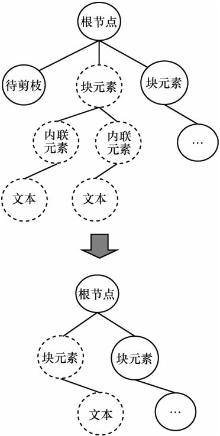
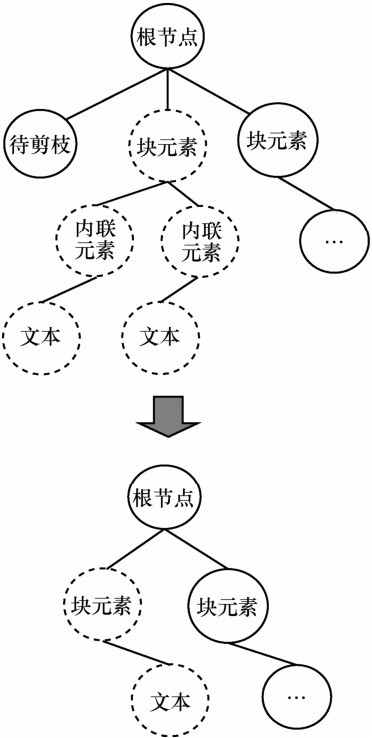
| [1] |
GRISHMAN R Information extraction:techniques and challenges [EB/OL]. .
|
| [2] |
李蕾, 周延泉, 王菁华 . 基于全信息的中文信息抽取系统及应用[J]. 北京邮电大学学报, 2005,28(6): 48-51. LI L , ZHOU Y Q , WANG J H . Comprehensive information based chinese information extraction system and application[J]. Journal of Beijing University of Posts and Telecommunications, 2005,28(6): 48-51.
|
| [3] |
黄诗琳, 郑小琳, 陈德人 . 针对产品命名实体识别的半监督学习方法[J]. 北京邮电大学学报, 2013,36(2): 20-23. HUANG S L , ZHENG X L , CHEN D R . A semi-supervised learning method for product named entity recognition[J]. Journal of Beijing University of Posts and Telecommunications, 2013,36(2): 20-23.
|
| [4] |
秦兵, 刘安安, 刘挺 . 无指导的中文开放式实体关系抽取[J]. 计算机研究与发展, 2015,52(5): 1029-1035. QIN B , LIU A A , LIU T . Unsupervised Chinese open entity relation extraction[J]. Journal of Computer Research and Development, 2015,52(5): 1029-1035.
|
| [5] |
李天颍, 刘璘, 赵德旺 ,等. 一种基于依存文法的需求文本策略依赖关系抽取方法[J]. 计算机学报, 2013,31(1): 54-62. LI T Y , LIU L , ZHAO D W ,et al. Eliciting relations from requirements text based on dependency analysis[J]. Journal of Computers, 2013,31(1): 54-62.
|
| [6] |
DENG C , YU S P , WEN J R . VIPS:a vision-based page segmentation[R]// Microsoft Technical Report,MSR-TR_ 203-79, 2003.
|
| [7] |
NEIL A , HONG J . Visually extracting data records from the deepWeb[C]// WWW 2013. Rio,IEEE Press, 2013: 1233-1238.
|
| [8] |
NARWAL N , . Improving Web data extraction by noise removal[C]// ARTCom 2013. Bangalore,IET, 2013: 388-395.
|
| [9] |
SUN F , SONG D , LIAO L . DOM based content extraction via text density[C]// ACM SIGIR 2011. Beijing, 2011: 245-254.
|
| [10] |
张乃洲, 曹薇, 李石君 . 一种基于节点密度分割和标签传播的Web页面挖掘方法[J]. 计算机学报, 2015,38(2): 349-364. ZHANG N Z , CAO W , LI S J . A method based on node density segmentation and label propagation for mining Web page[J]. Journal of Computers, 2015,38(2): 349-364.
|
| [11] |
WANG J B , WANG L Z , GAO W L ,et al. Chinese Web content extraction based on naive bayes model[C]// International Federation for Information Processing IFIP. 2014: 404-413.
|
| [12] |
KRISHNA S S , DATTATRAYA J S . Schema inference and data extraction from templatized Web pages[C]// ICPC, 2015: 1-6.
|
| [13] |
BHUIYAN M A , ALHASAN M . FSM-H:frequent subgraph mining algorithm in Hadoop[C]// Big Data. 2014: 9-16.
|
| [14] |
JIN S Y , BOULWARE D , KIMMEY D . A parallel spatial co-location mining algorithm based on MapReduce[C]// Big Data. 2014: 25-31.
|