

Journal on Communications ›› 2014, Vol. 35 ›› Issue (7): 46-55.doi: 10.3969/j.issn.1000-436x.2014.07.006
• paperⅡ • Previous Articles Next Articles
HENZi-yang C1,2,ANGXuan W1,2( ),ANGXian T3
),ANGXian T3
Online:2014-07-25
Published:2017-06-24
Supported by:HENZi-yang C,ANGXuan W,ANGXian T. Efficiently computing RKN for keyword queries on XML data[J]. Journal on Communications, 2014, 35(7): 46-55.

"
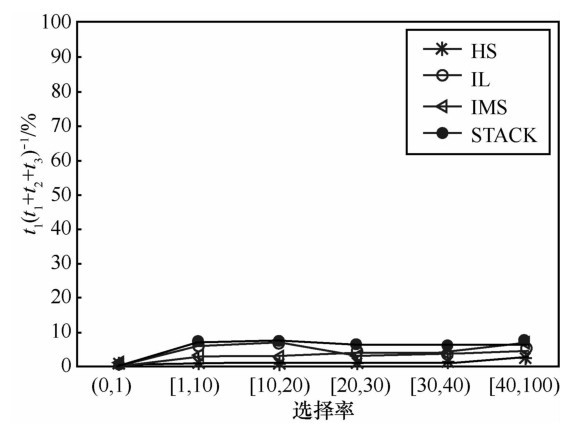
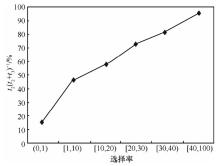
"

"
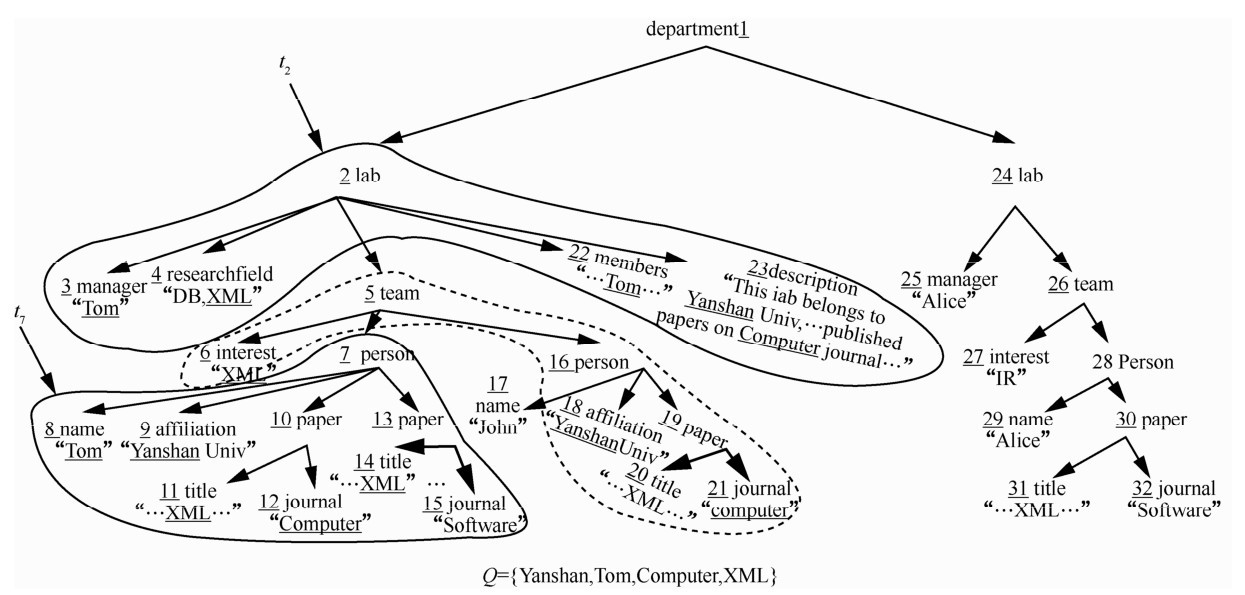
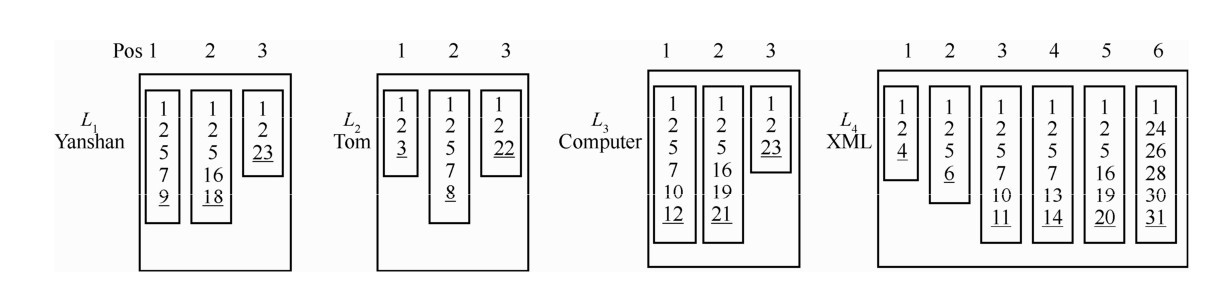
"
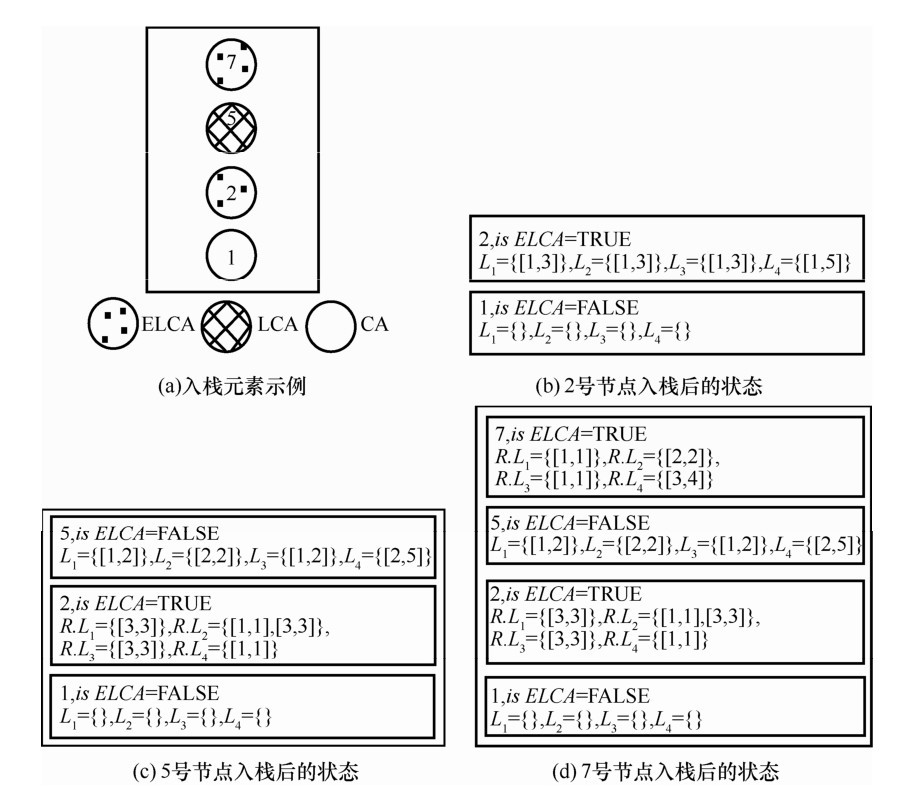
"
"
ID | Keywords | | |Lmax| | |Lmin| | NE | RE/% | Group |
Q1 | bidder, incategory | 710 593 | 411 575 | 299 018 | 1 | 0.0003 | Group1 |
Q2 | bidder, text | 827 825 | 528 807 | 299 018 | 54 200 | 18.13 | |
Q3 | listitem, bold | 675 087 | 370 118 | 304 969 | 117 933 | 38.67 | |
Q4 | bidder, listitem, incategory | 1 015 562 | 411 575 | 299 018 | 1 | 0.0003 | Group2 |
Q5 | bidder, date, emph | 1 106 809 | 457 231 | 299 018 | 29 089 | 9.73 | |
Q6 | check, listitem, keyword | 693 390 | 352 121 | 36 300 | 11 552 | 31.82 | |
Q7 | bidder, listitem, date, incategory | 1 472 793 | 457 231 | 299 018 | 1 | 0.0003 | Group3 |
Q8 | check, listitem, keyword, date | 1 150 621 | 457 231 | 36 300 | 8 087 | 22.28 | |
Q9 | takano, keyword, bold, emph | 1 089 928 | 370 118 | 17 129 | 6 448 | 37.64 | |
Q10 | bidder, text, time, date, incategory | 2 009 949 | 528 807 | 299 018 | 1 | 0.0003 | Group4 |
Q11 | order, keyword, text, emph, increase | 1 552 894 | 528 807 | 16 700 | 1 918 | 11.49 | |
Q12 | check, keyword, bold, text, date | 1 744 577 | 528 807 | 36 300 | 16 204 | 44.64 |
"
查询ID | TB/ms | TO/ms | Re/% |
Q1 | 1 248 | 0.1 | 0.008 |
Q2 | 18 018 | 17 845 | 99.039 |
Q3 | 63 274 | 68 672 | 108.531 |
Q4 | 2 106 | 0.1 | 0.0047 |
Q5 | 3 978 | 3 588 | 90.196 |
Q6 | 1 279 | 1 124 | 87.881 |
Q7 | 4 227 | 0.1 | 0.002 |
Q8 | 1 841 | 499 | 27.104 |
Q9 | 1 592 | 437 | 27.449 |
Q10 | 7 895 | 0. 047 | 0.000 6 |
Q11 | 2 402 | 125 | 5.203 |
Q12 | 3 728 | 1 779 | 47.719 |
"
查询ID | NB×103 | NO×103 | Ne/% |
Q1 | 2 543 | 0.04 | 0.0015 73 |
Q2 | 1 495 939 | 1 471 036 | 98.335 29 |
Q3 | 3 501 520 | 3 492 110 | 99.731 26 |
Q4 | 4 551 | 0.06 | 0.0013 18 |
Q5 | 247 065 | 213 349 | 86.353 39 |
Q6 | 54 119 | 34 976 | 64.627 95 |
Q7 | 7 910 | 0.08 | 0.001 011 |
Q8 | 51 528 | 17 030 | 33.049 99 |
Q9 | 38 391 | 7 768 | 20.233 91 |
Q10 | 12 751 | 0.101 | 0.000 792 |
Q11 | 42 979 | 1 225 | 2.850 229 |
Q12 | 124 417 | 67 445 | 54.208 83 |
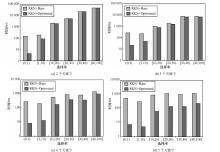
"
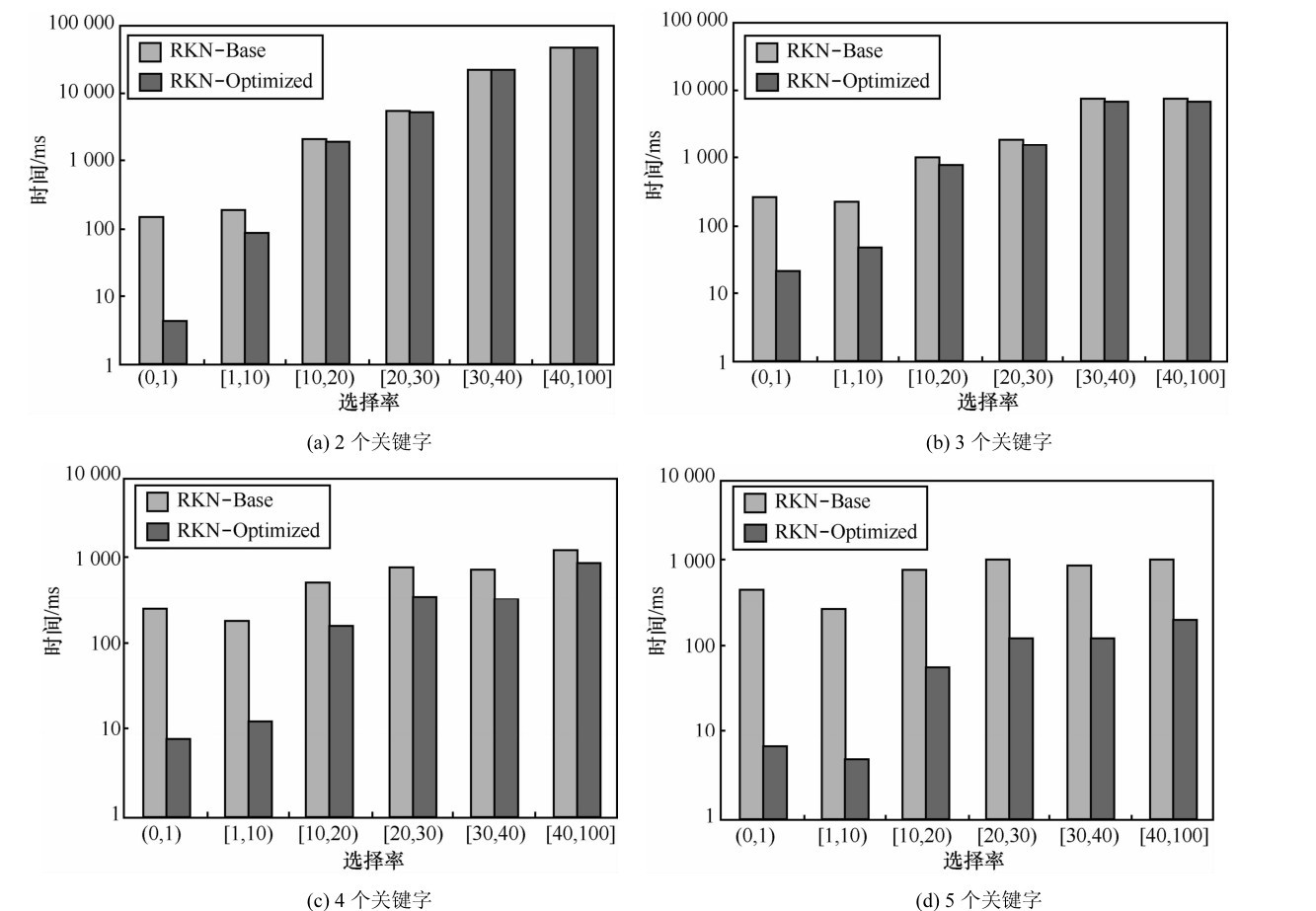
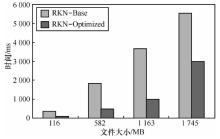
"

"
ID | Keywords | NE |
Q1 | article,book | 1 456 |
Q2 | algorithm,article | 18 349 |
Q3 | data,article | 26 611 |
Q4 | article,database | 5 753 |
Q5 | XML,article | 1 033 |
Q6 | year,2001 | 59 355 |
Q7 | book,article,mining | 6 |
Q8 | algorithm,article,2001 | 521 |
Q9 | article,data,mining | 1 563 |
Q10 | data,XML,article | 209 |
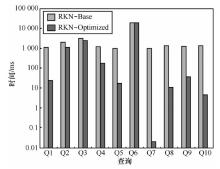
"
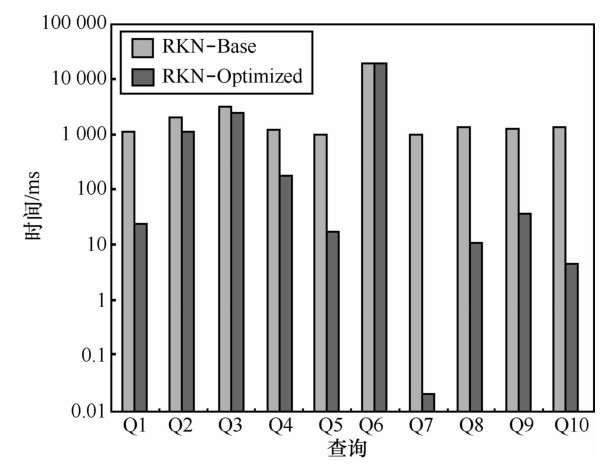
| [1] | TATARINOV I , VIGLAS S , BEYER K S , et al. Storing and querying ordered XML using a relational database system[A]. SIGMOD Con-ference[C]. 2002. 204-215. |
| [2] | GUO L , SHAO F , BOTEV C , et al. Xrank: ranked keyword search over XML documents[A]. SIGMOD Conference[C]. 2003. 16-27. |
| [3] | ZHOU RUI , LIU CHENGFEI , LI JIANXIN . Fast elca computation for keyword queries on XML data[A]. International Conference on Ex-tending DB Technology[C]. Lausanne, Switzerland, 2010. 549-560. |
| [4] | COHEN S , MAMOU J , KANZA Y , et al. Xsearch: a semantic search engine for XML[A]. VLDB[C]. 2010. 45-56. |
| [5] | LI G , FENG J , WANG J , et al. Effective keyword search for valuable lcas over XML documents[A]. CIKM[C]. 2007. 31-40. |
| [6] | ZHOU J , BAO Z , CHEN Z , et al. Top-down SLCA computation based on list partition[A]. DASFAA[C]. 2012. |
| [7] | WANG W Y , WANG X L , ZHOU A Y . Hash-search: an efficient slca-based keyword search algorithm on XML documents[A]. LNCS 5463[C]. 2009. 496-510. |
| [8] | XU Y , PAPAKONSTANTINOU Y . Efficient keyword search for smallest lcas in XML databases[A]. SIGMOD Conference[C]. 2005. |
| [9] | SUN C , CHAN C Y , GOENKA A K . Multiway slca-based keyword search in XML data[A]. WWW[C]. 2007. 1043-1052. |
| [10] | ZHOU J , BAO Z , WANG W , et al. Fast SLCA and ELCA computation for XML keyword queries based on set intersection[A]. ICDE[C]. 2012. |
| [11] | XU Y , PAPAKONSTANTINOU Y . Efficient lca based keyword search in XML data[A]. EDBT[C]. 2008. |
| [12] | LIU Z , CHEN Y Reasoning and identifying relevant matches for XML keyword search[A]. PVLDB, 2008. 1(1):921-932. |
| [13] | KONG L , GILLERON R , LEMAY A . Retrieving meaningful relaxed tightest fragments for XML keyword search[A]. EDBT[C]. 2009. 815-826. |
| [14] | ZHOU J , BAO Z , CHEN Z , et al. Fast result enumeration for keyword queries on XML data[A]. DASFAA[C]. 2012. 95-109. |
| [15] | HRISTIDIS V , KOUDAS N , PAPAKONSTANTINOU Y , et al. Key-word proximity search in XML trees[J]. IEEE Trans Knowl Data Eng, 2006,18(4):525-539. |
| [16] | TATARINOV I , VIGLAS S , et al. Storing and querying ordered XML using a relational database system[A]. Special Interest Group on Man-agement of Data Conference[C]. Madison, USA, 2002. 204-215. |
| [17] | BRODER A Z . A taxonomy of Web search[J]. SIGIR Forum, 2002,36(2):3-10. |
| [1] | . Efficiently computing RKN for keyword queries on XML data [J]. Journal on Communications, 2014, 35(7): 6-55. |
| [2] | Mang SU,Guo-zhen SHI,Feng-hua LI,Ying SHEN,Qiong HUANG,Miao-miao WANG. Fine-grained description model and implementation of hypermedia document [J]. Journal on Communications, 2013, 34(Z1): 223-229. |
| [3] | . Fine-grained description model and implementation of hypermedia document [J]. Journal on Communications, 2013, 34(Z1): 29-229. |
| [4] | Hong-yu YANG,Jin-bo YU,Li-xia XIE. Three-dimensional spherical model based XML communication protocols security evaluation method [J]. Journal on Communications, 2013, 34(3): 183-191. |
| [5] | . DeweyTP: a labeling scheme for probabilistic XML data [J]. Journal on Communications, 2013, 34(11): 4-32. |
| [6] | Zi-yang CHEN,Jia LIU,Liu-hui ZHANG,Jun-feng ZHOU. DeweyTP: a labeling scheme for probabilistic XML data [J]. Journal on Communications, 2013, 34(11): 26-32. |
| [7] | Mang SU,Feng-hua LI,Guo-zhen SHI,Li LI. Representation model of structured document for multilevel security [J]. Journal on Communications, 2012, 33(Z1): 222-227. |
| [8] | Xing-hua LI,Shuai-tuan LI,Deng LI,Jian-feng MA. Multi-language oriented automatic realization method for cryptographic protocols [J]. Journal on Communications, 2012, 33(9): 152-159. |
| [9] | Xiong-fei LI,Tao SUN,Jian-fang GUO. Rough set model based on the labelled tree [J]. Journal on Communications, 2010, 31(6): 35-43. |
| [10] | Ruo-tong WANG,Hui ZHANG,Jia-hai YANG,Gui-fen HUANG. Design and implementation of the information model of a P2P-based network management system [J]. Journal on Communications, 2010, 31(1): 85-91. |
| [11] | Bo LIU,Lu-ming YANG,Xue-min ZHAI,Yun-long DENG. Parallel XML documents placement algorithm based on adaptive ant clustering of chaos [J]. Journal on Communications, 2008, 29(3A): 63-69. |
| [12] | Bo JING,ONGJing D,HIMei-lin2 S. Study on a service-oriented platform for business process orchestration and integration [J]. Journal on Communications, 2006, 27(11): 19-23. |
| [13] | Ya-hua CHEN,Shi-lin WU. Framework of workflow-based telecom enterprise application integration [J]. Journal on Communications, 2005, 26(4): 105-111. |
| [14] | Li-bing WU,Chan-le WU,Jian-qun CUI. Structure the model of network elements in the network management software [J]. Journal on Communications, 2005, 26(1A): 81-85. |
| [15] | Zhen-yu LU,Qiao GUO,Li WANG,Si-bo WANG. XML-based extensible topology discovery [J]. Journal on Communications, 2005, 26(1A): 86-90. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||