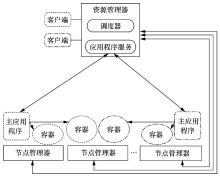
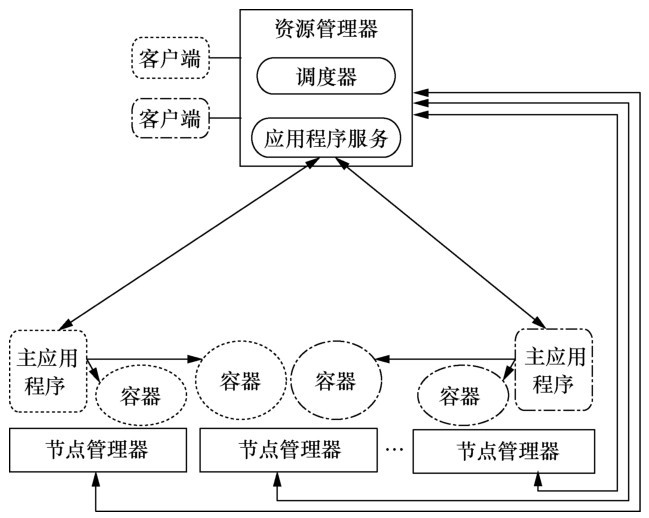
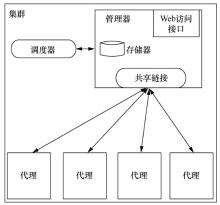
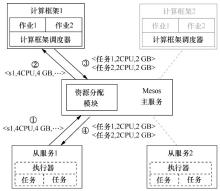
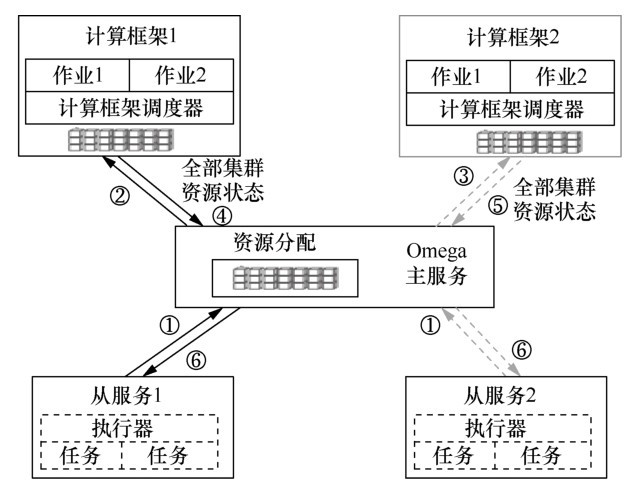
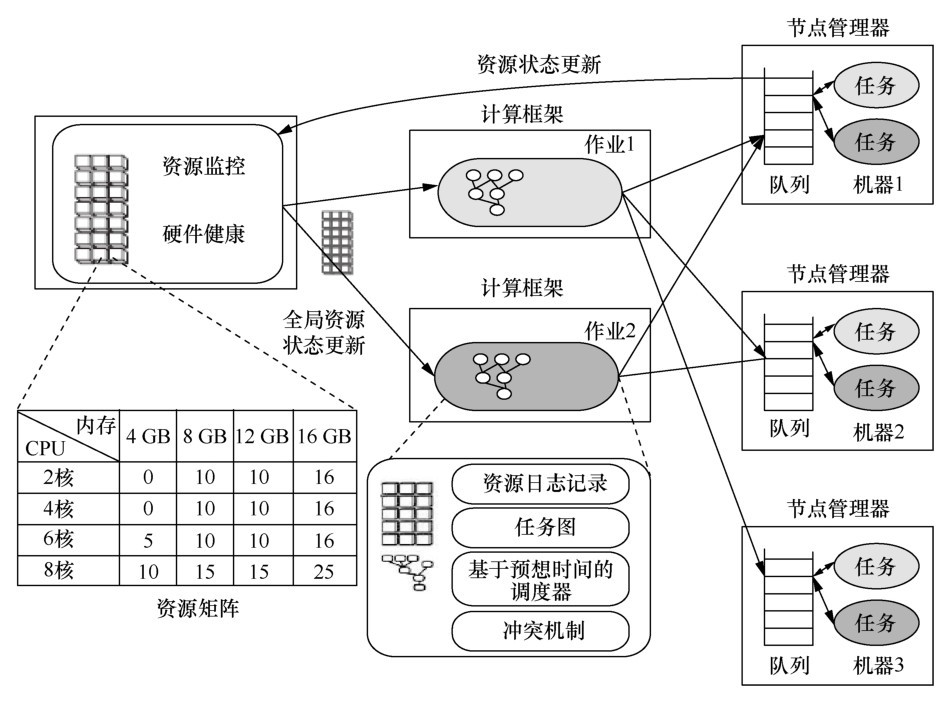
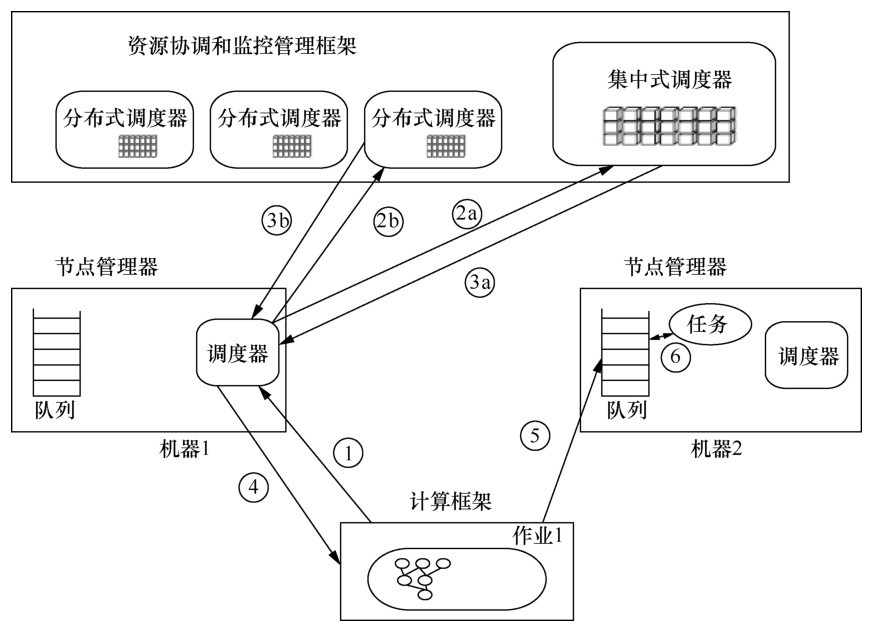
| [1] |
HOVESTADT M , KAO O , KELLER A ,et al. Scheduling in HPC resource management systems:queuing vs planning[J]. Genetica, 2003:112-113(1): 445-461.
|
| [2] |
MISHRA M K , PATEL Y S , ROUT Y ,et al. A survey on scheduling heuristics in grid computing environment[J]. International Journal of Modern Education and Computer Science, 2014,6(10): 57-77.
|
| [3] |
杜小勇, 陈跃国, 范举 ,等. 数据整理——大数据治理的关键技术[J]. 大数据, 2019,5(3): 13-22.
|
|
DU X Y , CHEN Y G , FAN J ,et al. Data wrangling:a key technique of data governance[J]. Big Data Research, 2019,5(3): 13-22.
|
| [4] |
陈康, 郑纬民 . 云计算:系统实例与研究现状[J]. 软件学报, 2009,20(5): 1337-1348.
|
|
CHEN K , ZHENG W M . Cloud computing:system instances and current research[J]. Journal of Software, 2009,20(5): 1337-1348.
|
| [5] |
KARANASOS K , RAO S , CURINO C ,et al. Mercury:hybrid centralized and distributed scheduling in large shared clusters[C]// 2015 USENIX Annual Technical Conference. Berkeley:USENIX Association, 2015: 485-497.
|
| [6] |
DEAN J , GHEMAWAT S . MapReduce:simplified data processing on large clusters[J]. Communications of the ACM, 2008,51(1): 107-113.
|
| [7] |
PARK J J K , PARK Y , MAHLKE S . Dynamic resource management for efficient utilization of multitasking GPUs[C]// The 22nd International Conference on Architectural Support for Programming Languages and Operating Systems. New York:ACM Press, 2017: 527-540.
|
| [8] |
ZAHARIA M , CHOWDHURY M , DAS T ,et al. Resilient distributed datasets:a fault-tolerant abstraction for inmemory cluster computing[C]// The 9th USENIX Networked Systems Design and Implementation. Berkeley:USENIX Association, 2012: 2-14.
|
| [9] |
ARMBRUST M , XIN R S , LIAN C ,et al. Spark SQL:relational data processing in Spark[C]// The 2015 ACM SIGMOD International Conference on Management of Data. New York:ACM Press, 2015: 1383-1394.
|
| [10] |
CARBONE P , KATSIFODIMOS A , EWEN S ,et al. Apache Flink:stream and batch processing in a single engine[J]. IEEE Data Engineering Bulletin, 2015,38(4): 28-38.
|
| [11] |
FUKUTOMI D , IIDA Y , AZUMI T ,et al. GPUhd:augmenting YARN with GPU resource management[C]// International Conference on High Performance Computing in Asia-Pacific Region. New York:ACM Press, 2018: 127-136.
|
| [12] |
VERMA A , PEDROSA L , KORUPOLU M .et al Large-scale cluster management at Google with Borg[C]// The 10th European Conference on Computer Systems. New York:ACM Press, 2015: 1-17.
|
| [13] |
HINDMAN B , KONWINSKI A , ZAHARIA M ,et al. Mesos:a platform for finegrained resource sharing in the data center[C]// The 8th USENIX Conference on Networked Systems Design and Implementation. Berkeley:USENIX Association, 2011: 295-308.
|
| [14] |
BOUTIN E , EKANAYAKE J , LIN W ,et al. Apollo:scalable and coordinated scheduling for cloud-scale computing[C]// The 11th USENIX Conference on Operating Systems Design and Implementation. Berkeley:USENIX Association, 2014: 285-300.
|
| [15] |
KONSTANTINOS K , SRIRAM R , CARLO C ,et al. Mercury:hybrid centralized and distributed scheduling in large shared clusters[C]// 2015 USENIX Annual Technical Conference. Berkeley:USENIX Association, 2015: 485-497.
|
| [16] |
AKIDAU T , BRADSHAW R , CHAMBERS C ,et al. The dataflow model:a practical approach to balancing correctness,latency,and cost in massive-scale,unbounded,out-of-order data processing[J]. Proceedings of the VLDB Endowment, 2015,8(12): 1792-1803.
|