The National Natural Science Foundation of China. 61673229 The National Natural Science Foundation of China. 62073182 National Key Research and De-velopment Program of China. 2017YFC0704100 National Key Research and De-velopment Program of China. 2016YFB0901900 111 International Collaboration Project. BP2018006
It is of significant social and economical impact to achieve green and reliable operation of data center.The optimization and control methods for green and reliable data center were reviewed briefly.An event-based reinforcement learning approach for improving the energy efficiency was developed.And a method to improve the accuracy of battery lifetime forecasting was developed.
Keywords:data center
;
cyber physical energy system
;
reinforcement learning
;
event-based optimization
JIA Qing-Shan. Reinforcement learning for green and reliable data center. Chinese Journal of Intelligent Science and Technology[J], 2020, 2(4): 341-347 doi:10.11959/j.issn.2096-6652.202036
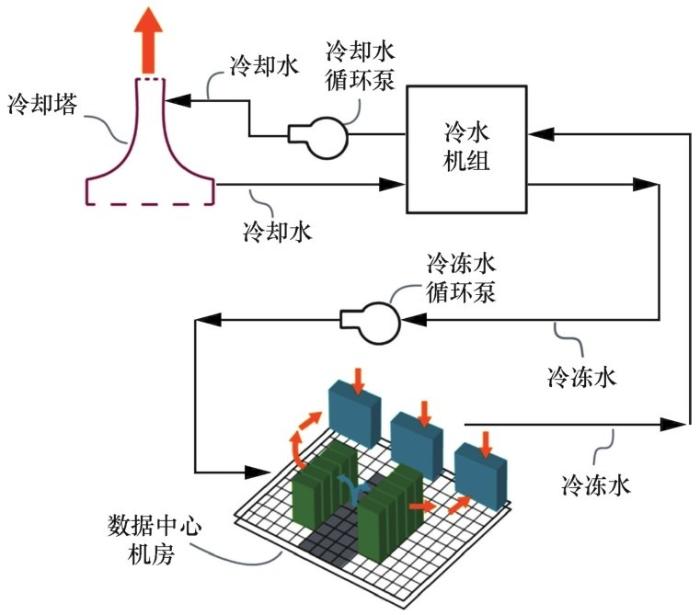
数据中心的运行节能面临多方面挑战。第一,高维信息。现代数据中心一般部署了大量传感器,传感器定期监测数据中心机柜的温度场分布、制冷系统的冷冻水水温与水流量等信息,并汇聚到大数据运行平台。高维海量数据中的信息方差小,为决策优化带来了挑战。第二,耦合动态过程。大型数据中心一般由多栋建筑物构成,建筑面积达到上万平方米,甚至更大。数据中心的发展呈现出模块化趋势,在每个模块化数据中心(modularized data center,MDC)内,由冷热通道将机柜群分隔,机柜整齐排列在通道两侧。冷热通道之间的空气流动相对独立,各机柜内的温度场分布受服务器所承载的计算任务影响,动态变化,关联耦合。这一复杂的动态过程虽有机理模型,但是精细的性能评价仍需基于仿真模拟甚至物理实验。制冷系统的循环过程也需仿真模拟方可评价控制策略的性能,这导致对策略性能的评价非常耗费时间。第三,计算业务的需求随机波动。数据中心支撑的计算任务种类丰富、差异明显,计算业务的需求量具有明显的随机波动性,难以精准预测。因而对制冷系统的控制策略和对计算作业的调度策略的性能评价,一般需要多次仿真、多次实验取均值才能获得较为精确的评价。这使得策略性能评价耗费了大量的时间与代价。如何在上述挑战下实现数据中心的运行节能是一项重大挑战。
作为基础设施,数据中心运行的稳定性与可靠性至关重要。为保障电源供应的稳定,数据中心一般配有备用发电机(柴油发电机、氢能源发电机等)及不间断电源(uninterruptible power supply,UPS)。UPS的核心构件是电池。数据中心一般建有针对电池工作状况的在线监测系统,将工作电压、温度等数据回传至大数据平台。虽然有许多针对电池寿命预测的机理模型与实验研究,但是现有方法一般需要通过充放电才可以获得较为详细的内部电化学反应数据。而数据中心UPS的电池一般处于浮充状态,很少处于放电状态。这导致电池监测数据中鲜有适用于经典分析方法的数据。如何将专家知识与监测数据相结合,提升对电池潜在故障的预测精度,更准确地进行电池的预防性维护与更换,是一项重大的科学挑战,具有重要的实际意义。
强化学习是解决策略优化问题的一种重要方法,特别适用于机理模型复杂或未知的系统,但是存在需要大量且丰富的观测数据的问题。利用上述CFD仿真软件,已经有学者基于强化学习方法对数据中心的运行节能进行研究。Li Y L等人[7]基于深度确定性策略梯度 (deep deterministic policy gradient,DDPG)和行动-评价(actor-critic)框架,提出了一种端到端的制冷控制算法,该算法包含5个动作(action):直接蒸发冷却出口温度、间接蒸发冷却出口温度、冷却水回路出口温度、直接膨胀式冷却盘管出口温度、冷却器冷却空气回路出口温度;两个状态量(state):环境空气温度、信息技术(information technology,IT)设备负荷系数;一个奖励函数:基于PUE和各温度数据计算得到的目标函数值。EnergyPlus平台的仿真结果表明,该方法可达到较低的PUE,与手动设定数据中心温度的基准控制方法相比,可节省约11%的冷却量。但这种方法是完全由数据驱动的,它的控制决策依赖于清洁的数据,在大型数据中心中,如何保证数据的清洁度是需要认真考虑的问题。Ran Y Y等人[8]基于深度Q网络(deep Q-network,DQN)提出了一种参数化动作空间的方法,解决了离散(IT 设备)-连续(冷却装置)混合的动作空间问题,联合优化了 IT 系统的作业调度和冷却系统的风量调节。该方法使用了 6 个状态量,涉及 IT 系统与热管理,具体包括:可用CPU数、CPU利用率、能量消耗、机架的两个入口温度和一个出口温度;两个动作:精密冷却单元的通风量、任务调度行为;奖励函数:基于 PUE 和惩罚项计算得到的目标函数值。6SigmaDC 软件的仿真结果表明,该算法可以节省10%~15%的能量,并且可以在节能和保证服务质量之间实现更好的权衡。Yi D L等人[9]提出了基于深度Q网络的数据中心作业调度方法,使得数据中心在达到同样作业吞吐量的同时减小能源消耗。上述基于强化学习方法的数据中心均取得了一定的能源降耗成果,但在实际使用过程中还存在以下问题:第一,若数据中心规模较大、结构较复杂,则原始数据可能含有较大噪声、缺失、异常值,数据清洗必须做到非常精细;第二,在训练阶段及强化学习算法收敛前,为了充分探索状态-动作空间,可能会尝试激进的动作,这些动作可能会导致严重偏离最佳状态和服务器过热等问题;第三,IT系统往往在几秒甚至几微秒内做出响应,而冷却系统(机械设备)可能在几分钟内做出响应,这种反应时间的不匹配可能会导致不必要的波动等。
数据中心 UPS 的电池主要采用阀控式密封铅酸(valve-regulated lead acid,VRLA)蓄电池。在实际使用过程中,电池的寿命受板栅材料、运维状态、外部环境等多重因素的影响。常规的电池维护手段包括人工定期检测和故障维修。估计电池的剩余寿命一般需要通过深度充放电实验实现[10],而数据中心UPS的电池长期处于浮充状态,完整的放电过程数据较少,这为电池维护带来了挑战。
其中,s与s’表示任意两个状态,S表示状态空间, E表示事件构成的集合。事件驱动的优化关注如何由事件 e 驱动进行决策。可以定义策略 d 的事件-行为的Q-因子:
其中,表示事件e的输入状态构成的集合,表示策略 d 下出现事件 e时系统的真实状态为 i 的概率,r(i,a)表示在状态 i和行为a下的收益,表示事件e的输出状态构成的集合,表示系统在状态i下出现事件e时采取行为a且最终转移到状态j的概率,gdK(j)表示状态j在策略d下未来K阶段的势函数,即:
然后决定k时刻的行为:
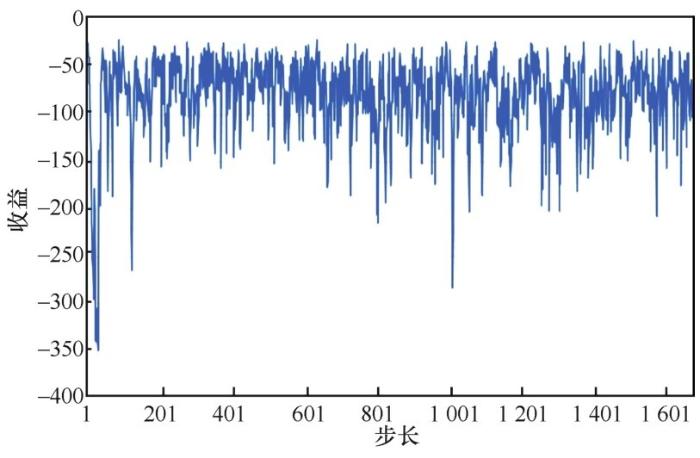
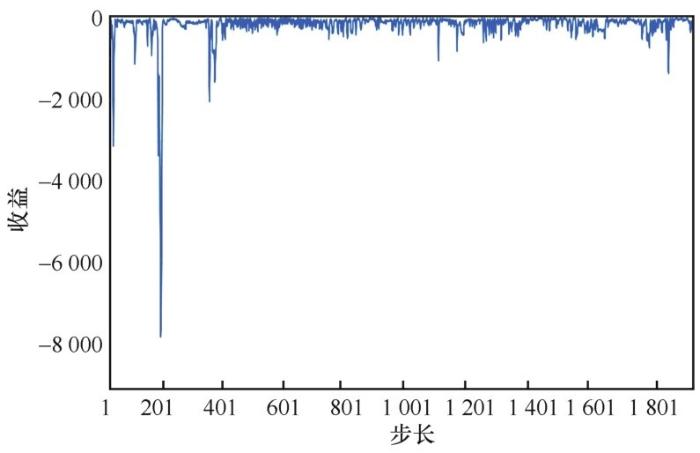
这便是事件驱动的Q学习的基本思想。该方法的性能受事件的定义影响较大。事件优选本身等价于状态转移对的着色问题[12],寻求最优事件定义一般而言并非易事,应结合具体的问题结构,选择恰当的状态转移对聚类方式。另外,给定事件定义后,可以与现有的其他强化学习算法相结合,比如深度Q网络、深度确定性策略梯度、信任域策略优化(trust region policy optimization,TRPO)、actor-critic等。
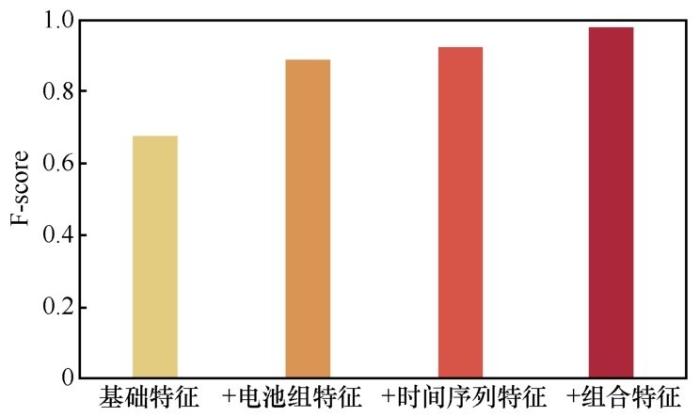
第三步,特征构造。寻找预测函数f的过程本质上是在所张成的向量空间中找到一个分类超平面。一般而言,只包含电压、电流、内阻三维,相对于百万量级的样本量来说,空间维度过低,找到分类超平面的难度极大。因此需要首先设计映射函数H: R3→RD(D>3),将样本点从三维空间映射至 D 维空间。函数 H 的设计思路以专家经验为主,综合考虑电池组内特征(如组内电压和电阻的均衡性)和离散度、时间序列特征(如电压和电阻的变化率及组合特征)。
IEEE 1188-2005-IEEE recommended practice for maintenance,testing,and replacement of valve-regulated lead-acid (VRLA) batteries for stationary applications
Transforming cooling optimization for green data center via deep reinforcement learning
1
2019
... 强化学习是解决策略优化问题的一种重要方法,特别适用于机理模型复杂或未知的系统,但是存在需要大量且丰富的观测数据的问题.利用上述CFD仿真软件,已经有学者基于强化学习方法对数据中心的运行节能进行研究.Li Y L等人[7]基于深度确定性策略梯度 (deep deterministic policy gradient,DDPG)和行动-评价(actor-critic)框架,提出了一种端到端的制冷控制算法,该算法包含5个动作(action):直接蒸发冷却出口温度、间接蒸发冷却出口温度、冷却水回路出口温度、直接膨胀式冷却盘管出口温度、冷却器冷却空气回路出口温度;两个状态量(state):环境空气温度、信息技术(information technology,IT)设备负荷系数;一个奖励函数:基于PUE和各温度数据计算得到的目标函数值.EnergyPlus平台的仿真结果表明,该方法可达到较低的PUE,与手动设定数据中心温度的基准控制方法相比,可节省约11%的冷却量.但这种方法是完全由数据驱动的,它的控制决策依赖于清洁的数据,在大型数据中心中,如何保证数据的清洁度是需要认真考虑的问题.Ran Y Y等人[8]基于深度Q网络(deep Q-network,DQN)提出了一种参数化动作空间的方法,解决了离散(IT 设备)-连续(冷却装置)混合的动作空间问题,联合优化了 IT 系统的作业调度和冷却系统的风量调节.该方法使用了 6 个状态量,涉及 IT 系统与热管理,具体包括:可用CPU数、CPU利用率、能量消耗、机架的两个入口温度和一个出口温度;两个动作:精密冷却单元的通风量、任务调度行为;奖励函数:基于 PUE 和惩罚项计算得到的目标函数值.6SigmaDC 软件的仿真结果表明,该算法可以节省10%~15%的能量,并且可以在节能和保证服务质量之间实现更好的权衡.Yi D L等人[9]提出了基于深度Q网络的数据中心作业调度方法,使得数据中心在达到同样作业吞吐量的同时减小能源消耗.上述基于强化学习方法的数据中心均取得了一定的能源降耗成果,但在实际使用过程中还存在以下问题:第一,若数据中心规模较大、结构较复杂,则原始数据可能含有较大噪声、缺失、异常值,数据清洗必须做到非常精细;第二,在训练阶段及强化学习算法收敛前,为了充分探索状态-动作空间,可能会尝试激进的动作,这些动作可能会导致严重偏离最佳状态和服务器过热等问题;第三,IT系统往往在几秒甚至几微秒内做出响应,而冷却系统(机械设备)可能在几分钟内做出响应,这种反应时间的不匹配可能会导致不必要的波动等. ...
DeepEE:joint optimization of job scheduling and cooling control for data center energy efficiency using deep reinforcement learning
1
2019
... 强化学习是解决策略优化问题的一种重要方法,特别适用于机理模型复杂或未知的系统,但是存在需要大量且丰富的观测数据的问题.利用上述CFD仿真软件,已经有学者基于强化学习方法对数据中心的运行节能进行研究.Li Y L等人[7]基于深度确定性策略梯度 (deep deterministic policy gradient,DDPG)和行动-评价(actor-critic)框架,提出了一种端到端的制冷控制算法,该算法包含5个动作(action):直接蒸发冷却出口温度、间接蒸发冷却出口温度、冷却水回路出口温度、直接膨胀式冷却盘管出口温度、冷却器冷却空气回路出口温度;两个状态量(state):环境空气温度、信息技术(information technology,IT)设备负荷系数;一个奖励函数:基于PUE和各温度数据计算得到的目标函数值.EnergyPlus平台的仿真结果表明,该方法可达到较低的PUE,与手动设定数据中心温度的基准控制方法相比,可节省约11%的冷却量.但这种方法是完全由数据驱动的,它的控制决策依赖于清洁的数据,在大型数据中心中,如何保证数据的清洁度是需要认真考虑的问题.Ran Y Y等人[8]基于深度Q网络(deep Q-network,DQN)提出了一种参数化动作空间的方法,解决了离散(IT 设备)-连续(冷却装置)混合的动作空间问题,联合优化了 IT 系统的作业调度和冷却系统的风量调节.该方法使用了 6 个状态量,涉及 IT 系统与热管理,具体包括:可用CPU数、CPU利用率、能量消耗、机架的两个入口温度和一个出口温度;两个动作:精密冷却单元的通风量、任务调度行为;奖励函数:基于 PUE 和惩罚项计算得到的目标函数值.6SigmaDC 软件的仿真结果表明,该算法可以节省10%~15%的能量,并且可以在节能和保证服务质量之间实现更好的权衡.Yi D L等人[9]提出了基于深度Q网络的数据中心作业调度方法,使得数据中心在达到同样作业吞吐量的同时减小能源消耗.上述基于强化学习方法的数据中心均取得了一定的能源降耗成果,但在实际使用过程中还存在以下问题:第一,若数据中心规模较大、结构较复杂,则原始数据可能含有较大噪声、缺失、异常值,数据清洗必须做到非常精细;第二,在训练阶段及强化学习算法收敛前,为了充分探索状态-动作空间,可能会尝试激进的动作,这些动作可能会导致严重偏离最佳状态和服务器过热等问题;第三,IT系统往往在几秒甚至几微秒内做出响应,而冷却系统(机械设备)可能在几分钟内做出响应,这种反应时间的不匹配可能会导致不必要的波动等. ...
Toward efficient compute-intensive job allocation for green data centers:a deep reinforcement learning approach
1
2019
... 强化学习是解决策略优化问题的一种重要方法,特别适用于机理模型复杂或未知的系统,但是存在需要大量且丰富的观测数据的问题.利用上述CFD仿真软件,已经有学者基于强化学习方法对数据中心的运行节能进行研究.Li Y L等人[7]基于深度确定性策略梯度 (deep deterministic policy gradient,DDPG)和行动-评价(actor-critic)框架,提出了一种端到端的制冷控制算法,该算法包含5个动作(action):直接蒸发冷却出口温度、间接蒸发冷却出口温度、冷却水回路出口温度、直接膨胀式冷却盘管出口温度、冷却器冷却空气回路出口温度;两个状态量(state):环境空气温度、信息技术(information technology,IT)设备负荷系数;一个奖励函数:基于PUE和各温度数据计算得到的目标函数值.EnergyPlus平台的仿真结果表明,该方法可达到较低的PUE,与手动设定数据中心温度的基准控制方法相比,可节省约11%的冷却量.但这种方法是完全由数据驱动的,它的控制决策依赖于清洁的数据,在大型数据中心中,如何保证数据的清洁度是需要认真考虑的问题.Ran Y Y等人[8]基于深度Q网络(deep Q-network,DQN)提出了一种参数化动作空间的方法,解决了离散(IT 设备)-连续(冷却装置)混合的动作空间问题,联合优化了 IT 系统的作业调度和冷却系统的风量调节.该方法使用了 6 个状态量,涉及 IT 系统与热管理,具体包括:可用CPU数、CPU利用率、能量消耗、机架的两个入口温度和一个出口温度;两个动作:精密冷却单元的通风量、任务调度行为;奖励函数:基于 PUE 和惩罚项计算得到的目标函数值.6SigmaDC 软件的仿真结果表明,该算法可以节省10%~15%的能量,并且可以在节能和保证服务质量之间实现更好的权衡.Yi D L等人[9]提出了基于深度Q网络的数据中心作业调度方法,使得数据中心在达到同样作业吞吐量的同时减小能源消耗.上述基于强化学习方法的数据中心均取得了一定的能源降耗成果,但在实际使用过程中还存在以下问题:第一,若数据中心规模较大、结构较复杂,则原始数据可能含有较大噪声、缺失、异常值,数据清洗必须做到非常精细;第二,在训练阶段及强化学习算法收敛前,为了充分探索状态-动作空间,可能会尝试激进的动作,这些动作可能会导致严重偏离最佳状态和服务器过热等问题;第三,IT系统往往在几秒甚至几微秒内做出响应,而冷却系统(机械设备)可能在几分钟内做出响应,这种反应时间的不匹配可能会导致不必要的波动等. ...
IEEE 1188-2005-IEEE recommended practice for maintenance,testing,and replacement of valve-regulated lead-acid (VRLA) batteries for stationary applications
1
2006
... 数据中心 UPS 的电池主要采用阀控式密封铅酸(valve-regulated lead acid,VRLA)蓄电池.在实际使用过程中,电池的寿命受板栅材料、运维状态、外部环境等多重因素的影响.常规的电池维护手段包括人工定期检测和故障维修.估计电池的剩余寿命一般需要通过深度充放电实验实现[10],而数据中心UPS的电池长期处于浮充状态,完整的放电过程数据较少,这为电池维护带来了挑战. ...













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}