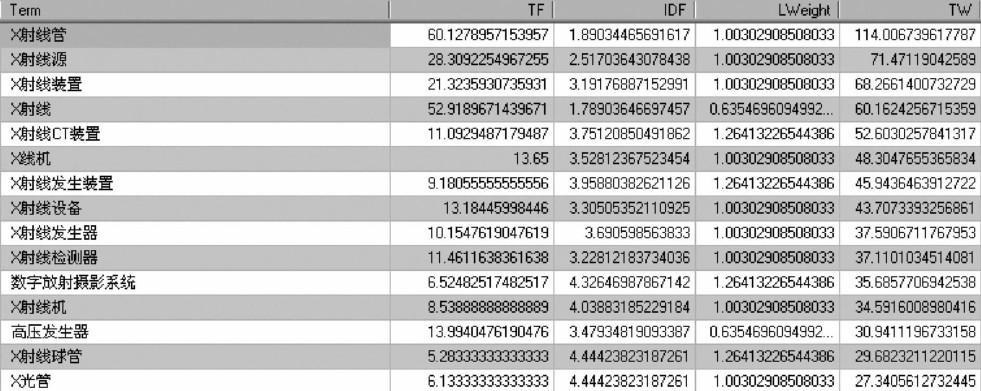
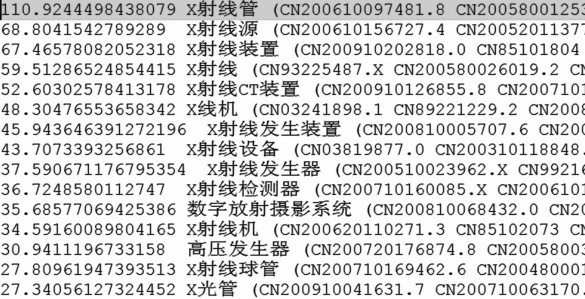
| [1] |
郭泽华, 朱昊文, 徐同文. 面向分布式机器学习的网络模态创新[J]. 电信科学, 2023, 39(6): 44-51. |
| [2] |
韩璐, 陈威宇, 张斐, 何建锋, 苏怀振. 差异化需求下的非关系型分布式报送信息大数据分类方法[J]. 电信科学, 2023, 39(6): 114-121. |
| [3] |
陈楠, 赵建军, 钟平, 黄勇军, 陈天. 基于云原生的分布式物联网操作系统架构研究[J]. 电信科学, 2022, 38(7): 146-156. |
| [4] |
李琴, 李唯源, 孙晓文, 胡玉双, 孙滔. 6G网络智能内生的思考[J]. 电信科学, 2021, 37(9): 20-29. |
| [5] |
刘飞扬, 李坤, 宋飞, 周华春. DDoS攻击恶意行为知识库构建[J]. 电信科学, 2021, 37(11): 17-32. |
| [6] |
余云河, 孙君. 机器类通信中集中式与分布式Q学习的资源分配算法研究[J]. 电信科学, 2021, 37(11): 41-50. |
| [7] |
李舒婷,刘金科,陈娜. 基于区块链技术的计费清结算平台的设计与研究[J]. 电信科学, 2020, 36(9): 84-93. |
| [8] |
许丹丹,张云勇,张道琳,张第,王笑,蔡一欣. 5G时代区块链发展趋势及应用分析[J]. 电信科学, 2020, 36(3): 117-124. |
| [9] |
马大燕,谢祥颖,那峙雄,沈文涛,孟凡腾. 基于调度自动化系统的低压分布式光伏电站接入估算模型[J]. 电信科学, 2020, 36(2): 90-94. |
| [10] |
谢萍,刘孝颂. 基于区块链的SDN物联网部署安全[J]. 电信科学, 2020, 36(12): 139-146. |
| [11] |
张帅,潘鹏,王璀. 分布式阵列系统中反馈比特的分配方法[J]. 电信科学, 2020, 36(11): 79-88. |
| [12] |
聂凯君,曹傧,彭木根. 6G内生安全:区块链技术[J]. 电信科学, 2020, 36(1): 21-27. |
| [13] |
孙嘉琪, 杨广铭, 党娟娜, 刘文杰. 温敏网络的关键能力和架构体系[J]. 电信科学, 2019, 35(9): 52-57. |
| [14] |
任昊文,杨雅琪. 区块链分布式技术在电力需求侧响应管理中的应用[J]. 电信科学, 2019, 35(5): 155-160. |
| [15] |
康凯凯,刘兆霆,姚英彪. 传感器网络分布式顽健RLS估计算法[J]. 电信科学, 2019, 35(1): 37-43. |