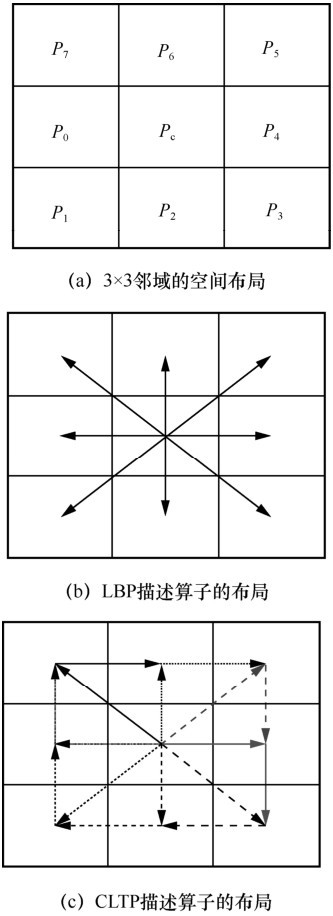
| [1] |
DHANUSH B K , SUPARNA S , AARTHY R ,et al. Factor analysis methods for joint speaker verification and spoof detection[C]// Proceedings of 2017 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Piscataway:IEEE Press, 2017: 5385-5389.
|
| [2] |
MO Y C , WANG S L . Multi-task learning improves synthetic speech detection[C]// Proceedings of ICASSP 2022 - 2022 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Piscataway:IEEE Press, 2022: 6392-6396.
|
| [3] |
LI C T , YANG F R , YANG J . The role of long-term dependency in synthetic speech detection[J]. IEEE Signal Processing Letters, 2022,29: 1142-1146.
|
| [4] |
PAUL D , PAL M , SAHA G . Spectral features for synthetic speech detection[J]. IEEE Journal of Selected Topics in Signal Processing, 2017,11(4): 605-617.
|
| [5] |
HIMAWAN I , VILLAVICENCIO F , SRIDHARAN S ,et al. Deep domain adaptation for anti-spoofing in speaker verification systems[J]. Computer Speech & Language, 2019,58: 377-402.
|
| [6] |
梁瑞刚, 吕培卓, 赵月 ,等. 视听觉深度伪造检测技术研究综述[J]. 信息安全学报, 2020,5(2): 1-17.
|
|
LIANG R G , LYU P Z , ZHAO Y ,et al. A survey of audiovisual deepfake detection techniques[J]. Journal of Cyber Security, 2020,5(2): 1-17.
|
| [7] |
YANG J C , DAS R K , LI H Z . Extended constant-Q cepstral coefficients for detection of spoofing attacks[C]// Proceedings of 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). Piscataway:IEEE Press, 2019: 1024-1029.
|
| [8] |
SRINIVAS K , DAS R K , PATIL H A . Combining phase-based features for replay spoof detection system[C]// Proceedings of 2018 11th International Symposium on Chinese Spoken Language Processing (ISCSLP). Piscataway:IEEE Press, 2019: 151-155.
|
| [9] |
任延珍, 刘晨雨, 刘武洋 ,等. 语音伪造及检测技术研究综述[J]. 信号处理, 2021,37(12): 2412-2439.
|
|
REN Y Z , LIU C Y , LIU W Y ,et al. A survey on speech forgery and detection[J]. Journal of Signal Processing, 2021,37(12): 2412-2439.
|
| [10] |
YANG J C , DAS R K . Improving anti-spoofing with octave spectrum and short-term spectral statistics information[J]. Applied Acoustics, 2020,157:107017.
|
| [11] |
徐剑, 简志华, 于佳祺 ,等. 采用完整局部二进制模式的伪装语音检测[J]. 电信科学, 2021,37(5): 91-99.
|
|
XU J , JIAN Z H , YU J Q ,et al. Completed local binary pattern based speech anti-spoofing[J]. Telecommunications Science, 2021,37(5): 91-99.
|
| [12] |
ALEGRE F , AMEHRAYE A , EVANS N . A one-class classification approach to generalised speaker verification spoofing countermeasures using local binary patterns[C]// Proceedings of 2013 IEEE Sixth International Conference on Biometrics:Theory,Applications and Systems (BTAS). Piscataway:IEEE Press, 2014: 1-8.
|
| [13] |
JAVED A , MALIK K M , MALIK H ,et al. Voice spoofing detector:a unified anti-spoofing framework[J]. Expert Systems With Applications, 2022,198:116770.
|
| [14] |
ZHAO X C , LIN Y P , HEIKKIL? J . Dynamic texture recognition using volume local binary count patterns with an application to 2D face spoofing detection[J]. IEEE Transactions on Multimedia, 2018,20(3): 552-566.
|
| [15] |
ZHANG Y J , LI S H , WANG S L ,et al. Revealing the traces of Median filtering using high-order local ternary patterns[J]. IEEE Signal Processing Letters, 2014,21(3): 275-279.
|
| [16] |
ZHENG Z H , XU B C , JU J P ,et al. Circumferential local ternary pattern:new and efficient feature descriptors for anti-counterfeiting pattern identification[J]. IEEE Transactions on Information Forensics and Security, 2022,17: 970-981.
|
| [17] |
于佳祺, 简志华, 徐嘉 ,等. 基于联合特征与随机森林的伪装语音检测[J]. 电信科学, 2022,38(6): 91-99.
|
|
YU J Q , JIAN Z H , XU J ,et al. Spoofing speech detection algorithm based on joint feature and random forest[J]. Telecommunications Science, 2022,38(6): 91-99.
|
| [18] |
梁超, 高勇 . 一种利用 SE-Res2Net 的合成语音检测系统[J]. 无线电工程, 2022,52(9): 1560-1565.
|
|
LIANG C , GAO Y . A synthetic speech detection system using SE-Res2Net[J]. Radio Engineering, 2022,52(9): 1560-1565.
|
| [19] |
MONTEIRO J , ALAM J , FALK T H . Generalized end-to-end detection of spoofing attacks to automatic speaker recognizers[J]. Computer Speech & Language, 2020,63:101096.
|
| [20] |
ZHANG Y , JIANG F , DUAN Z Y . One-class learning towards synthetic voice spoofing detection[J]. IEEE Signal Processing Letters, 2021,28: 937-941.
|
| [21] |
WANG X , YAMAGISHI J , TODISCO M ,et al. ASVspoof 2019:a large-scale public database of synthesized,converted and replayed speech[J]. Computer Speech & Language, 2020,64:101114.
|
| [22] |
KINNUNEN T , DELGADO H , EVANS N ,et al. Tandem assessment of spoofing countermeasures and automatic speaker verification:fundamentals[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2020,28: 2195-2210.
|
| [23] |
MALIK K M , JAVED A , MALIK H ,et al. A light-weight replay detection framework for voice controlled IoT devices[J]. IEEE Journal of Selected Topics in Signal Processing, 2020,14(5): 982-996.
|
| [24] |
WU Z Z , DAS R K , YANG J C ,et al. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks[C]// Proceedings of Interspeech 2020.[S.l.:s.n.], 2020: 1101-1105.
|
| [25] |
TAK H , PATINO J , TODISCO M ,et al. End-to-end anti-spoofing with RawNet2[C]// Proceedings of ICASSP 2021-2021 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Piscataway:IEEE Press, 2021: 6369-6373.
|
| [26] |
王锦阳, 华光, 黄双 . 基于注意力机制的端到端合成语音检测[J]. 信号处理, 2022,38(9): 1975-1987.
|
|
WANG J Y , HUA G , HUANG S . End-to-end synthetic speech detection based on attention mechanism[J]. Journal of Signal Processing, 2022,38(9): 1975-1987.
|