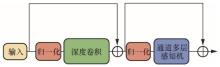
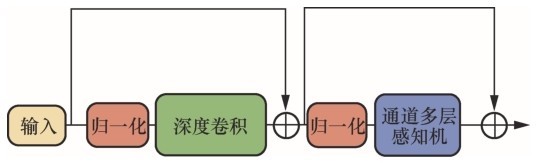
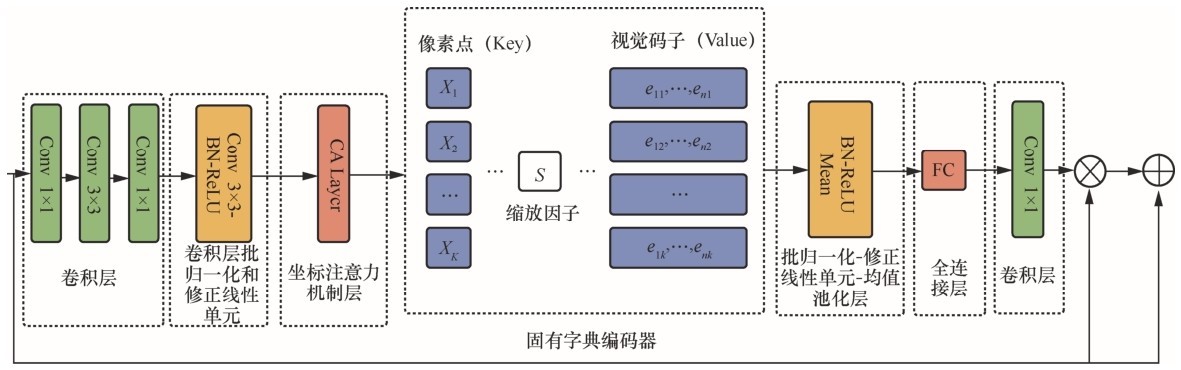
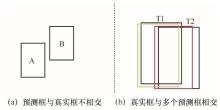
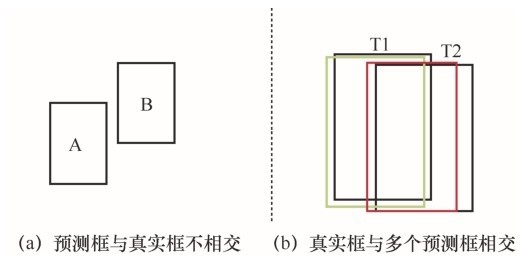
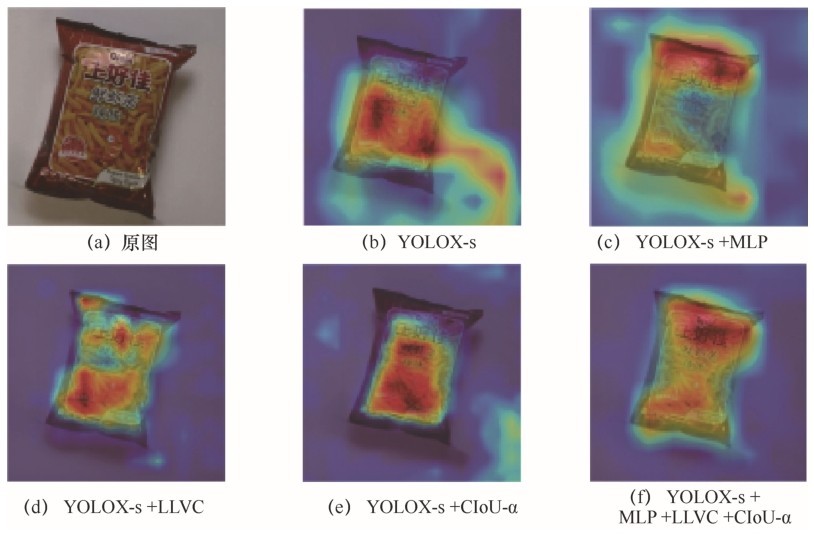
| [10] |
SZEGEDY C , VANHOUCKE V , IOFFE S ,et al. Rethinking the inception architecture for computer vision[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2016: 2818-2826.
|
| [11] |
SELVAM P , KOILRAJ J A S . A deep learning framework for grocery product detection and recognition[J]. Food Analytical Methods, 2022,15(12): 3498-3522.
|
| [12] |
WANG H I , MIYAZAKI L K , FALHEIRO M S ,et al. Designing a self-payment cashier for bakeries using YOLO V4[C]// Proceedings of 2021 14th IEEE International Conference on Industry Applications (INDUSCON). Piscataway:IEEE Press, 2021: 260-265.
|
| [13] |
GE Z , LIU S , WANG F ,et al. YOLOX:exceeding YOLO series in 2021[J]. arXiv preprint, 2021,arXiv:2107.08430.
|
| [14] |
WANG H I , MIYAZAKI L K , FALHEIRO M S ,et al. Designing a self-payment cashier for bakeries using YOLO V4[C]// Proceedings of 2021 14th IEEE International Conference on Industry Applications (INDUSCON). Piscataway:IEEE Press, 2021: 260-265.
|
| [15] |
QUAN Y , ZHANG D , ZHANG L ,et al. Centralized feature pyramid for object detection[J]. arXiv preprint, 2022,arXiv:2210.02093.
|
| [16] |
HOU Q B , ZHOU D Q , FENG J S . Coordinate attention for efficient mobile network design[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2021: 13708-13717.
|
| [17] |
YU J H , JIANG Y N , WANG Z Y ,et al. UnitBox:an advanced object detection network[C]// Proceedings of the 24th ACM International Conference on Multimedia. New York:ACM Press, 2016: 516-520.
|
| [18] |
ZHENG Z H , WANG P , LIU W ,et al. Distance-IoU loss:faster and better learning for bounding box regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020,34(7): 12993-13000.
|
| [19] |
HE J , ERFANI S , MA X ,et al. Alpha-IoU:a family of power intersection over union losses for bounding box regression[J]. Advances in Neural Information Processing Systems, 2021,34: 20230-20242.
|
| [20] |
BOCHKOVSKIY A , WANG C Y , LIAO H Y M . YOLOv4:optimal speed and accuracy of object detection[J]. arXiv preprint, 2020:arXiv:2004.10934.
|
| [1] |
SARAN A , HASSAN E , MAURYA A K . Robust visual analysis for planogram compliance problem[C]// Proceedings of 2015 14th IAPR International Conference on Machine Vision Applications (MVA). Piscataway:IEEE Press, 2015: 576-579.
|
| [2] |
RAY A , KUMAR N , SHAW A ,et al. U-PC:Unsupervised planogram compliance[C]// European Conference on Computer Vision. Cham:Springer, 2018: 598-613.
|
| [3] |
GEORGE M , FLOERKEMEIER C . Recognizing products:a per-exemplar multi-label image classification approach[C]// European Conference on Computer Vision. Cham:Springer, 2014: 440-455.
|
| [4] |
HIGA K , IWAMOTO K , NOMURA T . Multiple object identification using grid voting of object center estimated from keypoint matches[C]// Proceedings of 2013 IEEE International Conference on Image Processing. Piscataway:IEEE Press, 2014: 2973-2977.
|
| [5] |
BAO R , HIGA K , IWAMOTO K . Local feature based multiple object instance identification using scale and rotation invariant implicit shape model[C]// Computer Vision-ACCV 2014 Workshops. Cham:Springer International Publishing, 2015: 600-614.
|
| [6] |
Y?RüK E , ?NER K T , AKGüL C B . An efficient Hough transform for multi-instance object recognition and pose estimation[C]// Proceedings of 2016 23rd International Conference on Pattern Recognition (ICPR). Piscataway:IEEE Press, 2017: 1352-1357.
|
| [7] |
WEI Y C , TRAN S , XU S X ,et al. Deep learning for retail product recognition:challenges and techniques[J]. Computational Intelligence and Neuroscience, 2020:8875910.
|
| [8] |
HURTIK P , MOLEK V , VLASANEK P . YOLO-ASC:you only look once and see contours[C]// Proceedings of 2020 International Joint Conference on Neural Networks (IJCNN). Piscataway:IEEE Press, 2020: 1-7.
|
| [9] |
GOLDMAN E , HERZIG R , EISENSCHTAT A ,et al. Precise detection in densely packed scenes[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2020: 5222-5231.
|
| [21] |
REDMON J , FARHADI A . YOLOv3:an incremental improvement[J]. arXiv preprint, 2018,arXiv:1804.02767.
|
| [22] |
LIN T Y , DOLLáR P , GIRSHICK R ,et al. Feature pyramid networks for object detection[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2017: 936-944.
|
| [23] |
LIU S , QI L , QIN H F ,et al. Path aggregation network for instance segmentation[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 8759-8768.
|
| [24] |
HOWARD A G , ZHU M , CHEN B ,et al. MobileNets:efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint, 2017,arXiv:1704.04861.
|
| [25] |
TOLSTIKHIN I , HOULSBY N , KOLESNIKOV A ,et al. MLP-mixer:an all-MLP architecture for vision[J]. Advances in Neural Information Processing Systems, 2021(34): 24261-24272.
|
| [26] |
HENDRYCKS D , GIMPEL K . Gaussian error linear units (GELUs)[J]. arXiv preprint, 2016,arXiv:1606.08415.
|
| [27] |
IOFFE S , SZEGEDY C . Batch normalization:accelerating deep network training by reducing internal covariate shift[C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. New York:ACM Press, 2015: 448-456.
|
| [28] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017,60(6): 84-90.
|
| [29] |
BA J L , KIROS J R , HINTON G E . Layer normalization[J]. arXiv preprint, 2016,arXiv:1607.06450.
|
| [30] |
LOSHCHILOV I , HUTTER F . SGDR:stochastic gradient descent with warm restarts[J]. arXiv preprint, 2016,arXiv:1608.03983.
|