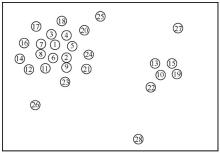
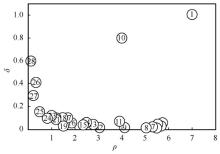
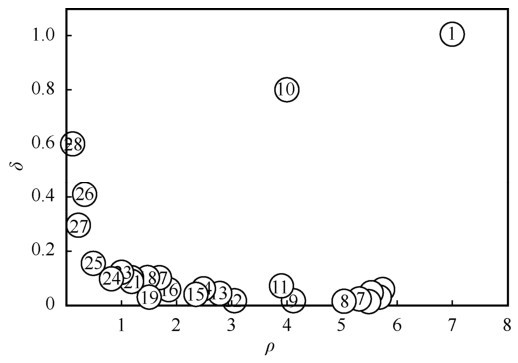
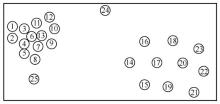
| [1] |
RAMOTSOELA D , ABU-MAHFOUZ A , HANCKE G . A survey of anomaly detection in industrial wireless sensor networks with critical water system infrastructure as a case study[J]. Sensors (Basel,Switzerland), 2018,18(8): 2491.
|
| [2] |
AVDIIENKO V , KUZNETSOV K , ROMMELFANGER I ,et al. Detecting behavior anomalies in graphical user interfaces[C]// Proceedings of IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). Piscataway:IEEE Press, 2017: 201-203.
|
| [3] |
NGAI E W T , HU Y , WONG Y H ,et al. The application of data mining techniques in financial fraud detection:a classification framework and an academic review of literature[J]. Decision Support Systems, 2011,50(3): 559-569.
|
| [4] |
季一木, 杨卫东, 李奎 ,等. 基于主机系统调用频率的容器入侵检测方法[J]. 网络与信息安全学报, 2021,7(4): 18-29.
|
|
JI Y M , YANG W D , LI K ,et al. Container intrusion detection method based on host system call frequency[J]. Chinese Journal of Network and Information Security, 2021,7(4): 18-29.
|
| [5] |
ANDRYSIAK T . Sparse representation and overcomplete dictionary learning for anomaly detection in electrocardiograms[J]. Neural Computing and Applications, 2020,32(5): 1269-1285.
|
| [6] |
ROUSSEEUW P J , LEROY A M . Robust regression and outlier detection[M]. New Jersey: John Wiley & Sons, 1987.
|
| [7] |
BARNETT V , LEWIS T , ABELES F . Outliers in statistical data[M]. New Jersey: John Wiley & Sons, 1994.
|
| [8] |
KNORR E M , NG R T , TUCAKOV V . Distance-based outliers:algorithms and applications[J]. The VLDB Journal, 2000,8(3/4): 237-253.
|
| [9] |
KNORR E M , NG R T . A unified approach for mining outliers:properties and computation[C]// Proceedings of Conference of the Centre for Advanced Studies on Collaborative Research.[S.n.:s.l.], 1997: 219-222.
|
| [10] |
JAIN A K , MURTY M N , FLYNN P J . Data clustering[J]. ACM Computing Surveys, 1999,31(3): 264-323.
|
| [11] |
ESTER M , KRIEGEL H , SANDER J ,et al. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]// International Conference on Knowledge Discovery & Data Mining. New York:ACM Press, 1996: 226-231.
|
| [12] |
KARYPIS G , HAN E H , KUMAR V . Chameleon:hierarchical clustering using dynamic modeling[J]. Computer, 1999,32(8): 68-75.
|
| [13] |
BREUNIG M M , KRIEGEL H P , NG R T ,et al. LOF:identifying density-based local outliers[C]// Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data. New York:ACM Press, 2000: 93-104.
|
| [14] |
杨晓晖, 刘晓明 . 基于双向邻居修正的局部异常因子算法[J]. 通信学报, 2020,41(8): 130-140.
|
|
YANG X H , LIU X M . Local outlier factor algorithm based on correction of bidirectional neighbor[J]. Journal on Communications, 2020,41(8): 130-140.
|
| [15] |
ZHANG K , HUTTER M , JIN H D . A new local distance-based outlier detection approach for scattered real-world data[C]// Advances in Knowledge Discovery and Data Mining. Berlin:Springer, 2009: 813-822.
|
| [16] |
WANG L N , FENG C , REN Y J ,et al. Local outlier detection based on information entropy weighting[J]. International Journal of SensorNetworks, 2019,30(4): 207.
|
| [17] |
SCHUBERT E , ZIMEK A , KRIEGEL H P . Generalized outlier detection with flexible kernel density estimates[C]// Proceedings of the 2014 SIAM International Conference on Data Mining.[S.n.:s.l.], 2014: 542-550.
|
| [18] |
WAHID A , ANNAVARAPU C S R . NaNOD:a natural neigh-bour-based outlier detection algorithm[J]. Neural Computing and Applications, 2021,33(6): 2107-2123.
|
| [19] |
RODRIGUEZ A , LAIO A . Clustering by fast search and find of density peaks[J]. Science, 2014,344(6191): 1492-1496.
|
| [20] |
XU X , DING S F , DU M J ,et al. DPCG:an efficient density peaks clustering algorithm based on grid[J]. International Journal of Machine Learning and Cybernetics, 2018,9(5): 743-754.
|
| [21] |
HUANG J L , ZHU Q S , YANG L J ,et al. A non-parameter outlier detection algorithm based on natural neighbor[J]. Knowledge-Based Systems, 2016,92: 71-77.
|
| [22] |
MACQUEEN J , . Some methods for classification and analysis of multivariate observations[C]// Proceedings of Berkeley Symposium on Mathematical Statistics & Probability. Berkeley:University of California Press, 1967: 281-297.
|
| [23] |
ESTER M , KRIEGEL H , SANDER J ,et al. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]// International Conference on Knowledge Discovery & Data Mining. New York:ACM Press, 1996: 226-231.
|
| [24] |
COMANICIU D , MEER P . MeanShift:a robust approach toward feature space analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002,24(5): 603-619.
|
| [25] |
DANG T T , NGAN H Y T , LIU W . Distance-based k-nearest neighbors outlier detection method in large-scale traffic data[C]// Proceedings of IEEE International Conference on Digital Signal Processing. Piscataway:IEEE Press, 2015: 507-510.
|
| [26] |
TANG J , CHEN Z X , FU A W C ,et al. Enhancing effectiveness of outlier detections for low density patterns[C]// Advances in Knowledge Discovery and Data Mining. Berlin:Springer, 2002: 535-548.
|
| [27] |
TANG B , HE H B . A local density-based approach for outlier detection[J]. Neurocomputing, 2017,241: 171-180.
|
| [28] |
LATECKI L J , LAZAREVIC A , POKRAJAC D . Outlier detection with kernel density functions[C]// Machine Learning and Data Mining in Pattern Recognition. Berlin:Springer, 2007: 61-75.
|
| [29] |
LIU F T , TING K M , ZHOU Z H . Isolation-based anomaly detection[J]. ACM Transactions on Knowledge Discovery from Data, 2012,6(1): 1-39.
|
| [30] |
WAHID A , ANNAVARAPU C S R . NaNOD:a natural neighbour-based outlier detection algorithm[J]. Neural Computing and Applications, 2021,33(6): 2107-2123.
|
| [31] |
YANG J W , RAHARDJA S , FR?NTI P , . Mean-shift outlier detection and filtering[J]. Pattern Recognition, 2021,115:107874.
|
| [32] |
FRANK A , ASUNCION A . UCI machine learning repository[R]. 2010.
|