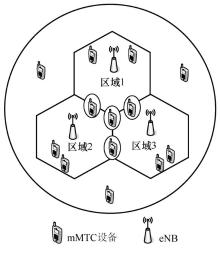
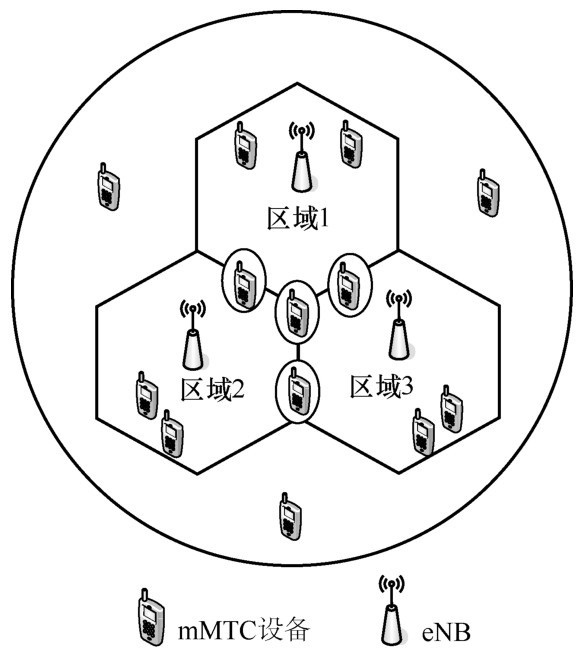
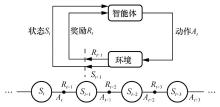
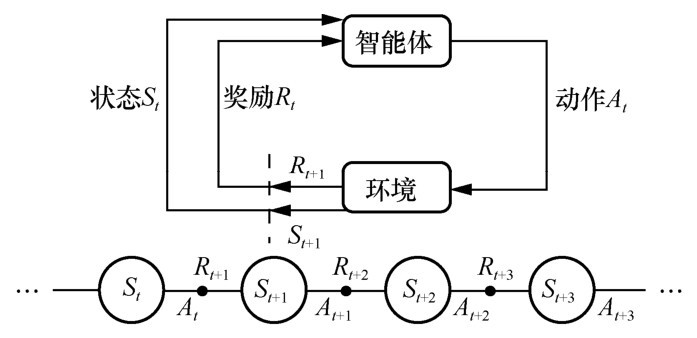
| [1] |
TULLBERG H , POPOVSKI P , LI Z X ,et al. The METIS 5G system concept:meeting the 5G requirements[J]. IEEE Communications Magazine, 2016,54(12): 132-139.
|
| [2] |
Latva-aho M , Lepp?nen K , Clazzer F ,et al. Key drivers and research challenges for 6G ubiquitous wireless intelligence[J]. 2016.
|
| [3] |
BI Q . Ten trends in the cellular industry and an outlook on 6G[J]. IEEE Communications Magazine, 2019,57(12): 31-36.[LinkOut]
|
| [4] |
董石磊, 赵婧博 . 面向工业场景的 5G 专网解决方案研究[J]. 电信科学, 2021,37(11): 97-103.
|
|
DONG S L , ZHAO J B . Research on 5G private networking schemes for industry[J]. Telecommunications Science, 2021,37(11): 97-103.
|
| [5] |
POPLI S , JHA R K , JAIN S . A survey on energy efficient narrowband internet of things (NBIoT):architecture,application and challenges[J]. IEEE Access, 2018(7): 16739-16776.
|
| [6] |
NAVARRO-ORTIZ J , ROMERO-DIAZ P , SENDRA S ,et al. A survey on 5G usage scenarios and traffic models[J]. IEEE Communications Surveys & Tutorials, 2020,22(2): 905-929.
|
| [7] |
ANALYTICS S . Number of Internet of things(IoT) connected devices worldwide in 2018,2025 and 2030(in billions)[J]. Statista Inc, 2020,(7): 17.
|
| [8] |
SHARMA S K , WANG X B . Toward massive machine type communications in ultra-dense cellular IoT networks:current issues and machine learning-assisted solutions[J]. IEEE Communications Surveys & Tutorials, 2020,22(1): 426-471.
|
| [9] |
3GPP. Study on RAN improvements for machine-type communications:TR 37.868[R]. 2011.
|
| [10] |
ALI M S , HOSSAIN E , KIM D I . LTE/LTE-A random access for massive machine-type communications in smart cities[J]. IEEE Communications Magazine, 2017,55(1): 76-83.
|
| [11] |
SHARMA S K , WANG X B . Collaborative distributed Q-learning for RACH congestion minimization in cellular IoT networks[J]. IEEE Communications Letters, 2019,23(4): 600-603.
|
| [12] |
DA SILVA M V , SOUZA R D , ALVES H ,et al. A NOMA-based Q-learning random access method for machine type communications[J]. IEEE Wireless Communications Letters, 2020,9(10): 1720-1724.
|
| [13] |
TSOUKANERI G , WU S B , WANG Y . Probabilistic preamble selection with reinforcement learning for massive machine type communication (MTC) devices[C]// Proceedings of 2019 IEEE 30th Annual International Symposium on Personal,Indoor and Mobile Radio Communications. Piscataway:IEEE Press, 2019: 1-6.
|
| [14] |
PACHECO-PARAMO D , TELLO-OQUENDO L . Adjustable access control mechanism in cellular MTC networks:a double Q-learning approach[C]// Proceedings of 2019 IEEE Fourth Ecuador Technical Chapters Meeting. Piscataway:IEEE Press, 2019: 1-6.
|
| [15] |
BAI J N , SONG H , YI Y ,et al. Multiagent reinforcement learning meets random access in massive cellular Internet of Things[J]. IEEE Internet of Things Journal, 2021,8(24): 17417-17428.
|
| [16] |
MOHAMMED A H , KHWAJA A S , ANPALAGAN A ,et al. Base Station selection in M2M communication using Q-learning algorithm in LTE-A networks[C]// Proceedings of 2015 IEEE 29th International Conference on Advanced Information Networking and Applications. Piscataway:IEEE Press, 2015: 17-22.
|
| [17] |
LEE D , ZHAO Y , LEE J . Reinforcement learning for random access in multi-cell networks[C]// Proceedings of 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). Piscataway:IEEE Press, 2021: 335-338.
|
| [18] |
MOON J , LIM Y . Access control of MTC devices using reinforcement learning approach[C]// Proceedings of 2017 International Conference on Information Networking (ICOIN). Piscataway:IEEE Press, 2017: 641-643.
|
| [19] |
LIEN S Y , CHEN K C , LIN Y H . Toward ubiquitous massive accesses in 3GPP machine-to-machine communications[J]. IEEE Communications Magazine, 2011,49(4): 66-74.
|
| [20] |
VAN HASSELT H , GUEZ A , SILVER D . Deep reinforcement learning with double q-learning[C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2016: 2094-2100.
|
| [21] |
SILVER D , HUANG A , MADDISON C J ,et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016,529(7587): 484-489.
|
| [22] |
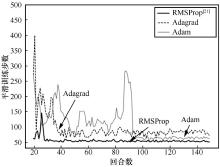
TIELEMAN T , HINTON G . Lecture 6.5-rmsprop:divide the gradient by a running average of its recent magnitude[J]. COURSERA:Neural networks for machine learning, 2012,4(2): 26-31.
|