摘要:
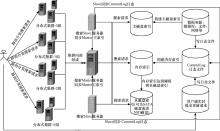
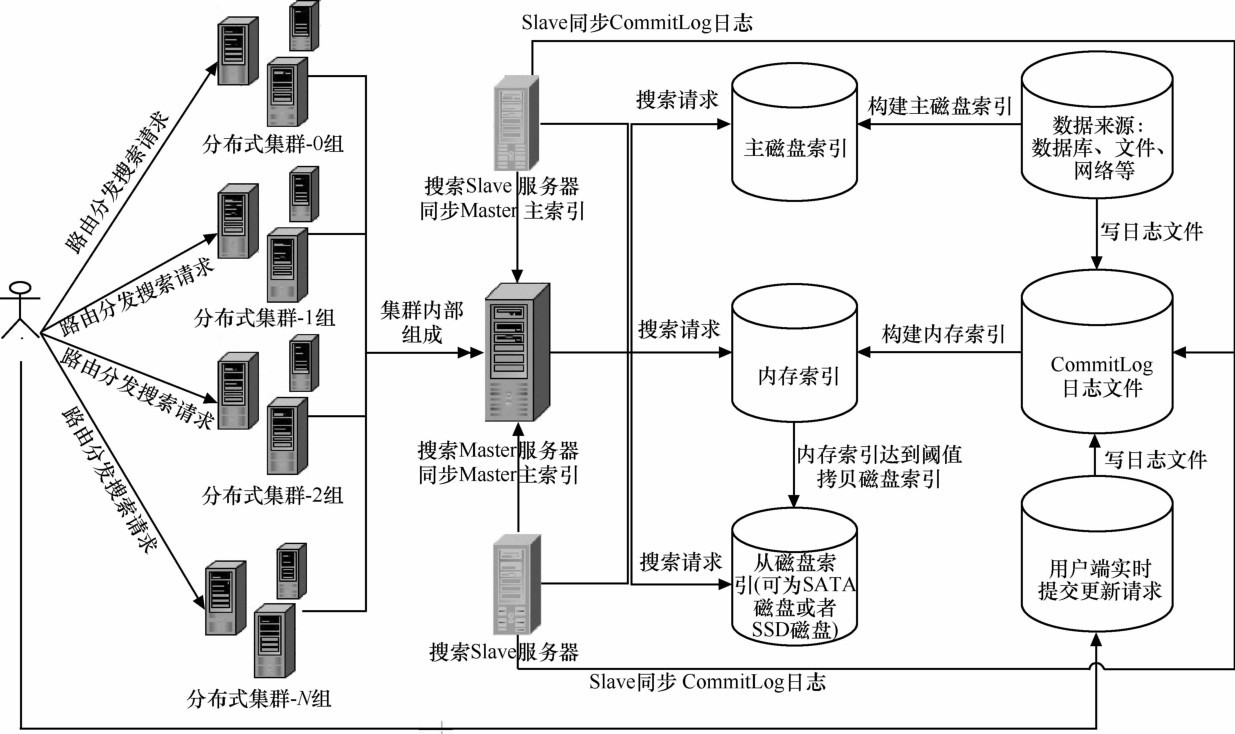
实时搜索已成为信息检索领域的热点问题之一。传统搜索引擎在分布式环境下无法保证大数据量、高并发情况下的实时响应和数据容灾。本文提出了一种基于 Solr 的分布式实时搜索模型,分析了其实现原理。模型通过内存索引与磁盘索引相结合保证索引信息的实时展示,同时引入CommitLog 日志保证内存索引数据容灾,并通过Master/Slave 模型保证搜索服务的可用性。最终应用于实际生产系统中,实践结果充分证明了该模型的可行性。
傅巍玮,李仁发,刘钰峰,黄松立. 基于Solr的分布式实时搜索模型研究与实现[J]. 电信科学, 2011, 27(11): 51-56.
Weiwei Fu,Renfa Li,Yufeng Liu,Songli Huang. Study and Implementation of Distributed Real-Time Search Engine Model Based on Solr[J]. Telecommunications Science, 2011, 27(11): 51-56.