

电信科学 ›› 2024, Vol. 40 ›› Issue (1): 35-47.doi: 10.11959/j.issn.1000-0801.2024015
• 研究与开发 • 上一篇
徐海峰1, 王鸿奎1, 殷海兵1, 陈楚翘2
修回日期:2024-01-12
出版日期:2024-01-01
发布日期:2024-01-01
作者简介:徐海峰(1999- ),男,杭州电子科技大学通信工程学院硕士生,主要研究方向为感知视频编码基金资助:Haifeng XU1, Hongkui WANG1, Haibing YIN1, Chuqiao CHEN2
Revised:2024-01-12
Online:2024-01-01
Published:2024-01-01
Supported by:摘要:
视觉恰可察觉失真(just noticeable distortion,JND)直接反映人眼视觉系统对视觉信号噪声的敏感程度,广泛应用于图像和视频处理领域。针对视频 JND 阈值的多层级预测问题,将其转化为用户满意率(satisfied user ratio,SUR)曲线的预测问题,并提出一种基于特征融合的SUR曲线预测模型。该模型主要分为关键帧选择模块、特征提取和融合模块以及SUR分数回归模块。在关键帧选择模块,根据视觉感知机制,提出空时域感知复杂度并以此作为视频关键帧判决指标。在特征提取和融合模块,基于密集残差块(dense residual block,RDB)提出多尺度密集残差网络实现图像特征提取和多尺度融合。实验结果表明,所提出的SUR曲线预测模型在JND阈值预测精度方面整体优于现有模型,且在运行效率上平均降低8.1%的时间成本。同时,该模型还可以用于预测其他层级JND阈值,可直接应用于视频多层级感知编码优化。
中图分类号:
徐海峰, 王鸿奎, 殷海兵, 陈楚翘. 基于深度学习的多层级恰可察觉失真预测[J]. 电信科学, 2024, 40(1): 35-47.
Haifeng XU, Hongkui WANG, Haibing YIN, Chuqiao CHEN. Deep learning-based prediction of multi-level just noticeable distortion[J]. Telecommunications Science, 2024, 40(1): 35-47.
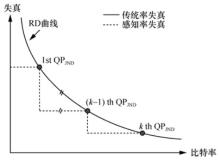
图1
压缩视频的传统和感知RD函数"
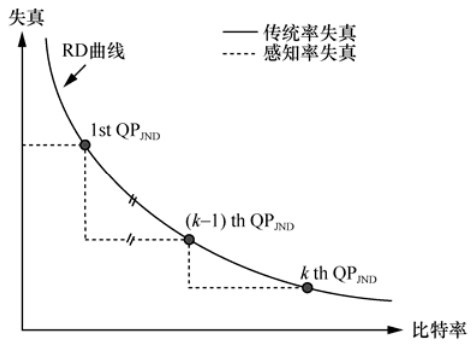
表1
压缩图像和视频数据库"
| 数据库 | 类型 | 原始样本数 | 分辨率/像素 | QF/QP/VBR | 编码器 | 压缩样本数 | 测试者数量 | 发布时间 |
| Lin2015[ | 图片 | 5 | 1 920×1 080 | QF:1~100 | JPEG | 5×100 | 20 | 2015年 |
| 视频 | 5 | 1 920×1 080 | QP:1~51/VBR | x264/x265 | 5×51×2×2 | 20 | 2015年 | |
| MCL-JCI[ | 图片 | 50 | 1 920×1 080 | QF:1~100 | JPEG | 50×100 | 20 | 2015年 |
| MCL-JCV[ | 视频 | 30 | 1 920×1 080 | QF:1~100 | x264 | 30×51 | 50 | 2016年 |
| Huang2017[ | 视频 | 40 | 1 920×1 080 | QP:1~51 | HM16.0-RA | 40×51 | 30 | 2017年 |
| VideoSet[ | 视频 | 220×4=880 | 1 920×1 080 | QP:1~51 | H.264/AVC | 880×51 | 30+ | 2017年 |
| 1 280×720 | ||||||||
| 960×540 | ||||||||
| 640×360 | ||||||||
| SIAT-JSSI[ | 立体对称图片 | 12 | 1 920×1 080 | QF:1~300 | JPEG2000 | 7020 | 50 | 2019年 |
| SIAT-JASI[ | 立体非对称图片 | 12 | 1 920×1 080 | QP:1~51 | HM16.7-AI | 7020 | 50 | 2019年 |
| JND-Pano[ | 全景图片 | 40 | 5 000×5 000 | QF:1~100 | JPEG | 4040 | 24 | 2018年 |
| Shen2020[ | 图片 | 202 | 1 920×1 080 | QP:13~51 | VTM5.0-AI | 39×202 | 20 | 2020年 |
| KonJND-1k[ | 图片 | 1 008 | 640×480 | QF:1~100 | JPEG/BPG | 77 112 | 42 | 2022年 |
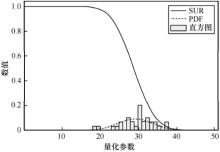
图2
主观测试中JND样本的直方图、PDF和SUR曲线示例"
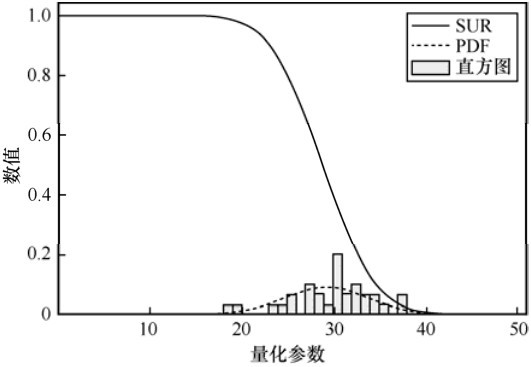
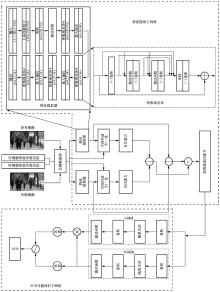
图3
SUR曲线预测模型的框架"
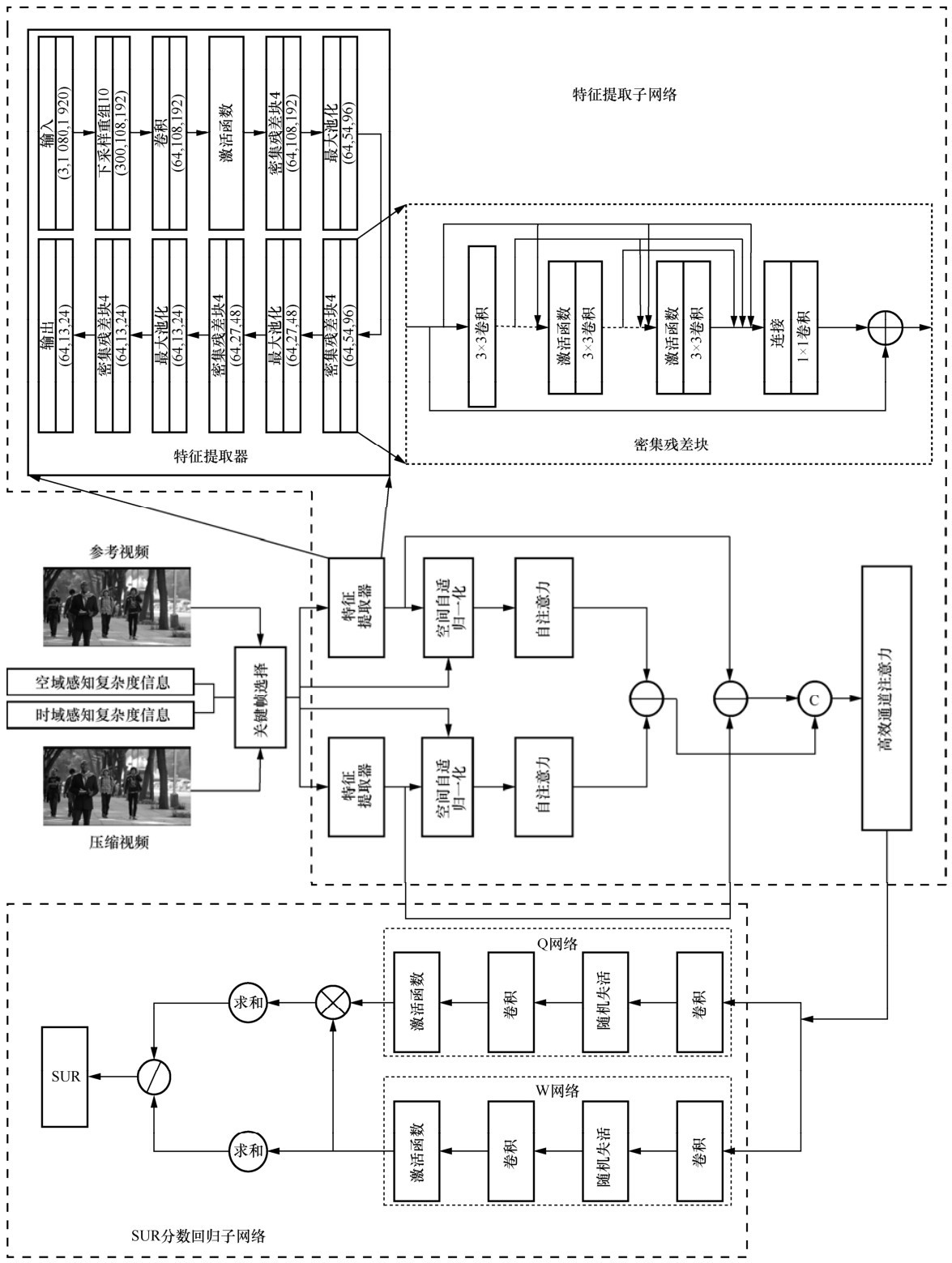
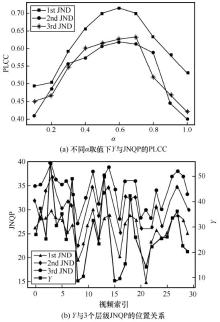
图4
Y值与JNQP的关系"
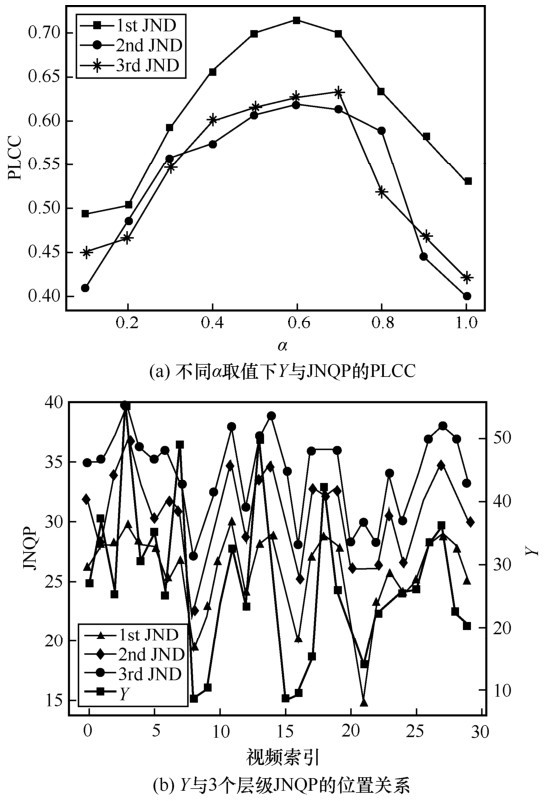

图5
Videoset数据集中3个典型视频序列以及对应的感知复杂度"

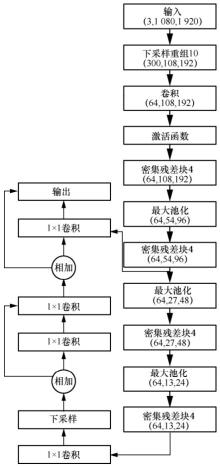
图6
多尺度密集残差网络"
表2
不同模块在VideoSet上的性能比较"
| 方法 | SUR | QP | |||
| 平均值 | 方差 | 平均值 | 方差 | ||
| WQFS [ | 0.076 | 0.009 6 | 3.01 | 3.45 | |
| KFS | 0.072 | 0.009 2 | 2.67 | 2.89 | |
| KFS+add_RDB | 0.069 | 0.008 2 | 2.55 | 2.25 | |
| KFS+add_RDB+SPADE | 0.052 | 0.006 6 | 2.41 | 1.93 | |
| KFS+MSDRN | 0.051 | 0.006 2 | 2.22 | 1.83 | |
表3
本文模型与其他模型在SUR和JND预测误差比较"
| 指标 | 方法 | |ΔSUR| | |ΔQP| | |△PSNR| | |△SSIM| | 时间/s |
| 平均值 | VW-SSUR[ | 0.066 | 1.90 | 0.91 | 1.63×10-3 | 15.51 |
| VW-STSUR-QF[ | 0.056 | 1.69 | 0.84 | 1.56×10--3 | 19.28 | |
| VW-STSUR-FF[ | 0.049 | 1.86 | 0.90 | 1.71×10-3 | 20.33 | |
| SUR-SPADE | 0.055 | 1.89 | 0.90 | 1.60×10-3 | 14.26 | |
| SUR-MSDRN | 0.053 | 1.86 | 0.89 | 1.61×10-3 | 14.04 | |
| 方差 | VW-SSUR[ | 0.006 4 | 1.94 | 0.46 | 1.90×10-6 | — |
| VW-STSUR-QF[ | 0.004 8 | 1.69 | 0.51 | 2.17×10-6 | — | |
| VW-STSUR-FF[ | 0.005 7 | 2.07 | 0.60 | 3.61×10-6 | — | |
| SUR-SPADE | 0.007 2 | 2.01 | 0.53 | 2.55×10-6 | — | |
| SUR-MSDRN | 0.005 6 | 1.66 | 0.51 | 2.11×10--6 | — |
表4
多分辨率下参考视频的SUR和QP预测误差比较"
| 方法 | 分辨率 | |||
| 1 080p | 720p | 540p | 360p | |
| VW-SSUR[ | 0.066/1.90 | — | 0.056/2.27 | — |
| SUR-SPADE | 0.055/1.89 | 0.058/2.21 | 0.052/2.41 | 0.061/2.30 |
| SUR-MSDRN | 0.053/1.86 | 0.057/2.32 | 0.051/2.22 | 0.059/2.48 |
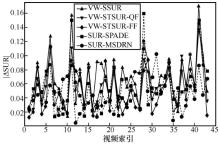
图7
VideoSet中每个1 080p测试视频的1st JND点SUR预测误差分布"
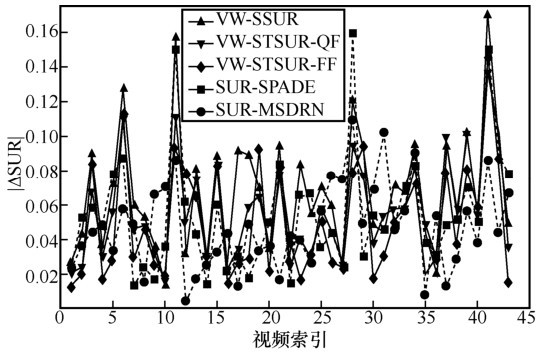
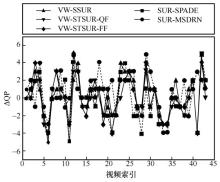
图8
VideoSet中每个1 080p测试视频的1st JND点QP预测误差分布"
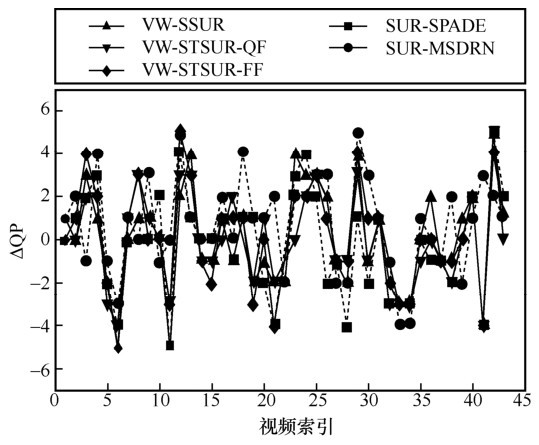
表5
本文模型在VideoSet中分辨率为1080p视频上的第二和第三层级的JND预测结果"
| 方法 | 指标 | 层级 | |ΔSUR| | |ΔQP| | |ΔPSNR| | |ΔSSIM| |
| SUR-SPADE | 平均值 | 2nd JND | 0.049 | 1.65 | 0.71 | 2.01×10-3 |
| 3rd JND | 0.052 | 1.67 | 0.75 | 2.25×10--3 | ||
| SUR-MSDRN | 2nd JND | 0.051 | 1.40 | 0.69 | 1.97×10--3 | |
| 3rd JND | 0.050 | 1.53 | 0.72 | 2.27×10-3 | ||
| SUR-SPADE | 方差 | 2nd JND | 0.004 1 | 1.32 | 0.56 | 6.36×10-6 |
| 3rd JND | 0.005 6 | 1.96 | 0.47 | 5.23×10--6 | ||
| SUR-MSDRN | 2nd JND | 0.003 9 | 1.54 | 0.49 | 4.61×10-6 | |
| 3rd JND | 0.004 6 | 1.80 | 0.51 | 6.78×10-6 |
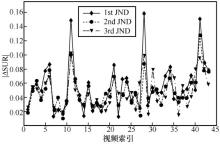
图9
SUR-SPADE预测的3个层级SUR绝对误差分布"
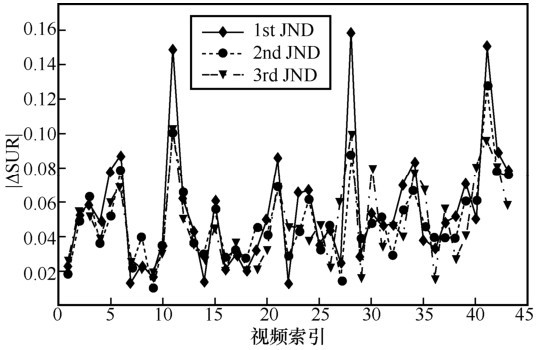
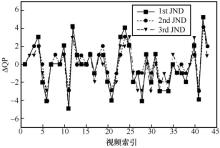
图10
SUR-SPADE预测的3个层级QP误差分布"
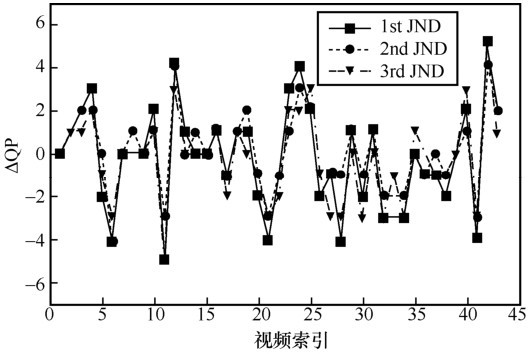
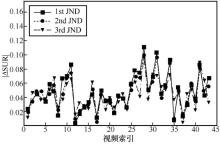
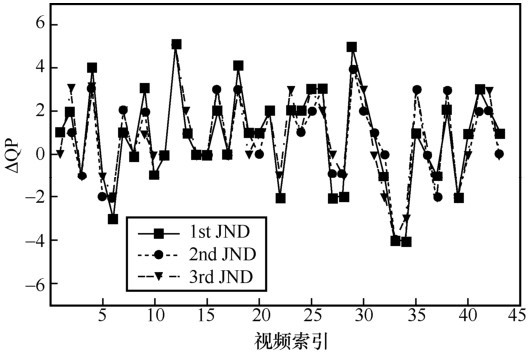
图11
SUR-MSDRN预测的3个层级SUR绝对误差分布"
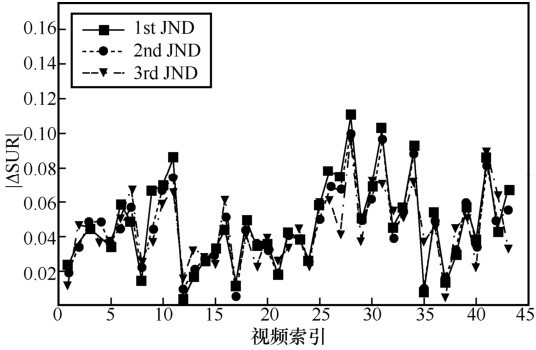
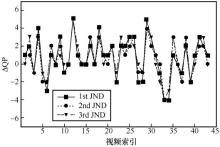
图12
SUR-MSDRN预测的3个层级QP误差分布"
| [1] | LIN W S , GHINEA G . Progress and opportunities in modelling just-noticeable difference (JND) for multimedia[J]. IEEE Transactions on Multimedia, 2021(24): 3706-3721. |
| [2] | WU J , LI L , DONG W ,et al. Enhanced just noticeable difference model for images with pattern complexity[J]. IEEE Transactions on Image Processing, 2017,26(6): 2682-2693. |
| [3] | WANG H , YU L , LIANG J ,et al. Hierarchical predictive coding-based JND estimation for image compression[J]. IEEE Transactions on Image Processing, 2020(30): 487-500. |
| [4] | BAE S H , KIM M . A novel generalized DCT-based JND profile based on an elaborate CM-JND model for variable block-sized transforms in monochrome images[J]. IEEE Transactions on Image Processing, 2014,23(8): 3227-3240. |
| [5] | 骆琼华, 王鸿奎, 殷海兵 ,等. 基于熵掩蔽的 DCT 域恰可察觉失真模型[J]. 电信科学, 2023,39(2): 59-70. |
| LUO Q H , WANG H K , YIN H B ,et al. Just noticeable distortion model based on entropy masking in DCT domain[J]. Telecommunications Science, 2023,39(2): 59-70. | |
| [6] | 邢亚芬, 殷海兵, 王鸿奎 ,等. 基于视频时域感知特性的恰可察觉失真模型[J]. 电信科学, 2022,38(2): 92-102. |
| XING Y F , YIN H B , WANG H K ,et al. Video temporal perception characteristics based just noticeable difference model[J]. Telecommunications Science, 2022,38(2): 92-102. | |
| [7] | JIN L N , LIN J Y , HU S D ,et al. Statistical study on perceived JPEG image quality via MCL-JCI dataset construction and analysis[J]. Electronic Imaging, 2016,28(13): 1-9. |
| [8] | WANG H Q , GAN W H , HU S D ,et al. MCL-JCV:a JND-based H.264/AVC video quality assessment dataset[C]// Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP). Piscataway:IEEE Press, 2016: 1509-1513. |
| [9] | WANG H Q , KATSAVOUNIDIS I , ZHOU J T ,et al. VideoSet:a large-scale compressed video quality dataset based on JND measurement[J]. Journal of Visual Communication and Image Representation, 2017(46): 292-302. |
| [10] | HUANG Q , WANG H Q , LIM S C ,et al. Measure and prediction of HEVC perceptually lossy/lossless boundary QP values[C]// Proceedings of the 2017 Data Compression Conference (DCC). Piscataway:IEEE Press, 2017: 42-51. |
| [11] | ZHANG X , YANG C , WANG H ,et al. Satisfied-user-ratio modeling for compressed video[J]. IEEE Transactions on Image Processing, 2020(29): 3777-3789. |
| [12] | ZHANG Y , LIU H H , YANG Y ,et al. Deep learning based just noticeable difference and perceptual quality prediction models for compressed video[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022,32(3): 1197-1212. |
| [13] | LIN J Y , JIN L N , HU S D ,et al. Experimental design and analysis of JND test on coded image/video[C]// SPIE Optical Engineering + Applications.Applications of Digital Image Processing XXXVIII.[S.l.:s.n.], 2015: 324-334. |
| [14] | FAN C L , ZHANG Y , HAMZAOUI R ,et al. Learning-based satisfied user ratio prediction for symmetrically and asymmetrically compressed stereoscopic images[J]. IEEE MultiMedia, 2021,28(3): 8-20. |
| [15] | LIU X H , CHEN Z H , WANG X ,et al. JND-pano:database for just noticeable difference of JPEG compressed panoramic images[C]// Pacific Rim Conference on Multimedia. Berlin:Springer, 2018: 458-468. |
| [16] | SHEN X L , NI Z K , YANG W H ,et al. A JND dataset based on VVC compressed images[C]// Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). Piscataway:IEEE Press, 2020: 1-6. |
| [17] | LIN H H , CHEN G G , JENADELEH M ,et al. Large-scale crowdsourced subjective assessment of picturewise just noticeable difference[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022,32(9): 5859-5873. |
| [18] | TIAN T , WANG H L , ZUO L X ,et al. Just noticeable difference level prediction for perceptual image compression[J]. IEEE Transactions on Broadcasting, 2020,66(3): 690-700. |
| [19] | LIU H H , ZHANG Y , ZHANG H ,et al. Deep learning based picture-wise just noticeable distortion prediction model for image compression[J]. IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society, 2019(29): 641-656. |
| [20] | ITU-T P. 910.Subjective video quality assessment methods for multimedia applications[S]. Geneva:ITU-T Publications, 2022. |
| [21] | ZHANG Y , TIAN Y , KONG Y ,et al. Residual dense network for image super-resolution[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 2472-2481. |
| [22] | PARK T , LIU M Y , WANG T C ,et al. Semantic image synthesis with spatially-adaptive normalization[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2019: 2337-2346. |
| [23] | BAO L , YANG Z , WANG S ,et al. Real image denoising based on multi-scale residual dense block and cascaded U-Net with block-connection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway:IEEE Press, 2020: 448-449. |
| [24] | WANG Q , WU B , ZHU P ,et al. ECA-Net:Efficient channel attention for deep convolutional neural networks[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Piscataway:IEEE Press, 2020: 11534-11542. |
| [1] | 马智勇. 家庭Wi-Fi网络质量远程评价方法及实现[J]. 电信科学, 2023, 39(Z1): 182-188. |
| [2] | 张剑, 程俊华, 龚菡洁, 李红, 牛凯. 基于云边协同的高可用厨房卫生监控系统[J]. 电信科学, 2023, 39(Z1): 62-70. |
| [3] | 祝谷乔, 姜超, 徐煜烨. 超分辨率重建技术及其在智能终端上的应用[J]. 电信科学, 2023, 39(7): 156-165. |
| [4] | 叶振, 王国相, 宋俊锋, 刘昊坤, 黎天送. 一种基于深度可分离卷积的VVC帧内编码快速块划分算法[J]. 电信科学, 2023, 39(7): 99-108. |
| [5] | 卢敏, 胡娟, 张先超, 丁伟健, 乐光学. 基于用户多特征融合的个性化推荐模型[J]. 电信科学, 2023, 39(5): 101-115. |
| [6] | 骆琼华, 王鸿奎, 殷海兵, 邢亚芬. 基于熵掩蔽的DCT域恰可察觉失真模型[J]. 电信科学, 2023, 39(2): 59-70. |
| [7] | 杨蓓, 梁鑫, 尹航, 蒋峥, 佘小明. 基于自注意力机制的大规模MIMO信道状态信息特征向量反馈方法[J]. 电信科学, 2023, 39(11): 128-136. |
| [8] | 胡炜晨, 许聪源, 詹勇, 陈广辉, 刘思情, 王志强, 王晓琳. 一种适用于小样本条件的网络入侵检测方法[J]. 电信科学, 2023, 39(10): 85-100. |
| [9] | 马稼明, 潘路平, 张琰琳. 基于Transformer的互联网暗链检测方法[J]. 电信科学, 2022, 38(Z2): 241-247. |
| [10] | 诸葛斌, 尹正虎, 斯文学, 颜蕾, 董黎刚, 蒋献. 基于学生知识追踪的多指标习题推荐算法[J]. 电信科学, 2022, 38(9): 129-143. |
| [11] | 周杰, Esono Mikue Bernardo Esono, 王学英, 周惠婷, 罗宏. 基于SLM-PTS算法融合的NC-OFDM峰均比优化[J]. 电信科学, 2022, 38(7): 63-74. |
| [12] | 邢亚芬, 殷海兵, 王鸿奎, 骆琼华. 基于视频时域感知特性的恰可察觉失真模型[J]. 电信科学, 2022, 38(2): 92-102. |
| [13] | 申情, 郭文宾, 楼俊钢, 余强国. 考虑多层次潜在特征的个性化推荐模型[J]. 电信科学, 2022, 38(2): 71-83. |
| [14] | 李攀攀, 谢正霞, 乐光学, 刘鑫. 基于深度学习的无线通信接收方法研究进展与趋势[J]. 电信科学, 2022, 38(2): 1-17. |
| [15] | 陈志宏, 王明晓. 计算机视觉在智慧安防中的应用[J]. 电信科学, 2021, 37(8): 142-147. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||