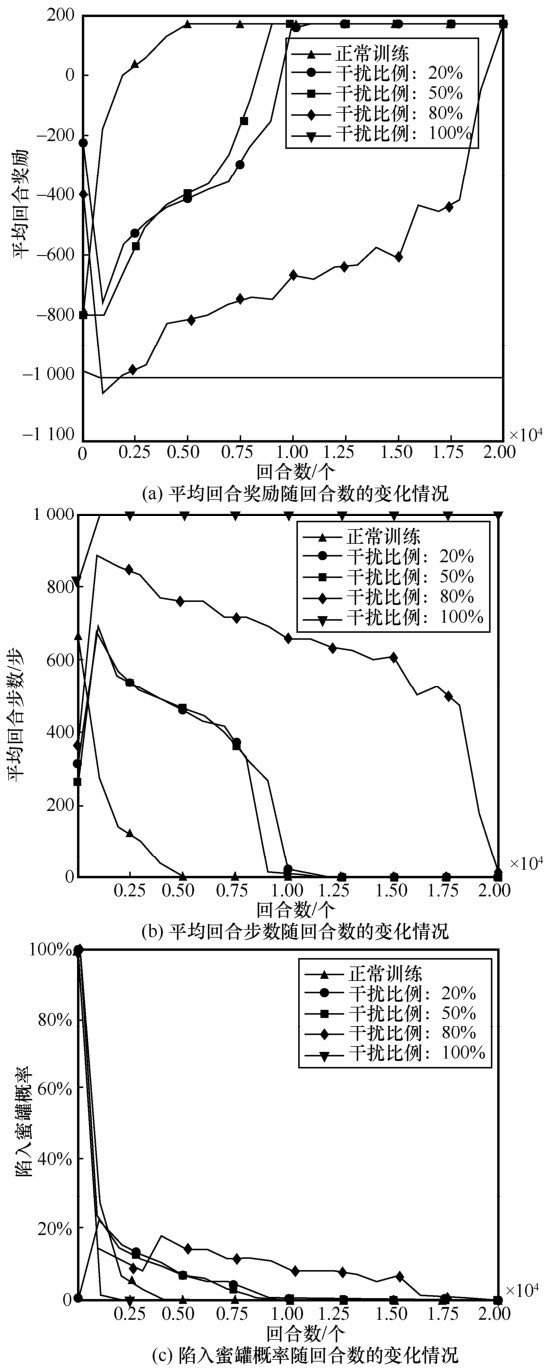
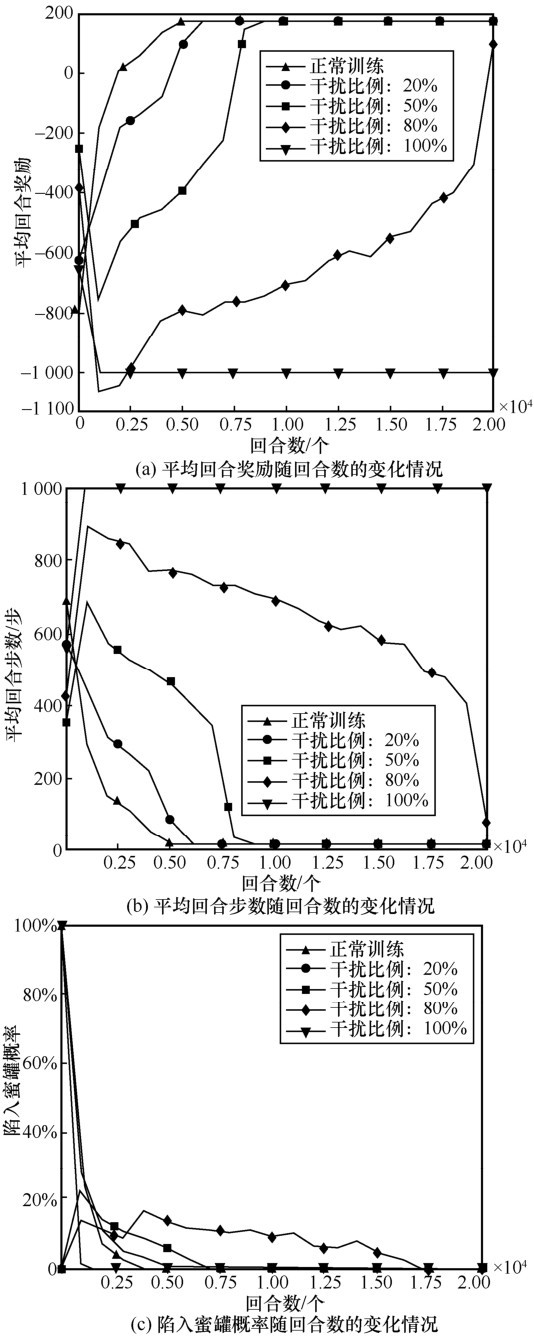
| [1] |
ARKIN B , STENDER S , MCGRAW G . Software penetration testing[J]. IEEE Security & Privacy, 2005,3(1): 84-87.
|
| [2] |
杨宏宇, 袁海航, 张良 . 基于攻击图的主机安全评估方法[J]. 通信学报, 2022,43(2): 89-99.
|
|
ROWE N C , CUSTY EJ , DUONG B T . Defending cyberspace with fake honeypots[J]. Journal of Computers, 2007,2(2): 25-36.
|
| [3] |
KAUR G , KAUR N . Penetration testing-reconnaissance with Nmap tool[J]. International Journal of Advanced Research in Computer Science, 2017,8(3): 844-846.
|
| [4] |
MULI?SKI T . ICT security in tax administration - Rapid7 Nexpose vulnerability analysis[J]. Studia Informatica, 2021,24: 37-51.
|
| [5] |
LEE A . Advanced penetration testing for highly-secured environments:the ultimate security guide[M]. Birmingham: Packt Publishing, 2012.
|
| [6] |
HelpSysthems. Core impact[EB]. 2021.
|
| [7] |
SAYED A . Adaptation,learning,and optimization over networks[J]. Foundations and Trends in Machine Learning, 2014,7(4/5): 311-801.
|
| [8] |
MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Playing atari with deep reinforcement learning[J]. arXiv Preprint,arXiv:1312.5602, 2013.
|
| [9] |
ZHOU S C , LIU J J , HOU D D ,et al. Autonomous penetration testing based on improved deep Q-network[J]. Applied Sciences, 2021,11(19): 8823.
|
| [10] |
TRAN K , AKELLA A , STANDEN M ,et al. Deep hierarchical reinforcement agents for automated penetration testing[J]. arXiv Preprint,arXiv:2109.06449, 2021.
|
| [11] |
DULAC-ARNOLD G , EVANS R , SUNEHAGP ,et al. Reinforcement learning in large discrete action spaces[J]. arXiv Preprint,arXiv:1512.07679, 2015.
|
| [12] |
YUILL J J . Defensive computer-security deception operations:processes,principles and techniques[D]. Raleigh:North Carolina State University, 2006.
|
| [13] |
Gartner Research. Hype cycle for threat-facing technologies 2017[R]. 2017.
|
| [14] |
贾召鹏, 方滨兴, 刘潮歌 ,等. 网络欺骗技术综述[J]. 通信学报, 2017,38(12): 128-143.
|
|
JIA Z P , FANG B X , LIU C G ,et al. Survey on cyber deception[J]. Journal on Communications, 2017,38(12): 128-143.
|
| [15] |
胡永进, 马骏, 郭渊博 . 基于博弈论的网络欺骗研究[J]. 通信学报, 2018,39(S2): 9-18.
|
|
HU Y J , MA J , GUO Y B . Research on cyber deception based on game theory[J]. Journal on Communications, 2018,39(S2): 9-18.
|
| [16] |
王硕, 王建华, 裴庆祺 ,等. 基于动态伪装网络的主动欺骗防御方法[J]. 通信学报, 2020,41(2): 97-111.
|
|
WANG S , WANG J H , PEI Q Q ,et al. Active deception defense method based on dynamic camouflage network[J]. Journal on Communications, 2020,41(2): 97-111.
|
| [17] |
JAFARIAN J H , AL-SHAER E , DUAN Q . Adversary-aware IP address randomization for proactive agility against sophisticated attackers[C]// Proceedings of 2015 IEEE Conference on Computer Communications. Piscataway:IEEE Press, 2015: 738-746.
|
| [18] |
WANG K , CHEN X , ZHU Y F . Random domain name and address mutation (RDAM) for thwarting reconnaissance attacks[J]. PLoS One, 2017,12(5): e0177111.
|
| [19] |
ANAGNOSTAKIS K , SIDIROGLOU S , AKRITIDIS P ,et al. Detecting targeted attacks using shadow honeypots[C]// Proceedings of the 14th Conference on USENIX Security Symposium. Berkeley:USENIX Association, 2005:9.
|
| [20] |
ROWE N C , CUSTY E J , DUONG B T . Defending cyberspace with fake honeypots[J]. Journal of Computers, 2007,2(2): 25-36.
|
| [21] |
石乐义, 姜蓝蓝, 刘昕 ,等. 拟态式蜜罐诱骗特性的博弈理论分析[J]. 电子与信息学报, 2013,35(5): 1063-1068.
|
|
SHI L Y , JIANG L L , LIU X ,et al. Game theoretic analysis for the feature of mimicry honeypot[J]. Journal of Electronics & Information Technology, 2013,35(5): 1063-1068.
|
| [22] |
SILVER D , HUANG A , MADDISON C J ,et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016,529(7587): 484-489.
|
| [23] |
BERNER C , BROCKMAN G , CHAN B ,et al. Dota 2 with large scale deep reinforcement learning[J]. arXiv Preprint,arXiv:1912.06680, 2019.
|
| [24] |
VINYALS O , BABUSCHKIN I , CZARNECKI W M ,et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019,575(7782): 350-354.
|
| [25] |
SCHWARTZ J , KURNIAWATI H . Autonomous penetration testing using reinforcement learning[J]. arXiv Preprint,arXiv:1905.05965, 2019.
|
| [26] |
ZENNARO F M , ERDODI L . Modeling penetration testing with reinforcement learning using capture-the-flag challenges and tabular Q-learning[J]. arXiv Preprint,arXiv:2005.12632, 2005.
|
| [27] |
臧艺超, 周天阳, 朱俊虎 ,等. 领域独立智能规划技术及其面向自动化渗透测试的攻击路径发现研究进展[J]. 电子与信息学报, 2020,42(9): 2095-2107.
|
|
ZANG Y C , ZHOU T Y , ZHU J H ,et al. Domain-independent intelligent planning technology and its application to automated penetration testing oriented attack path discovery[J]. Journal of Electronics &Information Technology, 2020,42(9): 2095-2107.
|
| [28] |
SCHWARTZ J . Network attack simulator[EB]. 2017.
|