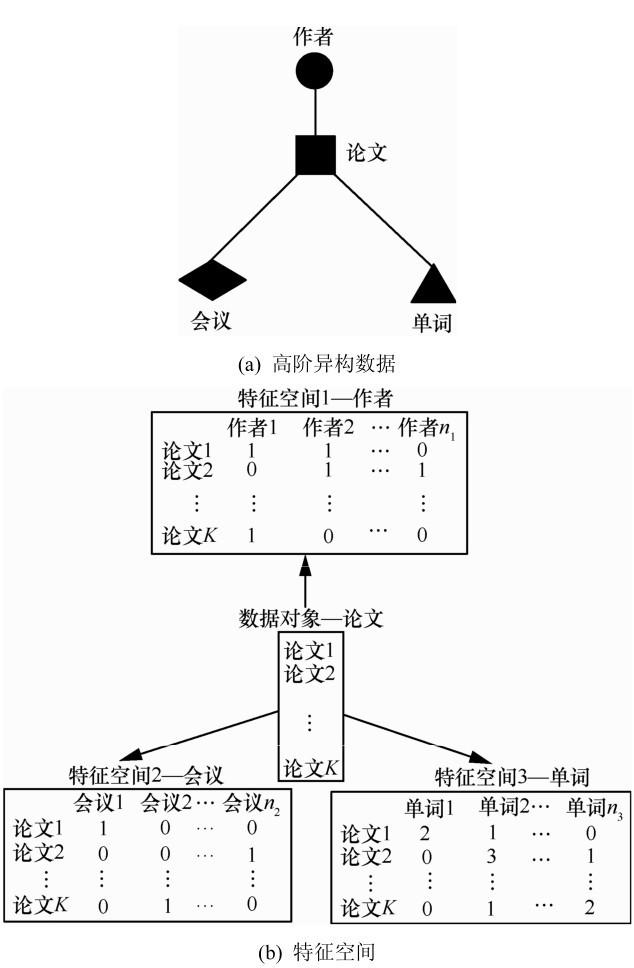
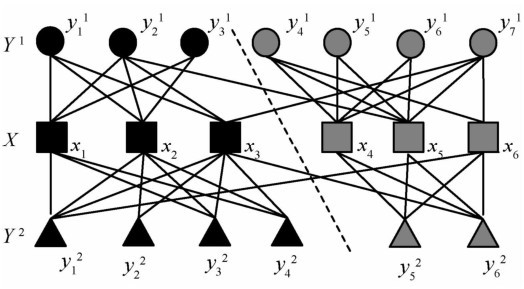
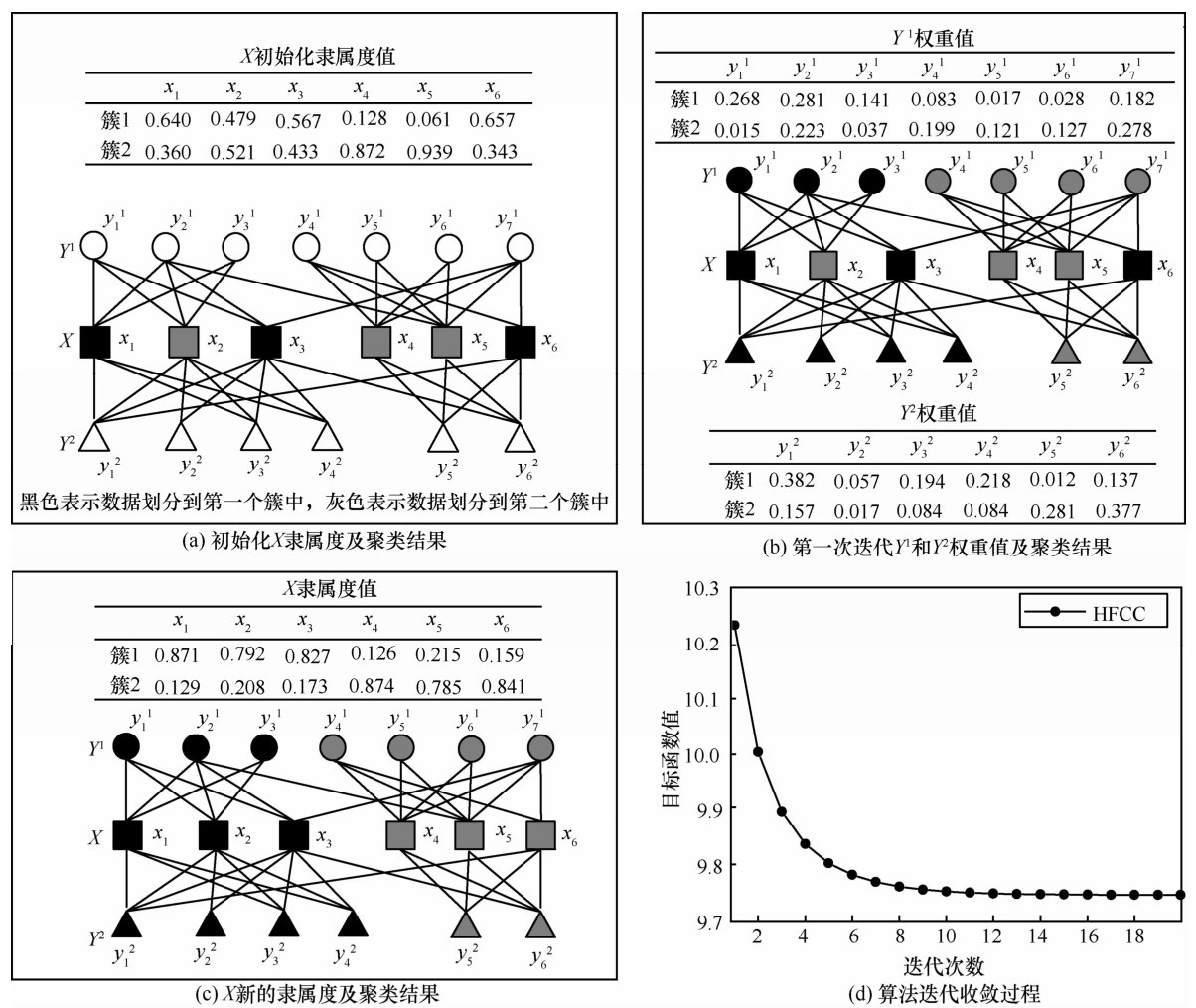
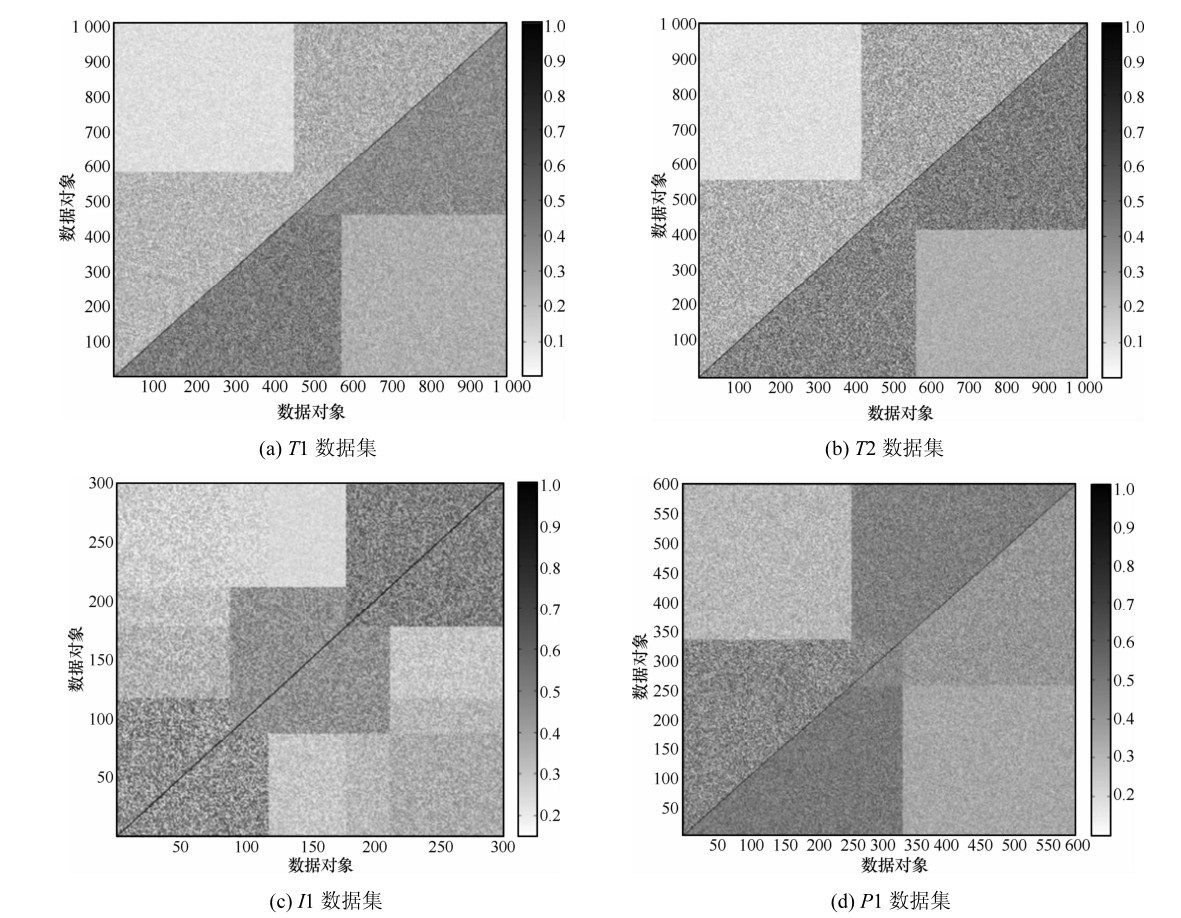
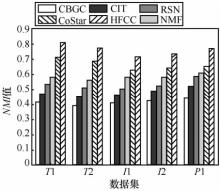
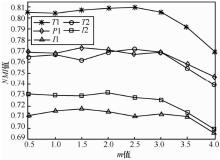
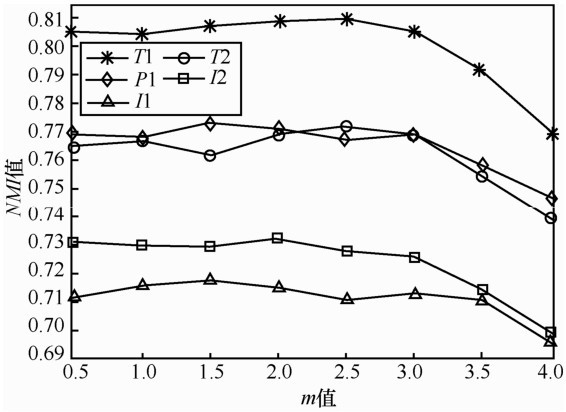
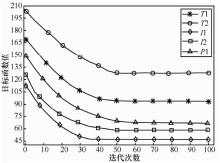
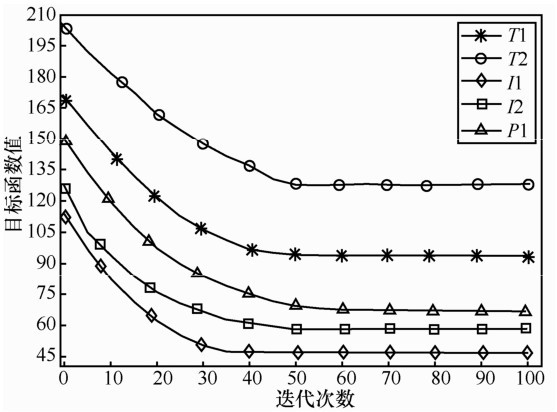
| [1] |
LONG B , WU X Y , ZHANG Z F , et al. Unsupervised learning on k-partite graphs[A]. roceedings of the 12th ACM SIGKDD Interna-tional Conference on Knowledge Discovery and Data Mining[C]. Philadelphia, USA, 2006.317-326.
|
| [2] |
DINO I , ROBARDET C , RUGGERO G , et al. Parameter-less co-clustering for star-structured heterogeneous data[J]. Data Mining and Knowledge Discovery, 2013,26(2): 217-254.
|
| [3] |
周志华, 王珏 . 机器学习及其应用[M]. 北京: 清华大学出版社, 2007. ZHOU Z H , WANG J . Machine Learning and Application[M]. Beijing: Tsinghua University Press, 2007.
|
| [4] |
GAO B , LIU T Y , ZHENG X , et al. Consistent bipartite graph co-partitioning for star-structured high-order heterogeneous data co-clustering[A]. Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining[C]. Chicago, USA, 2005.41-50.
|
| [5] |
GAO B , LIU T Y , MA W Y , et al. Star-structured high-order heterogenous data co-clustering based on consistent information theory[A]. ro-ceedings of the 6th IEEE International Conference on Data Mining[C]. HongKong, China, 2006.880-884.
|
| [6] |
WANG H , NIE F P , HUANG H , et al. Nonnegative matrix tri-factorization based high-order co-clustering and its fast implemen-tation[A]. Proceedings of 11th IEEE International Conference on Data Miningg[C]. Arlington, USA, 2011.174-183.
|
| [7] |
SHAO J , YIN W T , MA S , et al. Topic discovery of Web video using star-structured k-partite graph[A]. PProceedings of the International Conference on Multimedia[C]. Firenze, Italy, 2010.915-918.
|
| [8] |
GAO B , LIU T Y , FENG G , et al. Hierarchical taxonomy preparation for text categorization using consistent bipartite spectral graph co-partitioning[J]. IEEE Transactions on Knowledge and Data Engi-neering, 2005,17(9): 1293-1273.
|
| [9] |
GAO B , LIU T Y , QIN T , et al. Web image clustering by consistent utilization of visual features and surrounding texts[A]. Proceedings of the 13th annual ACM International Conference on Multimedia[C]. Singapore, 2005.112-121.
|
| [10] |
REGE M , DONG M , HUA J . Graph theoretical framework for simul-taneously integrating visual and textual features for efficient Web im-age clustering[A]. Proceedings of the 17th International Conference on World Wide Web[C]. Beijing, China, 2008.317-326.
|
| [11] |
CHIARAVALLOTI A D , GRECO G , GUZZO A , et al. An informa-tion-theoretic framework for high-order co-clustering of heterogene-ous objects[A]. Proceedings of the 17th European Conference on Ma-chine Learning[C]. Berlin, Germany, 2006.598-605.
|
| [12] |
GRECO G , GUZZO A . APONTIERI L.Coclustering multiple heteroge-neous domains: linear combinations and agreements[J]. IEEE Transac-tions on Knowledge and Data Engineering, 2010,22(12): 1649-1663.
|
| [13] |
JING L P , YUN J L , YU J , et al. High-order co-clustering text data on semantics-based representation model[A]. Proceedings of the 15th Pa-cific-Asia Conference on Advance in Knowledge Discovery and Data Mining[C]. Shenzhen, China, 2011.171-182.
|
| [14] |
SUN Y Z , YU Y T , HAN J W . Ranking-based clustering of heteroge-neous information networks with star network schema[A]. Proceed-ings of the 15th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining[C]. Paris, France, 2009.797-805.
|
| [15] |
SUN Y Z , HAN J W , ZHAO P X , et al. RankClus: integrating cluster-ing with ranking for heterogeneous information network analysis[A]. Proceedings of the 12th International Conference on Extending Data-base Technology: Advances in Database Technology[C]. Saint Peters-burg, Russia, 2009.565-576.
|
| [16] |
CHEN Y H , WANG L J , DONG M . Non-negative matrix factorization for semisupervised heterogeneous data coclusteering[J]. IEEE Trans-actions on Knowledge and Data Engineering, 2010,22(10): 1459-1474.
|
| [17] |
XIE X L , BENI G . A validity measure for fuzzy clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1991,13(8): 841-847.
|
| [18] |
PAL N R , BEZDEK J C . On cluster validity for fuzzy c-means model[J]. IEEE Transactions on Fuzzy Systems, 1995,3(3): 370-379.
|
| [19] |
STREHL A , GHOSH J . Cluster ensembles-a knowledge reuse frame-work for combining multiple partitions[J]. Journal of Machine Learn-ing Research, 2002,3(3): 583-617.
|