







1 引言
在每天例行设备检修工作时,工作人员会撰写交接班记录,形成质量分析工区工作记录单。这些质量分析工区工作记录单是对列车运行过程中发生的问题或故障的概括。日志文件和工作人员的交接班记录之间有着重要的内在联系。工作人员在填写质量分析工区工作记录单之后,需要手工查阅日志文件,将故障人工描述和计算机故障语句对应起来,对故障语句进行解读,进而对质量分析工区工作记录单记录的故障进行更加全面的描述。因此,日志文件和质量分析工区工作记录单就成为车载设备优化运营和维护的重要数据,是车载设备故障发现的信息依据。
目前基于日志文件的人工信息处理和记录模式是车载设备故障发现及维护工作的关键环节,并已有成熟的工作流程,但随着CTCS的发展,以下问题越来越凸显[6]。
(1)日志文件数据量越来越大,以本文处理的CTCS3-300T动车组的数据为例,仅2016年4月的日志文件记录就高达120 000多条,异常记录300多条,人工查阅日志和异常记录的工作量非常大。
(2)人工描述主观性易导致遗漏、出错和记录的不一致性。质量分析工区工作记录单的填写主要依靠工作人员的经验,同一故障可能有不同的故障原因,对同一故障也可能会有多种描述方式,文本的规范性和可用性差。
(3)基于人工进行日志文件和质量分析工区工作记录单的关联和核对,效率极低,且容易漏查。
随着智能信息处理算法研究的深入和计算机技术的进步,很多依赖人工知识和经验的工作逐渐被计算机替代。本文针对CTCS日志文件数据处理及故障发现问题,引入智能信息处理算法,构建故障分析字典,开发了故障自动发现和定位软件[6]。本文的主要工作如下:
● 提出日志文件数据的智能处理算法,本文选择TFIDF(term frequency and inverse documentation frequency)算法[7]进行信息抽取,自动定位描述车载设备故障的语句;
● 提出质量分析工区工作记录单文本处理算法,本文选择最大匹配(maximum matching,MM)分词算法[8]进行分词,从历史工作记录文本中获取故障类型和故障处理方案,搭建了一个包括规范的故障名、故障语句、故障处理方案的故障分析字典;
2 问题分析与技术方案
2.1 日志文件分析
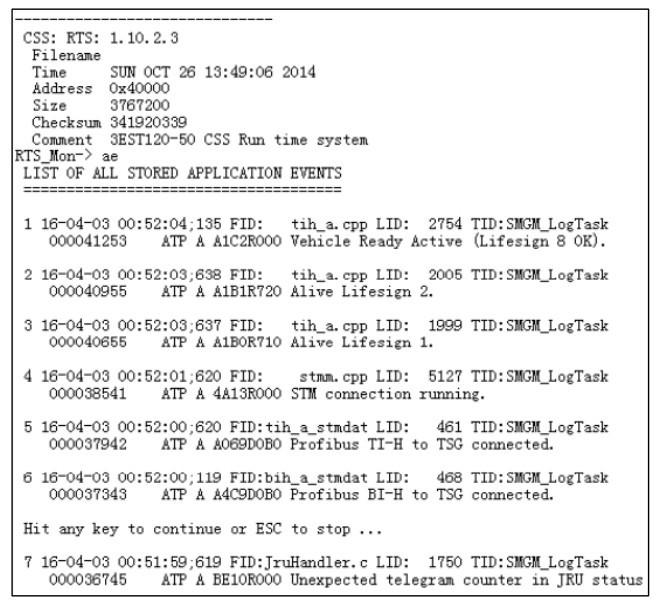
本文使用的数据来源于某铁路局动车段2016 年4月30天的日志文件,记录数据120 000多条,工作人员的异常记录300多条。局部日志文件如图1所示。
每个日志文件包含 250 条设备信息记录,每条记录分为两部分,第一部分主要包括时间信息,第二部分记录这个时间车载设备的运行状态。如果出现故障,会有故障名称等。如“13 16-04-01 09:24:19;129 FID: stmm.cpp LID: 3459 TID:SMGM_Log Task 000077199 ATP A 4A29R000 STM reports failure state.”,该句是一句完整的信息,“13”是该条信息的序号,表示该信息是本文档中自上而下的第 13 条信息;“16-04-01 09:24:19”表示该条信息记录的时间是2016年4月1日的9时24分19秒;“129 FID:stmm.cpp LID: 3459 TID: SMGM_Log Task 000077199 ATP A 4A29R000”表示该条信息的代码等。每条信息中的该部分都不相同,但是该部分对故障的描述没有实际的意义,因此在本文的研究中不予关注。“STM reports failure state.”是该条信息中最有效的部分,描述了列车运行过程中的状态,本条信息表示STM(specific transmission module)的报告处于故障状态。
图1
2.2 质量分析工区工作记录单
工作人员在每天例行设备检修工作中,根据设备情况,结合日志文件中异常的信息进行记录和分析,形成质量分析工区工作记录单,详细记录故障并给出处理方式和记录处理结果。表1 为某个关于CTCS3-300T的部分记录单。
表1 质量分析工区工作记录单(CTCS3-300T)
| 项 | 内容 |
| 车号 | 5542 |
| 端号 | 0 |
| 系 | b |
| 故障日期 | 4月1日 |
| 故障时间 | 12:49:24 |
| 故障描述 | 电台超时,C3掉C2,JRU中:车载ATP在12:49:20收到地面发送的信息包后,在10秒内未再次收到地面消息,导致无线连接超时,C3降级C2 |
| 通知情况 | 已通知南所 |
| 处理情况 | 测试正常、灯显正常,单呼试验,试验结果良好,已更换右侧电台 |
表1给出了4月1日的工作人员工作记录的前8项。前两项是列车的车号和端号,第3项是出现故障或者问题的车载设备所在的系(有 a、b 两个不同的系进行备份运作),第4项和第5项主要是故障产生的时间。前5项的信息一般可以从日志文件中找到对应的描述,因此质量分析工区工作记录单和日志文件就可以建立一一对应的关系。以表1数据为例,通过查找日志文件中车号为5542的文档,找到对应时间的记录为“16-04-01 12:49:24;838 FID: wi_a_RBCcont LID: 856 TID: SMGM_Log Task 004751814 ATP A 5224R000 1 1 1 radio service lost”,从而可以找出与工作人员故障描述对应的故障语句。记录的第6项主要是故障描述,该描述是基于工作人员的经验和现场的状况进行的,口语化严重,并且因为不同的交接班记录由不同的工作人员填写,对同一个故障的描述可能存在很大的差异,但是在关键词语上会比较相似。第7项和第8项记录了故障发生之后的处理方式。
值得注意的是,工作人员的质量分析工区工作记录单是不完全记录,也就是说,工作人员并未把车载设备的所有故障或者运行状况记录下来,只是记录了表现出来的故障,而对隐而未现的问题并未记录,因此还需要对日志文件进行更加细致的搜索,才能获取列车运行状态的全面信息。质量分析工区工作记录单虽然不够全面,但是该类文档具有很大的参考价值,是对故障的人工确认和详细描述,可以为车载设备的故障发现提供良好的数据支持。
2.3 两类文本数据的分析与算法应用
日志文件和质量分析工区工作记录单属于两类文本数据,这两类文本数据既紧密联系又有所不同。两者内容不同,日志文件是列车运行中实时记录下来、全面反映列车运行状况的文件,质量分析工区工作记录单是对表现出来的故障的详细信息描述及处理方案。两者形式不同,质量分析工区工作记录单是中文记录,日志文件是非结构化英文记录。因此,对这两类文本数据的分析需要采用不同的算法。
对于非结构化英文文本,常见的信息抽取算法有基于文档频率(document frequency,DF)法、互信息(mutual information,MI)法[15]和 TFIDF算法等。本文采用简洁而准确率高的TFIDF算法对日志文件进行处理。TFIDF 算法选用词频(term frequency,TF)与逆文本频率(inverse document frequency,IDF)指数来评估某词条对于一个语料库中的某份文件的重要程度。TF为ti在文档d中出现的频率,记为tf(ti,d);DF 为特征项的文档频率,即在全部文档集合中出现ti的文档数量,记为df(ti);IDF为特征项的逆文档频率,即包含词条ti的文档越少,IDF越大,则词条ti具有更好的类别区分能力,记为idf(ti)=log(n df(ti)),其中n表示训练样本总数;则ti的权重Wi如式(1)所示:
TFIDF算法的原理为:某词条在某文档中出现的频率较高,而在其他文档中出现的频率较低,说明该词条适合用于分类;包含某个词条的文档越少,词条区分文档内容的能力越强[7]。
日志文件和质量分析工区工作记录是非结构化文本数据,因此本文用正则表达式算法进行文本信息的降维处理,匹配特征项,实现日志文件的自动查询、阅读。
3 算法与故障分析字典搭建
基于上述分析,本文采用智能信息抽取算法对日志文件和质量分析工区工作记录单进行分析处理;构造故障分析字典,设计自动故障发现软件,实现对日志文件和质量分析工区工作记录单信息的挖掘和自动匹配。
3.1 分词算法
对表1所示质量分析工区工作记录单中的故障描述语言进行分词,主要步骤如下。
步骤 1:收集处理信息时间范围内所有质量分析工区工作记录单故障记录,构造原始字典,统计字典的最长词条,记为MaxLen,本研究处理数据的最长词条为MaxLen=14。
步骤 2:以标点符号为标识进行分句,并进行分词。
步骤 3:以原始字典中的第一个字为初始值,向后取n个字,n≤MaxLen,跳转至步骤4。
步骤4:如果取到的n个字是一个正确的词语,则分词成功,跳转至步骤6,否则跳转至步骤5。
步骤5:去掉n个字的最后一个字,令n=n-1,跳转至步骤 4,继续判断和操作,如此循环,直到n 1=。
步骤 6:将词条中的词语去掉,如果该词条为空,则算法结束,否则跳转至步骤3。
步骤 7:整理结果,得到较为完整的故障名称和故障处理方案。
基于字符串的最大匹配分词算法可以对工作记录中冗杂数据进行分词,通过对匹配的内容进行整理,即可确定质量分析工区工作记录单中常见的故障类型和故障的解决方案。图2所示为将某质量分析工区工作记录单进行分词之后的结果,可以得到如“多普勒雷达故障”和“启机 BSA 故障”等常见故障名称。
图2

3.2 TFIDF算法
使用TFIDF算法对日志文件进行信息抽取,步骤如下。
步骤1:基于质量分析工区工作记录单的故障记录时间,确定对应的所有日志文件。
步骤2:对日志文件中的每条语句进行首次分词,得到单个词语。
步骤3:计算单个词语在每一个日志文件中出现的次数TF。
步骤4:计算单个词语在所有的日志文件中出现的次数DF,计算IDF。
步骤5:根据式(1)计算权重,并将其放大。
步骤6:根据权重计算结果确定故障语句中的关键词。
步骤7:整理得到的关键词,构建故障语句词库。
本文以“Speed sensor failure”为例,计算这个词语在某铁路局动车段2016年4月30天内所有日志文件中出现的权重,其结果如图3所示。
图3
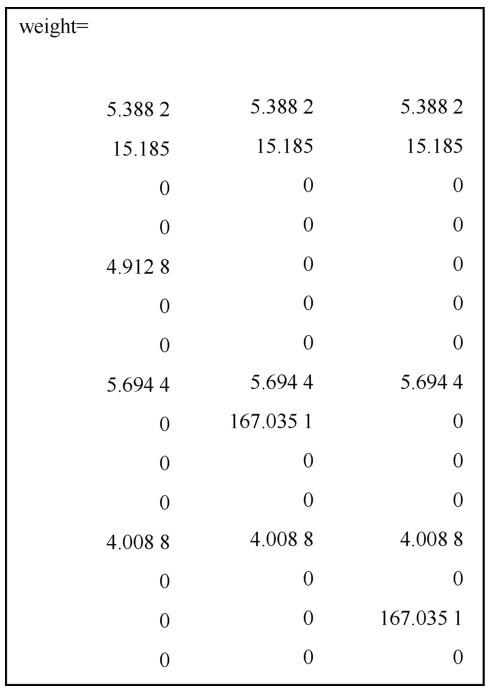
图3是所有日志文件中截取到的“Speed sensor failure”的权重计算结果。其中每一行的数据是在同一天产生的,分别代表“speed”“sensor”“failure”的权重。从结果可以看出,第1、2、5等行对应的日期的日志文件记录中都出现过这一故障语句,第3、4、6 等行对应日期的日志文件记录中没有出现这类故障语句,因此,根据权重计算结果可以查找出对应的故障名称。
3.3 故障分析字典
基于前文提到的分词算法和信息抽取 TFIDF算法,可以从质量分析工区工作记录单和对应日期的日志文件中提取关键故障信息,以时间和故障名称为索引,建立自动记录信息和人工记录信息的对应关系,从而构造故障分析字典,为自动故障发现奠定了算法和数据基础。
车载设备故障分析字典(部分)见表2,包括故障关键词、故障描述、故障处理方案3个部分。故障关键词是根据日志文件中的记录进行信息抽取得到的结果。故障描述和故障处理方案则是利用分词对质量分析工区工作记录单进行信息抽取得到的关键词。
4 基于文本信息抽取的故障发现实验
4.1 故障发现系统功能需求
本文以CTCS车载设备故障发现为研究背景,以日志文件和质量分析工区工作记录单为数据源,依托智能信息抽取算法,开发了故障发现软件,软件需求如下:
● 完备的故障分析字典,基于人工经验的专业故障分析功能;
● 便捷的故障定位功能;
● 良好的人机交互能力,简洁的操作界面。
4.2 故障发现软件的操作流程
本文基于 MATLAB 开发的故障发现软件包括3 个功能程序:文件读取子程序、故障定位子程序和故障处理子程序,其中故障定位子程序基于正则表达式的程序语言对日志文件中的信息进行降维处理,实现故障语句定位。故障发现软件主界面如图4所示,软件操作流程如下。
步骤 1:用户登录系统;新用户需先注册,注册成功后即可登录使用。
步骤 2:用户进入主界面,点击“浏览”,选择并读取需要进行故障信息抽取的日志文件。
步骤 3:从下拉菜单中选择故障语句或故障名称,点击“查询”,则可以在定位界面显示对应故障的位置、记录时间等,该功能可以自动统计所选日志文件中某故障发生的次数。如果出现新的故障语句或名称,则跳转至步骤5。
表2 车载设备故障分析字典(部分)
| 故障关键词 | 故障描述 | 故障处理方案 |
| ATP A LOG MSG SPL_Initialise-104 | ATPCU硬件故障 | 更换ATPCU模块后测试 |
| BSA Permanent Error | 启机BSA故障 | 换系重启 |
| Speed sensor failure | 多普勒雷达故障 | 核对轮径值设置是否有误;清洁速度传感器探头;雷达工作若正常,则在雷达参数标定后观察,否则更换 |
| JRU message could not be sent (event size too long) | JRU硬件故障 | 重启ATP和JRU故障未消除,确定为JRU硬件故障,予以更换 |
| EBFR state wrong | 制动反馈继电器故障 | 检查BFB继电器与底座安装是否紧固没有松动;若无松动重启后无法恢复则更换处理 |
| Network resource not available | 网络资源不可用 | C3降级为C2,更换电台 |
步骤 4:点击“分析”按钮,在故障分析界面显示故障产生的原因和故障的处理方案。
步骤 5:基于质量分析工区工作记录单中新故障的产生时间,查找新故障的故障语句,并将其录入故障分析字典。
步骤6:分别点击“导出1”和“导出2”按钮,可以导出定位界面和故障分析界面的内容。如点击“导出3”按钮,则导出故障发现与分析记录单,这个记录单可以替代以往基于人工方式得到的质量分析工区工作记录单,同时可以得到故障分析信息,从而实现基于日志文件的故障发现、记录及处理的自动化。
4.3 实验成果
图4所示为故障发现软件使用主界面,包括导入日志文件和故障名称选择的查询界面;日志文件定位故障记录的定位界面以及故障描述和处理的故障分析界面。
图4

在查询界面点击“浏览”按键,可以打开日志文件并读取信息。查询界面有两个不同的下拉菜单,第一个是日志文件中的故障语句选项,第二个是故障分析字典中的故障中文名称。在进行故障定位时,可以选择适合的下拉菜单,从中选择想要查找的故障语句或者故障名称,查询的同时可以统计故障次数。
本文在选择2016年4月1日的一个日志文件之后,选择“多普勒雷达故障”这一故障名称。点击“分析”按钮,则在定位界面和故障分析界面分别展示了与这一故障相关的信息。
点击“导出 2”按钮,可以将故障语句和故障分析描述以Excel格式导出。
主界面的左侧有时间查询的选项,对于新发现的故障名称,可以选择时间作为查询条件,从日志文件中定位这一故障语句,并填充至故障分析字典。
本文的仿真实验使用了某铁路局动车段2016 年4月的日志文件和质量分析工区工作记录单,共有78个车次的数据,日志文件记录120 000多条,工作人员的异常记录300多条。在本实验中,将这300 多条记录用于构建词典,形成的故障分析字典记录约100多条。在更多的验证实验中,笔者增加异常记录至千余条,但故障分析字典记录没有明显增加。通过对质量分析工区工作记录单记录故障进行整理可以发现,大部分故障类型可以归为几大类设备或运行故障,虽然总故障数目随着记录的增加而增加,但故障类型没有明显增加,主要原因是车载设备本身具有极高的可靠性,并且设备模块化。
本文提出的算法和软件很好地实现了日志故障语句的自动定位和分析,在基于历史数据的实验中,故障发现准确率为 100%,有效提高了故障发现及记录分析的工作效率。
5 结束语
日志文件和地面设备维护工作人员撰写的交接班记录——质量分析工区工作记录单,包含着大量的反映车载设备运行状态的信息,是车载设备故障发现和诊断的重要依据。然而目前对CTCS车载设备进行故障诊断和发现的研究中,利用日志文件和质量分析工区工作记录单的研究还很少见。对这两类文本数据的利用,目前还局限于工作人员人工记录、查询和解读,存在效率低、主观性强等问题。特别是,日志文件的日常分析记录工作关系到CTCS 运行的安全,是一项工作量非常大的日常维护任务。人工方式的分析和记录很容易出现记录遗漏和分析差错。本文设计了基于两类信息的故障发现研究方法,构建了基于分词算法、智能信息抽取算法的故障分析字典,利用正则表达式算法实现故障语句的自动定位。最后通过 MATLAB 编程开发了一个可以适用于 Windows 操作系统的故障发现软件,该软件通过基于历史质量分析工区记录单信息获得的故障分析字典,对导入的日志文件进行故障语句定位和分析。将两类关于车载设备安全的数据有机结合、延伸应用。基于实际数据的测试实验表明了所提算法和软件的合理性及可应用性。
参考文献
列车运行控制系统
[M].
Chinese train control system
[M].
列控设备动态检测系统
[M].
Train control equipment dynamic detection system
[M].
基于文本挖掘的高铁信号系统车载设备故障诊断
[J].
Text mining based fault diagnosis for vehicle on-board equipment of high speed railway signal system
[J].
探究列控系统对动车组制动系统故障后的安全防护作用
[J].
Safety protection after the braking system fault of train con-trol system
[J].
CTCS-3级列控车载记录下载器的软件设计
[J].
Software design of CTCS-3 carrier record downloader
[J].
基于文本信息抽取的高铁车载设备故障发现的理论与方法
[D].
The theory and method of fault discovery based on text in-formation extraction for on-board vehicle equipment of high speed railway
[D].
TFIDF 算法研究综述
[J].
Study of TFIDF algorithm
[J].
中文信息检索引擎中的分词与检索技术
[J].
Word segment and search techniques for chinese information search engines
[J].
非结构化文本中内容对象抽取的技术方法综述
[J].
Review of the technologies and methods for extracting content objects from unstructured text
[J].
正则表达式匹配算法研究
[D].
Research on regular expression matching algorithms
[D].
Chinese word segmentation:a decade review
[J].
Improved Chinese word segmentation method based on dictionary
[J].
论汉语自动分词方法
[J].
The method of automatic Chinese word segmentation
[J].
Critical tokenization and its properties
[J].
Effective global approaches for mutual information based feature selection
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}