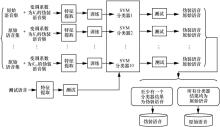
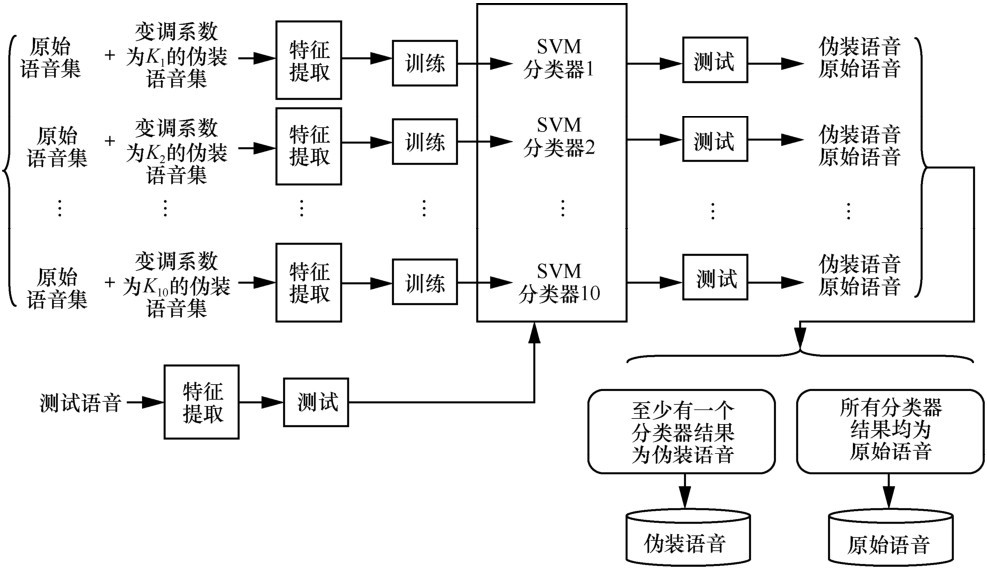
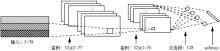
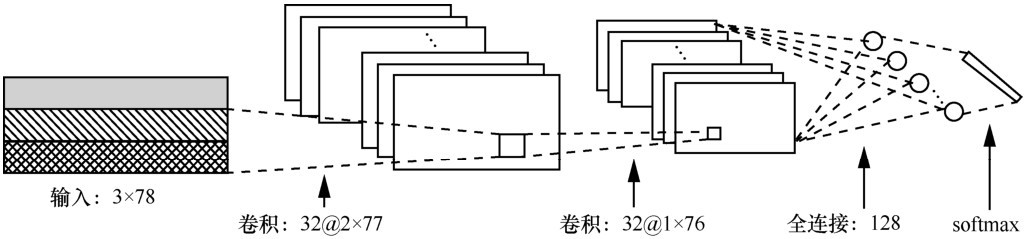
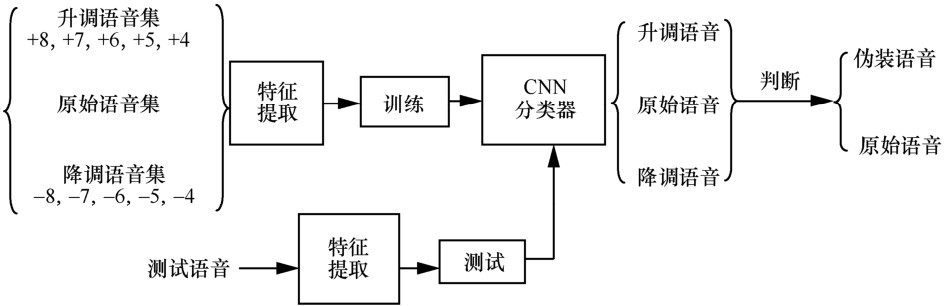
| [1] |
RODMAN R , . Speaker recognition of disguised voices:A program for research[C]// Consortium on Speech Technology in Conjunction with the Conference on Speaker Recognition by Man and Machine:Directions for Forensic Applications,Oct 8-11,1998, Ankara,Turkey.[S.l.:s.n] 1998: 9-22.
|
| [2] |
WU H , WANG Y , HUANG J . Blind detection of electronic disguised voice[C]// 2013 IEEE International Conference on Acoustics,Speech and Signal Processing,May 26-31,2013,Vancouver,Canada. Piscataway:IEEE Press, 2013: 3013-3017.
|
| [3] |
WU H , WANG Y , HUANG J . Identification of electronic disguised voices[J]. IEEE Transactions on Information Forensics and Security, 2014,9(3): 489-500.
|
| [4] |
CAO W , WANG H . Identification of Electronic Disguised Voices in the Noisy Environment[C]// International Workshop on Digital-forensics and Watermarking,Sep 17-19,2016, Beijing China.[S.l.:s.n] 2016: 75-87.
|
| [5] |
ZHENG F , ZHANG G , SONG Z . Comparison of different implementations of MFCC[J]. Journal of Computer science and Technology, 2001,16(6): 582-589.
|
| [6] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[C]// Advances in neural information processing systems,Dec 3-8,2012,Lake Tahoe,USA. New York:ACM Press, 2012: 1097-1105.
|
| [7] |
SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
|
| [8] |
ROUCOS S , WILGUS A . High quality time-scale modification for speech[C]// ICASSP’85:Proceedings of IEEE International Conference on Acoustics,Speech,and Signal Processing,Apri 26-29,1985,Florida,USA. Piscataway:IEEE Press, 1985: 493-496.
|
| [9] |
ZHU X , BEAUREGARD G , WYSE L . Real-time signal estimation from modified short-time Fourier transform magnitude spectra[J]. IEEE Transactions on Audio Speech & Language Processing, 2007,15(5): 1645-1653.
|
| [10] |
Time-scale/pitch modification[EB/OL].(2009-11-24)[201709-27]. .
|
| [11] |
ZHU X , BEAUREGARD G T . Real-time signal estimation from modified short-time Fourier transform magnitude spectra[J]. IEEE Transactions on Audio Speech & Language Processing, 2007,15(5): 1645-1653.
|
| [12] |
TREHUB S E , COHEN A J , THORPE L A . Development of the perception of musical relations:semitone and diatonic structure[J]. Journal of Experimental Psychology Human Perception & Performance, 1986,12(3): 295.
|
| [13] |
Audacity:Free Audio Editor and Recorder[EB/OL].(2016-01-20)[2017-03-27]. .
|
| [14] |
Cool Edit Pro is Now Adobe Audition[EB/OL].(2012-11-08)[2017-03-27]. .
|
| [15] |
LECUN Y , BOTTOU L , BENGIO Y . Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324.
|
| [16] |
SRIVASTAVA N , HINTON G E , KRIZHEVSKY A . Dropout:a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014,15(1): 1929-1958.
|
| [17] |
CHOLLET F . Keras[EB/OL].(2016-09-16)[2016-11-24]. .
|