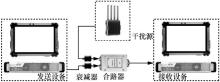
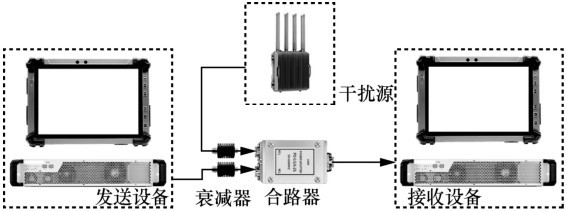
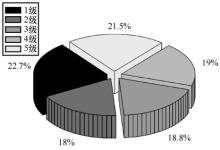
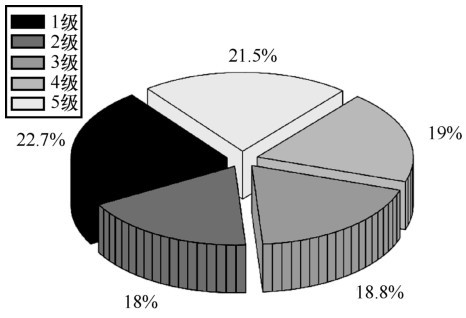
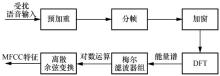
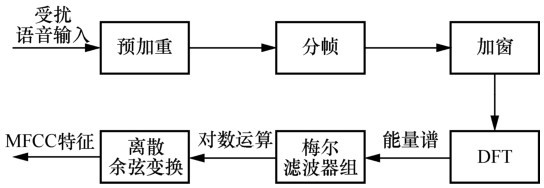
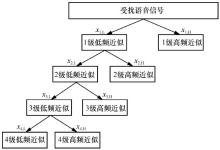
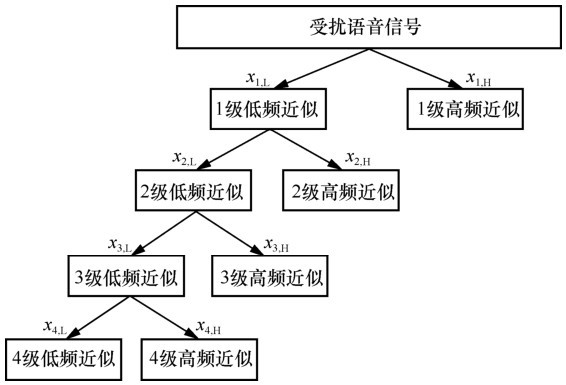
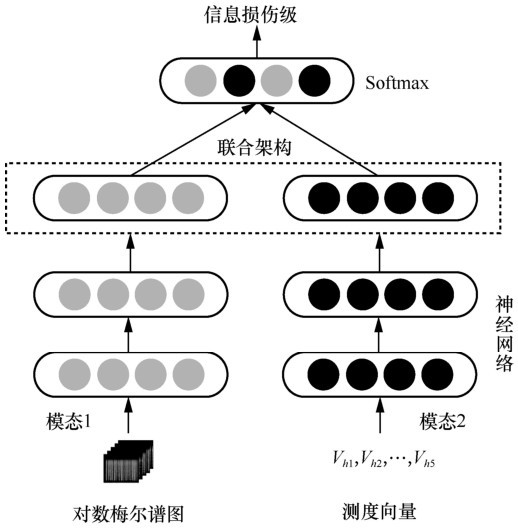
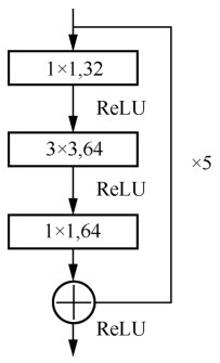
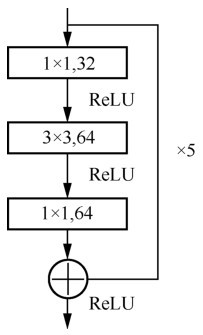
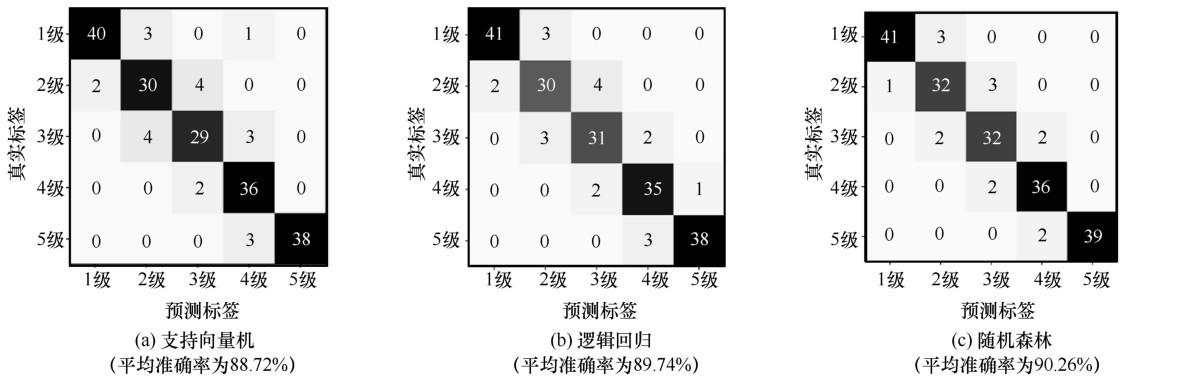
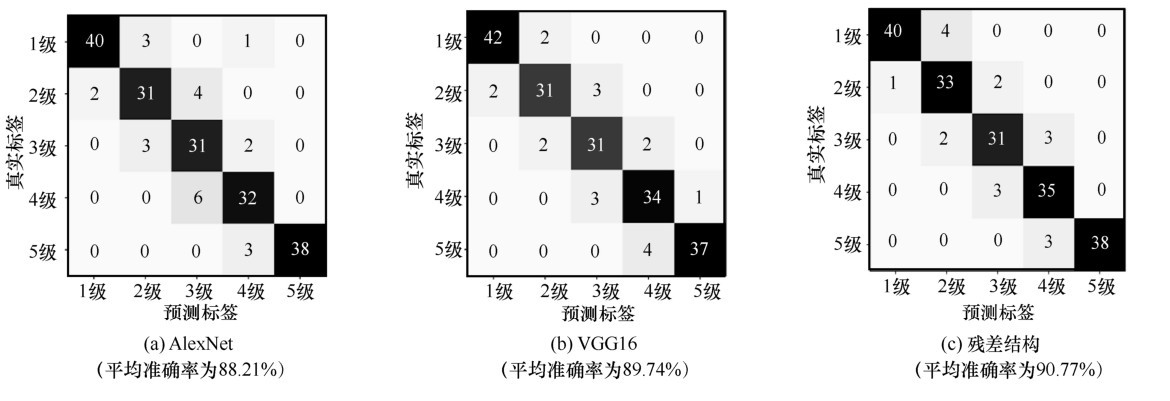
| [1] |
潘志丽, 张宏科, 张思东 . 现代电子干扰理论与效能评估的研究[J]. 通信学报, 2003,24(11): 40-45.
|
|
PAN Z L , ZHANG H K , ZHANG S D . Research on modern electronic jamming theory and efficiency evaluation[J]. Journal of China Institute of Communications, 2003,24(11): 40-45.
|
| [2] |
ITU-T. Mean opinion score(MOS)terminology[S]. 2003.
|
| [3] |
RIX A W , BEERENDS J G , HOLLIER M P ,et al. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs[C]// Proceedings of 2001 IEEE International Conference on Acoustics,Speech,and Signal Processing. Piscataway:IEEE Press, 2002: 749-752.
|
| [4] |
BEERENDS J G , SCHMIDMER C , BERGER J ,et al. Perceptual objective listening quality assessment (POLQA),the third generation ITU-T standard for end-to-end speech quality measurement part I—temporal alignment[J]. Journal of the Audio Engineering Society, 2013,61(6): 366-384.
|
| [5] |
AFFONSO E T , ROSA R L , RODRíGUEZ D Z , . Speech quality assessment over lossy transmission channels using deep belief networks[J]. IEEE Signal Processing Letters, 2018,25(1): 70-74.
|
| [6] |
FU S W , TSAO Y , HWANG H T ,et al. Quality-net:an end-to-end non-intrusive speech quality assessment model based on BLSTM[J]. arXiv Preprint,arXiv:1808.05344, 2018.
|
| [7] |
FU S W , LIAO C F , TSAO Y . Learning with learned loss function:speech enhancement with quality-net to improve perceptual evaluation of speech quality[J]. IEEE Signal Processing Letters, 2020,27: 26-30.
|
| [8] |
RODRíGUEZ D Z , PíVARO G F , ROSA R L ,et al. Improving a parametric model for speech quality assessment in wireless communication systems[C]// Proceedings of 2018 26th International Conference on Software,Telecommunications and Computer Networks. Piscataway:IEEE Press, 2018: 1-5.
|
| [9] |
ITU-T. The E-model:a computational model for use in transmission planning:G.107[S]. 2002.
|
| [10] |
LO C C , FU S W , HUANG W C ,et al. MOSNet:deep learning based objective assessment for voice conversion[J]. arXiv Preprint,arXiv:1904.08352, 2019.
|
| [11] |
ZHANG L , ZHAO X L , LI X . Assessment of extreme communication environment with ultralow SNR:a benchmark[J]. IEEE Access, 2021,9: 45400-45406.
|
| [12] |
WANG S , LIN Y , HAO M ,et al. Interference quality assessment of speech communication based on deep learning[J]. IEEE Transactions on Reliability, 2022,71(2): 1011-1021.
|
| [13] |
HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778.
|
| [14] |
龙华, 杨明亮, 邵玉斌 . 基于特征流融合的带噪语音检测算法[J]. 通信学报, 2020,41(4): 134-142.
|
|
LONG H , YANG M L , SHAO Y B . Noisy voice detection algorithm based on feature stream fusion[J]. Journal on Communications, 2020,41(4): 134-142.
|
| [15] |
张璐琳, 张磊, 赵凌伟 . 语音通信干扰效果评定规则:GJB4405B-2017[S]. 2017.
|
|
ZHANG L L , ZHANG L , ZHAO L W . Speech communication interference effect assessment rules:GJB4405B-2017[S]. 2017.
|
| [16] |
傅恒丰 . 语音通信干扰效果评估方法研究[D]. 哈尔滨:哈尔滨工程大学, 2021.
|
|
FU H F . Research on the evaluation method of speech communication interference effect[D]. Harbin:Harbin Engineering University, 2021.
|
| [17] |
DUBEY R K , KUMAR A . Non-intrusive objective speech quality assessment using a combination of MFCC,PLP and LSF features[C]// Proceedings of 2013 International Conference on Signal Processing and Communication. Piscataway:IEEE Press, 2014: 297-302.
|
| [18] |
张文克 . 融合LPCC和MFCC特征参数的语音识别技术的研究[D]. 湘潭:湘潭大学, 2016.
|
|
ZHANG W K . The research of fusion LPCC and MFCC feature parameters in speech recognition technology[D]. Xiangtan:Xiangtan University, 2016.
|
| [19] |
KEERTHANA Y M , REDDY M K , RAO K S . CWT-based approach for epoch extraction from telephone quality speech[J]. IEEE Signal Processing Letters, 2019,26(8): 1107-1111.
|
| [20] |
杨路飞, 章新华, 吴秉坤 ,等. 基于 MFCC特征的被动水声目标深度学习分类方法[J]. 舰船科学技术, 2020,42(19): 129-133.
|
|
YANG L F , ZHANG X H , WU B K ,et al. Research on the classification method of passive acoustic target depth learning based on MFCC[J]. Ship Science and Technology, 2020,42(19): 129-133.
|
| [21] |
MUDA L , BEGAM M , ELAMVAZUTHI I . Voice recognition algorithms using Mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques[J]. arXiv Preprint,arXiv:1003.4083, 2010.
|
| [22] |
TIN K H . The random subspace method for constructing decision forests[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998,20(8): 832-844.
|
| [23] |
MITTAG G , NADERI B , CHEHADI A ,et al. NISQA:a deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets[J]. arXiv Preprint,arXiv:2104.09494, 2021.
|
| [24] |
YU M , ZHANG C , XU Y ,et al. MetricNet:towards improved modeling for non-intrusive speech quality assessment[J]. arXiv Preprint,arXiv:2104.01227, 2021.
|
| [25] |
张思成, 林云, 涂涯 ,等. 基于轻量级深度神经网络的电磁信号调制识别技术[J]. 通信学报, 2020,41(11): 12-21.
|
|
ZHANG S C , LIN Y , TU Y ,et al. Electromagnetic signal modulation recognition technology based on lightweight deep neural network[J]. Journal on Communications, 2020,41(11): 12-21.
|