self-training method[D]. Chongqing:Chongqing Normal University, 2018.
|
| [13] |
董立岩, 隋鹏, 孙鹏 ,等. 基于半监督学习的朴素贝叶斯分类新算法[J]. 吉林大学学报(工学版), 2016,46(3): 884-889.
|
|
DONG L Y , SUI P , SUN P ,et al. Novel naive Bayes classification algorithm based on semi-supervised learning[J]. Journal of Jilin University (Engineering and Technology Edition), 2016,46(3): 884-889.
|
| [14] |
陈颖, 杨欣, 孙道贺 . 基于 GA-XGBoost 模型的大学生科研能力预测问题研究[J]. 数学的实践与认识, 2021,51(6): 318-328.
|
|
CHEN Y , YANG X , SUN D H . Research on college students' scientific research ability prediction based on GA-XGBoost model[J]. Mathematics in Practice and Theory, 2021,51(6): 318-328.
|