

Journal on Communications ›› 2022, Vol. 43 ›› Issue (3): 148-163.doi: 10.11959/j.issn.1000-436x.2022054
• Papers • Previous Articles Next Articles
Yimin MAO1, Dejin GAN1, Liefa LIAO1, Zhigang CHEN2
Revised:2021-12-10
Online:2022-03-25
Published:2022-03-01
Supported by:CLC Number:
Yimin MAO, Dejin GAN, Liefa LIAO, Zhigang CHEN. Parallel division clustering algorithm based on Spark framework and ASPSO[J]. Journal on Communications, 2022, 43(3): 148-163.
"
| 节点类型 | 主机名 | IP地址 |
| master | master | 192.168.111.1 |
| worker | slave_1 | 192.168.111.2 |
| worker | slave_2 | 192.168.111.3 |
| worker | slave_3 | 192.168.111.4 |
"
| 数据集 | 样本数/个 | 特征属性 | 文件大小/MB | 数据特点 |
| Online Retail | 1 067 371 | 8 | 580 | 样本多,属性少 |
| N_BaloT | 7 062 606 | 115 | 960.5 | 样本多,属性相对适中 |
| Health News | 580 000 | 25 000 | 830.2 | 样本少,属性多 |
| Bag words | 8 000 000 | 1 000 000 | 2 687.9 | 样本多,属性多 |
"
| 类型 | 函数名称 | 函数表达式 | 取值范围 | 最优值 |
| 单峰 | Sphere | [-10,10] | 0 | |
| Schwefel | [-100,100] | 0 | ||
| 高维多峰 | Ackely | [-32,32] | 0 | |
| Griewank | [-600,600] | 0 |
"
| 函数 | 算法 | 中间值 | 平均值 | 标准差 |
| f1 | PSO | 6.487×10-14 | 2.189×10-13 | 1.584×10-14 |
| MSPSO | 8.432×10-16 | 1.345×10-13 | 5.365×10-18 | |
| ASPSO | 3.458×10-16 | 5.975×10-15 | 2.858×10-26 | |
| f2 | PSO | 8.469×10-17 | 7.486×10-22 | 5.753×10-8 |
| MSPSO | 2.368×10-17 | 9.325×10-20 | 6.225×10-12 | |
| ASPSO | 4.457×10-18 | 6.733×10-24 | 2.946×10-22 | |
| f3 | PSO | 6.445×10-12 | 8.554×10-8 | 6.332 |
| MSPSO | 5.398×10-13 | 4.443×10-11 | 9.352×10-4 | |
| ASPSO | 2.331×10-14 | 9.328×10-12 | 2.977×10-10 | |
| f4 | PSO | 4.474×10-16 | 5.254×10-12 | 3.289 |
| MSPSO | 9.998×10-18 | 8.887×10-16 | 5.877×10-0 | |
| ASPSO | 3.649×10-22 | 3.977×10-18 | 4.618×10-8 |

"
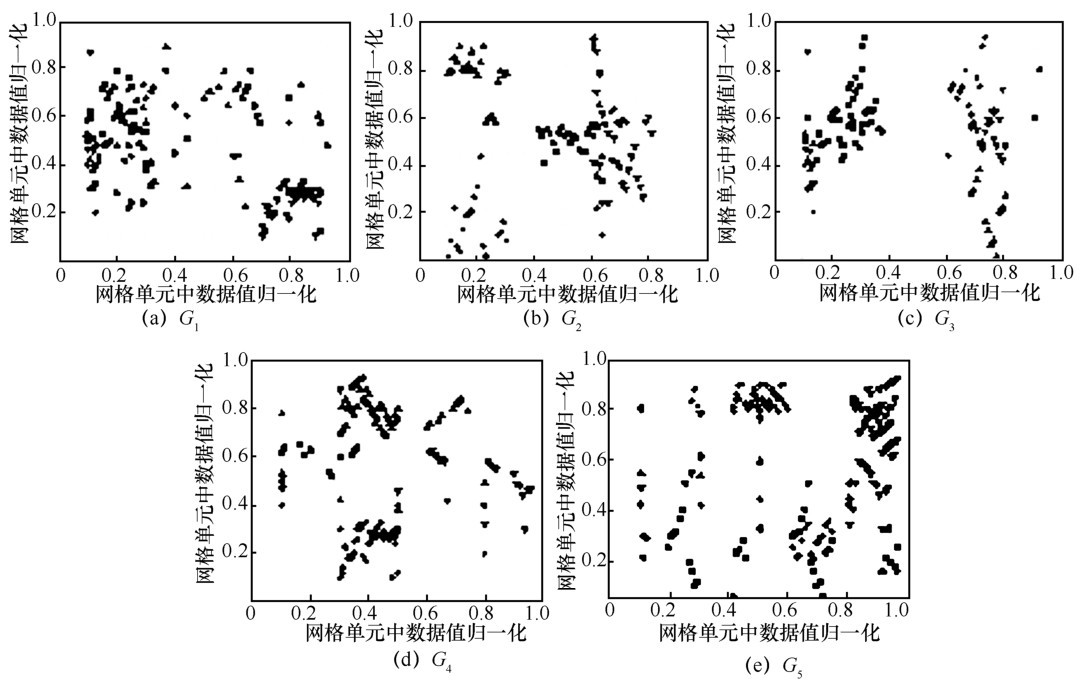
"


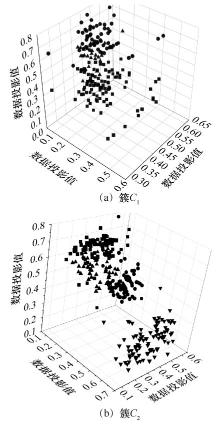
"
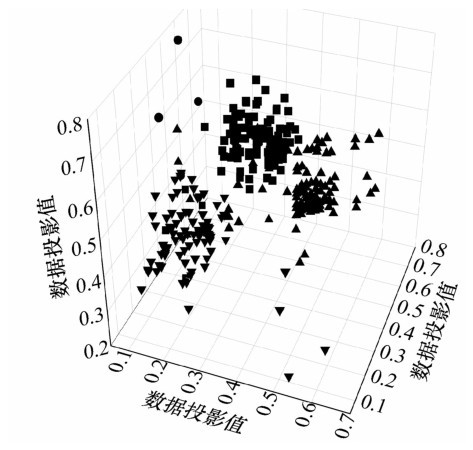

"
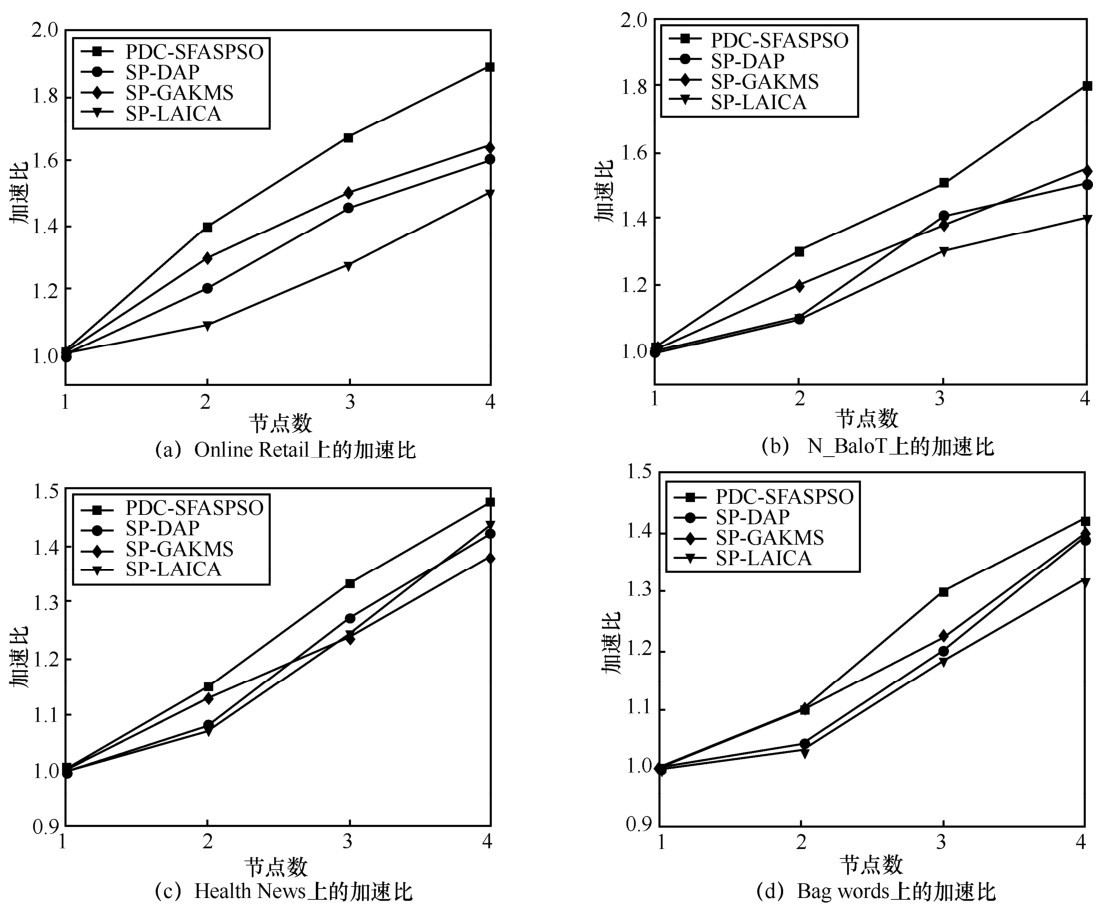
"
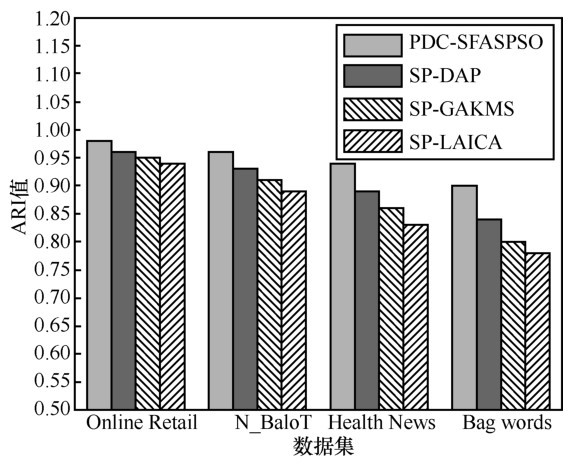
| 算法 | Online Retail | N_BaloT | Health News | Bag words |
| PDC-SFASPSO | 0.895(± 0.027) | 0.886(± 0.0372) | 0.836(± 0.0563) | 0.721(± 0.0775) |
| SP-DAP | 0.766(± 0.0372) | 0.721(± 0.0197) | 0.691(± 0.0754) | 0.591(± 0.0674) |
| SP-GAKMS | 0.751(± 0.0196) | 0.711(± 0.0542) | 0.621(± 0.0621) | 0.521(± 0.0788) |
| SP-LAICA | 0.769(± 0.0126) | 0.703(± 0.0278) | 0.646(± 0.0487) | 0.546(± 0.0597) |

"

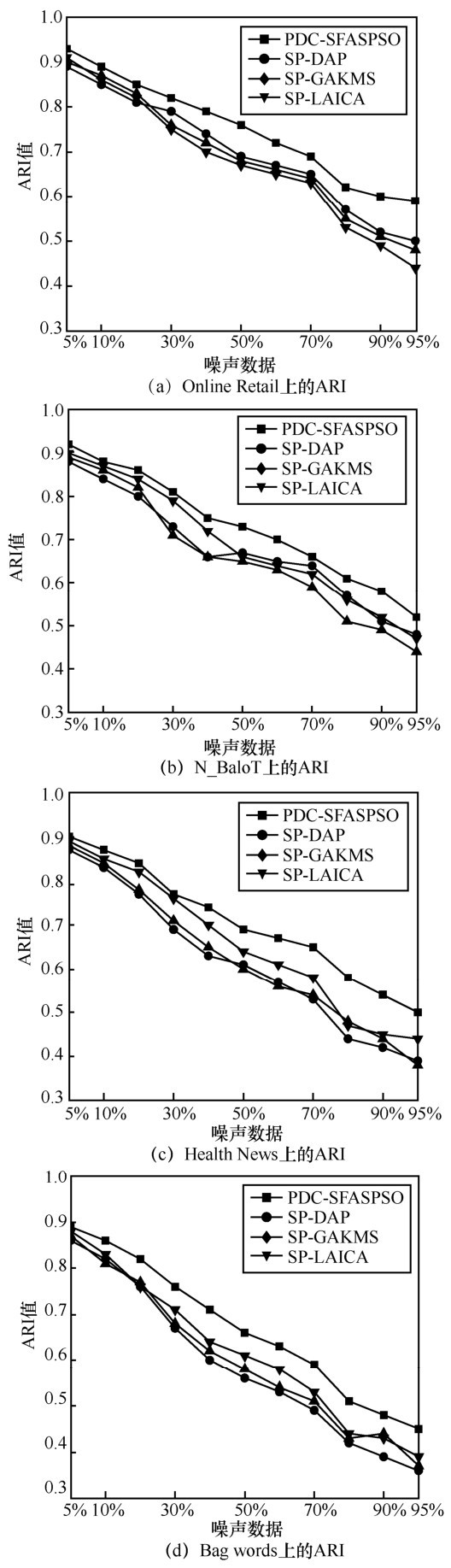
"
"
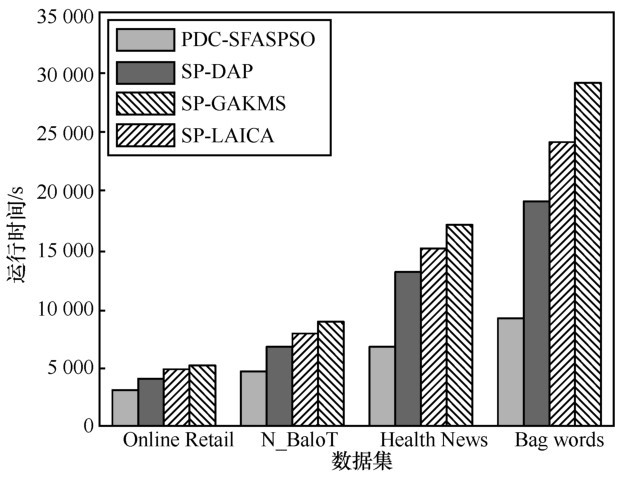
| [1] | WANG P K , CHEN C H , PUN S H ,et al. Parallel architecture to accelerate super paramagnetic clustering algorithm[J]. Electronics Letters, 2020,56(14): 701-704. |
| [2] | KHAN A , ZUBAIR S . Expansion of regularized kmeans discretization machine learning approach in prognosis of dementia progression[C]// Proceedings of 2020 11th International Conference on Computing,Communication and Networking Technologies. Piscataway:IEEE Press, 2020: 1-6. |
| [3] | MARTANTO , ANWAR S , ROHMAT C L ,et al. Clustering of Internet network usage using the K-medoid method[J]. IOP Conference Series:Materials Science and Engineering, 2021,1088(1): 012036. |
| [4] | SCHUBERT E , ROUSSEEUW P J . Fast and eager k-medoids clustering:O(k) runtime improvement of the PAM,CLARA,and CLARANS algorithms[J]. Information Systems, 2021,101: 101804. |
| [5] | LEKHWAR S , YADAV S , SINGH A . Big data analytics in retail[R]. 2019. |
| [6] | WEISSMAN B , VAN D L E . Working with spark in big data clusters[R]. 2020. |
| [7] | MUGDHA S , CHIRAG P , AKASH A . Design and implementation of university network[J]. International Journal of Recent Technology and Engineering, 2019,8(26): 1199-1214. |
| [8] | 王海艳, 肖亦康 . 基于密度峰值聚类的动态群组发现方法[J]. 计算机研究与发展, 2018,55(2): 391-399. |
| WANG H Y , XIAO Y K . Dynamic group discovery based on density peaks clustering[J]. Journal of Computer Research and Development, 2018,55(2): 391-399. | |
| [9] | WANG B W , YIN J , HUA Q ,et al. Parallelizing K-means-based clustering on spark[C]// Proceedings of 2016 International Conference on Advanced Cloud and Big Data. Piscataway:IEEE Press, 2016: 31-36. |
| [10] | 徐鹏程, 王诚 . K-means算法改进及基于Spark计算模型的实现[J]. 南京邮电大学学报(自然科学版), 2017,37(4): 113-118. |
| XU P C , WANG C . Improvement of K-means algorithm and implementation based on Spark computing model[J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2017,37(4): 113-118. | |
| [11] | MULTAZAM M T , DIJAYA R , DEVI N S . Index group optimization based on automatic clustering using K-means genetic algorithm[J]. Journal of Physics:Conference Series, 2019,1402(6): 066028. |
| [12] | 许明杰, 蔚承建, 沈航 . 基于 Spark 的并行 K-means 算法研究[J]. 微电子学与计算机, 2018,35(5): 95-99. |
| XU M J , WEI C J , SHEN H . Research on K-means algorithm of Spark parallelization[J]. Microelectronics & Computer, 2018,35(5): 95-99. | |
| [13] | GAO H J , LI Y T , KABALYANTS P ,et al. A novel hybrid PSO-K-means clustering algorithm using Gaussian estimation of distribution method and Lévy flight[J]. IEEE Access, 2020,8: 122848-122863. |
| [14] | AGRAWAL S , PATEL A . SAG cluster:an unsupervised graph clustering based on collaborative similarity for community detection in complex networks[J]. Physica A:Statistical Mechanics and Its Applications, 2021,563: 125459. |
| [15] | LAI M J , MCKENZIE D . Compressive sensing for cut improvement and local clustering[J]. SIAM Journal on Mathematics of Data Science, 2020,2(2): 368-395. |
| [16] | 裴继红, 谢维信 . 势函数聚类自适应多阈值图像分割[J]. 计算机学报, 1999,22(7): 758-762. |
| PEI J H , XIE W X . Adaptive multi thresholds image segmentation based on potential function clustering[J]. Chinese Journal of Computers, 1999,22(7): 758-762. | |
| [17] | ZHANG Y L , HAN J . Differential privacy fuzzy C-means clustering algorithm based on Gaussian kernel function[J]. PLoS One, 2021,16(3): e0248737. |
| [18] | 赵姝, 许显胜, 华波 ,等. 收缩邻居节点集方法求解有向网络的最大流问题[J]. 模式识别与人工智能, 2013,26(5): 425-431. |
| ZHAO S , XU X S , HUA B ,et al. Contracting neighbor-node-set approach for solving maximum flow problem in directed network[J]. Pattern Recognition and Artificial Intelligence, 2013,26(5): 425-431. | |
| [19] | PAULCHAMY B , CHIDAMBARAM S , JAYA J . An energy efficient neighbor node based clustering (EENNC) algorithm for wireless sensor networks[J]. Journal of Xidian University, 2020,14(6): 2483-2493. |
| [20] | SUN C , YUE S H , LI Q . Clustering characteristics of UCI dataset[C]// Proceedings of 2020 39th Chinese Control Conference (CCC). Piscataway:IEEE Press, 2020,13(5): 428-439. |
| [21] | DASH D R , DASH P K , BISOI R . Short term solar power forecasting using hybrid minimum variance expanded RVFLN and sine-cosine Levy flight PSO algorithm[J]. Renewable Energy, 2021,174: 513-537. |
| [1] | Zhongping ZHANG, Sen LI, Weixiong LIU, Shuxia LIU. Outlier detection algorithm based on fast density peak clustering outlier factor [J]. Journal on Communications, 2022, 43(10): 186-195. |
| [2] | Huafeng HUANG, Purui SU, Yi YANG, Xiangkun JIA. Automatic exploitation generation method of write-what-where vulnerability [J]. Journal on Communications, 2022, 43(1): 83-95. |
| [3] | Yan YAN, Yiming CONG, Mahmood Adnan, Quanzheng SHENG. Statistics release and privacy protection method of location big data based on deep learning [J]. Journal on Communications, 2022, 43(1): 203-216. |
| [4] | Zhongping ZHANG, Weixiong LIU, Yuting ZHANG, Yu DENG, Mianxin WEI. ERDOF: outlier detection algorithm based on entropy weight distance and relative density outlier factor [J]. Journal on Communications, 2021, 42(9): 133-143. |
| [5] | Yuhong LIU, Liang YANG, Chunhui PIAO, Zhiguo ZHANG. Research on key technologies of safety monitoring data sharing for railway engineering construction based on blockchain [J]. Journal on Communications, 2021, 42(8): 206-216. |
| [6] | Ru HUO, Dong NI, Hua LU, Yunfeng XIA, Shuo WANG, Tao HUANG, Yunjie LIU. Efficient routing strategy of blockchain-based payment channel network [J]. Journal on Communications, 2021, 42(6): 30-40. |
| [7] | Yimin MAO, Qianhu DENG, Zhigang CHEN. Parallel association rules incremental mining algorithm based on information entropy and genetic algorithm [J]. Journal on Communications, 2021, 42(5): 122-136. |
| [8] | Haining MENG, Xinyu TONG, Yuekai SHI, Lei ZHU, Kai FENG, Xinhong HEI. Cloud server aging prediction method based on hybrid model of auto-regressive integrated moving average and recurrent neural network [J]. Journal on Communications, 2021, 42(1): 163-171. |
| [9] | Ziyang LI,Jiong YU,Yuefei WANG,Chen BIAN,Yonglin PU,Yitian ZHANG,Yu LIU. Load prediction based elastic resource scheduling strategy in Flink [J]. Journal on Communications, 2020, 41(10): 92-108. |
| [10] | Hongqiang YAN,Linjie WANG. Research of authentication techniques for the Internet of things [J]. Journal on Communications, 2020, 41(7): 213-222. |
| [11] | Yonglin PU,Jiong YU,Liang LU,Ziyang LI,Chen BIAN,Bin LIAO. Energy-efficient strategy for data migration and merging in Storm [J]. Journal on Communications, 2019, 40(12): 68-85. |
| [12] | Yunchuan GUO,Ling LI,Yongjun LI,Lin CHENG,Jun DU,Lingcui ZHANG. Policy translation and configuration using dynamic template [J]. Journal on Communications, 2019, 40(12): 138-148. |
| [13] | Chunfu JIA,Shengbo YAN,Zhi WANG,Chenlu WU,Hang LI. Method to improve edge coverage in fuzzing [J]. Journal on Communications, 2019, 40(11): 76-85. |
| [14] | Ziyang LI,Jiong YU,Chen BIAN,Yitian ZHANG,Yonglin PU,Yuefei WANG,Liang LU. Flow-network based auto rescale strategy for Flink [J]. Journal on Communications, 2019, 40(8): 85-101. |
| [15] | Fenghua LI,Dingyan LI,Wei JIN,Zhu WANG,Yunchuan GUO,Kui GENG. Hierarchical scalable storage architecture for massive electronic bill [J]. Journal on Communications, 2019, 40(5): 79-87. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||