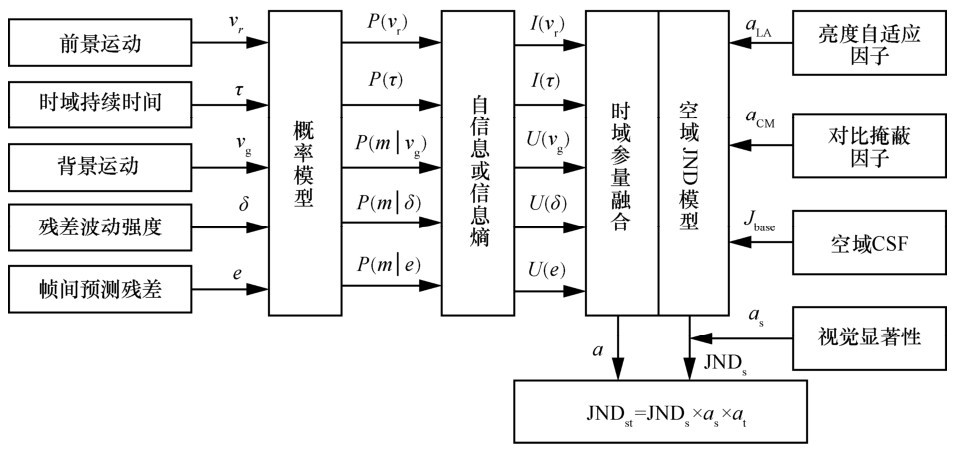
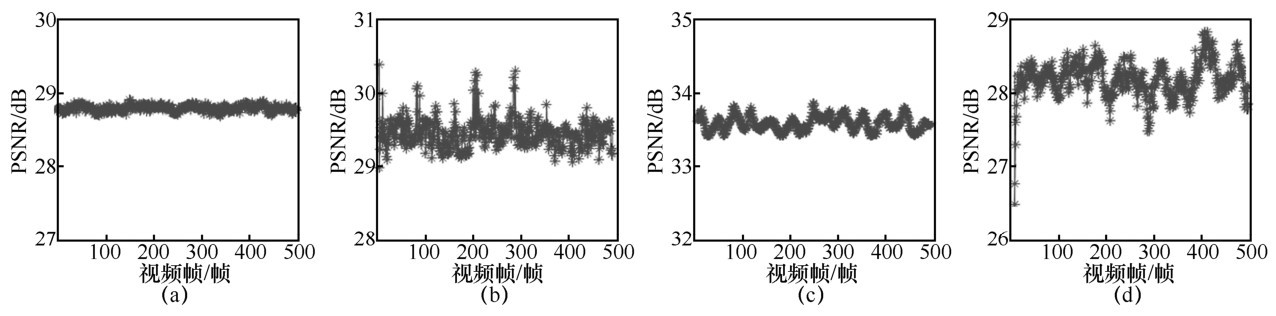
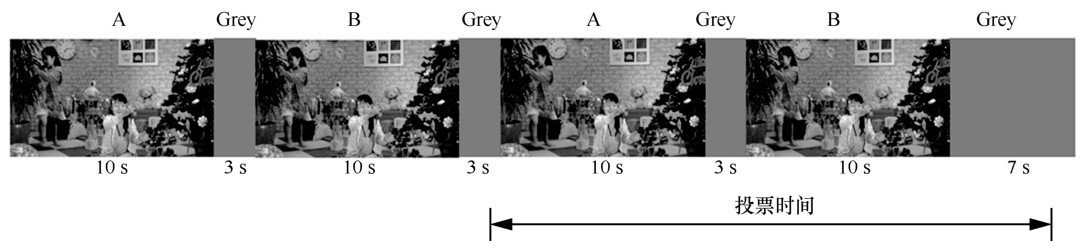
| [1] |
YUAN D , ZHAO T S , XU Y W ,et al. Visual JND:a perceptual measurement in video coding[J]. IEEE Access, 2019(7): 29014-29022.
|
| [2] |
KORHONEN J . Two-level approach for no-reference consumer video quality assessment[J]. IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society, 2019,28(12): 5923-5938.
|
| [3] |
CHOU C H , LI Y C . A perceptually tuned subband image coder based on the measure of just-noticeable-distortion profile[J]. IEEE Transactions on Circuits and Systems for Video Technology, 1995,5(6): 467-476.
|
| [4] |
YANG X K , LING W S , LU Z K ,et al. Just noticeable distortion model and its applications in video coding[J]. Signal Processing:Image Communication, 2005,20(7): 662-680.
|
| [5] |
CHIN Y J , BERGER T . A software-only videocodec using pixelwise conditional differential replenishment and perceptual enhancements[J]. IEEE Transactions on Circuits and Systems for Video Technology, 1999,9(3): 438-450.
|
| [6] |
KELLY D H . Motion and vision.II.Stabilized spatio-temporal threshold surface[J]. Journal of the Optical Society of America, 1979,69(10): 1340-1349.
|
| [7] |
DALY S . Engineering observations from spatiovelocity and spatiotemporal visual models[M]. Vision Models and Applications to Image and Video Processing. Heidelberg: Springer, 2001: 179-200.
|
| [8] |
JIA Y , LIN W , KASSIM A A . Estimating just-noticeable distortion for video[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2006,16(7): 820-829.
|
| [9] |
WEI Z Y , NGAN K N . Spatio-temporal just noticeable distortion profile for grey scale image/video in DCT domain[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009,19(3): 337-346.
|
| [10] |
BAE S H , KIM M . A DCT-based total JND profile for spatiotemporal and foveated masking effects[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017,27(6): 1196-1207.
|
| [11] |
WANG H Q , GAN W H , HU S D ,et al. MCL-JCV:a JND-based H.264/AVC video quality assessment dataset[C]// Proceedings of 2016 IEEE International Conference on Image Processing. Piscataway:IEEE Press, 2016: 1509-1513.
|
| [12] |
WANG H Q , KATSAVOUNIDIS I , ZHOU J T ,et al. VideoSet:a large-scale compressed video quality dataset based on JND measurement[J]. Journal of Visual Communication and Image Representation, 2017,46: 292-302.
|
| [13] |
KI S , BAE S H , KIM M ,et al. Learning-based just-noticeable-quantization- distortion modeling for perceptual video coding[J]. IEEE Transactions on Image Processing, 2018,27(7): 3178-3193.
|
| [14] |
LIU H H , ZHANG Y , ZHANG H ,et al. Deep learning-based picture-wise just noticeable distortion prediction model for image compression[J]. IEEE Transactions on Image Processing, 2020,29: 641-656.
|
| [15] |
ZHANG Y , LIU H H , YANG Y ,et al. Deep learning based just noticeable difference and perceptual quality prediction models for compressed video[J]. IEEE Transactions on Circuits and Systems for Video Technology, 6224(99): 1.
|
| [16] |
WANG Z , LI Q . Video quality assessment using a statistical model of human visual speed perception[J]. Journal of the Optical Society of America A,Optics,Image Science,and Vision, 2007,24(12): B61-B69.
|
| [17] |
MACKNIK S L , LIVINGSTONE M S . Neuronal correlates of visibility and invisibility in the primate visual system[J]. Nature Neuroscience, 1998,1(2): 144-149.
|
| [18] |
STOCKER A A , SIMONCELLI E P . Noise characteristics and prior expectations in human visual speed perception[J]. Nature Neuroscience, 2006,9(4): 578-585.
|
| [19] |
PETERSON H A , AHUMADA A J J , WATSON A B . Improved detection model for DCT coefficient quantization[C]// Proceedings of the Human Vision,Visual Processing,and Digital Dis play IV,F,1993.[S.l.:s.n.], 1993: 191-201.
|
| [20] |
BARKOWSKY M , BIALKOWSKI J , ESKOFIER B ,et al. Temporal trajectory aware video quality measure[J]. IEEE Journal of Selected Topics in Signal Processing, 2009,3(2): 266-279.
|
| [21] |
HU S D , JIN L N , WANG H L ,et al. Objective video quality assessment based on perceptually weighted mean squared error[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017,27(9): 1844-1855.
|
| [22] |
CHEN Z , GUILLEMOT C . Perceptually-friendly H.264/AVC video coding based on foveated just-noticeable-distortion model[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2010,20(6): 806-819.
|
| [23] |
WU J , QI F , SHI G ,et al. Non-local spatial redundancy reduction for bottom-up saliency estimation[J]. Journal of Visual Communication and Image Representation, 2012,23(7): 1158-1166.
|
| [24] |
崔帅南, 彭宗举, 邹文辉 ,等. 多特征融合的合成视点立体图像质量评价[J]. 电信科学, 2019,35(5): 104-112.
|
|
CUI S N , PENG Z J , ZOU W H ,et al. Quality assessment of synthetic viewpoint stereo image with multi-feature fusion[J]. Telecommunications Science, 2019,35(5): 104-112.
|
| [25] |
ZENG Z P , ZENG H Q , CHEN J ,et al. Visual attention guide dpixel-wise just noticeable difference model[J]. IEEE Access, 2019,7: 132111-132119.
|