

Journal on Communications ›› 2023, Vol. 44 ›› Issue (6): 183-197.doi: 10.11959/j.issn.1000-436x.2023122
• Papers • Previous Articles Next Articles
Biao JIN1,2, Yikang LI1, Zhiqiang YAO1,2, Yulin CHEN1, Jinbo XIONG1,2
Revised:2023-03-29
Online:2023-06-25
Published:2023-06-01
Supported by:CLC Number:
Biao JIN, Yikang LI, Zhiqiang YAO, Yulin CHEN, Jinbo XIONG. GenFedRL: a general federated reinforcement learning framework for deep reinforcement learning agents[J]. Journal on Communications, 2023, 44(6): 183-197.
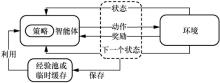
"
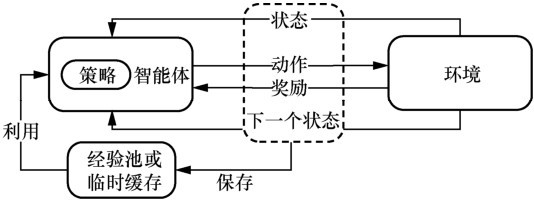

"
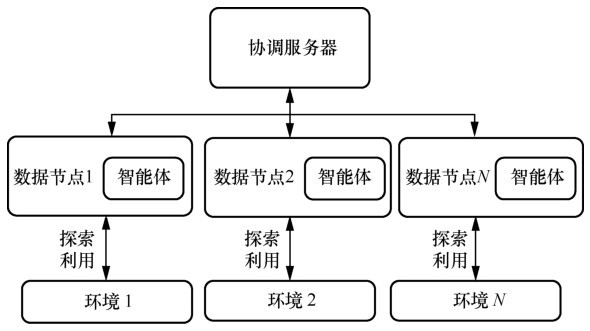
"
| 符号 | 含义 |
| Pi | 第i轮联邦强化学习过程 |
| P | 一次完整的联邦强化学习过程 |
| A ij | 第i轮参与训练的智能体集合中的第 j个智能体 |
| 第i轮联邦强化学习过程中参与训练的智能体集合, | |
| Env ij | 第i轮参与训练的智能体集合中的第 j个智能体所对应的环境 |
| Envi | 第i轮联邦强化学习过程中参与训练的智能体所对应的环境集合 |
| Eijk | 第i轮参与训练的第 j个智能体的第k轮本地训练 |
| 第i轮参与训练的第 j个智能体在环境Env ij中的本地训练集合, | |
| S ijk | Eijk对应的得分 |
| 本地训练 |
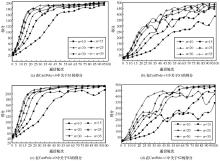
"
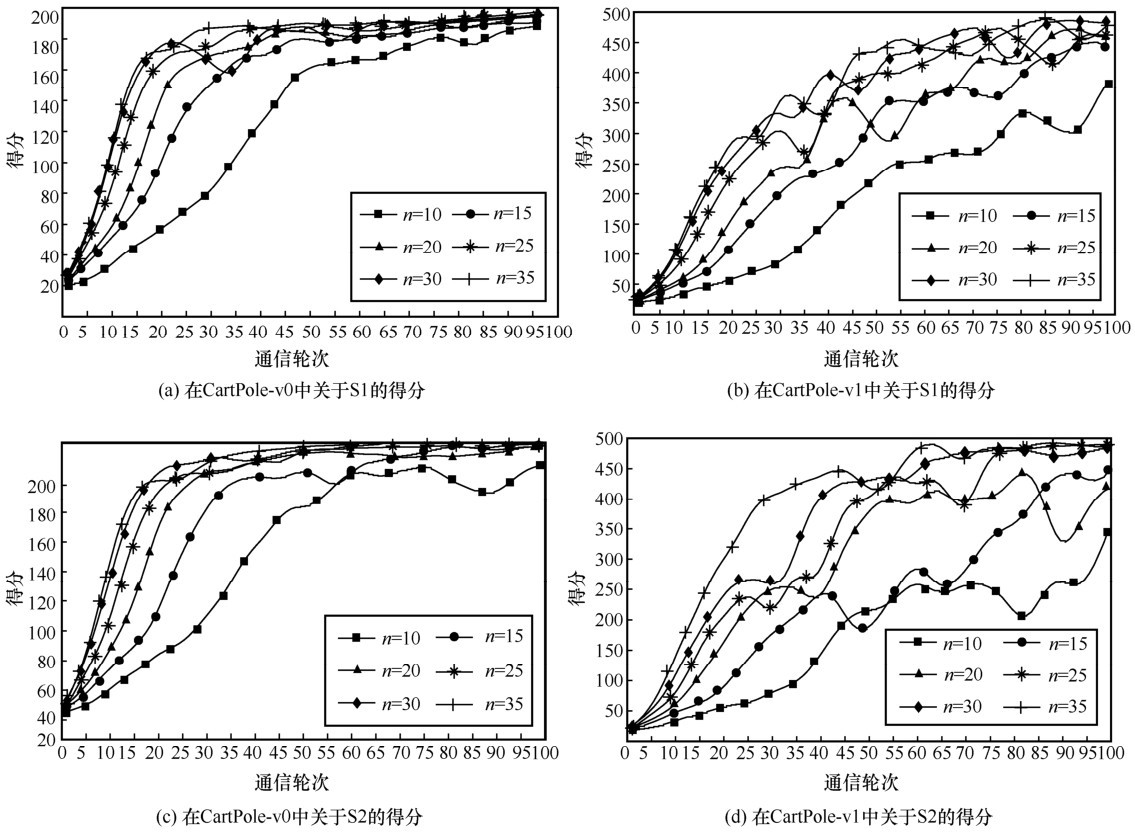
"
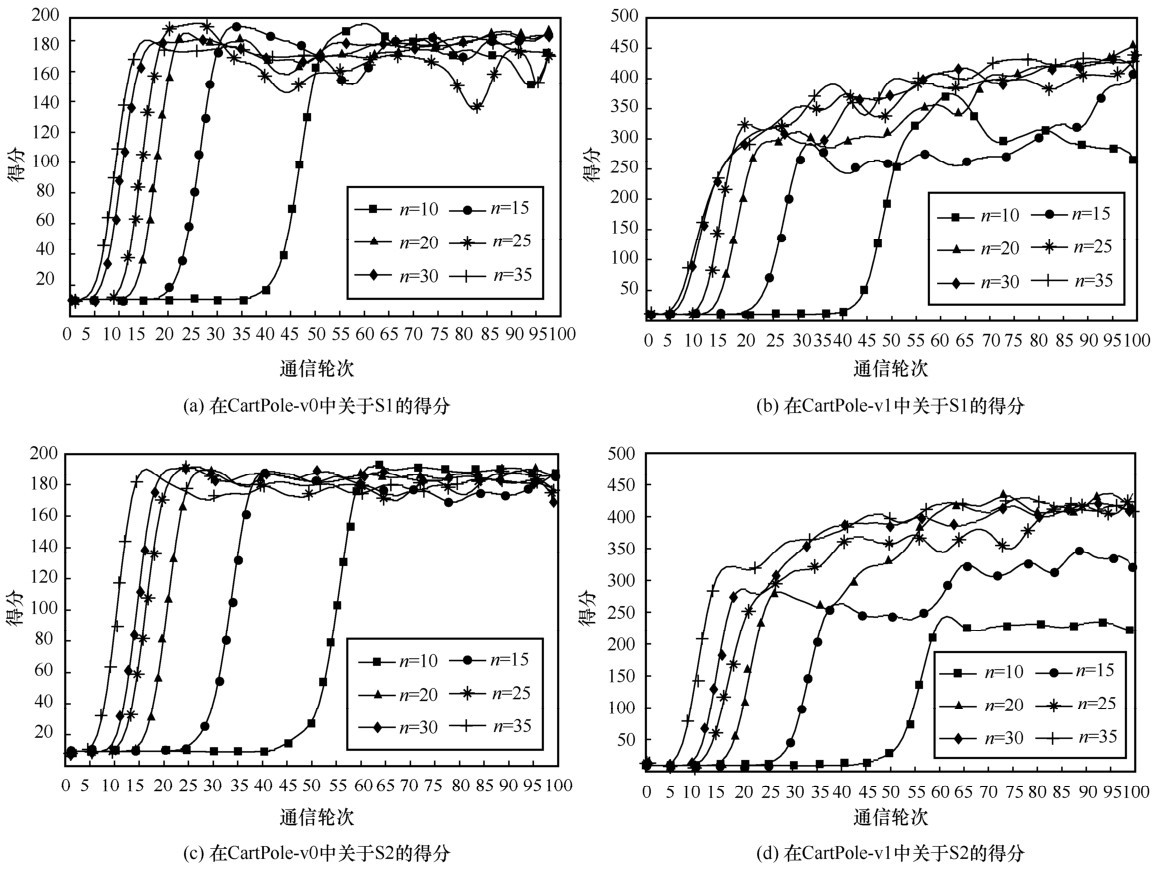

"
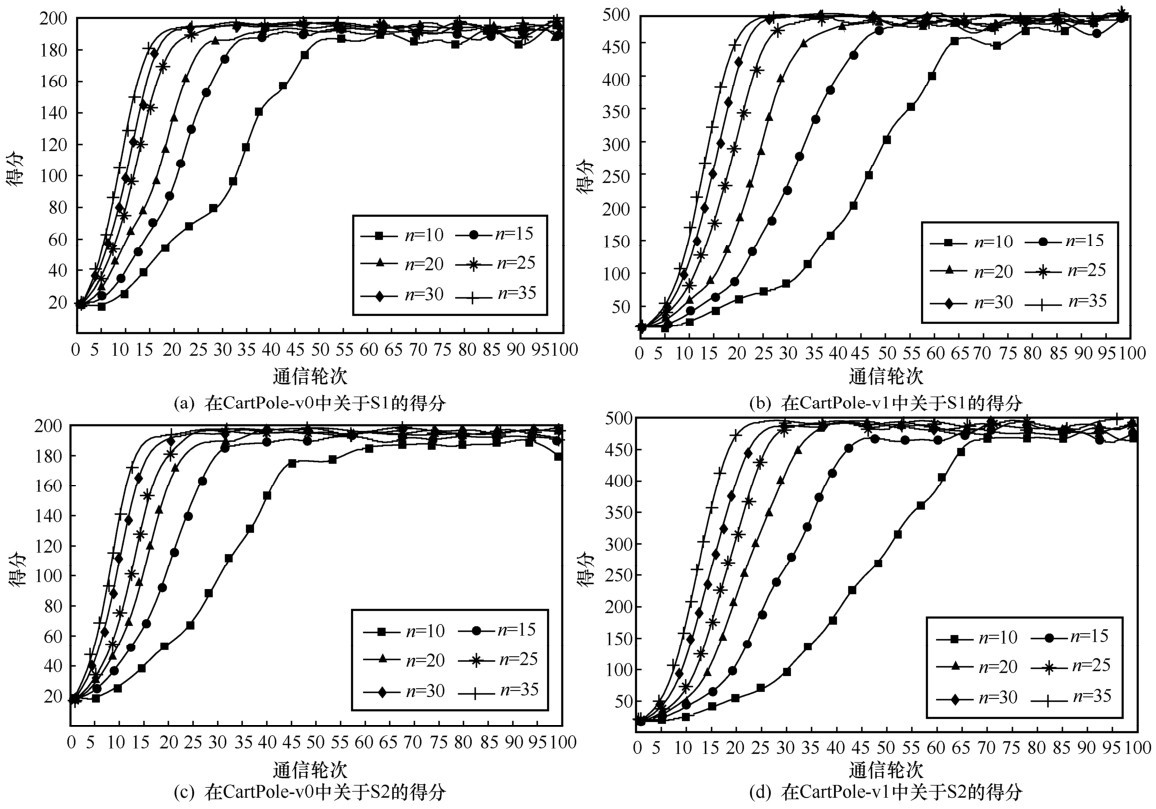

"
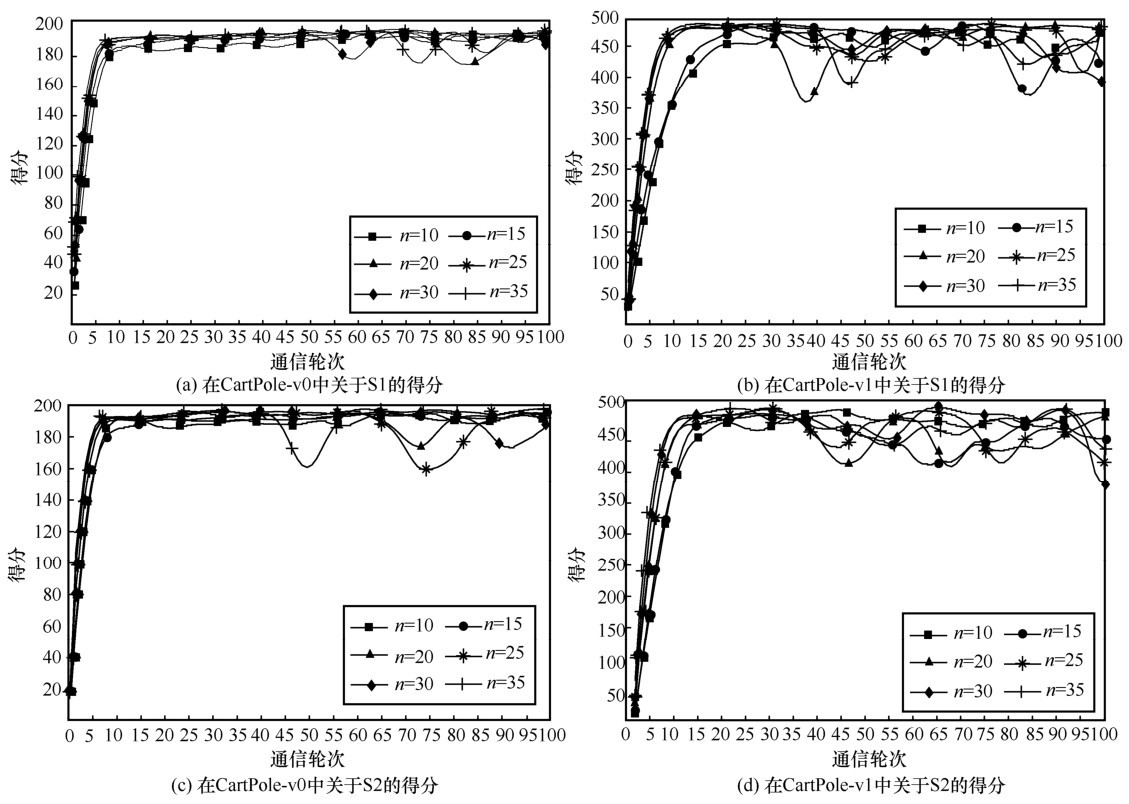

"


"

"
| 算法 | n=10 | n=15 | n=20 | n=25 | n=30 | n=35 |
| reinforce | 91 (—) | 73(68) | 45(44) | 36(47) | 42(31) | 27(33) |
| DQN | 57 (61) | 32 (—) | 99 (93) | 20 (23) | 99 (21) | —(16) |
| Actor Critic | 83 (90) | 40 (42) | 35 (33) | 24 (23) | 19 (19) | 17 (16) |
| PPO | 49 (10) | 19 (17) | 7 (8) | 10 (7) | 8 (7) | 6 (6) |
"
| 算法 | n=10 | n=15 | n=20 | n=25 | n=30 | n=35 |
| reinforce | —(—) | 81 (84) | 69 (60) | 55 (49) | 50 (40) | 44 (28) |
| DQN | —(—) | 99 (—) | 69 (59) | 87 (81) | 57 (70) | 50 (45) |
| Actor Critic | 59 (61) | 40 (38) | 29 (29) | 23 (23) | 19 (20) | 17 (16) |
| PPO | 13 (10) | 11 (9) | 7 (7) | 6 (7) | 5 (6) | 5 (5) |
"
| 算法 | n=5 | n=10 | n=15 | n=20 | n=25 | n=30 | n=35 |
| DDPG | 26 (31) | 12 (12) | 12 (8) | 10 (9) | 6 (7) | 6 (7) | 6 (7) |
| SAC | 16 (17) | 10 (14) | 7 (9) | 6 (9) | 6 (16) | 5 (11) | 8 (15) |
| [1] | MCMAHAN H B , MOORE E , RAMAGE D ,et al. Communication-efficient learning of deep networks from decentralized data[J]. arXiv Preprint,arXiv:1602.05629, 2016. |
| [2] | SILVER D , SCHRITTWIESER J , SIMONYAN K ,et al. Mastering the game of GO without human knowledge[J]. Nature, 2017,550(7676): 354-359. |
| [3] | HESSEL M , SOYER H , ESPEHOLT L ,et al. Multi-task deep reinforcement learning with PopArt[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2019: 3796-3803. |
| [4] | ANDRYCHOWICZ O M , BAKER B , CHOCIEJ M ,et al. Learning dexterous in-hand manipulation[J]. International Journal of Robotics Research, 2020,39(1): 3-20. |
| [5] | HAO J Y , YANG T P , TANG H Y ,et al. Exploration in deep reinforcement learning:from single-agent to multiagent domain[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023:doi.org/10.1109/TNNLS.2023.3236361. |
| [6] | 杨强, 刘洋, 程勇 ,等. 联邦学习[M]. 北京: 电子工业出版社, 2020. |
| YANG Q , LIU Y , CHENG Y ,et al. Federated learning[M. Beijing: Publishing House of Electronics Industry, 2020. | |
| [7] | ESPEHOLT L , SOYER H , MUNOS R ,et al. IMPALA:scalable distributed deep-RL with importance weighted actor-learner architectures[C]// Proceedings of International Conference on Machine Learning. New York:ACM Press, 2018: 1407-1416. |
| [8] | KAPTUROWSKI S , OSTROVSKI G , QUAN J ,et al. Recurrent experience replay in distributed reinforcement learning[C]// Proceedings of International Conference on Learning Representations. [s.l.:Open Review, 2019: 1-19. |
| [9] | ESPEHOLT L , MARINIER R , STANCZYK P ,et al. SEED RL:scalable and efficient deep-RL with accelerated central inference[J]. arXiv Preprint,arXiv:1910.06591, 2019. |
| [10] | KRISHNAN S , LAM M , CHITLANGIA S ,et al. QuaRL:quantization for fast and environmentally sustainable reinforcement learning[J]. arXiv Preprint,arXiv:1910.01055, 2019. |
| [11] | SCHAUL T , QUAN J , ANTONOGLOU I ,et al. Prioritized experience replay[J]. arXiv Preprint,arXiv:1511.05952, 2015. |
| [12] | 王志勤, 江甲沫, 刘沛西 ,等. 6G 联邦边缘学习新范式:基于任务导向的资源管理策略[J]. 通信学报, 2022,43(6): 16-27. |
| WANG Z Q , JIANG J M , LIU P X ,et al. New design paradigm for federated edge learning towards 6G:task-oriented resource management strategies[J. Journal on Communications, 2022,43(6): 16-27. | |
| [13] | ZHOU Z , TIAN Y L , XIONG J B ,et al. Blockchain-enabled secure and trusted federated data sharing in IIoT[J]. IEEE Transactions on Industrial Informatics, 2023,19(5): 6669-6681. |
| [14] | 贺文晨, 郭少勇, 邱雪松 ,等. 基于 DRL 的联邦学习节点选择方法[J]. 通信学报, 2021,42(6): 62-71. |
| HE W C , GUO S Y , QIU X S ,et al. Node selection method in federated learning based on deep reinforcement learning[J. Journal on Communications, 2021,42(6): 62-71. | |
| [15] | MIAO Q , LIN H , WANG X ,et al. Federated deep reinforcement learning based secure data sharing for Internet of things[J]. Computer Networks, 2021,197:108327. |
| [16] | MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533. |
| [17] | TESAURO G . Temporal difference learning and TD-Gammon[J]. Communications of the ACM, 1995,38(3): 58-68. |
| [18] | NADIGER C , KUMAR A , ABDELHAK S . Federated reinforcement learning for fast personalization[C]// Proceedings of 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering. Piscataway:IEEE Press, 2019: 123-127. |
| [19] | LIU B Y , WANG L J , LIU M . Lifelong federated reinforcement learning:a learning architecture for navigation in cloud robotic systems[J]. IEEE Robotics and Automation Letters, 2019,4(4): 4555-4562. |
| [20] | MOWLA N I , TRAN N H , DOH I ,et al. AFRL:adaptive federated reinforcement learning for intelligent jamming defense in FANET[J]. Journal of Communications and Networks, 2020,22(3): 244-258. |
| [21] | WANG X F , WANG C Y , LI X H ,et al. Federated deep reinforcement learning for Internet of things with decentralized cooperative edge caching[J]. IEEE Internet of Things Journal, 2020,7(10): 9441-9455. |
| [22] | HASSELT H V , GUEZ A , SILVER D . Deep reinforcement learning with double Q-learning[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2016: 2094-2100. |
| [23] | WILLIAMS R J . Simple statistical gradient-following algorithms for connectionist reinforcement learning[J]. Machine Learning, 1992,8(3): 229-256. |
| [24] | SUTTON R S , MCALLESTER D , SINGH S ,et al. Policy gradient methods for reinforcement learning with function approximation[C]// Proceedings of the 12th International Conference on Neural Information Processing Systems. New York:ACM, 1999: 1057-1063. |
| [25] | KONDA V , TSITSIKLIS J . Actor-critic algorithms[J]. Advances in Neural Information Processing Systems, 1999,12: 1008-1014. |
| [26] | ZHAO G Q , XU J M , LIU A D ,et al. Research on proximal policy optimization algorithm based on N-step update[C]// Proceedings of International Conference on Communications,Information System and Computer Engineering. Piscataway:IEEE Press, 2021: 854-857. |
| [27] | SEYED M S M , BAGHI V , MIANDOAB E M ,et al. Duplicated replay buffer for asynchronous deep deterministic policy gradient[C]// Proceedings of the 26th International Computer Conference,Computer Society of Iran. Piscataway:IEEE Press, 2021: 1-6. |
| [28] | HAARNOJA T , ZHOU A , ABBEEL P ,et al. Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]// 2018 International Conference on Machine Learning. New York:ACM Press, 2018: 1861-1870. |
| [29] | LIM H K , KIM J B , HEO J S ,et al. Federated reinforcement learning for training control policies on multiple IoT devices[J]. Sensors, 2020,20(5): 1359. |
| [30] | YOO S , LEE W . Federated reinforcement learning based AANs with LEO satellites and UAVs[J]. Sensors, 2021,21(23): 8111. |
| [31] | HU Y Q , HUA Y , LIU W Y ,et al. Reward shaping based federated reinforcement learning[J]. IEEE Access, 2021,9: 67259-67267. |
| [32] | NG A Y , HARADA D , RUSSELL S J . Policy invariance under reward transformations:theory and application to reward shaping[C]// Proceedings of the 16th International Conference on Machine Learning. New York:ACM Press, 1999: 278-287. |
| [33] | KINGMA D P , BA J . Adam:a method for stochastic optimization[J]. arXiv Preprint,arXiv:1412.6980, 2014. |
| [34] | LE G T , MARJOU X , LEMLOUMA T ,et al. A multi-agent OpenAI gym environment for telecom providers cooperation[C]// Proceedings of the 24th Conference on Innovation in Clouds,Internet and Networks and Workshops. Piscataway:IEEE Press, 2021: 28-32. |
| [35] | BARTO A G , SUTTON R S , ANDERSON C W . Neuronlike adaptive elements that can solve difficult learning control problems[J]. IEEE Transactions on Systems,Man,and Cybernetics, 1983,SMC-13(5): 834-846. |
| [36] | MOHASSEL P , ZHANG Y P . SecureML:a system for scalable privacy-preserving machine learning[C]// Proceedings of IEEE Symposium on Security and Privacy. Piscataway:IEEE Press, 2017: 19-38. |
| [37] | ACAR A , AKSU H , ULUAGAC A S ,et al. A survey on homomorphic encryption schemes:theory and implementation[J]. ACM Computing Surveys, 2018,51(4): 1-35. |
| [38] | EL-YAHYAOUI A , ECH-CHERIF E K M D . A verifiable fully homomorphic encryption scheme for cloud computing security[J]. Technologies, 2019,7(1): 21. |
| [39] | DWORK C , MCSHERRY F , NISSIM K ,et al. Calibrating noise to sensitivity in private data analysis[C]// Proceedings of Third Theory of Cryptography Conference. Berlin:Springer, 2006: 265-284. |
| [40] | DWORK C , FELDMAN V , HARDT M ,et al. Preserving statistical validity in adaptive data analysis[C]// Proceedings of the 47th Annual ACM Symposium on Theory of Computing. New York:ACM Press, 2015: 117-126. |
| [1] | Yuancheng LI, Yongtai QIN. Deep reinforcement learning based algorithm for real-time QoS optimization of software-defined security middle platform [J]. Journal on Communications, 2023, 44(5): 181-192. |
| [2] | Guoliang XU, Feng TAN, Yongyi RAN, Feng CHEN. Joint beam hopping and coverage control optimization algorithm for multibeam satellite system [J]. Journal on Communications, 2023, 44(4): 78-86. |
| [3] | Zongxuan SHA, Ru HUO, Chuang SUN, Shuo WANG, Tao HUANG. Forwarding efficiency aware traffic scheduling algorithm based on deep reinforcement learning [J]. Journal on Communications, 2022, 43(8): 30-40. |
| [4] | Yu ZHANG, Min CHENG. Joint optimization of edge computing and caching in NDN [J]. Journal on Communications, 2022, 43(8): 164-175. |
| [5] | Xianchao ZHANG, Yao ZHAO, Haijun YE, Rui FAN. Intelligent transmit power control algorithm for the multi-user interference of wireless network [J]. Journal on Communications, 2022, 43(2): 15-21. |
| [6] | Xin SU, Leilei MENG, Yiqing ZHOU, Wu CELIMUGE. Maritime mobile edge computing offloading method based on deep reinforcement learning [J]. Journal on Communications, 2022, 43(10): 133-145. |
| [7] | Li’na DU, Li ZHUO, Shuo YANG, Jiafeng LI, Jing ZHANG. Survey on reinforcement learning based adaptive bit rate algorithm for mobile video streaming services [J]. Journal on Communications, 2021, 42(9): 205-217. |
| [8] | Wenchen HE, Shaoyong GUO, Xuesong QIU, Liandong CHEN, Suxiang ZHANG. Node selection method in federated learning based on deep reinforcement learning [J]. Journal on Communications, 2021, 42(6): 62-71. |
| [9] | Guolin SUN,Ruijie OU,Guisong LIU. Deep reinforcement learning-based resource reservation algorithm for emergency Internet-of-things slice [J]. Journal on Communications, 2020, 41(9): 8-20. |
| [10] | Yingchang LIANG,Junjie TAN,Dusit Niyato. Overview on intelligent wireless communication technology [J]. Journal on Communications, 2020, 41(7): 1-17. |
| [11] | Tingting LIU,Yi’nan LUO,Chenyang YANG. Distributed interference coordination based on multi-agent deep reinforcement learning [J]. Journal on Communications, 2020, 41(7): 38-48. |
| [12] | Pei ZHANG,Shuaijun LIU,Zhiguo MA,Xiaohui WANG,Junde SONG. Improved satellite resource allocation algorithm based on DRL and MOP [J]. Journal on Communications, 2020, 41(6): 51-60. |
| [13] | Quan LIU,Yubin JIANG,Zhihui HU. Advantage estimator based on importance sampling [J]. Journal on Communications, 2019, 40(5): 108-116. |
| [14] | Xiaomin LIAO,Shaohu YAN,Jia SHI,Zhenyu TAN,Zhongling ZHAO,Zan LI. Deep reinforcement learning based resource allocation algorithm in cellular networks [J]. Journal on Communications, 2019, 40(2): 11-18. |
| [15] | Julong LAN,Xueshuai ZHANG,Yuxiang HU,Penghao SUN. Software-defined networking QoS optimization based on deep reinforcement learning [J]. Journal on Communications, 2019, 40(12): 60-67. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||