

Journal on Communications ›› 2022, Vol. 43 ›› Issue (11): 65-79.doi: 10.11959/j.issn.1000-436x.2022222
• Papers • Previous Articles Next Articles
Meiyu ZHONG1, Peiliang WU1,2, Yan DOU1,3, Yi LIU1, Lingfu KONG1,2
Revised:2022-10-24
Online:2022-11-25
Published:2022-11-01
Supported by:CLC Number:
Meiyu ZHONG, Peiliang WU, Yan DOU, Yi LIU, Lingfu KONG. Chinese semantic and phonological information-based text proofreading model for speech recognition[J]. Journal on Communications, 2022, 43(11): 65-79.
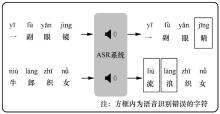
"
"
| 模型简称 | 音韵信息 | 基于深度学习的模型 | 检错F1值 | 纠错F1值 |
| NTOU[ | × | × | 42.01% | 36.64% |
| NCTU-NTUT[ | × | × | 45.79% | 37.55% |
| Fusion Lattice LSTM-CRF[ | √ | √ | 49.10% | — |
| Confusionset[ | × | √ | 69.80% | 64.90% |
| FASPell[ | × | √ | 63.50% | 62.60% |
| Soft-Masked BERT[ | × | √ | 73.50% | 66.40% |
| SpellGCN[ | √ | √ | 77.70% | 75.90% |
| SpellBERT[ | √ | √ | 80.00% | 78.50% |
| MLM-phonetics[ | √ | √ | 80.20% | 77.50% |
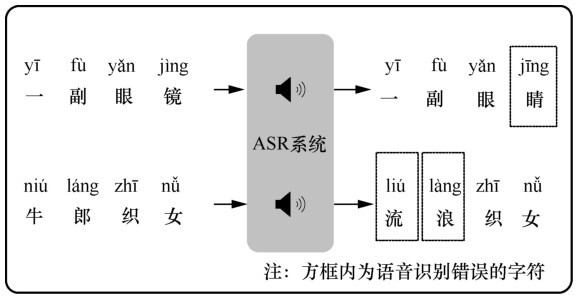
"

"
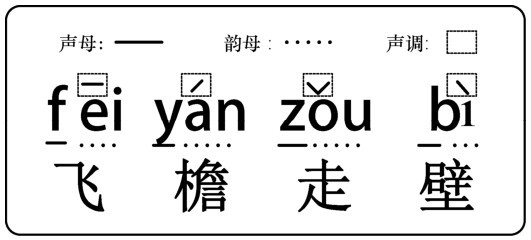
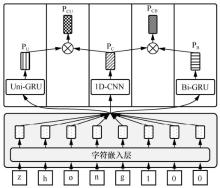
"
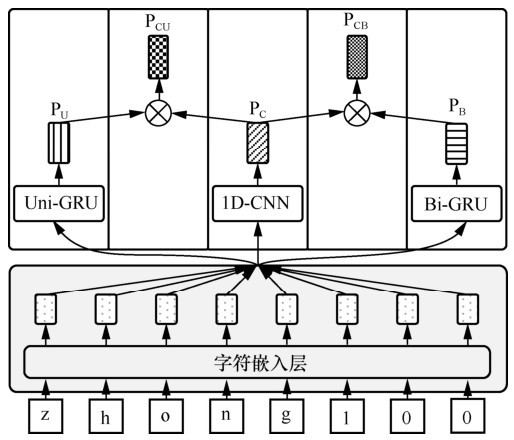
"
| 示例 | 语音识别错误语句 | 错误字符的拼音 | 相应的正确语句 | 相应正确字符的拼音 |
| 1 | 但是不行最终还是发生了 | xing2 | 但是不幸最终还是发生了 | xing4 |
| 2 | 没让亚运会进行的城市资金投入 | mei2/ rang4 | 围绕亚运会进行的城市资金投入 | wei2/rao4 |
| 3 | 与岳风学生赔偿问题 | yue4/feng1/xue2/sheng1 | 与院方协商赔偿问题 | yuan4/fang1/xie2/shang1 |
"
| Data/条 | Total/个 | True/个 | False/个 | Len/个 | Error/个 | 语句占比 | |
| Len<5 | Len<10 | ||||||
| Train | 24 813 | 300 | 24 513 | 2~39 | 1~15 | 6.11% | 43.65% |
| Test | 9 888 | 104 | 9 784 | 1~39 | 1~16 | 12.91% | 49.61% |
"
| 参数 | 值 |
| 迭代轮次 | 150 |
| 批量大小 | 32 |
| 优化器 | Adam |
| 学习率 | 0.001 |
| 丢弃率 | 0.2 |
| 卷积核大小 | 2 |
| 编码器和解码器的层数 | 1 |
| 嵌入向量的维度 | 256 |
| 编码器隐藏向量的维度 | 128 |
| 解码器隐藏向量的维度 | 128 |

"
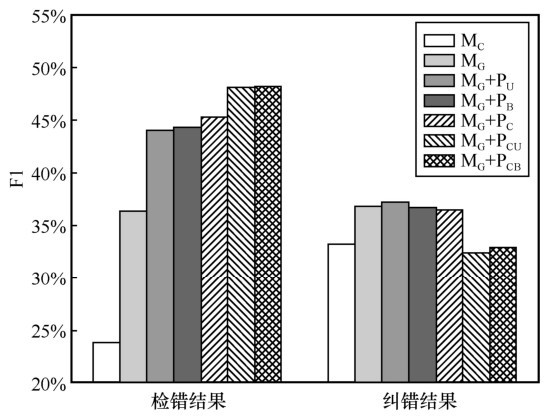
"
| 模型 | 检错结果 | 纠错结果 | |||||
| P | R | F1 | P | R | F1 | ||
| MC | 59.53% | 14.93% | 23.85% | 48.45% | 25.29% | 33.23% | |
| MG | 56.76% | 26.63% | 36.25% | 29.01% | 36.78% | ||
| MG+PU | 33.71% | 44.03% | 48.58% | ||||
| MG+PB | 63.18% | 34.19% | 44.34% | 47.78% | 29.77% | 36.68% | |
| MG+PC | 61.63% | 35.72% | 45.22% | 47.49% | 29.67% | 36.52% | |
| MG+PCU | 48.29% | 48.03% | 40.07% | 27.11% | 32.33% | ||
| MG+PCB | 49.69% | 46.92% | 41.00% | 27.47% | 32.90% |
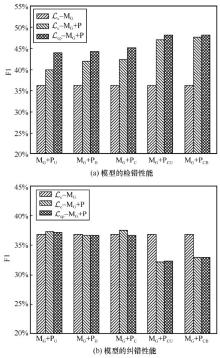
"
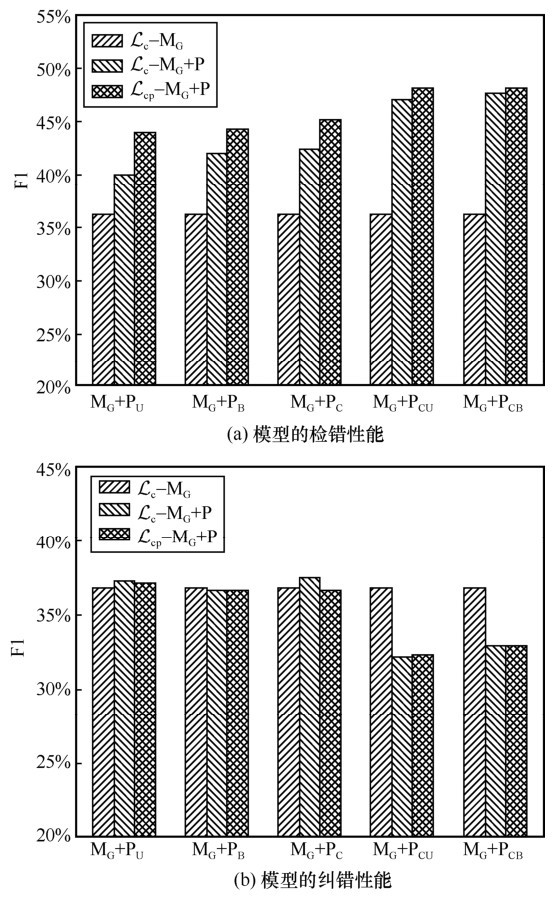
"
| 模型 | 检错结果 | 纠错结果 | |||||||||||||||
| P | R | F1 | P | R | F1 | ||||||||||||
| MG | 56.76% | — | 26.63% | — | 36.25% | — | — | 29.01% | — | 36.78% | — | ||||||
| MG+PU | 29.07% | 33.71% | 39.90% | 44.03% | 49.93% | 29.69% | 37.24% | ||||||||||
| MG+PB | 62.76% | 63.18% | 31.58% | 34.19% | 42.00% | 44.34% | 48.62% | 47.78% | 29.44% | 29.77% | 36.67% | 36.68% | |||||
| MG+PC | 62.20% | 61.63% | 32.17% | 35.72% | 42.39% | 45.22% | 49.43% | 47.49% | 29.67% | 36.52% | |||||||
| MG+PCU | 46.75% | 48.29% | 48.12% | 47.06% | 48.03% | 39.77% | 40.07% | 26.97% | 27.11% | 32.14% | 32.33% | ||||||
| MG+PCB | 46.31% | 49.69% | 46.92% | 40.49% | 41.00% | 27.73% | 27.47% | 32.91% | 32.90% | ||||||||
"
| 数据大小 | 检错结果 | 纠错结果 | |||||||||||||||
| P | R | F1 | P | R | F1 | ||||||||||||
| MG+PC | MG+PCB | MG+PC | MG+PCB | MG+PC | MG+PCB | MG+PC | MG+PCB | MG+PC | MG+PCB | MG+PC | MG+PCB | ||||||
| Origin | 49.69% | 35.72% | 46.92% | 45.22% | 48.16% | ||||||||||||
| 10w | 59.41% | 49.39% | 37.55% | 49.27% | 46.02% | 49.33% | 41.21% | 33.61% | 26.20% | 23.28% | 32.03% | 27.51% | |||||
| 15w | 56.71% | 52.19% | 42.57% | 49.94% | 48.63% | 51.04% | 37.22% | 35.48% | 24.43% | 24.73% | 29.50% | 29.15% | |||||
| 20w | 56.80% | 37.96% | 34.56% | 25.19% | 24.07% | 30.28% | 28.38% | ||||||||||
| [1] | ERRATTAHI R , HANNANI A E , OUAHMANE H . Automatic speech recognition errors detection and correction:a review[J]. Procedia Computer Science, 2018,128: 32-37. |
| [2] | ZHANG S L , LEI M , YAN Z J . Investigation of transformer based spelling correction model for CTC-based end-to-end mandarin speech recognition[C]// Proceedings of the International Speech Communication Association (INTERSPEECH). Grenoble:International Speech Communication Association, 2019: 2180-2184. |
| [3] | ZHAO Y , YANG X R , WANG J C ,et al. BART based semantic correction for Mandarin automatic speech recognition system[C]// Proceedings of the International Speech Communication Association (INTERSPEECH). Grenoble:International Speech Communication Association, 2021: 2017-2021. |
| [4] | WANG X Q , LIU Y Q , ZHAO S ,et al. A light-weight contextual spelling correction model for customizing transducer-based speech recognition systems[C]// Proceedings of the International Speech Communication Association (INTERSPEECH). Grenoble:International Speech Communication Association, 2021: 1982-1986. |
| [5] | ZHANG S L , LEI M , LIU Y ,et al. Investigation of modeling units for mandarin speech recognition using dfsmn-ctc-smbr[C]// Proceedings of 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 7085-7089. |
| [6] | YANG L , LI Y , WANG J ,et al. Post text processing of Chinese speech recognition based on bidirectional LSTM networks and CRF[J]. Electronics, 2019,8(11): 1248. |
| [7] | CHEN Y C , CHENG C Y , CHEN C A ,et al. Integrated semantic and phonetic post-correction for Chinese speech recognition[C]// Proceedings of Conference on Computational Linguistics and Speech Processing (ROCLING). Stroudsburg:Association for Computational Linguistics, 2021: 95-102. |
| [8] | LI M , DANILEVSKY M , NOEMAN S ,et al. DIMSIM:an accurate Chinese phonetic similarity algorithm based on learned high dimensional encoding[C]// Proceedings of the 22nd Conference on Computational Natural Language Learning. Stroudsburg:Association for Computational Linguistics, 2018: 444-453. |
| [9] | DUAN D G , LIANG S H , HAN Z M ,et al. Pinyin as a feature of neural machine translation for Chinese speech recognition error correction[C]// China National Conference on Chinese Computational Linguistics (CCL). Berlin:Springer, 2019: 651-663. |
| [10] | JIANG Y , WANG T , LIN T ,et al. A rule based Chinese spelling and grammar detection system utility[C]// Proceedings of 2012 International Conference on System Science and Engineering (ICSSE). Piscataway:IEEE Press, 2012: 437-440. |
| [11] | CHU W C , LIN C J . NTOU Chinese spelling check system in SIGHAN-8 bake-off[C]// Proceedings of the Eighth SIGHAN Workshop on Chinese Language Processing. Stroudsburg:Association for Computational Linguistics, 2015: 102-107. |
| [12] | XU H D , LI Z L , ZHOU Q Y ,et al. Read,listen,and see:leveraging multimodal information helps Chinese spell checking[C]// Proceedings of Findings of the Association for Computational Linguistics:ACL-IJCNLP 2021. Stroudsburg:Association for Computational Linguistics, 2021: 716-728. |
| [13] | 王辰成, 杨麟儿, 王莹莹 ,等. 基于Transformer增强架构的中文语法纠错方法[J]. 中文信息学报, 2020,34(6): 106-114. |
| WANG C C , YANG L E , WANG Y Y ,et al. Chinese grammatical error correction method based on transformer enhanced architecture[J]. Journal of Chinese Information Processing, 2020,34(6): 106-114. | |
| [14] | 段建勇, 袁阳, 王昊 . 基于Transformer局部信息及语法增强架构的中文拼写纠错方法[J]. 北京大学学报(自然科学版), 2021,57(1): 61-67. |
| DUAN J Y , YUAN Y , WANG H . Chinese spelling correction method based on transformer local information and syntax enhancement ar-chitecture[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2021,57(1): 61-67. | |
| [15] | ZHUANG L , BAO T , ZHU X ,et al. A Chinese OCR spelling check approach based on statistical language models[C]// Proceedings of 2004 IEEE International Conference on Systems,Man and Cybernetics. Piscataway:IEEE Press, 2004: 4727-4732. |
| [16] | XIE W J , HUANG P J , ZHANG X R ,et al. Chinese spelling check system based on N-gram model[C]// Proceedings of the Eighth SIGHAN Workshop on Chinese Language Processing. Stroudsburg:Association for Computational Linguistics, 2015: 128-136. |
| [17] | LIU X D , CHENG F , DUH K ,et al. A hybrid ranking approach to Chinese spelling check[J]. ACM Transactions on Asian and Low-Resource Language Information Processing, 2015,14(4): 1-17. |
| [18] | 冯海林, 张潇, 刘同存 . 融合评论文本特征和评分图卷积表示的推荐模型[J]. 通信学报, 2022,43(3): 164-171. |
| FENG H L , ZHANG X , LIU T C . Recommendation model combining review's feature and rating graph convolutional representation[J]. Journal on Communications, 2022,43(3): 164-171. | |
| [19] | 张煜, 吕锡香, 邹宇聪 ,等. 基于生成对抗网络的文本序列数据集脱敏[J]. 网络与信息安全学报, 2020,6(4): 109-119. |
| ZHANG Y , LYU X X , ZOU Y C ,et al. Differentially private sequence generative adversarial networks for data privacy masking[J]. Chinese Journal of Network and Information Security, 2020,6(4): 109-119. | |
| [20] | 叶俊民, 罗达雄, 陈曙 . 基于层次化修正框架的文本纠错模型[J]. 电子学报, 2021,49(2): 401-407. |
| YE J M , LUO D X , CHEN S . A text error correction model based on hierarchical editing framework[J]. Acta Electronica Sinica, 2021,49(2): 401-407. | |
| [21] | 郭可翔, 王衡军, 白祉旭 . 融合多通道CNN与BiGRU的字词级文本错误检测模型[J]. 计算机工程, 2022,48(9): 63-70. |
| GUO K X , WANG H J , BAI Z X . Detection model for word-level text error combining multi-channel CNN and BiGRU[J]. Computer Engi-neering, 2022,48(9): 63-70. | |
| [22] | WANG D M , SONG Y , LI J ,et al. A hybrid approach to automatic corpus generation for Chinese spelling check[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:Association for Computational Linguistics, 2018: 2517-2527. |
| [23] | WANG D M , TAY Y , ZHONG L . Confusionset-guided pointer networks for Chinese spelling check[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg:Association for Computational Linguistics, 2019: 5780-5785. |
| [24] | CHOLLAMPATT S , NG H T . A multilayer convolutional encoder-decoder neural network for grammatical error correction[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2018: 5755-5762. |
| [25] | LIU C L , LAI M H , TIEN K W ,et al. Visually and phonologically similar characters in incorrect Chinese words[J]. ACM Transactions on Asian Language Information Processing, 2011,10(2): 1-39. |
| [26] | WANG H , WANG B , DUAN J Y ,et al. Chinese spelling error detection using a fusion lattice LSTM[J]. ACM Transactions on Asian and Low-Resource Language Information Processing, 2021,20(2): 1-11. |
| [27] | LIU S L , YANG T , YUE T C ,et al. PLOME:pre-training with misspelled knowledge for Chinese spelling correction[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1:Long Papers). Stroudsburg:Association for Computational Linguistics, 2021: 2991-3000. |
| [28] | HONG Y Z , YU X G , HE N ,et al. FASPell:a fast,adaptable,simple,powerful Chinese spell checker based on DAE-decoder paradigm[C]// Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019). Stroudsburg:Association for Computational Linguistics, 2019: 160-169. |
| [29] | ZHANG S H , HUANG H R , LIU J C ,et al. Spelling error correction with soft-masked BERT[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg:Association for Computational Linguistics, 2020: 882-890. |
| [30] | CHENG X Y , XU W D , CHEN K L ,et al. SpellGCN:incorporating phonological and visual similarities into language models for Chinese spelling check[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg:Association for Computational Linguistics, 2020: 871-881. |
| [31] | JI T , YAN H , QIU X P . SpellBERT:a lightweight pretrained model for Chinese spelling check[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:Association for Computational Linguistics, 2021: 3544-3551. |
| [32] | ZHANG R Q , PANG C , ZHANG C Q ,et al. Correcting Chinese spelling errors with phonetic pre-training[C]// Proceedings of Findings of the Association for Computational Linguistics:ACL-IJCNLP 2021. Stroudsburg:Association for Computational Linguistics, 2021: 2250-2261. |
| [33] | TSENG Y H , LEE L H , CHANG L P ,et al. Introduction to SIGHAN 2015 bake-off for Chinese spelling check[C]// Proceedings of the Eighth SIGHAN Workshop on Chinese Language Processing. Stroudsburg:Association for Computational Linguistics, 2015: 32-37. |
| [34] | CHO K , MERRIENBOER B V , GULCEHRE C ,et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg:Association for Computational Linguistics, 2014: 1724-1734. |
| [35] | SUTSKEVER I , VINYALS O , LE Q V . Sequence to sequence learning with neural networks[C]// Annual Conference on Neural Information Processing Systems (NeurIPS). Cambridge:MIT Press, 2014: 3104-3112. |
| [36] | GRUNDKIEWICZ R , JUNCZYS-DOWMUNT M ,, . Near human-level performance in grammatical error correction with hybrid machine translation[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Volume 2 (Short Papers). Stroudsburg:Association for Computational Linguistics, 2018: 284-290. |
| [37] | LUONG T , PHAM H , MANNING C D . Effective approaches to attention-based neural machine translation[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:Association for Computational Linguistics, 2015: 1412-1421. |
| [38] | SHI Y , BU H , XU X ,et al. AISHELL-3:a multi-speaker mandarin TTS corpus and the baselines[J]. arXiv Preprint,arXiv:2010.11567, 2020. |
| [39] | POVEY D , GHOSHAL A , BOULIANNE G ,et al. The Kaldi speech recognition toolkit[C]// IEEE Workshop on Automatic Speech Recognition and Understanding (CONF). Piscataway:IEEE Press, 2011: 1-4. |
| [40] | 王宁 . 通用规范汉字字典[M]. 北京: 商务印书馆, 2013. |
| WANG N . The general specification Chinese character dictionary[M]. Beijing: The Commercial Press, 2013. |
| [1] | Hailin FENG, Xiao ZHANG, Tongcun LIU. Recommendation model combining review’s feature and rating graph convolutional representation [J]. Journal on Communications, 2022, 43(3): 164-171. |
| [2] | Zhuo CHEN, Miao ZHU, Junwei DU. Multi-view graph neural network for fraud detection algorithm [J]. Journal on Communications, 2022, 43(11): 225-232. |
| [3] | Hongyan WANG, Hai YUAN. Action recognition method based on fusion of skeleton and apparent features [J]. Journal on Communications, 2022, 43(1): 138-148. |
| [4] | Xiaojuan ZHAO, Yan JIA, Aiping LI, Kai CHEN. Research on link prediction model based on hierarchical attention mechanism [J]. Journal on Communications, 2021, 42(3): 36-44. |
| [5] | Fan GUO, Yongxiang ZHANG, Jin TANG, Weiqing LI. YOLOv3-A: a traffic sign detection network based on attention mechanism [J]. Journal on Communications, 2021, 42(1): 87-99. |
| [6] | Linhui LI,Bin ZHOU,Jing LIAN,Yafu ZHOU. Research on pedestrian trajectory prediction method based on social attention mechanism [J]. Journal on Communications, 2020, 41(6): 175-183. |
| [7] | Zhurong WANG, Wei XUE, Yabang NIU, Ying’an CUI, Qindong SUN, Xinhong HEI. Research on berth occupancy prediction model based on attention mechanism [J]. Journal on Communications, 2020, 41(12): 182-192. |
| [8] | Yong-jun HE,Ji-qing HAN. Linearized distortion model for robust speech recognition in noisy environments [J]. Journal on Communications, 2010, 31(9): 8-14. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||