1 引言
视网膜疾病发病率高,且相关疾病种类繁多。据世界卫生组织报告,世界视力障碍者总数达22 亿人,其中至少10亿个病例可以预防或有待解决[1 ] 。眼部疾病的早期发现和治疗可以很好地预防视力问题带来的障碍。目前,人工智能技术在视网膜疾病中最常见的应用是通过彩色眼底数码照相机采集患者眼底图像[2 ] ,将眼部生理结构、病灶特征和颜色变化以清晰的图像展现出来,医生可以利用这种非侵入式的方法对视网膜疾病做出诊断。然而,由于病患众多,仅依靠人工进行眼部疾病的筛查和诊断会给医生带来极大的工作压力,提高误诊率。因此,计算机视觉技术的发展为眼科医生利用计算机辅助诊断带来了可能。考虑到病人的差异性,眼科医生对患者进行初步诊断的阶段面临诸多困难:
● 视网膜疾病种类繁多,需要医生具备丰富的诊断经验;
● 图像采集过程中,光线的影响会对成像质量产生干扰,增加医生工作难度。
近年来,随着深度学习在计算机视觉和模式识别领域的成功发展,基于眼底图像的疾病筛查和识别方法不断涌现。Pratt H等人[3 ] 以及Colas E等人[4 ] 提出了使用深度神经网络的方法对5 000位患有糖尿病性视网膜病变(diabetic retinopathy,DR)患者的10 000张眼底图像进行特征提取,将DR患病阶段分为4类:轻度病变、中度病变、重度病变和扩散,为计算机辅助DR的诊断做出了贡献;WorrallD E 等人[5 ] 提出基于深度学习的端到端系统对早产儿视网膜病变(ROP)进行早期诊断,他们对经过预训练的GoogleNet模型进行微调后,在私有数据集上对ROP疾病的诊断准确率达到95.4%;BurlinaP等人[6 ] 提出使用 ImageNet 预训练权重的深度卷积神经网络对年龄相关性黄斑变性(age-related macular degeneration,ARMD)正常、早期、中期、晚期的 4 个阶段进行识别,基于该疾病的特性,深度卷积神经网络从眼底图像中心区域的多个同心矩形中提取特征进行训练,并取得了较好的识别效果。
以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献。实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题。区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断。其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别。针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果。ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%。以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题。
前人的工作表明,利用深度神经网络对病灶特征进行提取并对疾病进行识别已经成为当前主流的方法,相较于传统机器学习方法,无论是对病灶特征提取的能力,还是对疾病识别的效果,都有极大的提升。但是针对多种疾病的筛查和识别工作,尤其是疾病种类较多时,模型的识别能力仍待改善。基于此,本文做出的贡献有以下几点:
● 只使用一个模型,在仅有2 500多个样本的情况下对多达28种疾病进行筛查和识别;
● 由于数据集样本数量极不平衡,本文采用分组多任务的方法同时参与网络更新;
● 与以往的工作相比,笔者用更少的成本达到了更好的性能。
2 数据预处理
2.1 黑框裁切
使用眼底相机采集视网膜眼底图像时,因设备的不同和患者间的差异性,采集到的图像存在以下问题:视网膜眼底图像分辨率不同、眼底在整张图像中的位置不固定、眼底尺寸存在细微差异。另外,眼底图像均存在大量冗余的黑色区域,这些黑色区域并非视网膜区域。因此,为了尽量减少黑框对提取特征过程造成的不必要的干扰,需要去除多余的黑色边框,裁剪出感兴趣区域,并将图像调整为统一尺寸。
为了找到眼底区域,可以通过图像的RGB数值定位眼底的边缘位置。眼底边缘位置定位方式如下:
sum ( R , G , B ) − 3 × margin > 0 ( 1 )
其中,R、G、B为每行(列)的RGB色彩空间数值,其取值范围为[0,255]。受光照及其他因素影响,靠近眼底边缘处的一部分区域从 RGB 数值上看并非完全黑色,若尽可能多地去除黑色区域,则需要减去一个人为设置的阈值(margin),本文设定为5。根据式(1)可从上、下、左、右分别定位眼底边缘位置,再从原图中去除黑色边框,裁剪出感兴趣区域。
2.2 数据增强
深度学习模型的训练需要海量的数据做支撑,而一些罕见的视网膜疾病难以获得足够的训练数据[14 ] ,深度学习在医学图像处理上的应用使得这一问题尤为凸显。在仅有少量数据集的条件下,训练一个效果良好、泛化性能较强的模型需要根据现有的少量数据进行数据增强,以满足深度神经网络模型对大数据量的需求。本文在训练前和训练过程中使用不同的数据增强方法,有效解决了数据量不足的问题。
首先,在训练前,对输入图像采用图形变换的方式进行数据增强。使用的方法包括随机裁剪、垂直和水平方向翻转、随机角度旋转、增加高斯噪声、限制对比度自适应直方图均衡化(CLAHE)等。其中, Zuiderveld K [15 ] 提出的CLAHE方法是对直方图均衡化的改进,通过将原始图像的灰度直方图划分成若干个子区域,对子区域分别进行受对比度限制的直方图均衡化,再利用双线性差值消除各个子区域间比较明显的截断部分,得到一张对比度增强的图像。这一方法使一些受光照条件影响而过暗或过亮的图像获得更加清晰的成像效果。
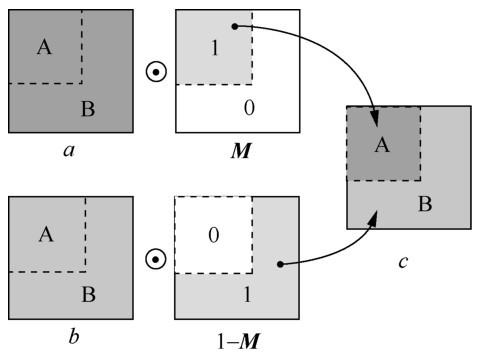
另外,在训练过程中引入了Yun S等人[16 ] 提出的 CutMix 数据增强方法,即将每个小批量中的图像进行随机拼接组合,并加权计算总损失。其原理如图1 所示。
图1
步骤 1:在一个轮次的每个批量中,采用不放回的方式随机抽取两个图像样本和对应的标签,记为a、b;
步骤3:从a中截取占比为p的局部图像A,记录边框对角位置x1 、y1 、x2 、y2 ,剩余部分记为B;
步骤4:利用x1 、y1 、x2 、y2 将a中的B区域替换为b中的B区域,组成新的图像c,其中B区域占比为 1‒p;步骤 3、步骤 4 可用式(2)表示:
c = M ⊙ a + ( 1 − M ) ⊙ b ( 2 )
步骤5:将新图像c输入模型,并计算总损失,计算方法如下:
Loss = p × loss ( f ( c ) , Y a ) + ( 1 − p ) × loss ( f ( c ) , Y b ) ( 3 )
其中,式(2)中M ⊙ a 和Yb 分别为图像a和图像b的标签。
使用该方法,在一次训练过程中拼接两张不同的图像,可以在局部信息中识别出两个不同的目标,从而提高模型的识别能力和泛化能力,达到数据增强的效果。
3 基于深度卷积集成网络的视网膜多种疾病筛查和识别模型
本文将 EfficientNet 作为主干网络进行特征提取,再对整个网络模型进行微调,分别完成视网膜疾病的筛查和识别任务。最后,多个网络模型进行集成,并将最终的结果用于疾病筛查和识别。
3.1 目标函数
在疾病筛查任务中,需要根据被试的眼底图像判断该被试是否有患病的风险,因此,可以将疾病筛查问题看作二分类问题。将交叉熵(cross entropy)损失作为多种疾病筛查任务的损失函数:
L screen ( Y , p ( X ) ) = − Y × log ( p ( X ) ) − ( 1 − Y ) × log ( p ( X ) ) ( 4 )
为了给患者的患病种类做出判断,需要根据患者的眼底图像对患病的概率做出预测,而同一患者可能会患有多种疾病,因此,疾病识别任务实际为多标签分类问题。将二分类交叉熵损失作为多种疾病识别任务的损失函数:
L rec ( Y , f 2 ( X ) ) = − 1 N ∑ i = 1 N ( Y × log σ ( f 2 ( X ) ) ) +
( 1 − Y ) × log ( 1 − σ ( f 2 ( X ) ) ) ( 5 )
Loss = α × L screen ( Y , f 1 ( X ) ) + β × L rec ( Y , f 2 ( X ) ) ( 6 )
在式(4)~式(6)中,X为输入的视网膜眼底图像,Y为相应图像的标签,f(*)为主干网络对图像信息编码后预测为正类的概率,N为疾病类别数量,σ(*)为Sigmoid函数,α和β为超参数,用于平衡两个任务损失函数所占比重。
3.2 特征提取
对视网膜眼底图像进行处理时,采用卷积的方式提取图像中的信息,通过叠加多种卷积层构建一个深层的卷积神经网络。相较于传统的机器学习方法,深层卷积神经网络可以自动完成特征提取,并达到更好的特征提取效果。经过近几年深度卷积神经网络的发展,优秀的神经网络往往有以下特点:
● 使用残差结构,以增加神经网络的深度,提高特征提取能力;
● 在神经网络的单元结构中增加特征提取层数,即增加神经网络的宽度;
● 调整神经网络的参数,以适应更大分辨率图像的输入,使得网络模型可学习更精确的内容。
本文将谷歌大脑团队提出的 EfficientNet[17 ] 作为模型的主干网络部分进行特征提取,该网络可对网络的深度、宽度和输入的分辨率进行适当的调整,以达到更好的特征提取效果。
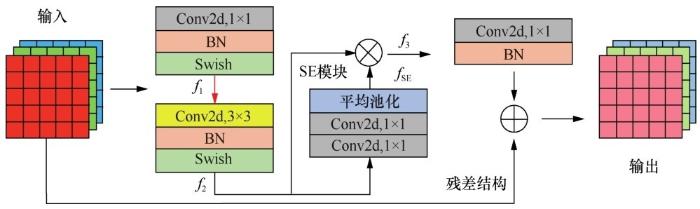
在EfficientNet中,最核心的MBConv模块结构如图2 所示。该模块源于MobileNet-V3[18 ] 中的倒置残差模块(inverted residual block),Tan M X等人[17 ] 对其进行改进,采用了Swish激活函数[19 ] ,并引入了Hu J等人[20 ] 在SENet中提出的SE(squeezeand-excitation)模块,将通道注意力机制应用于特征提取过程中。Swish激活函数如式(7)所示:
f ( x ) = x 1 + e − β x ( 7 )
其中,x 为激活函数的输入数据,β 为常数或可训练的参数。
f 1 = Swish ( BN ( Conv 2 d ( X , 1 ) ) ) ( 8 )
f 2 = Swish ( BN ( DepthConv 2 d ( f 1 , 3 ) ) ) ( 9 )
f SE = Conv 2 d ( Conv 2 d ( AveragePool ( f 2 ) , 1 ) ) ( 10 )
f 3 = BN ( Conv 2 d ( f SE ⊗ f 2 , 1 ) ) ( 11 )
output = X + f 3 ( 12 )
首先,MBConv模块使用1×1卷积(Conv2d)对输入做升维操作得到特征图f1 ,利用3×3或5×5的通道维度卷积(DepthConv2d)得到相同维度的特征图f2 ,其中,卷积操作后含有归一化层(BN)和激活层(Swish);特征图f2 经过 SE 模块中 1×1卷积和平均池化(average pool)后计算出通道注意力权重fSE ,再将fSE 与f2 相乘,获得带有注意力的特征图f3 。最后,经过全连接层后,与原始输入的特征图进行残差连接,在一定程度上缓解了随着网络深度的增加带来的网络退化和过拟合问题[21 ] ,最终输出新的特征图(output)。
从EfficientNet的B0到B7,通过对MBConv模块的叠加和网络参数的调整,构成了不同深度和宽度的网络结构,输入图像的分辨率随之增大,特征提取的能力不断增强本文将采用EfficientNet-B5、EfficientNet-B6、EfficientNet-B7所得到的结果进行后续工作。
3.3 网络微调
在使用深度学习对医学图像进行处理的过程中,常面临数据集的数据量过少的问题,而且深层的主干网络含有大量的网络参数,很容易出现过拟合和泛化能力差的情况。为了缓解这一情况,本文采用了迁移学习的方法,在模型的训练开始前加载公开的预训练网络权重,再将训练集数据输入网络进行训练。视网膜眼底图像经过主干网络后,学习到的特征被提取出来,因此,若将提取出的特征用于多种疾病的筛查任务和识别任务,需要对网络进行微调,微调网络的结构如图3 右侧所示。
图2
首先,将主干网络输出的特征图用展平(flatten)操作拉伸成一维向量,经过中间的隐藏层(包括线性映射层Linear、归一化层BN和ReLU激活层)增加网络的非线性能力后,输出维度为对应疾病类别数量的向量,用于对多种疾病的患病概率进行预测,并根据该向量计算多种疾病识别损失Lscreen ;然后,按照上述类似步骤,根据多种疾病患病概率完成疾病筛查任务,即预测患病风险,并计算疾病筛查损失 Lrec ;最后,按照合适的权重对两个损失进行加权,计算出总损失,用于对整个网络模型的反向传播更新网络参数。
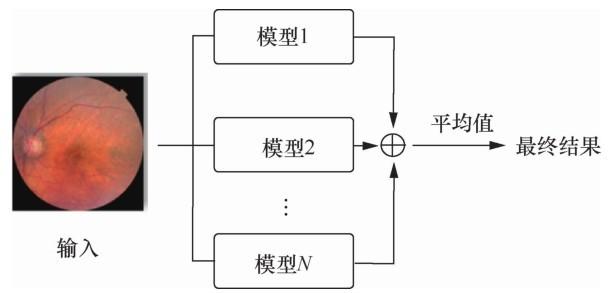
3.4 模型集成
在实际的训练过程中,笔者在多种结构的模型上尝试对视网膜疾病进行分类,但并不是所有的模型都能够达到相同的效果,且不同的模型对不同疾病的分类效果也各有差别。因此,本文采用集成学习的方法,综合考虑不同模型的分类结果,使整体的疾病筛查和识别效果在一定程度上有所提升。
集成学习是一种被广泛应用于机器学习和深度学习的算法,即将多个训练器结合使用,其结果往往比单个训练器更优。常用的模型集成策略有以下几种。
Result = 1 N ∑ i = 1 N S i ( 13 )
Result = 1 N ∑ i = 1 N W i S i ( 14 )
式(13)、式(14)中 N 为集成模型的数量,Si 为第i个模型的预测结果,Wi 为第i个模型的权重。
图3
图3
基于深度卷积集成网络的视网膜多种疾病筛查和识别模型
● 投票法:投票法常使用多数表决法,记第i个模型对第j个类别的预测结果对应的标签为Lij ,那么所有模型对第j个类别的分类结果为Rj ={L1j , L2j ,…,LNj },将Rj 中多数投票结果作为最终分类结果。
● 堆叠法:堆叠法实际上通过构建新的学习器,将多个模型预测的结果作为一个新的数据集输入,得到最终预测结果。
如图4 所示,本文选用直接平均法模型集成策略,对训练完成的EfficientNet-B5、EfficientNet-B6、EfficientNet-B7 3个模型预测结果取平均值,得到最终结果。
图4
4 实验结果
4.1 数据集
本文将IEEE ISBI 2021[22 ] 中的视网膜眼底图像作为数据集,该数据集分别使用 3 台数码眼底照相机采集,共2 560张视网膜眼底图像,其中1 920张图像为训练集,640张图像为测试集。这2 560张图像中共包含3种分辨率,分别为4 288×2 848、2 144×1 424和2 048×1 536。此外,数据集包含48种视网膜疾病,其中较为罕见的疾病将被统一标记为“其他(OTHER)”类别,包括“其他”类别在内共有28 种疾病,且每个图像样本为正常或至少包含一种疾病。其余27种疾病如下:糖尿病性视网膜病变(DR)、年龄相关性黄斑变性(ARMD)、屈光介质混浊(media haze,MH)、玻璃疣(drusen,DN)、近视(myopia,MYA)、视网膜静脉分枝阻塞(branch retinal vein occlusion,BRVO)、镶 嵌 眼 底(tessellation,TSLN)、黄斑视网膜前膜(macular epiretinal membrane,ERM)、激光瘢痕(laser scar, LS)、黄斑瘢痕(macular scar,MS)、中心性浆液性脉络膜视网膜病变(central serous chorioretinopathy,CSR)、视神经盘凹(optic disc cupping, ODC)、视网膜中央静脉阻塞(central retinal vein occlusion,CRVO)、血管迂曲(vascular circuity)(原数据集用 TV 表示)、星状玻璃体病变(asteroid hyalosis,AH)、视盘苍白(optic disc pallor,ODP)、视盘水肿(optic disc edema,ODE)、分流(shunt, ST)、前部缺血性视神经病变(anterior ischemic optic neuropathy,AION)、中心凹毛细管扩张(parafoveal telangiectasia,PT)、视网膜牵引(retinal traction, RT)、视网膜炎(retinitis,RS)、脉络膜视网膜炎(chorioretinitis,CRS)、渗出(exudation,EDN)、视网膜色素上皮改变(retinal pigment epithelium change,RPEC)、黄斑裂孔(macular hole,MHL)、色素性视网膜炎(retinitis pigmentosa,RP)。
4.2 样本不平衡处理
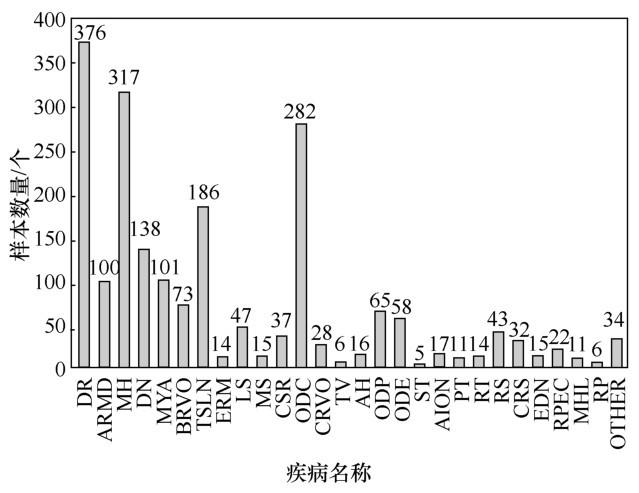
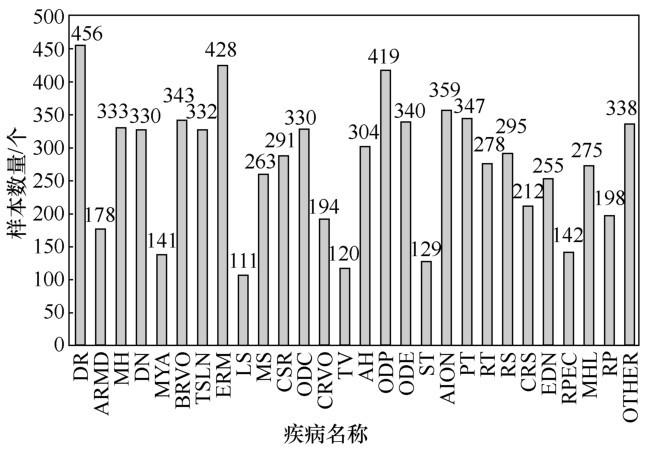
对样本不平衡的处理是机器学习和深度学习不可避免的一个问题,然而在本文使用的数据集中,样本不平衡的问题尤为突出。在多种疾病筛查和识别问题中,每种疾病往往与其他疾病有一定联系,即各种疾病之间并非互斥关系。训练集中各种疾病的样本数量如图5 所示。
图5
笔者分析各种疾病之间的关联性和单一疾病样本数量后,根据每种疾病样本数量分为[0,25]、(25,50]、(50,100]、(100,150]、(150,400]5个区间,处于不同区间内的疾病将采用不同程度的复制、镜像、旋转等方法对样本进行扩充,结果如图6 所示。
图6
从图6 可以看到,TV、ST等疾病的样本数量有大幅度的增加,但由于LS、TV、ST与DR、ODP关联性较大,因此各疾病间样本数量无法实现绝对的平衡。
4.3 数据预处理结果
实验开始前,首先对数据进行预处理,具体方法如第2节所述。训练开始前,读入黑框裁切后的1 920张训练集图像,再对图像进行尺寸调整、随机裁剪、随机旋转、CLAHE等数据增强方式扩充训练集,进行归一化处理后输入模型训练。训练过程中随机抽取每个轮次中的两张图像使用CutMix数据增强方法再次进行数据增强。黑框裁切的结果如图7 所示。
图7
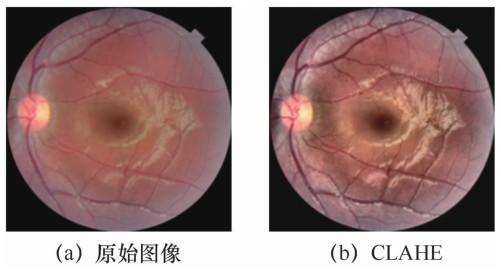
使用CLAHE数据增强方法的结果如图8 所示。图8 (a)为原始图像,图8 (b)为限制对比的直方图均衡化处理后的效果。可以看到,处理后的图像对病灶区域的显像效果有了明显的增强,这将有助于模型对病灶特点进行学习。
图8
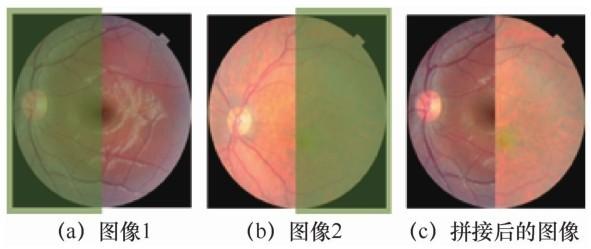
使用CutMix 数据增强方法的可视化结果如图9 所示。其中,图9 (a)、图9 (b)为随机抽取的两张图像,图像中的阴影部分为被裁剪出进行拼接的区域,图9 (c)为拼接后的图像,拼接后的图像及其标签将被输入模型进行训练。
图9
实验结果表明,预处理后的数据能减少原始图像中不必要的噪声,降低模型学习难度。此外,数据增强方法能够有效地扩充训练集的数量,有效解决了模型训练过程中数据量少的问题。
4.4 视网膜多种疾病筛查和识别结果
为了避免从零开始对深度卷积神经网络模型进行训练,在训练的初始阶段采用迁移学习的方法,加载经过大量数据预训练后得到的网络模型权重,以降低预训练的成本。
本文使用的目标函数如式(6)所示,将式(4)多种疾病筛查损失和式(5)多种疾病识别损失各自分配合适的权重后得到的整体损失用于反向传播,更新网络模型的参数。考虑到多种疾病识别任务的难度相对较大,设置α=0.4,β=0.6。另外,实验过程中优化器首先使用Adam算法以达到快速收敛的目的,之后使用 SGD 算法继续对模型优化,以达到更好的泛化性能;训练初始学习率设置为0.001,学习率衰减策略使用固定步长衰减,整个训练过程的轮次设置为 300,受设备影响,批大小设置为8。
实验采用五折交叉验证方法,训练集中85%的样本用于模型训练,剩余15%的样本作为验证集用于测试模型的泛化性能,选择训练过程中泛化性能最好的模型进行下一步的测试。在多种疾病筛查任务中,实验评价指标选择准确率(ACC)和 ROC曲线下面积(AUC),在多种疾病识别任务中实验评价指标选择准确率(ACC)和各类别平均准确率的均值(mAP)。在测试阶段,采用测试时增强和伪标签的策略,抽取置信度较高的测试样本加入训练集中不断优化网络模型。实验结果表明,该方法对多种疾病的筛查和识别性能有一定的提升。将每个网络模型五折交叉验证的平均结果作为该网络模型的预测结果,再根据式(13)中的方法集成各个网络模型,最终的结果为多种疾病筛查和识别的结果。实验结果见表1 。
实验结果表明,本文提出的基于深度卷积集成网络的视网膜多种疾病筛查和识别方法相较于主流的深度神经网络有较好的效果提升。如图10 、图11 所示,本文方法对EfficientNet的3个模型根据任务进行网络微调后,采用集成、测试增强、打伪标签等策略对训练过程进行优化,在多种疾病筛查任务中准确率达到96.05%,多种疾病识别任务中准确率达到72.55%,相较于EfficientNet的3个模型,两个任务分别提升1%~2%和 2%~5%;相较其他方法,两个任务分别提升2%~8%和9%~15%。
图10
图11
5 结束语
本文在视网膜多种疾病筛查和识别问题中,针对视网膜疾病种类繁多、病灶位置不确定、罕见疾病样本数量少等难题,首先提出了比较有效的图像数据增强和图像去噪方法,去除了视网膜眼底图像中冗余的黑框,提高了图像病灶位置的成像效果;结合使用深度卷积神经网络和集成学习的方法,对视网膜眼底图像的病灶特征进行提取,用于后续对多种疾病的筛查和识别。通过实验表明,在面临近30种视网膜疾病时,本文提出的方法能够有效地提升筛查和识别的准确率,可辅助眼科医生对患者进行初步诊断。本文方法虽取得了较好的结果,但在模型训练过程中仍存在耗时长、训练轮次多的问题,单次模型训练时间需4~6 h,如何对该模型做进一步的优化以提升模型的性能仍待解决。另外,模型在多种疾病识别任务中的准确率虽能达到72.55%,但仍有进一步提升的空间,这也是未来研究工作中的一个方向。
参考文献
View Option
[1]
STEINMETZ J D , BOURNE R R A , BRIANT P S ,et al . Causes of blindness and vision impairment in 2020 and trends over 30 years,and prevalence of avoidable blindness in relation to VISION 2020:the right to sight:an analysis for the global burden of disease study
[J]. The Lancet Global Health , 2021 ,9 (2 ): 144 -160 .
[本文引用: 1]
[2]
王诗惠 , 郝晓凤 , 谢立科 . 人工智能在视网膜疾病中应用的研究现状与展望
[J]. 中华眼科医学杂志(电子版) , 2020 ,10 (6 ): 374 -379 .
[本文引用: 1]
WANG S H , HAO X F , XIE L K . Research status and prospects of ap-plication of artificial intelligence in retinal diseases
[J]. Chinese Journal of Ophthalmologic Medicine (Electronic Edition) , 2020 ,10 (6 ): 374 -379 .
[本文引用: 1]
[3]
PRATT H , COENEN F , BROADBENT D M ,et al . Convolutional neural networks for diabetic retinopathy
[J]. Procedia Computer Science , 2016 ,90 : 200 -205 .
[本文引用: 1]
[4]
COLAS E , BESSE A , ORGOGOZO A ,et al . Deep learning approach for diabetic retinopathy screening
[J]. Acta Ophthalmologica , 2016 ,94.
[本文引用: 1]
[5]
WORRALL D E , WILSON C M , BROSTOW G J . Automated retinopathy of prematurity case detection with convolutional neural networks
[C]// Proceedings of the Deep Learning and Data Labeling for Medical Applications . Cham:Springer , 2016 : 68 -76 .
[本文引用: 1]
[6]
BURLINA P , PACHECO K D , JOSHI N ,et al . Comparing humans and deep learning performance for grading AMD:a study in using universal deep features and transfer learning for automated AMD analysis
[J]. Computers in Biology and Medicine , 2017 ,82 : 80 -86 .
[本文引用: 1]
[7]
ALTAF T , ANWAR S M , GUL N ,et al . Multi-class Alzheimer’s disease classification using image and clinical features
[J]. Biomedical Signal Processing and Control , 2018 ,43 : 64 -74 .
[本文引用: 1]
[8]
LIAO H F , LI Y C , LUO J B . Skin disease classification versus skin lesion characterization:achieving robust diagnosis using multi-label deep neural networks
[C]// Proceedings of the 2016 23rd International Conference on Pattern Recognition . Piscataway:IEEE Press , 2016 : 355 -360 .
[本文引用: 1]
[9]
SIDDIQUI M , MUJTABA G , REZA A ,et al . Multi-class disease classification in brain MRIs using a computer-aided diagnostic system
[J]. Symmetry , 2017 ,9 (3 ): 37 .
[本文引用: 1]
[10]
LEE C S , BAUGHMAN D M , LEE A Y . Deep learning is effective for classifying normal versus age-related macular degeneration OCT images
[J]. Ophthalmology Retina , 2017 ,1 (4 ): 322 -327 .
[本文引用: 1]
[11]
ARUNKUMAR R , KARTHIGAIKUMAR P . Multi-retinal disease classification by reduced deep learning features
[J]. Neural Computing and Applications , 2017 ,28 (2 ): 329 -334 .
[本文引用: 1]
[12]
WANG X , JU L , ZHAO X ,et al . Retinal abnormalities recognition using regional multitask learning
[C]// Proceedings of the Lecture Notes in Computer Science . Cham:Springer , 2019 : 30 -38 .
[本文引用: 2]
[13]
CHOI J Y , YOO T K , SEO J G ,et al . Multi-categorical deep learning neural network to classify retinal images:a pilot study employing small database
[J]. PLoS One , 2017 ,12 (11 ): e0187336 .
[本文引用: 1]
[14]
曲毅 , 张焕开 , 宋先 ,等 . 人工智能诊断系统在视网膜疾病的研究进展
[J]. 山东大学学报(医学版) , 2020 ,58 (11 ): 39 -44 .
[本文引用: 1]
QU Y , ZHANG H K , SONG X ,et al . Research progress of artificial intelligence diagnosis system in retinal diseases
[J]. Journal of Shan-dong University (Health Sciences) , 2020 ,58 (11 ): 39 -44 .
[本文引用: 1]
[15]
ZUIDERVELD K . Contrast limited adaptive histogram equalization
[M]// Graphics gems . Amsterdam : Elsevier , 1994 : 474 -485 .
[本文引用: 1]
[16]
YUN S , HAN D , CHUN S ,et al . CutMix:regularization strategy to train strong classifiers with localizable features
[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision . Piscataway:IEEE Press , 2019 : 6022 -6031 .
[本文引用: 1]
[17]
TAN M X , LE Q V . EfficientNet:rethinking model scaling for convolutional neural networks
[C]// Proceedings of the International Conference on Machine Learning .[S.l.:s..n.], 2019 : 6105 -6114 .
[本文引用: 2]
[18]
HOWARD A , SANDLER M , CHEN B ,et al . Searching for MobileNetV3
[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision . Piscataway:IEEE Press , 2019 : 1314 -1324 .
[本文引用: 1]
[19]
RAMACHANDRAN P , ZOPH B , LE Q V . Searching for activation functions
[J]. arXiv preprint,2017,arXiv:1710.05941 .
[本文引用: 1]
[20]
HU J , SHEN L , SUN G . Squeeze-and-excitation networks
[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Piscataway:IEEE Press , 2018 : 7132 -7141 .
[本文引用: 1]
[21]
HE K M , ZHANG X Y , REN S Q ,et al . Deep residual learning for image recognition
[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition . Piscataway:IEEE Press , 2016 : 770 -778 .
[本文引用: 1]
[22]
PACHADE S , PORWAL P , THULKAR D ,et al . Retinal fundus multi-disease image dataset (RFMiD):a dataset for multi-disease detection research
[J]. Data , 2021 ,6 (2 ): 14 .
[本文引用: 1]
[23]
HE K M , ZHANG X Y , REN S Q ,et al . Deep residual learning for image recognition
[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition . Piscataway:IEEE Press , 2016 : 770 -778 .
[本文引用: 1]
[24]
SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition
[J]. arXiv preprint,2014,arXiv:1409,1556 .
[本文引用: 1]
Causes of blindness and vision impairment in 2020 and trends over 30 years,and prevalence of avoidable blindness in relation to VISION 2020:the right to sight:an analysis for the global burden of disease study
1
2021
... 视网膜疾病发病率高,且相关疾病种类繁多.据世界卫生组织报告,世界视力障碍者总数达22 亿人,其中至少10亿个病例可以预防或有待解决[1 ] .眼部疾病的早期发现和治疗可以很好地预防视力问题带来的障碍.目前,人工智能技术在视网膜疾病中最常见的应用是通过彩色眼底数码照相机采集患者眼底图像[2 ] ,将眼部生理结构、病灶特征和颜色变化以清晰的图像展现出来,医生可以利用这种非侵入式的方法对视网膜疾病做出诊断.然而,由于病患众多,仅依靠人工进行眼部疾病的筛查和诊断会给医生带来极大的工作压力,提高误诊率.因此,计算机视觉技术的发展为眼科医生利用计算机辅助诊断带来了可能.考虑到病人的差异性,眼科医生对患者进行初步诊断的阶段面临诸多困难: ...
人工智能在视网膜疾病中应用的研究现状与展望
1
2020
... 视网膜疾病发病率高,且相关疾病种类繁多.据世界卫生组织报告,世界视力障碍者总数达22 亿人,其中至少10亿个病例可以预防或有待解决[1 ] .眼部疾病的早期发现和治疗可以很好地预防视力问题带来的障碍.目前,人工智能技术在视网膜疾病中最常见的应用是通过彩色眼底数码照相机采集患者眼底图像[2 ] ,将眼部生理结构、病灶特征和颜色变化以清晰的图像展现出来,医生可以利用这种非侵入式的方法对视网膜疾病做出诊断.然而,由于病患众多,仅依靠人工进行眼部疾病的筛查和诊断会给医生带来极大的工作压力,提高误诊率.因此,计算机视觉技术的发展为眼科医生利用计算机辅助诊断带来了可能.考虑到病人的差异性,眼科医生对患者进行初步诊断的阶段面临诸多困难: ...
人工智能在视网膜疾病中应用的研究现状与展望
1
2020
... 视网膜疾病发病率高,且相关疾病种类繁多.据世界卫生组织报告,世界视力障碍者总数达22 亿人,其中至少10亿个病例可以预防或有待解决[1 ] .眼部疾病的早期发现和治疗可以很好地预防视力问题带来的障碍.目前,人工智能技术在视网膜疾病中最常见的应用是通过彩色眼底数码照相机采集患者眼底图像[2 ] ,将眼部生理结构、病灶特征和颜色变化以清晰的图像展现出来,医生可以利用这种非侵入式的方法对视网膜疾病做出诊断.然而,由于病患众多,仅依靠人工进行眼部疾病的筛查和诊断会给医生带来极大的工作压力,提高误诊率.因此,计算机视觉技术的发展为眼科医生利用计算机辅助诊断带来了可能.考虑到病人的差异性,眼科医生对患者进行初步诊断的阶段面临诸多困难: ...
Convolutional neural networks for diabetic retinopathy
1
2016
... 近年来,随着深度学习在计算机视觉和模式识别领域的成功发展,基于眼底图像的疾病筛查和识别方法不断涌现.Pratt H等人[3 ] 以及Colas E等人[4 ] 提出了使用深度神经网络的方法对5 000位患有糖尿病性视网膜病变(diabetic retinopathy,DR)患者的10 000张眼底图像进行特征提取,将DR患病阶段分为4类:轻度病变、中度病变、重度病变和扩散,为计算机辅助DR的诊断做出了贡献;WorrallD E 等人[5 ] 提出基于深度学习的端到端系统对早产儿视网膜病变(ROP)进行早期诊断,他们对经过预训练的GoogleNet模型进行微调后,在私有数据集上对ROP疾病的诊断准确率达到95.4%;BurlinaP等人[6 ] 提出使用 ImageNet 预训练权重的深度卷积神经网络对年龄相关性黄斑变性(age-related macular degeneration,ARMD)正常、早期、中期、晚期的 4 个阶段进行识别,基于该疾病的特性,深度卷积神经网络从眼底图像中心区域的多个同心矩形中提取特征进行训练,并取得了较好的识别效果. ...
Deep learning approach for diabetic retinopathy screening
1
2016
... 近年来,随着深度学习在计算机视觉和模式识别领域的成功发展,基于眼底图像的疾病筛查和识别方法不断涌现.Pratt H等人[3 ] 以及Colas E等人[4 ] 提出了使用深度神经网络的方法对5 000位患有糖尿病性视网膜病变(diabetic retinopathy,DR)患者的10 000张眼底图像进行特征提取,将DR患病阶段分为4类:轻度病变、中度病变、重度病变和扩散,为计算机辅助DR的诊断做出了贡献;WorrallD E 等人[5 ] 提出基于深度学习的端到端系统对早产儿视网膜病变(ROP)进行早期诊断,他们对经过预训练的GoogleNet模型进行微调后,在私有数据集上对ROP疾病的诊断准确率达到95.4%;BurlinaP等人[6 ] 提出使用 ImageNet 预训练权重的深度卷积神经网络对年龄相关性黄斑变性(age-related macular degeneration,ARMD)正常、早期、中期、晚期的 4 个阶段进行识别,基于该疾病的特性,深度卷积神经网络从眼底图像中心区域的多个同心矩形中提取特征进行训练,并取得了较好的识别效果. ...
Automated retinopathy of prematurity case detection with convolutional neural networks
1
2016
... 近年来,随着深度学习在计算机视觉和模式识别领域的成功发展,基于眼底图像的疾病筛查和识别方法不断涌现.Pratt H等人[3 ] 以及Colas E等人[4 ] 提出了使用深度神经网络的方法对5 000位患有糖尿病性视网膜病变(diabetic retinopathy,DR)患者的10 000张眼底图像进行特征提取,将DR患病阶段分为4类:轻度病变、中度病变、重度病变和扩散,为计算机辅助DR的诊断做出了贡献;WorrallD E 等人[5 ] 提出基于深度学习的端到端系统对早产儿视网膜病变(ROP)进行早期诊断,他们对经过预训练的GoogleNet模型进行微调后,在私有数据集上对ROP疾病的诊断准确率达到95.4%;BurlinaP等人[6 ] 提出使用 ImageNet 预训练权重的深度卷积神经网络对年龄相关性黄斑变性(age-related macular degeneration,ARMD)正常、早期、中期、晚期的 4 个阶段进行识别,基于该疾病的特性,深度卷积神经网络从眼底图像中心区域的多个同心矩形中提取特征进行训练,并取得了较好的识别效果. ...
Comparing humans and deep learning performance for grading AMD:a study in using universal deep features and transfer learning for automated AMD analysis
1
2017
... 近年来,随着深度学习在计算机视觉和模式识别领域的成功发展,基于眼底图像的疾病筛查和识别方法不断涌现.Pratt H等人[3 ] 以及Colas E等人[4 ] 提出了使用深度神经网络的方法对5 000位患有糖尿病性视网膜病变(diabetic retinopathy,DR)患者的10 000张眼底图像进行特征提取,将DR患病阶段分为4类:轻度病变、中度病变、重度病变和扩散,为计算机辅助DR的诊断做出了贡献;WorrallD E 等人[5 ] 提出基于深度学习的端到端系统对早产儿视网膜病变(ROP)进行早期诊断,他们对经过预训练的GoogleNet模型进行微调后,在私有数据集上对ROP疾病的诊断准确率达到95.4%;BurlinaP等人[6 ] 提出使用 ImageNet 预训练权重的深度卷积神经网络对年龄相关性黄斑变性(age-related macular degeneration,ARMD)正常、早期、中期、晚期的 4 个阶段进行识别,基于该疾病的特性,深度卷积神经网络从眼底图像中心区域的多个同心矩形中提取特征进行训练,并取得了较好的识别效果. ...
Multi-class Alzheimer’s disease classification using image and clinical features
1
2018
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
Skin disease classification versus skin lesion characterization:achieving robust diagnosis using multi-label deep neural networks
1
2016
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
Multi-class disease classification in brain MRIs using a computer-aided diagnostic system
1
2017
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
Deep learning is effective for classifying normal versus age-related macular degeneration OCT images
1
2017
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
Multi-retinal disease classification by reduced deep learning features
1
2017
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
Retinal abnormalities recognition using regional multitask learning
2
2019
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
... 本文方法和对比方法的实验结果
方法 多种疾病筛查结果ACC 多种疾病筛查结果AUC 多种疾病识别结果ACC 多种疾病识别结果mAP Three-Stream[12 ] 91.57% 91.36% 63.47% 62.98% ResNet50[23 ] 93.77% 93.54% 60.55% 61.09% VGG16[24 ] 88.24% 89.12% 57.43% 56.21% EfficientNet-B5 94.35% 93.89% 67.88% 65.73% EfficientNet-B6 94.74% 95.33% 68.74% 67.35% EfficientNet-B7 95.16% 95.32% 70.45% 69.89% 本文方法 9 6 . 0 5 % 9 7 . 1 8 % 7 2 . 5 5 % 7 3 . 2 4 %
10.11959/j.issn.2096-6652.202127.F010 图10 视网膜多种疾病筛查结果 ![]()
10.11959/j.issn.2096-6652.202127.F011 图11 视网膜多种疾病识别结果 ![]()
5 结束语 本文在视网膜多种疾病筛查和识别问题中,针对视网膜疾病种类繁多、病灶位置不确定、罕见疾病样本数量少等难题,首先提出了比较有效的图像数据增强和图像去噪方法,去除了视网膜眼底图像中冗余的黑框,提高了图像病灶位置的成像效果;结合使用深度卷积神经网络和集成学习的方法,对视网膜眼底图像的病灶特征进行提取,用于后续对多种疾病的筛查和识别.通过实验表明,在面临近30种视网膜疾病时,本文提出的方法能够有效地提升筛查和识别的准确率,可辅助眼科医生对患者进行初步诊断.本文方法虽取得了较好的结果,但在模型训练过程中仍存在耗时长、训练轮次多的问题,单次模型训练时间需4~6 h,如何对该模型做进一步的优化以提升模型的性能仍待解决.另外,模型在多种疾病识别任务中的准确率虽能达到72.55%,但仍有进一步提升的空间,这也是未来研究工作中的一个方向. ...
Multi-categorical deep learning neural network to classify retinal images:a pilot study employing small database
1
2017
... 以上工作为视网膜疾病中的某个单一疾病或某个疾病的不同阶段的诊断做出了突出的贡献.实际上,视网膜疾病的筛查和识别并非针对单一疾病,且同一患者可能同时患有多种疾病,这就涉及对多种疾病进行识别和诊断的问题.区别于对单一疾病进行诊断的模型,针对多种疾病进行筛查和识别的模型更有助于辅助医生做初步判断.其中,参考文献[7 ,8 ,9 ,10 ]使用深度神经网络的方法在各种疾病图像中提取病灶特征,根据相关疾病的特点设计网络结构,实现对多种疾病的识别.针对视网膜眼底图像,Arunkumar R等人[11 ] 提出了一种通过深度学习提取视网膜疾病特征后进行特征降维的方法,使用支持向量机(support vector machine,SVM)分类器对老年性黄斑变性和糖尿病性视网膜病变两种视网膜疾病进行识别分类;Wang X等人[12 ] 使用集成学习的方法对视盘、黄斑和整个视网膜区域分别训练分类模型,并集成最终结果,该方法在糖尿病性视网膜病变和青光眼疾病的识别上有较好的效果.ChoiJ Y等人[13 ] 使用VGG(visual geometry group)网络和迁移学习的方法对视网膜疾病进行分类,疾病种类少时效果较好,但是在对 10 种视网膜疾病进行分类时,准确率仅为36.7%.以上这些方法仅适用于对两种或极少种类的疾病进行识别,存在任务难度较小或识别效果不理想等问题. ...
人工智能诊断系统在视网膜疾病的研究进展
1
2020
... 深度学习模型的训练需要海量的数据做支撑,而一些罕见的视网膜疾病难以获得足够的训练数据[14 ] ,深度学习在医学图像处理上的应用使得这一问题尤为凸显.在仅有少量数据集的条件下,训练一个效果良好、泛化性能较强的模型需要根据现有的少量数据进行数据增强,以满足深度神经网络模型对大数据量的需求.本文在训练前和训练过程中使用不同的数据增强方法,有效解决了数据量不足的问题. ...
人工智能诊断系统在视网膜疾病的研究进展
1
2020
... 深度学习模型的训练需要海量的数据做支撑,而一些罕见的视网膜疾病难以获得足够的训练数据[14 ] ,深度学习在医学图像处理上的应用使得这一问题尤为凸显.在仅有少量数据集的条件下,训练一个效果良好、泛化性能较强的模型需要根据现有的少量数据进行数据增强,以满足深度神经网络模型对大数据量的需求.本文在训练前和训练过程中使用不同的数据增强方法,有效解决了数据量不足的问题. ...
Contrast limited adaptive histogram equalization
1
1994
... 首先,在训练前,对输入图像采用图形变换的方式进行数据增强.使用的方法包括随机裁剪、垂直和水平方向翻转、随机角度旋转、增加高斯噪声、限制对比度自适应直方图均衡化(CLAHE)等.其中, Zuiderveld K [15 ] 提出的CLAHE方法是对直方图均衡化的改进,通过将原始图像的灰度直方图划分成若干个子区域,对子区域分别进行受对比度限制的直方图均衡化,再利用双线性差值消除各个子区域间比较明显的截断部分,得到一张对比度增强的图像.这一方法使一些受光照条件影响而过暗或过亮的图像获得更加清晰的成像效果. ...
CutMix:regularization strategy to train strong classifiers with localizable features
1
2019
... 另外,在训练过程中引入了Yun S等人[16 ] 提出的 CutMix 数据增强方法,即将每个小批量中的图像进行随机拼接组合,并加权计算总损失.其原理如图1 所示. ...
EfficientNet:rethinking model scaling for convolutional neural networks
2
2019
... 本文将谷歌大脑团队提出的 EfficientNet[17 ] 作为模型的主干网络部分进行特征提取,该网络可对网络的深度、宽度和输入的分辨率进行适当的调整,以达到更好的特征提取效果. ...
... 在EfficientNet中,最核心的MBConv模块结构如图2 所示.该模块源于MobileNet-V3[18 ] 中的倒置残差模块(inverted residual block),Tan M X等人[17 ] 对其进行改进,采用了Swish激活函数[19 ] ,并引入了Hu J等人[20 ] 在SENet中提出的SE(squeezeand-excitation)模块,将通道注意力机制应用于特征提取过程中.Swish激活函数如式(7)所示: ...
Searching for MobileNetV3
1
2019
... 在EfficientNet中,最核心的MBConv模块结构如图2 所示.该模块源于MobileNet-V3[18 ] 中的倒置残差模块(inverted residual block),Tan M X等人[17 ] 对其进行改进,采用了Swish激活函数[19 ] ,并引入了Hu J等人[20 ] 在SENet中提出的SE(squeezeand-excitation)模块,将通道注意力机制应用于特征提取过程中.Swish激活函数如式(7)所示: ...
Searching for activation functions
1
... 在EfficientNet中,最核心的MBConv模块结构如图2 所示.该模块源于MobileNet-V3[18 ] 中的倒置残差模块(inverted residual block),Tan M X等人[17 ] 对其进行改进,采用了Swish激活函数[19 ] ,并引入了Hu J等人[20 ] 在SENet中提出的SE(squeezeand-excitation)模块,将通道注意力机制应用于特征提取过程中.Swish激活函数如式(7)所示: ...
Squeeze-and-excitation networks
1
2018
... 在EfficientNet中,最核心的MBConv模块结构如图2 所示.该模块源于MobileNet-V3[18 ] 中的倒置残差模块(inverted residual block),Tan M X等人[17 ] 对其进行改进,采用了Swish激活函数[19 ] ,并引入了Hu J等人[20 ] 在SENet中提出的SE(squeezeand-excitation)模块,将通道注意力机制应用于特征提取过程中.Swish激活函数如式(7)所示: ...
Deep residual learning for image recognition
1
2016
... 首先,MBConv模块使用1×1卷积(Conv2d)对输入做升维操作得到特征图f1 ,利用3×3或5×5的通道维度卷积(DepthConv2d)得到相同维度的特征图f2 ,其中,卷积操作后含有归一化层(BN)和激活层(Swish);特征图f2 经过 SE 模块中 1×1卷积和平均池化(average pool)后计算出通道注意力权重fSE ,再将fSE 与f2 相乘,获得带有注意力的特征图f3 .最后,经过全连接层后,与原始输入的特征图进行残差连接,在一定程度上缓解了随着网络深度的增加带来的网络退化和过拟合问题[21 ] ,最终输出新的特征图(output). ...
Retinal fundus multi-disease image dataset (RFMiD):a dataset for multi-disease detection research
1
2021
... 本文将IEEE ISBI 2021[22 ] 中的视网膜眼底图像作为数据集,该数据集分别使用 3 台数码眼底照相机采集,共2 560张视网膜眼底图像,其中1 920张图像为训练集,640张图像为测试集.这2 560张图像中共包含3种分辨率,分别为4 288×2 848、2 144×1 424和2 048×1 536.此外,数据集包含48种视网膜疾病,其中较为罕见的疾病将被统一标记为“其他(OTHER)”类别,包括“其他”类别在内共有28 种疾病,且每个图像样本为正常或至少包含一种疾病.其余27种疾病如下:糖尿病性视网膜病变(DR)、年龄相关性黄斑变性(ARMD)、屈光介质混浊(media haze,MH)、玻璃疣(drusen,DN)、近视(myopia,MYA)、视网膜静脉分枝阻塞(branch retinal vein occlusion,BRVO)、镶 嵌 眼 底(tessellation,TSLN)、黄斑视网膜前膜(macular epiretinal membrane,ERM)、激光瘢痕(laser scar, LS)、黄斑瘢痕(macular scar,MS)、中心性浆液性脉络膜视网膜病变(central serous chorioretinopathy,CSR)、视神经盘凹(optic disc cupping, ODC)、视网膜中央静脉阻塞(central retinal vein occlusion,CRVO)、血管迂曲(vascular circuity)(原数据集用 TV 表示)、星状玻璃体病变(asteroid hyalosis,AH)、视盘苍白(optic disc pallor,ODP)、视盘水肿(optic disc edema,ODE)、分流(shunt, ST)、前部缺血性视神经病变(anterior ischemic optic neuropathy,AION)、中心凹毛细管扩张(parafoveal telangiectasia,PT)、视网膜牵引(retinal traction, RT)、视网膜炎(retinitis,RS)、脉络膜视网膜炎(chorioretinitis,CRS)、渗出(exudation,EDN)、视网膜色素上皮改变(retinal pigment epithelium change,RPEC)、黄斑裂孔(macular hole,MHL)、色素性视网膜炎(retinitis pigmentosa,RP). ...
Deep residual learning for image recognition
1
2016
... 本文方法和对比方法的实验结果
方法 多种疾病筛查结果ACC 多种疾病筛查结果AUC 多种疾病识别结果ACC 多种疾病识别结果mAP Three-Stream[12 ] 91.57% 91.36% 63.47% 62.98% ResNet50[23 ] 93.77% 93.54% 60.55% 61.09% VGG16[24 ] 88.24% 89.12% 57.43% 56.21% EfficientNet-B5 94.35% 93.89% 67.88% 65.73% EfficientNet-B6 94.74% 95.33% 68.74% 67.35% EfficientNet-B7 95.16% 95.32% 70.45% 69.89% 本文方法 9 6 . 0 5 % 9 7 . 1 8 % 7 2 . 5 5 % 7 3 . 2 4 %
10.11959/j.issn.2096-6652.202127.F010 图10 视网膜多种疾病筛查结果 ![]()
10.11959/j.issn.2096-6652.202127.F011 图11 视网膜多种疾病识别结果 ![]()
5 结束语 本文在视网膜多种疾病筛查和识别问题中,针对视网膜疾病种类繁多、病灶位置不确定、罕见疾病样本数量少等难题,首先提出了比较有效的图像数据增强和图像去噪方法,去除了视网膜眼底图像中冗余的黑框,提高了图像病灶位置的成像效果;结合使用深度卷积神经网络和集成学习的方法,对视网膜眼底图像的病灶特征进行提取,用于后续对多种疾病的筛查和识别.通过实验表明,在面临近30种视网膜疾病时,本文提出的方法能够有效地提升筛查和识别的准确率,可辅助眼科医生对患者进行初步诊断.本文方法虽取得了较好的结果,但在模型训练过程中仍存在耗时长、训练轮次多的问题,单次模型训练时间需4~6 h,如何对该模型做进一步的优化以提升模型的性能仍待解决.另外,模型在多种疾病识别任务中的准确率虽能达到72.55%,但仍有进一步提升的空间,这也是未来研究工作中的一个方向. ...
Very deep convolutional networks for large-scale image recognition
1
... 本文方法和对比方法的实验结果
方法 多种疾病筛查结果ACC 多种疾病筛查结果AUC 多种疾病识别结果ACC 多种疾病识别结果mAP Three-Stream[12 ] 91.57% 91.36% 63.47% 62.98% ResNet50[23 ] 93.77% 93.54% 60.55% 61.09% VGG16[24 ] 88.24% 89.12% 57.43% 56.21% EfficientNet-B5 94.35% 93.89% 67.88% 65.73% EfficientNet-B6 94.74% 95.33% 68.74% 67.35% EfficientNet-B7 95.16% 95.32% 70.45% 69.89% 本文方法 9 6 . 0 5 % 9 7 . 1 8 % 7 2 . 5 5 % 7 3 . 2 4 %
10.11959/j.issn.2096-6652.202127.F010 图10 视网膜多种疾病筛查结果 ![]()
10.11959/j.issn.2096-6652.202127.F011 图11 视网膜多种疾病识别结果 ![]()
5 结束语 本文在视网膜多种疾病筛查和识别问题中,针对视网膜疾病种类繁多、病灶位置不确定、罕见疾病样本数量少等难题,首先提出了比较有效的图像数据增强和图像去噪方法,去除了视网膜眼底图像中冗余的黑框,提高了图像病灶位置的成像效果;结合使用深度卷积神经网络和集成学习的方法,对视网膜眼底图像的病灶特征进行提取,用于后续对多种疾病的筛查和识别.通过实验表明,在面临近30种视网膜疾病时,本文提出的方法能够有效地提升筛查和识别的准确率,可辅助眼科医生对患者进行初步诊断.本文方法虽取得了较好的结果,但在模型训练过程中仍存在耗时长、训练轮次多的问题,单次模型训练时间需4~6 h,如何对该模型做进一步的优化以提升模型的性能仍待解决.另外,模型在多种疾病识别任务中的准确率虽能达到72.55%,但仍有进一步提升的空间,这也是未来研究工作中的一个方向. ...











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}