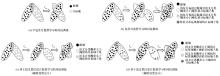
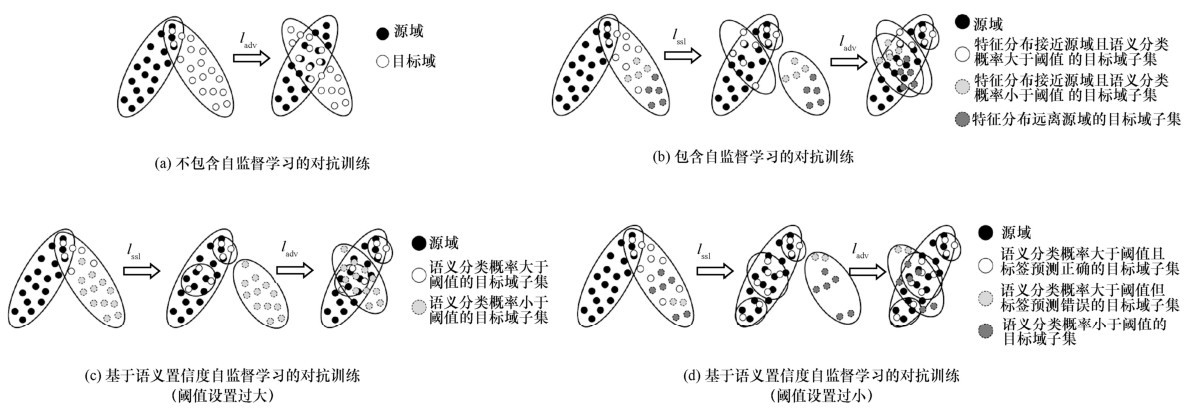
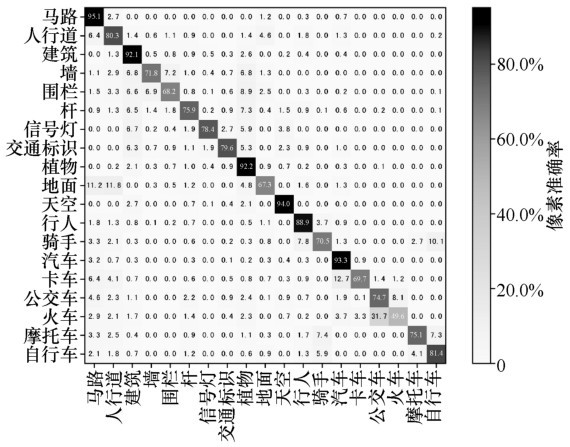
| [1] |
徐英姿, 刘原, 时梦然 ,等. 语义在通信中的应用综述[J]. 电信科学, 2022,38(Z1): 43-59.
|
|
XU Y Z , LIU Y , SHI M R ,et al. A survey of semantic applications in communications[J]. Telecommunications Science, 2022,38(Z1): 43-59.
|
| [2] |
AGIA C , JATAVALLABHULA K M , KHODEIR M ,et al. Taskography:evaluating robot task planning over large 3D scene graphs[C]// Proceedings of Conference on Robot Learning. Cambridge:JMLR, 2022: 46-58.
|
| [3] |
CAESAR H , BANKITI V , LANG A H ,et al. nuScenes:a multimodal dataset for autonomous driving[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11621-11631.
|
| [4] |
YU C , LIU Z X , LIU X J ,et al. DS-SLAM:a semantic visual SLAM towards dynamic environments[C]// Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway:IEEE Press, 2018: 1168-1174.
|
| [5] |
HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778.
|
| [6] |
LI Z , GAN Y , LIANG X ,et al. LSTM-CF:unifying context modeling and fusion with LSTMS for RGB-D scene labeling[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2016: 541-557.
|
| [7] |
YUAN Y H , CHEN X L , WANG J D . Object-contextual representations for semantic segmentation[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2020: 173-190.
|
| [8] |
RADFORD A , METZ L , CHINTALA S . Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv Preprint,arXiv:1511.06434, 2015.
|
| [9] |
HOFFMAN J , WANG D , YU F ,et al. FCNs in the wild:Pixel-level adversarial and constraint-based adaptation[J]. arXiv Preprint,arXiv:1612.02649, 2016.
|
| [10] |
TSAI Y H , HUNG W C , SCHULTER S ,et al. Learning to adapt structured output space for semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 7472-7481.
|
| [11] |
ZHU J Y , PARK T , ISOLA P ,et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]// Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2017: 2223-2232.
|
| [12] |
LI Z Y , TOGO R , OGAWA T ,et al. Learning intra-domain style-invariant representation for unsupervised domain adaptation of semantic segmentation[J]. Pattern Recognition, 2022,132(12): 108911.
|
| [13] |
LI Y S , YUAN L , VASCONCELOS N . Bidirectional learning for domain adaptation of semantic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2019: 6936-6945.
|
| [14] |
YANG J , AN W , WANG S ,et al. Label-driven reconstruction for domain adaptation in semantic segmentation[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2020: 480-498.
|
| [15] |
CHENG Y , WEI F , BAO J ,et al. Dual path learning for domain adaptation of semantic segmentation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2021: 9082-9091.
|
| [16] |
LEE S , HYUN J , SEONG H ,et al. Unsupervised domain adaptation for semantic segmentation by content transfer[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2021: 8306-8315.
|
| [17] |
SHIN I , WOO S , PAN F ,et al. Two-phase pseudo label densification for self-training based domain adaptation[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2020: 532-548.
|
| [18] |
PAN F , SHIN I , RAMEAU F ,et al. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 3764-3773.
|
| [19] |
PENG C L , MA J Y . Domain adaptive semantic segmentation via entropy-ranking and uncertain learning-based self-training[J]. IEEE/CAA Journal of Automatica Sinica, 2022,9(8): 1524-1527.
|
| [20] |
YANG J , AN W , YAN C ,et al. Context-aware domain adaptation in semantic segmentation[C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway:IEEE Press, 2021: 514-524.
|
| [21] |
HUANG J , LU S , GUAN D ,et al. Contextual-relation consistent domain adaptation for semantic segmentation[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2020: 705-722.
|
| [22] |
RICHTER S R , VINEET V , ROTH S ,et al. Playing for data:ground truth from computer games[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2016: 102-118.
|
| [23] |
ROS G , SELLART L , MATERZYNSKA J ,et al. The SYNTHIA dataset:a large collection of synthetic images for semantic segmentation of urban scenes[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 3234-3243.
|
| [24] |
CORDTS M , OMRAN M , RAMOS S ,et al. The cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 3213-3223.
|
| [25] |
SONG S R , LICHTENBERG S P , XIAO J X . SUN RGB-D:a RGB-D scene understanding benchmark suite[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2015: 567-576.
|
| [26] |
SILBERMAN N , HOIEM D , KOHLI P ,et al. Indoor segmentation and support inference from RGBD images[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2012: 746-760.
|
| [27] |
PASZKE A , GROSS S , MASSA F ,et al. PyTorch:an imperative style,high-performance deep learning library[J]. Advances in Neural Information Processing Systems, 2019,32(12): 8024-8035.
|
| [28] |
GUO X Q , YANG C , LI B P ,et al. MetaCorrection:domain-aware meta loss correction for unsupervised domain adaptation in semantic segmentation[C]// Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2021: 3926-3935.
|
| [29] |
ARASLANOV N , ROTH S . Self-supervised augmentation consistency for adapting semantic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 15384-15394.
|
| [30] |
JIANG Z K , LI Y X , YANG C Y ,et al. Prototypical contrast adaptation for domain adaptive semantic segmentation[C]// Proceedings of European Conference on Computer Vision. Berlin:Springer, 2022: 36-54.
|
| [31] |
ZHANG F , KOLTUN V , TORR P ,et al. Unsupervised contrastive domain adaptation for semantic segmentation[J]. arXiv Preprint,arXiv:2204.08399, 2022.
|
| [32] |
YANG J Y , LI C Y , AN W Z ,et al. Exploring robustness of unsupervised domain adaptation in semantic segmentation[C]// Proceedings of IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2021: 9174-9183.
|