

电信科学 ›› 2023, Vol. 39 ›› Issue (3): 124-134.doi: 10.11959/j.issn.1000-0801.2023045
刘昊双1, 张永2,3, 曹莹波1
修回日期:2023-03-15
出版日期:2023-03-20
发布日期:2023-03-01
作者简介:刘昊双(1996- ),女,辽宁师范大学硕士生,主要研究方向为数据挖掘、机器学习基金资助:Haoshuang LIU1, Yong ZHANG2,3, Yingbo CAO1
Revised:2023-03-15
Online:2023-03-20
Published:2023-03-01
Supported by:摘要:
域漂移严重影响了传统机器学习方法的性能,现有的领域自适应方法主要通过全局、类级或样本级分布匹配自适应地调整跨域表示。但全局匹配和类级匹配过于粗糙会导致自适应不足,而样本级匹配受到噪声的影响可能导致过度自适应。基于此,提出了一种基于K均值(K-means)聚类的子结构相关适配(SCOAD)迁移学习算法,首先通过 K-means 聚类分别获得源域和目标域的多个子域,其次寻求子域中心二阶统计量的匹配,最后利用子域内结构对目标域样本进行分类。该方法在传统方法的基础上进一步提高了源域与目标域之间知识迁移的性能。在常用迁移学习数据集上的实验结果表明了所提方法的有效性。
刘昊双, 张永, 曹莹波. 基于K-means聚类的子结构相关适配迁移学习方法[J]. 电信科学, 2023, 39(3): 124-134.
Haoshuang LIU, Yong ZHANG, Yingbo CAO. Substructure correlation adaptation transfer learning method based on K-means clustering[J]. Telecommunications Science, 2023, 39(3): 124-134.
表1
SCOAD算法与几种方法的比较"
| 方法 | BDA[ | OTDA[ | LDA[ | SCOAD(本文) |
| 参数 | μ | α , ,λη | λ, 1λ,η,kt | K |
| 子结构适配 | 不是 | 不是 | 是 | 是 |
| 子域内规划 | 不是 | 不是 | 不是 | 是 |
| 特征对齐 | 是 | 不是 | 不是 | 是 |
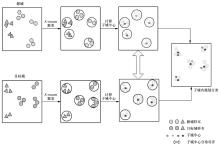
图1
SCOAD算法的主要过程"

图2
概率标注矩阵的示例"

表2
实验数据集信息"
| 数据集 | 名称 | 特征维数 | 类别 | 样本个数 |
| USPS+MNIST | USPS | 256 | 10 | 1 800 |
| MNIST | 256 | 10 | 2 000 | |
| Office-Caltech10 | Caltech | 800 | 10 | 1 123 |
| Webcam | 800 | 10 | 295 | |
| Amazon | 800 | 10 | 958 | |
| DSLR | 800 | 10 | 157 | |
| Amazon Review | Kitchen | 400 | 2 | 1 999 |
| DVDs | 400 | 2 | 1 999 | |
| Electronics | 400 | 2 | 1 998 | |
| Books | 400 | 2 | 2 000 |
表3
7种算法在14个迁移学习任务上的准确率对比"
| 数据集 | 1-NN | TCA | TJM | OTDA | CORAL | EASYTL | SCOAD |
| MNIST→USPS | 65.9% | 54.3% | 42.9% | 49.3% | 65.6% | 54.5% | |
| USPS→MNIST | 44.7% | 41.4% | 50.7% | 46.9% | 31.0% | 51.2% | |
| Caltech→Amazon | 23.7% | 43.4% | 46.7% | 30.5% | 47.2% | 40.0% | |
| Caltech→Webcam | 25.8% | 37.3% | 38.0% | 23.8% | 39.2% | 42.0% | |
| Caltech→DSLR | 25.5% | 44.0% | 43.3% | 26.6% | 40.7% | 48.4% | |
| Amazon→Caltech | 26.0% | 38.2% | 39.6% | 29.4% | 40.3% | 38.6% | |
| Amazon→Webcam | 29.8% | 38.0% | 25.6% | 38.7% | |||
| Amazon→DSLR | 25.5% | 30.6% | 42.2% | 35.7% | 38.3% | 38.9% | |
| Webcam→Caltech | 19.9% | 29.7% | 30.2% | 25.9% | 34.6% | 29.7% | |
| Webcam→Amazon | 23.0% | 32.3% | 29.9% | 27.4% | 37.8% | 35.2% | |
| Webcam→DSLR | 59.2% | 82.4% | 76.5% | 84.9% | 77.1% | 75.8% | |
| DSLR→Caltech | 26.3% | 30.9% | 31.5% | 27.3% | 34.2% | 31.2% | |
| DSLR→Amazon | 28.5% | 29.3% | 32.6% | 29.1% | 31.9% | 36.5% | |
| DSLR→Webcam | 63.4% | 84.8% | 85.6% | 65.7% | 85.9% | 69.5% | |
| 平均值 | 34.8% | 44.8% | 45.2% | 37.4% | 48.0% | 45.0% |
表4
在Amazon Review数据集上迁移学习任务的准确率对比"
| 数据集 | 1-NN | TCA | BDA | JGSA | CORAL | SCOAD |
| Books→DVDs | 49.6% | 63.6% | 64.2% | 66.6% | 65.4% | |
| Books→Electronics | 49.8% | 60.9% | 62.1% | 65.1% | 69.2% | |
| Books→Kitchen | 50.3% | 64.2% | 65.4% | 72.1% | 67.3% | |
| DVDs→Books | 53.3% | 63.3% | 62.4% | 55.5% | 70.1% | |
| DVDs→Electronics | 51.0% | 64.2% | 66.3% | 67.3% | 65.6% | |
| DVDs→Kitchen | 53.1% | 69.1% | 68.9% | 65.6% | 67.1% | |
| Electronics→Books | 50.8% | 59.5% | 59.2% | 51.6% | 67.1% | |
| Electronics→DVDs | 50.9% | 62.1% | 61.6% | 50.8% | 66.2% | |
| Electronics→Kitchen | 51.2% | 74.8% | 74.7% | 55.0% | 77.6% | |
| Kitchen→Books | 52.2% | 64.1% | 62.7% | 58.3% | 68.2% | |
| Kitchen→DVDs | 51.2% | 65.4% | 64.3% | 56.4% | 68.9% | |
| Kitchen→Electronics | 52.3% | 74.5% | 74.0% | 51.7% | 75.4% | |
| 平均值 | 51.3% | 65.5% | 65.5% | 60.5% | 69.2% |
表5
在MNIST + USPS、Office + Caltech10数据集上表的Friedman检验结果"
| 算法 | 1-NN | TCA | TJM | OTDA | CORAL | EASYTL | SCOAD |
| 序值 | 6.35 | 4.25 | 3.50 | 5.78 | 2.71 | 3.24 |
表6
在Amazon Review数据集上的Friedman检验结果"
| 算法 | 1-NN | TCA | BDA | JGSA | CORAL | SCOAD |
| 序值 | 5.83 | 3.58 | 3.83 | 4.08 | 2.42 |
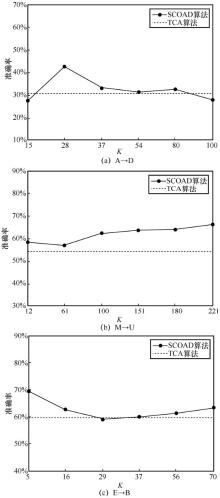
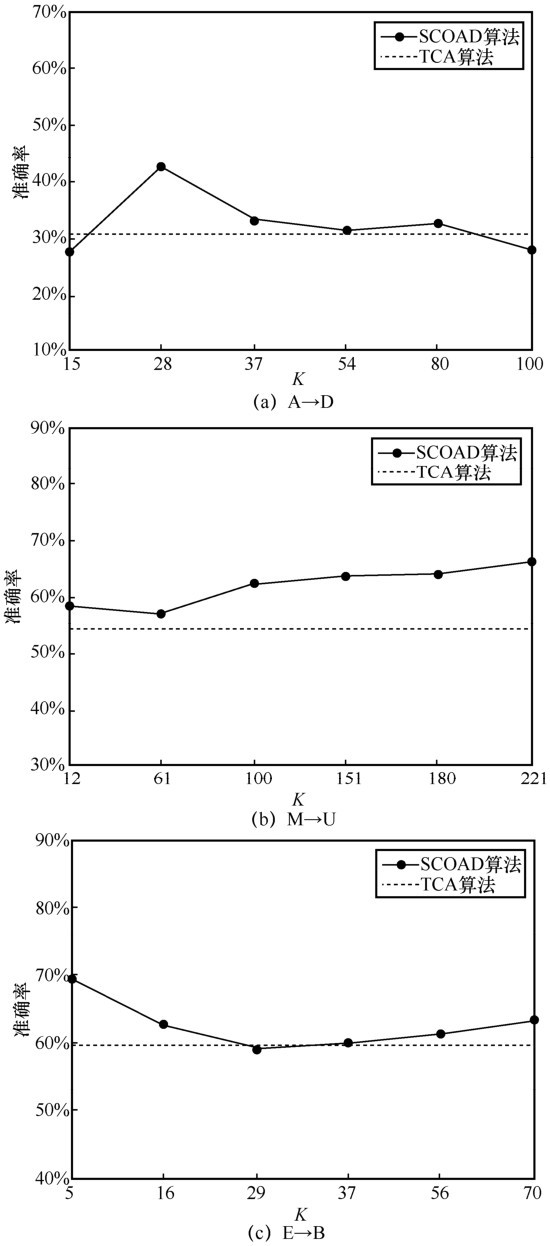
图3
簇数K对SCODA算法性能的影响"
| [1] | ZHUANG F Z , QI Z Y , DUAN K Y ,et al. A comprehensive survey on transfer learning[J]. Proceedings of the IEEE, 2021,109(1): 43-76. |
| [2] | GRETTON A , BORGWARDT K M , RASCH M J ,et al. A kernel two-sample test[J]. The Journal of Machine Learning Research, 2012,13(1): 723-773. |
| [3] | SUN B C , FENG J S , SAENKO K . Return of frustratingly easy domain adaptation[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2016,30(1): 2058-2065. |
| [4] | GAO J , HUANG R , LI H X . Sub-domain adaptation learning methodology[J]. Information Sciences, 2015(298): 237-256. |
| [5] | ZHU Y C , ZHUANG F Z , WANG J D ,et al. Deep subdomain adaptation network for image classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021,32(4): 1713-1722. |
| [6] | KRISHNA K , NARASIMHA M M . Genetic K-means algorithm[J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B (Cybernetics), 1999,29(3): 433-439. |
| [7] | HARTIGAN J A , WONG M A . A K-means clustering algorithm[J]. Journal of the Royal Statistical Society Series C:Applied Statistics, 1979,28(1): 100-108. |
| [8] | LECUN Y , BOTTOU L , BENGIO Y ,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324. |
| [9] | HULL J J . A database for handwritten text recognition research[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994,16(5): 550-554. |
| [10] | GONG B Q , SHI Y , SHA F ,et al. Geodesic flow kernel for unsupervised domain adaptation[C]// Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2012: 2066-2073. |
| [11] | CHEN M , XU Z , WEINBERGER K ,et al. Marginalized denoising autoencoders for domain adaptation[EB]. 2012:arXiv:1206.4683. |
| [12] | JIANG S Y , XU Y H , SONG H J ,et al. Multi-instance transfer metric learning by weighted distribution and consistent maximum likelihood estimation[J]. Neurocomputing, 2018(321): 49-60. |
| [13] | ZUO H , ZHANG G Q , BEHBOOD V ,et al. Transfer learning in hierarchical feature spaces[C]// Proceedings of 2015 10th International Conference on Intelligent Systems and Knowledge Engineering (ISKE). Piscataway:IEEE Press, 2016: 183-188. |
| [14] | ZHAO Z , CHEN Y , LIU J ,et al. Cross-people mobile-phone based activity recognition[C]// Proceedings of the 22th International Joint Conference on Artificial Intelligence. Barcelona,Catalonia,Spain:AAAI Press, 2011: 2545-2550. |
| [15] | WEI Y , ZHU Y , LEUNG C ,et al. Instilling social to physical:Co-regularized heterogeneous transfer learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2016,30(1): 1338-1344. |
| [16] | MIHALKOVA L , HUYNH T , MOONEY R J . Mapping and revising Markov logic networks for transfer learning[C]// Proceedings of the 22nd National Conference on Artificial intelligence. Vancouver,BC,Canada:AAAI Press, 2007: 608-614. |
| [17] | MIHALKOVA L , MOONEY R J . Transfer learning by mapping with minimal target data[C]// Proceedings of the AAAI-08 Workshop on Transfer Learning for Complex Tasks. Chicago,IL,USA:AAAI Press, 2008: 1163-1168. |
| [18] | WANG M , DENG W . Deep visual domain adaptation:a survey[J]. Neurocomputing, 2018(312): 135-153. |
| [19] | LI J , HE R , YE H ,et al. Unsupervised domain adaptation of a pretrained cross-lingual language mode[J]. ArXiv, 2020,preprint arXiv:2011.11499. |
| [20] | DAI Y , LIU J , REN X C ,et al. Adversarial training based multi-source unsupervised domain adaptation for sentiment analysis[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020,34(5): 7618-7625. |
| [21] | PAN S J , TSANG I W , KWOK J T ,et al. Domain adaptation via transfer component analysis[J]. IEEE Transactions on Neural Networks, 2011,22(2): 199-210. |
| [22] | LONG M S , WANG J M , DING G G ,et al. Transfer feature learning with joint distribution adaptation[C]// Proceedings of 2013 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2014: 2200-2207. |
| [23] | WANG J D , CHEN Y Q , HAO S J ,et al. Balanced distribution adaptation for transfer learning[C]// Proceedings of 2017 IEEE International Conference on Data Mining (ICDM). Piscataway:IEEE Press, 2017: 1129-1134. |
| [24] | COURTY N , FLAMARY R , TUIA D ,et al. Optimal transport for domain adaptation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(9): 1853-1865. |
| [25] | DAS D , LEE C S G . Unsupervised domain adaptation using regularized hyper-graph matching[C]// Proceedings of 2018 25th IEEE International Conference on Image Processing (ICIP). Piscataway:IEEE Press, 2018: 3758-3762. |
| [26] | PEI Z Y , CAO Z J , LONG M S ,et al. Multi-adversarial domain adaptation[C]// Proceedings of the thirty-second AAAI Conference on Artificial Intelligence. New Orleans,LA,USA:AAAI Press, 2018. |
| [27] | KUMAR A , SATTIGERI P , WADHAWAN K ,et al. Co-regularized alignment for unsupervised domain adaptation-[EB]. 2018,arXiv,1811.05443. |
| [28] | ZHAO J C , DENG F , HE H B ,et al. Local domain adaptation for cross-domain activity recognition[J]. IEEE Transactions on Human-Machine Systems, 2021,51(1): 12-21. |
| [29] | ESTER M , KRIEGEL H P , SANDER J ,et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the Second International Conference on Knowledge Discovery and Data Mining. Portland,OR,USA:AAAI Press, 1996: 226-231. |
| [30] | 徐晓, 丁世飞, 孙统风 ,等. 基于网格筛选的大规模密度峰值聚类算法[J]. 计算机研究与发展, 2018,55(11): 2419-2429. |
| XU X , DING S F , SUN T F ,et al. Large-scale density peaks clustering algorithm based on grid screening[J]. Journal of Computer Research and Development, 2018,55(11): 2419-2429. | |
| [31] | LONG M S , WANG J M , DING G G ,et al. Transfer joint matching for unsupervised domain adaptation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. New York:ACM, 2014: 1410-1417. |
| [32] | WANG J D , CHEN Y Q , YU H ,et al. Easy transfer learning by exploiting intra-domain structures[C]// Proceedings of 2019 IEEE International Conference on Multimedia and Expo (ICME). Piscataway:IEEE Press, 2019: 1210-1215. |
| [33] | ZHANG J , LI W Q , OGUNBONA P . Joint geometrical and statistical alignment for visual domain adaptation[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2017: 5150-5158. |
| [34] | GONG B Q , GRAUMAN K , SHA F . Reshaping visual datasets for domain adaptation[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems-Volume 1. New York:ACM, 2013: 1286-1294. |
| [1] | 祝文军, 王思宁, 高晓欣, 郑倩. 基于知识流和迁移学习的负荷预测[J]. 电信科学, 2022, 38(5): 114-123. |
| [2] | 赵海波, 相志军, 肖林松. 基于异构数据的电力短期负荷大数据预测方案[J]. 电信科学, 2022, 38(12): 103-111. |
| [3] | 金宁, 王庆扬. 基于聚类算法的6G典型应用场景研究[J]. 电信科学, 2022, 38(1): 121-131. |
| [4] | 陆勰, 徐雷, 张曼君. 基于聚类的安全分级虚拟网络映射方法[J]. 电信科学, 2021, 37(9): 112-117. |
| [5] | 刘子豪, 贾小军, 张素兰, 徐志玲, 张俊. 一种融合MeanShift聚类分析和卷积神经网络的Vibe++背景分割方法[J]. 电信科学, 2021, 37(3): 133-145. |
| [6] | 吴季桦, 朱鹏宇, 吴子辰, 顾彬, 洪涛, 郭波, 王晶, 王敬宇. 基于无监督聚类和频繁子图挖掘的电力通信网缺陷诊断与自动派单[J]. 电信科学, 2021, 37(11): 51-63. |
| [7] | 李想,李原,张子飞,杨哲. 基于密度聚类的网络性能故障大数据分析方法[J]. 电信科学, 2020, 36(9): 51-58. |
| [8] | 李亚杰,赵永利,刘守东,张杰. 基于人工智能的光纤非线性均衡算法研究概述[J]. 电信科学, 2020, 36(3): 61-70. |
| [9] | 孙洋,粟栗,张星,王峰生,杜海涛. 基于子语义空间的挖掘短文本策略方法[J]. 电信科学, 2020, 36(3): 83-94. |
| [10] | 朱应钊. 异构迁移学习研究综述[J]. 电信科学, 2020, 36(3): 100-110. |
| [11] | 江俊, 黄骅, 任条娟, 张登辉. 基于峰值密度聚类的电信业投诉热点话题检测方法[J]. 电信科学, 2019, 35(5): 97-103. |
| [12] | 马大燕. 基于自动聚类模型的输电线路外力破坏预警预测[J]. 电信科学, 2019, 35(3): 135-139. |
| [13] | 钟其柱, 吴修权, 罗耀满. 基于MDT智能分析LTE无线干扰的研究与应用[J]. 电信科学, 2019, 35(10): 130-136. |
| [14] | 袁泽恒,田润澜,王晓峰. 复杂体制雷达信号预分选的方法[J]. 电信科学, 2018, 34(9): 97-104. |
| [15] | 刘参,尚俊娜,李蕊江,岳克强. 基于迁移学习的室内动态环境定位算法[J]. 电信科学, 2018, 34(8): 98-108. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||