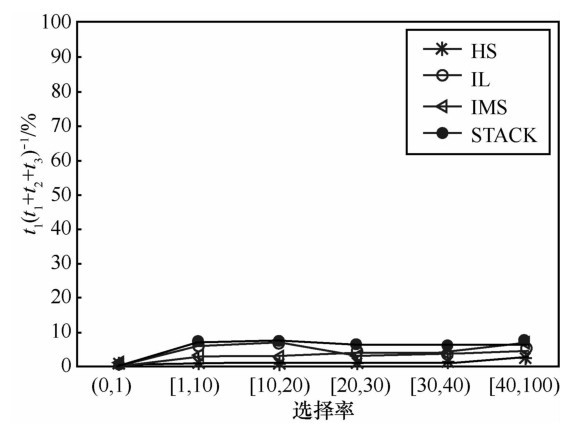
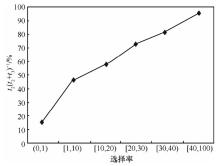
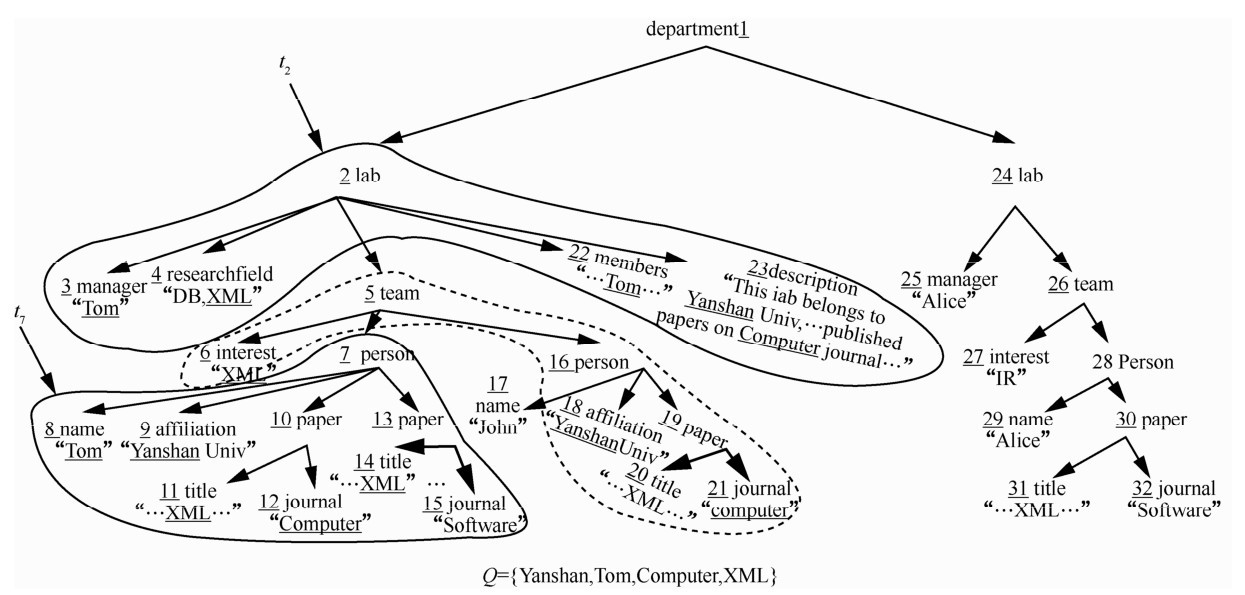
| [1] |
TATARINOV I , VIGLAS S , BEYER K S , et al. Storing and querying ordered XML using a relational database system[A]. SIGMOD Con-ference[C]. 2002. 204-215.
|
| [2] |
GUO L , SHAO F , BOTEV C , et al. Xrank: ranked keyword search over XML documents[A]. SIGMOD Conference[C]. 2003. 16-27.
|
| [3] |
ZHOU RUI , LIU CHENGFEI , LI JIANXIN . Fast elca computation for keyword queries on XML data[A]. International Conference on Ex-tending DB Technology[C]. Lausanne, Switzerland, 2010. 549-560.
|
| [4] |
COHEN S , MAMOU J , KANZA Y , et al. Xsearch: a semantic search engine for XML[A]. VLDB[C]. 2010. 45-56.
|
| [5] |
LI G , FENG J , WANG J , et al. Effective keyword search for valuable lcas over XML documents[A]. CIKM[C]. 2007. 31-40.
|
| [6] |
ZHOU J , BAO Z , CHEN Z , et al. Top-down SLCA computation based on list partition[A]. DASFAA[C]. 2012.
|
| [7] |
WANG W Y , WANG X L , ZHOU A Y . Hash-search: an efficient slca-based keyword search algorithm on XML documents[A]. LNCS 5463[C]. 2009. 496-510.
|
| [8] |
XU Y , PAPAKONSTANTINOU Y . Efficient keyword search for smallest lcas in XML databases[A]. SIGMOD Conference[C]. 2005.
|
| [9] |
SUN C , CHAN C Y , GOENKA A K . Multiway slca-based keyword search in XML data[A]. WWW[C]. 2007. 1043-1052.
|
| [10] |
ZHOU J , BAO Z , WANG W , et al. Fast SLCA and ELCA computation for XML keyword queries based on set intersection[A]. ICDE[C]. 2012.
|
| [11] |
XU Y , PAPAKONSTANTINOU Y . Efficient lca based keyword search in XML data[A]. EDBT[C]. 2008.
|
| [12] |
LIU Z , CHEN Y Reasoning and identifying relevant matches for XML keyword search[A]. PVLDB, 2008. 1(1):921-932.
|
| [13] |
KONG L , GILLERON R , LEMAY A . Retrieving meaningful relaxed tightest fragments for XML keyword search[A]. EDBT[C]. 2009. 815-826.
|
| [14] |
ZHOU J , BAO Z , CHEN Z , et al. Fast result enumeration for keyword queries on XML data[A]. DASFAA[C]. 2012. 95-109.
|
| [15] |
HRISTIDIS V , KOUDAS N , PAPAKONSTANTINOU Y , et al. Key-word proximity search in XML trees[J]. IEEE Trans Knowl Data Eng, 2006,18(4):525-539.
|
| [16] |
TATARINOV I , VIGLAS S , et al. Storing and querying ordered XML using a relational database system[A]. Special Interest Group on Man-agement of Data Conference[C]. Madison, USA, 2002. 204-215.
|
| [17] |
BRODER A Z . A taxonomy of Web search[J]. SIGIR Forum, 2002,36(2):3-10.
|

 ),汤显3
),汤显3