With the development of intelligent transportation,it has become an urgent problem to quickly and accurately recognize complex traffic scene.In recent years,a large number of scene recognition methods have been proposed to improve the effectiveness of traffic scene recognition,however,most of these algorithms cannot extract the semantic characteristics of the concept of vision,leading to the low recognition accuracy in traffic scenes.Therefore,a novel traffic scene recognition algorithm which extracts the high-level semantic and structural information for improving the accuracy was proposed.A system to discover semantically meaningful descriptions of the scene classes to reduce the “semantic gap” between the high level and the low-level feature representation was built.Then,the multi-label network was trained by minimizing loss function (namely,element-wise logistic loss) to obtain the high-level semantic representation of traffic scene images.Finally,experiments on four large-scale scene recognition datasets show that the proposed algorithm considerably outperforms other state-of-the-art methods.
LIU Wenhua. Transportation scene recognition based on high level feature representation. Chinese Journal of Intelligent Science and Technology[J], 2019, 1(4): 392-399 doi:10.11959/j.issn.2096-6652.201943
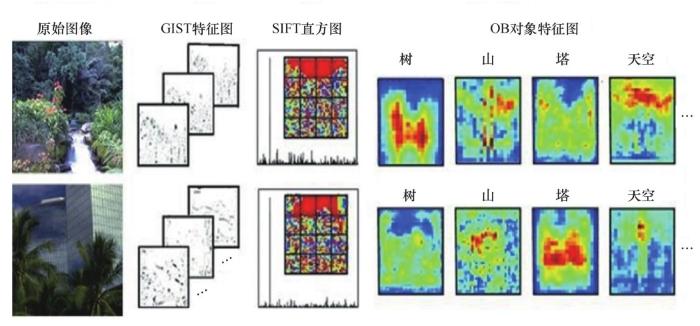
特征表示是场景识别处理任务的第一步,特征表示的效果直接影响识别精度,如何提取具有判别性的特征成为新的研究热点。图像特征中包含的图像信息越多,识别效果越好。目前,许多用于提取图像特征的算法被陆续提出,较为经典的有:基于梯度的GIST(generalized search tree)算子[1],该算子专门用于描述图像空间特征,以估计全局空间特征;基于纹理的尺度不变特征转换(scale-invariant feature transform,SIFT)算子[2],该算子检测尺度空间中的特征,并识别关键点的位置。这两种方法获得的特征是图像的低维统计信息,将低维特征直接进行映射,导致对图像的识别效果差。为解决低维表示直接映射引起的“语义鸿沟”问题, Li 等人[3]提出了一种高层语义表示方法——对象库(OB),它由许多对象特征图构成,对图像对象的语义和空间信息进行编码,图像被表示为通用对象的特征图。图像的 GIST特征图、SPM表示直方图和OB对象特征图具体如图1所示。OB算法表示图像的效果明显优于前两种算法,语义信息更丰富,但 OB 提取的特征中不包含描述性的图像信息。
低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6]。这些算法可解释性强且时间复杂度低,但其表示性能较差。随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等。研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”。为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%。Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%。
高维特征表示方法是由低维特征组合而成的更结构化、更复杂的特征表示方法。比如,经典的OB 算法首先利用目标检测器[12,13,14]获得图像中包含的对象,然后编码对象的语义和空间信息。随后, Hauptmann[15]使用对象到类(O2C)的距离构建场景识别模型,基于对象库的O2C距离的显式计算获得的图像特征更加抽象、复杂。现实世界中的对象具有层次结构概念,这导致基于对象的表示方法可能存在语义层次结构问题,无法同时识别同一张图中的“车”和“汽车”。为了解决语义层次结构问题,使用语义特征作为图像的表示方法,在没有训练图像的情况下,语义特征可用于识别对象类,使用语义特征识别对象类的这一过程被称为zero-short learning。为了获取图像的全局和局部特征,Vogel 等人用图像局部语义与图像全局特征组合来表示图像。Hinton G E等人[16]定义了中级特征,设计了6组特征,并将其作为图像的中层语义描述符。实验表明,图像特征包含的信息越丰富,其识别准确率越高。
Generating image descriptions using dependency relational patterns
1
2010
... 特征表示是场景识别处理任务的第一步,特征表示的效果直接影响识别精度,如何提取具有判别性的特征成为新的研究热点.图像特征中包含的图像信息越多,识别效果越好.目前,许多用于提取图像特征的算法被陆续提出,较为经典的有:基于梯度的GIST(generalized search tree)算子[1],该算子专门用于描述图像空间特征,以估计全局空间特征;基于纹理的尺度不变特征转换(scale-invariant feature transform,SIFT)算子[2],该算子检测尺度空间中的特征,并识别关键点的位置.这两种方法获得的特征是图像的低维统计信息,将低维特征直接进行映射,导致对图像的识别效果差.为解决低维表示直接映射引起的“语义鸿沟”问题, Li 等人[3]提出了一种高层语义表示方法——对象库(OB),它由许多对象特征图构成,对图像对象的语义和空间信息进行编码,图像被表示为通用对象的特征图.图像的 GIST特征图、SPM表示直方图和OB对象特征图具体如图1所示.OB算法表示图像的效果明显优于前两种算法,语义信息更丰富,但 OB 提取的特征中不包含描述性的图像信息. ...
Comparison of classi?cation algorithms to predict outcomes of feedlot cattle identi?ed and treated for bovine respiratory disease
1
2014
... 特征表示是场景识别处理任务的第一步,特征表示的效果直接影响识别精度,如何提取具有判别性的特征成为新的研究热点.图像特征中包含的图像信息越多,识别效果越好.目前,许多用于提取图像特征的算法被陆续提出,较为经典的有:基于梯度的GIST(generalized search tree)算子[1],该算子专门用于描述图像空间特征,以估计全局空间特征;基于纹理的尺度不变特征转换(scale-invariant feature transform,SIFT)算子[2],该算子检测尺度空间中的特征,并识别关键点的位置.这两种方法获得的特征是图像的低维统计信息,将低维特征直接进行映射,导致对图像的识别效果差.为解决低维表示直接映射引起的“语义鸿沟”问题, Li 等人[3]提出了一种高层语义表示方法——对象库(OB),它由许多对象特征图构成,对图像对象的语义和空间信息进行编码,图像被表示为通用对象的特征图.图像的 GIST特征图、SPM表示直方图和OB对象特征图具体如图1所示.OB算法表示图像的效果明显优于前两种算法,语义信息更丰富,但 OB 提取的特征中不包含描述性的图像信息. ...
Shape matching and object recognition using shape contexts
1
2010
... 特征表示是场景识别处理任务的第一步,特征表示的效果直接影响识别精度,如何提取具有判别性的特征成为新的研究热点.图像特征中包含的图像信息越多,识别效果越好.目前,许多用于提取图像特征的算法被陆续提出,较为经典的有:基于梯度的GIST(generalized search tree)算子[1],该算子专门用于描述图像空间特征,以估计全局空间特征;基于纹理的尺度不变特征转换(scale-invariant feature transform,SIFT)算子[2],该算子检测尺度空间中的特征,并识别关键点的位置.这两种方法获得的特征是图像的低维统计信息,将低维特征直接进行映射,导致对图像的识别效果差.为解决低维表示直接映射引起的“语义鸿沟”问题, Li 等人[3]提出了一种高层语义表示方法——对象库(OB),它由许多对象特征图构成,对图像对象的语义和空间信息进行编码,图像被表示为通用对象的特征图.图像的 GIST特征图、SPM表示直方图和OB对象特征图具体如图1所示.OB算法表示图像的效果明显优于前两种算法,语义信息更丰富,但 OB 提取的特征中不包含描述性的图像信息. ...
Hierarchical matching pursuit for image classi?cation:architecture and fast algorithms
1
2012
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
Unsupervised feature learning for aerial sceneclassiTcation
2
2014
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
... [5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
... [6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
Adapted Gaussian models for image classi?cation
1
2011
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
From captions to visual concepts and back
1
2015
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
Every picture tells a story:generating sentences from images
1
2010
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
A Bayesian hierarchical model for learning natural scene categories
1
2005
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...
Object detection with discriminatively trained part-based models
2
2014
... 低维特征表示方法是指从图像纹理、颜色、形状等方面来表示图像[4,5,6].这些算法可解释性强且时间复杂度低,但其表示性能较差.随后,中层特征表示方法被提出,其中被广泛使用的方法有计算图像每个子区域局部特征直方图的 SIFT 空间金字塔算法[5]、词袋(bag of words)模型[6]、提取图像结构特征的视觉描述符算法[7]等.研究发现,图像中低维特征的直接映射可能会引起更大的“语义鸿沟”.为此,Fang H[8]、Farhadi A[9]、Li F F[10]等人提出了从低维特征表示中学习高维语义的学习模型,获得了优异的识别性能,在Sports数据集上取得的识别准确率分别为84.4%、84.92%和85.7%.Felzenszwalb P F[11]提出了一种基于多种特征的混合特征提取方法,该方法在MIT-Indoor数据集上的识别精度达到了43.1%. ...














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}