

通信学报 ›› 2022, Vol. 43 ›› Issue (3): 180-195.doi: 10.11959/j.issn.1000-436x.2022051
冯竞舸1,2, 贺也平1,2,3, 陶秋铭1,2
修回日期:2022-02-09
出版日期:2022-03-25
发布日期:2022-03-01
作者简介:冯竞舸(1988- )男,满族,河北临城人,中国科学院大学博士生,主要研究方向为编译技术及性能优化技术基金资助:Jingge FENG1,2, Yeping HE1,2,3, Qiuming TAO1,2
Revised:2022-02-09
Online:2022-03-25
Published:2022-03-01
Supported by:摘要:
随着单指令流多数据流(SIMD)技术的迅速发展,近年来许多面向 SIMD 扩展部件的自动向量化编译方法被提出,有效缓解了程序员手写向量程序的压力,并发挥了SIMD扩展部件的加速效能。基于此,分析总结了自动向量化领域近 10 年的研究成果,从保义分析和变换、向量化分组分析和变换、面向处理器支持特性的分析和变换以及性能评估分析这4个方面分类归纳了自动向量化的关键问题和主要突破,进而对4个方面的发展趋势和研究方向进行了展望。
中图分类号:
冯竞舸, 贺也平, 陶秋铭. 自动向量化:近期进展与展望[J]. 通信学报, 2022, 43(3): 180-195.
Jingge FENG, Yeping HE, Qiuming TAO. Auto-vectorization: recent development and prospect[J]. Journal on Communications, 2022, 43(3): 180-195.

图1
自动向量化问题描述"


图2
自动向量化示例"

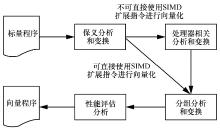
图3
自动向量化流程"

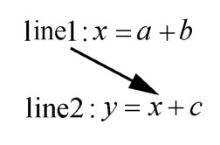
图4
数据依赖说明"

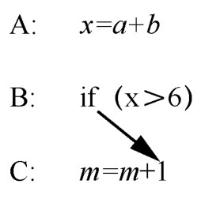
图5
控制依赖说明"

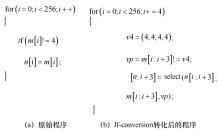
图6
基于If-conversion的向量化方法示例"


图7
别名分析示例程序"
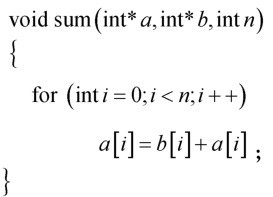
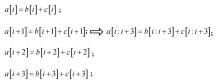
图8
分组转换示例"
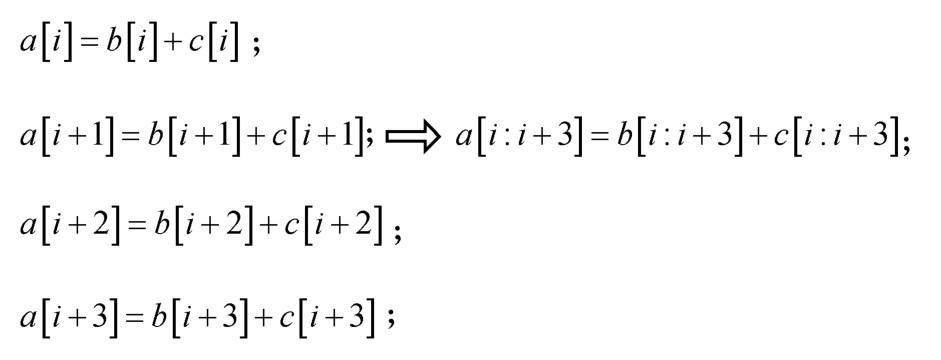

图9
Loop-based自动向量化方法示例"
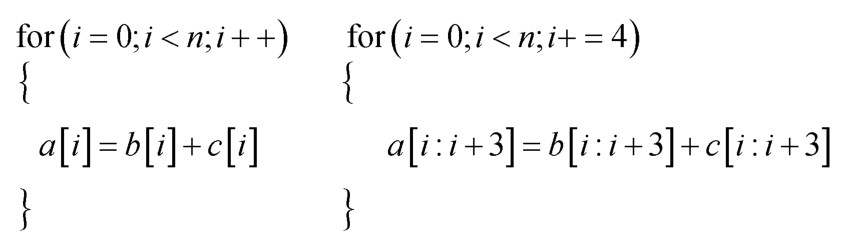
表1
支持带有SIMD扩展部件的处理器"
| 厂商 | 处理器 | 指令集 | 长度/bit |
| MMX | 64 | ||
| Pentium | |||
| SSE | 128 | ||
| AVX128 | 128 | ||
| Intel | |||
| AVX256 | 256 | ||
| Core | |||
| IMCI | 512 | ||
| AVX512 | 512 | ||
| P6 | VMX | 128 | |
| IBM | |||
| BG/L | BG/L | 256 | |
| DEC | Alpha | MVI | 64 |
| SGI | MIPS V | MDMX | 64 |
| Sun | SPARC v9 | VIS | 64 |
| HP | PA-RISC | MAX2-2 | 64 |
| Motorola | G4 | AltiVec | 128 |
| Athlon | 3Dnow! | 128 | |
| AMD | Jaguar | F16C | 128 |
| Bulldozer | FMA | 256 | |
| Ingenic | XBurst | MXU | 128 |
| Sony | Cell | AltiVec | 128 |
| CAS | Godson | Godson | 256 |
| NRCPC | SW26010 | SW26010 | 256 |
| NUDT | Matrix | Matrix | 1024 |
| ARMv6 | NEON | 128 | |
| ARM | PPC970 | VMX | 128 |
| ARMv8 | SVE | 2 048 |
表2
Intel SIMD扩展部件的指令集统计"
| 序号 时间 | 指令集 | 处理器 | 长度/bit | 特征 |
| 1 2015年 | AVX512 | Xeon Phi | 512 | Masked blend、Perm、Bitwise、Conflict detection、Gather、Scatter and Prefetchinstruction |
| 2 2013年 | AVX256 | Haswell | 256 | Mul and add instruction、Gather instruction、Broadcast instruction Masked load andstore instruction |
| 3 2008年 | AVX128 | Sandy Bridge | 128 | Data reorganization and Unaligned memory instruction |
| 4 2006年 | SSE4 | Penryn/Nehalem | 128 | Insert、Extract、Search and String processing instruction |
| 5 2004年 | SSE3 | Pentium4 | 128 | Unaligned memory instruction,Horizontal add instruction |
| 6 2001年 | SSE2 | Pentium4 | 128 | Type conversion instruction |
| 7 1999年 | SSE | Pentium3 | 128 | 128 length of Basic logical operation,shift and compare operation |
| 8 1996年 | MMX | Pentium | 64 | Basic logical operation,shift and compare operation |
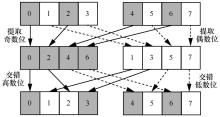
图10
交错和提取操作"


图11
改进自动向量化评估模型"
| [1] | 杨毅宇, 周威, 赵尚儒 ,等. 物联网安全研究综述:威胁、检测与防御[J]. 通信学报, 2021,42(8): 188-205. |
| YANG Y Y , ZHOU W , ZHAO S R ,et al. Survey of IoT security research:threats,detection and defense[J]. Journal on Communications, 2021,42(8): 188-205. | |
| [2] | 高伟, 赵荣彩, 韩林 ,等. SIMD自动向量化编译优化概述[J]. 软件学报, 2015,26(6): 1265-1284. |
| GAO W , ZHAO R C , HAN L ,et al. Research on SIMD auto-vectorization compiling optimization[J]. Journal of Software, 2015,26(6): 1265-1284. | |
| [3] | ZHENG R H , PAI S . Efficient execution of graph algorithms on CPU with SIMD extensions[C]// Proceedings of 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). Piscataway:IEEE Press, 2021: 262-276. |
| [4] | B?HM C , PLANT C . Massively parallel graph drawing and representation learning[C]// Proceedings of 2020 IEEE International Conference on Big Data (Big Data). Piscataway:IEEE Press, 2020: 609-616. |
| [5] | YAMAZAKI S . Future possibilities and effectiveness of JIT from elixir code of image processing and machine learning into native code with SIMD instructions[R]. 2021. |
| [6] | BIAN H D , HUANG J Q , LIU L B ,et al. ALBUS:a method for efficiently processing SpMV using SIMD and load balancing[J]. Future Generation Computer Systems, 2021,116: 371-392. |
| [7] | PAPAPHILIPPOU P , PAUL H J K , LUK W . Simodense:a RISC-V softcore optimised for exploring custom SIMD instructions[C]// Proceedings of 2021 31st International Conference on Field-Programmable Logic and Applications (FPL). Piscataway:IEEE Press, 2021: 391-397. |
| [8] | GAO Y , LIU Y Z , MA Y M ,et al. abPOA:an SIMD-based C library for fast partial order alignment using adaptive band[J]. Bioinformatics, 2020,37(15): 2209-2211. |
| [9] | BARREDO A , CEBRIAN J M , MORETó M ,et al. Improving predication efficiency through compaction/restoration of SIMD instructions[C]// Proceedings of 2020 IEEE International Symposium on High Performance Computer Architecture. Piscataway:IEEE Press, 2020: 717-728. |
| [10] | LI H J , HAN J , HAN D S . Leveraging SIMD parallelism for accelerating network applications[C]// Proceedings of APNet’20 4th Asia-Pacific Workshop on Networking. New York:ACM Press, 2020: 23-29. |
| [11] | MALEKI S , GAO Y Q , GARZAR′N M J ,et al. An evaluation of vectorizing compilers[C]// Proceedings of 2011 International Conference on Parallel Architectures and Compilation Techniques. Piscataway:IEEE Press, 2011: 372-382. |
| [12] | SISO S , ARMOUR W , THIYAGALINGAM J . Evaluating auto-vectorizing compilers through objective withdrawal of useful information[J]. ACM Transactions on Architecture and Code Optimization, 2020,16(4): 1-23. |
| [13] | INOUE H , . How SIMD width affects energy efficiency:a case study on sorting[C]// Proceedings of 2016 IEEE Symposium in Low-Power and High-Speed Chips. Piscataway:IEEE Press, 2016: 1-3. |
| [14] | AMIRI H , SHAHBAHRAMI A . SIMD programming using Intel vector extensions[J]. Journal of Parallel and Distributed Computing, 2020,135: 83-100. |
| [15] | STOJANOV A , TOSKOV I , ROMPF T ,et al. SIMD intrinsics on managed language runtimes[C]// Proceedings of the 2018 International Symposium on Code Generation and Optimization. 2018: 2-15. |
| [16] | BOGAEVSKIY D , MINENKO M , EZHOV S ,et al. Development and implementation of the H.264-codec deblocking filter based on the MIPS SIMD architecture[C]// Proceedings of 2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus). Piscataway:IEEE Press, 2021: 246-251. |
| [17] | STEPHENS N , BILES S , BOETTCHER M ,et al. The ARM scalable vector extension[J]. IEEE Micro, 2017,37(2): 26-39. |
| [18] | KUMAR R , MARTINEZ A , GONZALEZ A . A variable vector length SIMD architecture for HW/SW co-designed processors[J]. arXiv Preprint,arXiv:2102.13410, 2021. |
| [19] | MITRA G , JOHNSTON B , RENDELL A P ,et al. Use of SIMD vector operations to accelerate application code performance on low-powered ARM and Intel platforms[C]// Proceedings of 2013 IEEE International Symposium on Parallel & Distributed Processing,Workshops and Phd Forum. Piscataway:IEEE Press, 2013: 1107-1116. |
| [20] | 张为华, 藏斌宇 . SIMD编译优化技术研究概述[J]. 中国计算机学会通讯, 2007,3(2): 27-36. |
| ZHANG W H , ZANG B Y . A survey on SIMD vectorization technology[J]. Communications of CCF, 2007,3(2): 27-36. | |
| [21] | PORPODAS V , MAGNI A , JONES T M . PSLP:padded SLP automatic vectorization[C]// Proceedings of 2015 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). Piscataway:IEEE Press, 2015: 190-201. |
| [22] | CHEN Y S , MENDIS C , CARBIN M ,et al. VeGen:a vectorizer generator for SIMD and beyond[C]// Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. New York:ACM Press, 2021: 902-914. |
| [23] | HAJ-ALI A , AHMED N K , WILLKE T ,et al. NeuroVectorizer:end-to-end vectorization with deep reinforcement learning[C]// Proceedings of the 18th ACM/IEEE International Symposium on Code Generation and Optimization. New York:ACM Press, 2020: 242-255. |
| [24] | MOLL S , HACK S . Partial control-flow linearization[C]// Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation. New York:ACM Press, 2018: 543-556. |
| [25] | PLOTKIN G D . Call-by-name,call-by-value and the λ-calculus[J]. Theoretical Computer Science, 1975,1(2): 125-159. |
| [26] | EICHENBERGER A E , WU P , O’BRIEN K , . Vectorization for SIMD architectures with alignment constraints[J]. ACM SIGPLAN Notices, 2004,39(6): 82-93. |
| [27] | PORPODAS V , ROCHA R C O , GóES L F W , . VW-SLP:auto-vectorization with adaptive vector width[C]// Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques. New York:ACM Press, 2018: 1-15. |
| [28] | ALLEN R , KENNEDY K . Optimizing compilers for modern architectures:a dependence-based approach[M]. San Francisco: Morgan Kaufmann Publishers Inc, 2001. |
| [29] | PSARRIS K , KLAPPHOLZ D , KONG X Y . On the accuracy of the Banerjee test[J]. Journal of Parallel and Distributed Computing, 1991,12(2): 152-157. |
| [30] | BULI? P , GUSTIN V , . D-test:an extension to Banerjee test for a fast dependence analysis in a multimedia vectorizing compiler[C]// Proceedings of the 18th International Parallel and Distributed Processing Symposium,2004. Piscataway:IEEE Press, 2004:230. |
| [31] | JENSEN N B , KARLSSON S . Improving loop dependence analysis[J]. ACM Transactions on Architecture and Code Optimization, 2017,14(3): 1-24. |
| [32] | SAMPAIO D N , POUCHET L N , RASTELLO F . Simplification and runtime resolution of data dependence constraints for loop transformations[C]// Proceedings of the International Conference on Supercomputing. New York:ACM Press, 2017: 1-11. |
| [33] | 赵捷, 赵荣彩 . 基于有向图可达性的 SLP 向量化识别方法[J]. 中国科学:信息科学, 2017,47(3): 310-325. |
| ZHAO J , ZHAO R C . Identifying superword level parallelism with directed graph reachability[J]. Scientia Sinica (Informationis), 2017,47(3): 310-325. | |
| [34] | SMITH J E , FAANES G , SUGUMAR R . Vector instruction set support for conditional operations[J]. ACM SIGARCH Computer Architecture News, 2000,28(2): 260-269. |
| [35] | HALL M , SHIN J . Compiler optimizations for architectures supporting superword-level parallelism[M]. Los Angeles: University of Southern California, 2005. |
| [36] | SHIN J , . Introducing control flow into vectorized code[C]// Proceedings of the 16th International Conference on Parallel Architecture and Compilation Techniques (PACT 2007). Piscataway:IEEE Press, 2007: 280-291. |
| [37] | 孙回回, 赵荣彩, 高伟 ,等. 基于条件分类的控制流向量化[J]. 计算机科学, 2015,42(11): 240-247. |
| SUN H H , ZHAO R C , GAO W ,et al. Control flow vectorization based on conditions classification[J]. Computer Science, 2015,42(11): 240-247. | |
| [38] | SUJON M H , WHALEY R C , YI Q . Vectorization past dependent branches through speculation[C]// Proceedings of the 22nd International Conference on Parallel Architectures And Compilation Techniques. Piscataway:IEEE Press, 2013: 353-362. |
| [39] | BAGHSORKHI S S , VASUDEVAN N , WU Y F . FlexVec:auto-vectorization for irregular loops[J]. ACM SIGPLAN Notices, 2016,51(6): 697-710. |
| [40] | SUN H H , FEY F , ZHAO J ,et al. WCCV:improving the vectorization of IF-statements with warp-coherent conditions[C]// Proceedings of the ACM International Conference on Supercomputing. New York:ACM Press, 2019: 319-329. |
| [41] | 高伟, 李颖颖, 孙回回 ,等. 一种改进的控制流 SIMD 向量化方法[J]. 软件学报, 2017,28(8): 2046-2063. |
| GAO W , LI Y Y , SUN H H ,et al. Improved SIMD vectorization method in the presence of control flow[J]. Journal of Software, 2017,28(8): 2046-2063. | |
| [42] | MAALEJ M , PAISANTE V , RAMOS P ,et al. Pointer disambiguation via strict inequalities[C]// Proceedings of 2017 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). Piscataway:IEEE Press, 2017: 134-147. |
| [43] | 侯永生 . 多重循环 SIMD 向量化方法及性能优化技术研究[D]. 郑州:解放军信息工程大学, 2014. |
| HOU Y S . Research on SIMD vectorization of loop nests and its optimization techniques[D]. Zhengzhou:PLA Information Engineering University, 2014. | |
| [44] | 刘鹏, 赵荣彩, 李朋远 . 一种面向向量化的动态指针别名分析框架[J]. 计算机科学, 2015,42(3): 26-30. |
| LIU P , ZHAO R C , LI P Y . Dynamic pointer alias analysis framework for vectorization[J]. Computer Science, 2015,42(3): 26-30. | |
| [45] | SUI Y L , FAN X K , ZHOU H ,et al. Loop-oriented array and field-sensitive pointer analysis for automatic SIMD vectorization[J]. ACM SIGPLAN Notices, 2016,51(5): 41-51. |
| [46] | 高伟, 韩林, 赵荣彩 ,等. 向量并行度指导的循环SIMD向量化方法[J]. 软件学报, 2017,28(4): 925-939. |
| GAO W , HAN L , ZHAO R C ,et al. Loop vectorization method guided by SIMD parallelism[J]. Journal of Software, 2017,28(4): 925-939. | |
| [47] | LARSEN S , AMARASINGHE S . Exploiting superword level parallelism with multimedia instruction sets[C]// Proceedings of the ACM SIGPLAN 2000 conference on Programming language design and implementation. New York:ACM Press, 2000: 145-156. |
| [48] | 徐金龙, 赵荣彩, 韩林 . 分段约束的超字并行向量发掘路径优化算法[J]. 计算机应用, 2015,35(4): 950-955. |
| XU J L , ZHAO R C , HAN L . Vector exploring path optimization algorithm of superword level parallelism with subsection constraints[J]. Journal of Computer Applications, 2015,35(4): 950-955. | |
| [49] | PORPODAS V , JONES T M . Throttling automatic vectorization:when less is more[C]// Proceedings of 2015 International Conference on Parallel Architecture and Compilation (PACT). Piscataway:IEEE Press, 2015: 432-444. |
| [50] | PORPODAS V , ROCHA R C O , GóES L F W , . Look-ahead SLP:auto-vectorization in the presence of commutative operations[C]// Proceedings of the 2018 International Symposium on Code Generation and Optimization. New York:ACM Press, 2018: 163-174. |
| [51] | PORPODAS V , RATNALIKAR P . PostSLP:cross-region vectorization of fully or partially vectorized code[C]// Languages and Compilers for Parallel Computing. Berlin:Springer, 2021: 15-31. |
| [52] | PORPODAS V , . SuperGraph-SLP auto-vectorization[C]// Proceedings of 2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT). Piscataway:IEEE Press, 2017: 330-342. |
| [53] | MENDIS C , JAIN A , JAIN P ,et al. Revec:program rejuvenation through revectorization[C]// Proceedings of the 28th International Conference on Compiler Construction. 2019: 29-41. |
| [54] | BARIK R , ZHAO J S , SARKAR V . Efficient selection of vector instructions using dynamic programming[C]// Proceedings of 2010 43rd Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway:IEEE Press, 2010: 201-212. |
| [55] | LIU J , ZHANG Y R , JANG O ,et al. A compiler framework for extracting superword level parallelism[J]. ACM SIGPLAN Notices, 2012,47(6): 347-358. |
| [56] | HUH J , TUCK J . Improving the effectiveness of searching for isomorphic chains in superword level parallelism[C]// Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway:IEEE Press, 2017: 718-729. |
| [57] | MENDIS C , AMARASINGHE S . goSLP:globally optimized superword level parallelism framework[C]// Proceedings of the ACM on Programming Languages. New York:ACM Press, 2018: 1-28. |
| [58] | MENDIS C , YANG C , PU Y ,et al. Compiler auto-vectorization with imitation learning[C]// Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019). Cambridge:MIT Press, 2019:32. |
| [59] | ALLEN J R , KENNEDY K , PORTERFIELD C ,et al. Conversion of control dependence to data dependence[C]// Proceedings of the 10th ACM SIGACT-SIGPLAN Symposium on Principles of Programming Languages. New York:ACM Press, 1983: 177-189. |
| [60] | NUZMAN D , ZAKS A . Outer-loop vectorization:revisited for short SIMD architectures[C]// Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques. New York:ACM Press, 2008: 2-11. |
| [61] | 魏帅, 赵荣彩, 姚远 . 面向SLP的多重循环向量化[J]. 软件学报, 2012,23(7): 1717-1728. |
| WEI S , ZHAO R C , YAO Y . Loop-nest auto-vectorization based on SLP[J]. Journal of Software, 2012,23(7): 1717-1728. | |
| [62] | ZHAO J , LI B J , NIE W ,et al. AKG:automatic kernel generation for neural processing units using polyhedral transformations[C]// Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. New York:ACM Press, 2021: 1233-1248. |
| [63] | TRIFUNOVIC K , NUZMAN D , COHEN A ,et al. Polyhedral-model guided loop-nest auto-vectorization[C]// Proceedings of 2009 18th International Conference on Parallel Architectures and Compilation Techniques. Piscataway:IEEE Press, 2009: 327-337. |
| [64] | KONG M , VERAS R , STOCK K ,et al. When polyhedral transformations meet SIMD code generation[J]. ACM SIGPLAN Notices, 2013,48(6): 127-138. |
| [65] | MOREIRA R E A , COLLANGE C , QUINT?O F M , . Function call re-vectorization[J]. ACM SIGPLAN Notices, 2017,52(8): 313-326. |
| [66] | GNU. Using vector instructions through build-in functions[R]. 2018. |
| [67] | KARRENBERG R . Automatic SIMD vectorization of SSA-based control flow graphs[M]. Wiesbaden: Springer Vieweg, 2015. |
| [68] | REICHE O , KOBYLKO C , HANNIG F ,et al. Auto-vectorization for image processing DSLs[C]// Proceedings of the 18th ACM SIGPLAN/SIGBED Conference on Languages,Compilers,and Tools for Em bedded Systems. New York:ACM Press, 2017: 21-30. |
| [69] | SHIN J , HALL M , CHAME J . Superword-level parallelism in the presence of control flow[C]// Proceedings of International Symposium on Code Generation and Optimization. Piscataway:IEEE Press, 2005: 165-175. |
| [70] | TANAKA H , OTA Y , MATSUMOTO N ,et al. A new compilation technique for SIMD code generation across basic block boundaries[C]// Proceedings of 2010 15th Asia and South Pacific Design Automation Conference (ASP-DAC). Piscataway:IEEE Press, 2010: 101-106. |
| [71] | LARSEN S , RABBAH R , AMARASINGHE S . Exploiting vector parallelism in software pipelined loops[C]// Proceedings of 38th Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway:IEEE Press, 2005: 11-129. |
| [72] | ROCHA R C O , PORPODAS V , PETOUMENOS P ,et al. Vectorization-aware loop unrolling with seed forwarding[C]// Proceedings of the 29th International Conference on Compiler Construction. New York:ACM Press, 2020: 1-13. |
| [73] | ZHOU H , XUE J L . Exploiting mixed SIMD parallelism by reducing data reorganization overhead[C]// Proceedings of 2016 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). Piscataway:IEEE Press, 2016: 59-69. |
| [74] | YAZDANPANAH F . An approach for analyzing auto-vectorization potential of emerging workloads[J]. Microprocessors and Microsystems, 2017,49: 139-149. |
| [75] | RODRIGUEZ-CANCIO M , COMBEMALE B , BAUDRY B . Automatic microbenchmark generation to prevent dead code elimination and constant folding[C]// Proceedings of 2016 31st IEEE/ACM International Conference on Automated Software Engineering (ASE). Piscataway:IEEE Press, 2016: 132-143. |
| [76] | PORPODAS V , ROCHA R C O , BREVNOV E ,et al. Super-node SLP:optimized vectorization for code sequences containing operators and their inverse elements[C]// Proceedings of 2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). Piscataway:IEEE Press, 2019: 206-216. |
| [77] | SUN H H , ZHAO R C , GAO W ,et al. Exploiting pure superword level parallelism for array indirections[C]// Proceedings of 2015 Seventh International Symposium on Parallel Architectures,Algorithms and Programming (PAAP). Piscataway:IEEE Press, 2015: 13-19. |
| [78] | ASHFAQ M , HUANG R B , OMARI M . FSCS-SIMD:an efficient implementation of fixed-size-candidate-set adaptive random testing using SIMD instructions[C]// Proceedings of 2020 IEEE 31st International Symposium on Software Reliability Engineering. Piscataway:IEEE Press, 2020: 277-288. |
| [79] | 姚远 . SIMD自动向量识别及代码调优技术研究[D]. 郑州:解放军信息工程大学, 2012. |
| YAO Y . Research on automatic SIMD vectorization recognization and code tuning technology[D]. Zhengzhou:PLA Information Engineering University, 2012. | |
| [80] | NUZMAN D , ROSEN I , ZAKS A . Auto-vectorization of interleaved data for SIMD[J]. ACM SIGPLAN Notices, 2006,41(6): 132-143. |
| [81] | ANDERSON A , MALIK A , GREGG D . Automatic vectorization of interleaved data revisited[J]. ACM Transactions on Architecture and Code Op timization, 2016,12(4): 50. |
| [82] | 李玉祥, 施慧, 陈莉 . 面向向量化的局部数据重组[J]. 小型微型计算机系统, 2009,30(8): 1528-1534. |
| LI Y X , SHI H , CHEN L . Vectorization-oriented local data regrouping[J]. Journal of Chinese Computer Systems, 2009,30(8): 1528-1534. | |
| [83] | LI P Y , ZHANG Q H , ZHAO R C ,et al. Data layout transformation for structure vectorization on SIMD architectures[C]// Proceedings of 2015 IEEE/ACIS 16th International Conference on Software Engineering,Artificial Intelligence,Networking and Parallel/Distributed Computing (SNPD). Piscataway:IEEE Press, 2015: 1-7. |
| [84] | LI P Y , ZHANG Q H , ZHAO R C ,et al. Data layout transformation for structure vectorization on SIMD architectures[C]// Proceedings of 2015 IEEE/ACIS 16th International Conference on Software Engineering,Artificial Intelligence,Networking and Parallel/Distributed Computing (SNPD). Piscataway:IEEE Press, 2015: 1-7. |
| [85] | 于海宁, 韩林, 李鹏远 . 面向自动向量化的结构体优化[J]. 计算机科学, 2016,43(2): 210-215. |
| YU H N , HAN L , LI P Y . Structure optimization for automatic vectorization[J]. Computer Science, 2016,43(2): 210-215. | |
| [86] | WANG Q , HAN L , YAO J Y ,et al. Research on vectorization technology for irregular data access[C]// Communications in Computer and Information Science. Singapore:Springer Singapore, 2017: 321-334. |
| [87] | KIM S , HAN H . Efficient SIMD code generation for irregular kernels[J]. ACM SIGPLAN Notices, 2012,47(8): 55-64. |
| [88] | 姚金阳, 赵荣彩, 王琦 ,等. 面向间接数组索引的向量化方法[J]. 计算机科学, 2018,45(9): 220-223,236. |
| YAO J Y , ZHAO R C , WANG Q ,et al. Vectorization methods for indirect array index[J]. Computer Science, 2018,45(9): 220-223,236. | |
| [89] | CHEN L C , JIANG P , AGRAWAL G . Exploiting recent SIMD architectural advances for irregular applications[C]// Proceedings of the 2016 International Symposium on Code Generation and Optimization. New York:ACM Press, 2016: 47-58. |
| [90] | JIANG P , AGRAWAL G . Conflict-free vectorization of associative irregular applications with recent SIMD architectural advances[C]// Proceedings of the 2018 International Symposium on Code Generation and Optimization. 2018: 175-187. |
| [91] | PRYANISHNIKOV I , KRALL A . Pointer alignment analysis for processors with SIMD instructions[J]. Software-Practice and Experience, 2007,37: 93-113. |
| [92] | CIORBA F M , IWAINSKY C , BUDER P . OpenMP loop scheduling revisited:making a case for more schedules[C]// Evolving OpenMP for Evolving Architectures. Berlin:Springer, 2018: 21-36. |
| [93] | SHAHBAHRAMI A , JUURLINK B , VASSILIADIS S . Performance impact of misaligned accesses in SIMD extensions[C]// Proceedings of the 17th Annual Workshop on Circuits,Systems and Signal Processing (ProRISC 2006).[S.l.:s.n.], 2006: 334-342. |
| [94] | WU P , EICHENBERGER A E , WANG A . Efficient SIMD code generation for runtime alignment and length conversion[C]// Proceedings of International Symposium on Code Generation and Optimization. Piscataway:IEEE Press, 2005: 153-164. |
| [95] | CRUZ-AYOROA A J . Machine learning driven compiler tuning[D]. Fukuoka:Kyushu University, 2015. |
| [96] | TROUVé A , CRUZ A J , MURAKAMI K J ,et al. Guide automatic vectorization by means of machine learning:a case study of tensor contraction kernels[J]. IEICE Transactions on Information and Systems, 2016,E99.D(6): 1585-1594. |
| [97] | ZHOU H , XUE J L . A compiler approach for exploiting partial SIMD parallelism[J]. ACM Transactions on Architecture and Code Optimization, 2016,13(1): 1-26. |
| [98] | STOCK K , POUCHET L N , SADAYAPPAN P . Using machine learning to improve automatic vectorization[J]. ACM Transactions on Architecture and Code Optimization, 2012,8(4): 1-23. |
| [99] | POHL A , COSENZA B , JUURLINK B . Vectorization cost modeling for NEON,AVX and SVE[J]. Performance Evaluation, 2020,140/141:102106. |
| [100] | 张媛媛, 赵荣彩, 韩林 . 基于多面体表示的向量化收益评估方法[J]. 计算机工程, 2012,38(7): 266-268,272. |
| ZHANG Y Y , ZHAO R C , HAN L . Vectorization benefit evaluation method based on polyhedron representation[J]. Computer Engineering, 2012,38(7): 266-268,272. | |
| [101] | 杜丽娜, 卓力, 杨硕 ,等. 基于强化学习的移动视频流业务码率自适应算法研究进展[J]. 通信学报, 2021,42(9): 205-217. |
| DU L N , ZHUO L , YANG S ,et al. Survey on reinforcement learning based adaptive bit rate algorithm for mobile video streaming services[J]. Journal on Communications, 2021,42(9): 205-217. |
| [1] | 杜文峰,吴真,赖力潜. 传输延迟感知的多路径并发差异化路径数据分配算法[J]. 通信学报, 2013, 34(4): 18-157. |
| [2] | 杜文峰,吴真,赖力潜. 传输延迟感知的多路径并发差异化路径数据分配算法[J]. 通信学报, 2013, 34(4): 149-157. |
| [3] | 林昭文,王鲲鹏,马严. IPv6入侵检测系统性能优化的研究与实现[J]. 通信学报, 2006, 27(11A): 68-71. |
| [4] | 温涛,王济勇,王晓霞,邹翔. 一个面向嵌入式系统实时性能优化的抢占模型[J]. 通信学报, 2005, 26(9): 129-134. |
| [5] | 岳光荣,李川,李少谦. 超宽带跳时PPM信号在多径环境下的误码率性能优化[J]. 通信学报, 2005, 26(10): 7-12. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||