

通信学报 ›› 2023, Vol. 44 ›› Issue (6): 183-197.doi: 10.11959/j.issn.1000-436x.2023122
金彪1,2, 李逸康1, 姚志强1,2, 陈瑜霖1, 熊金波1,2
修回日期:2023-03-29
出版日期:2023-06-25
发布日期:2023-06-01
作者简介:金彪(1985- ),男,安徽六安人,博士,福建师范大学副教授、硕士生导师,主要研究方向为信息安全、隐私保护等基金资助:Biao JIN1,2, Yikang LI1, Zhiqiang YAO1,2, Yulin CHEN1, Jinbo XIONG1,2
Revised:2023-03-29
Online:2023-06-25
Published:2023-06-01
Supported by:摘要:
针对智能物联网中,搭载深度强化学习智能体的智能设备缺乏有效安全数据共享机制的问题,提出一种面向深度强化学习智能体的通用联邦强化学习(GenFedRL)框架。GenFedRL不需要共享深度强化学习智能体的本地私有数据,而通过模型共享技术实现共同训练,在保护各智能体私有数据隐私的同时,有效地利用其数据资源和计算资源。为应对现实通信环境的复杂性与满足加速训练的需要,为GenFedRL设计了基于同步并行的模型共享机制。结合常见深度强化学习算法自身的模型结构特点,基于 FedAvg 算法设计了适用于单网络结构与多网络结构的通用联邦强化学习算法,进而实现了具有同种网络结构的智能体间的模型共享机制,更好地保护各类智能体的私有数据。仿真实验表明,即使在大部分数据节点无法参与训练的恶劣通信环境下,常见深度强化学习算法智能体在所提框架上仍表现出良好的性能。
中图分类号:
金彪, 李逸康, 姚志强, 陈瑜霖, 熊金波. GenFedRL:面向深度强化学习智能体的通用联邦强化学习框架[J]. 通信学报, 2023, 44(6): 183-197.
Biao JIN, Yikang LI, Zhiqiang YAO, Yulin CHEN, Jinbo XIONG. GenFedRL: a general federated reinforcement learning framework for deep reinforcement learning agents[J]. Journal on Communications, 2023, 44(6): 183-197.
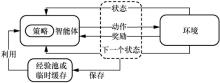
图1
搭载异策略/同策略深度强化学习算法智能体的数据节点工作原理"
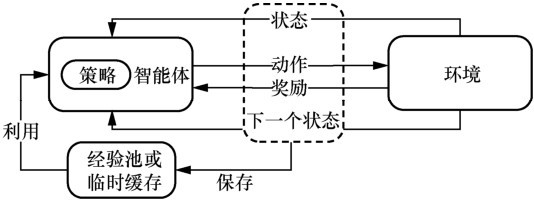

图2
GenFedRL框架"
表1
符号定义"
| 符号 | 含义 |
| Pi | 第i轮联邦强化学习过程 |
| P | 一次完整的联邦强化学习过程 |
| A ij | 第i轮参与训练的智能体集合中的第 j个智能体 |
| 第i轮联邦强化学习过程中参与训练的智能体集合, | |
| Env ij | 第i轮参与训练的智能体集合中的第 j个智能体所对应的环境 |
| Envi | 第i轮联邦强化学习过程中参与训练的智能体所对应的环境集合 |
| Eijk | 第i轮参与训练的第 j个智能体的第k轮本地训练 |
| 第i轮参与训练的第 j个智能体在环境Env ij中的本地训练集合, | |
| S ijk | Eijk对应的得分 |
| 本地训练 |
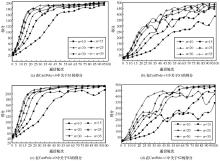
图3
搭载reinforce智能体的GenFedRL的得分"
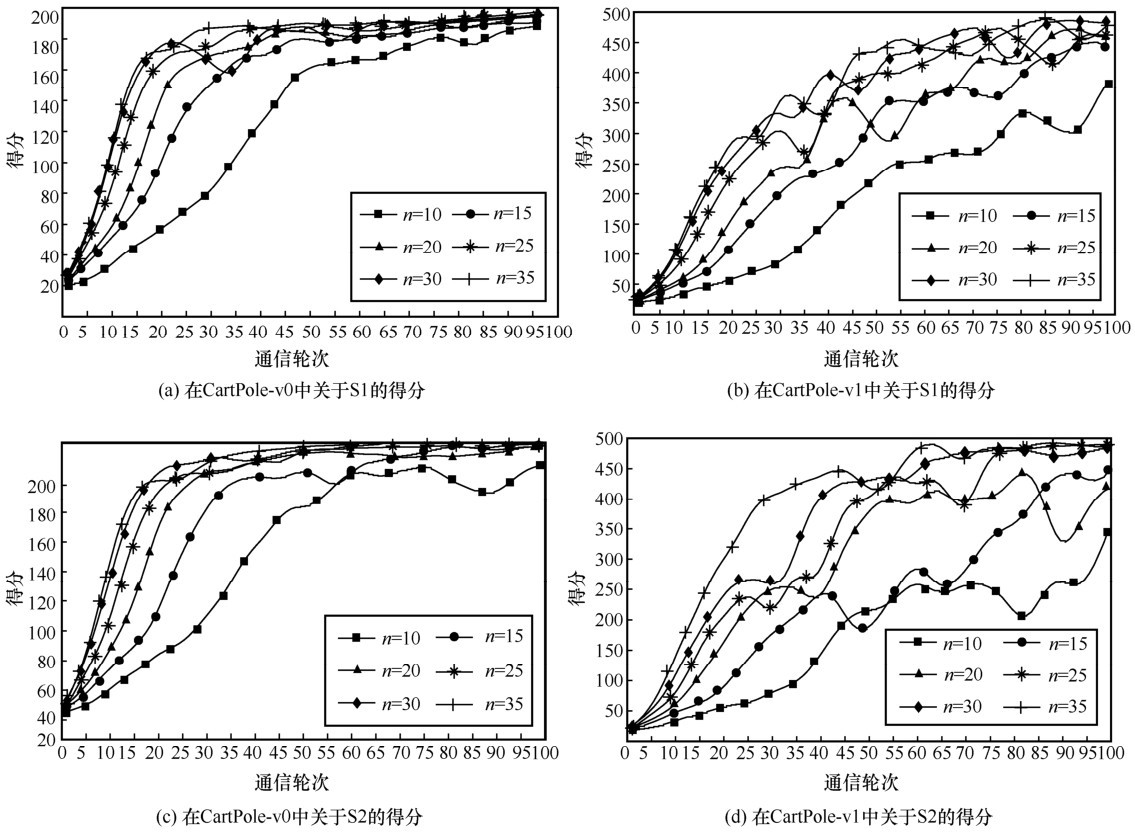
图4
搭载DQN智能体的GenFedRL的得分"
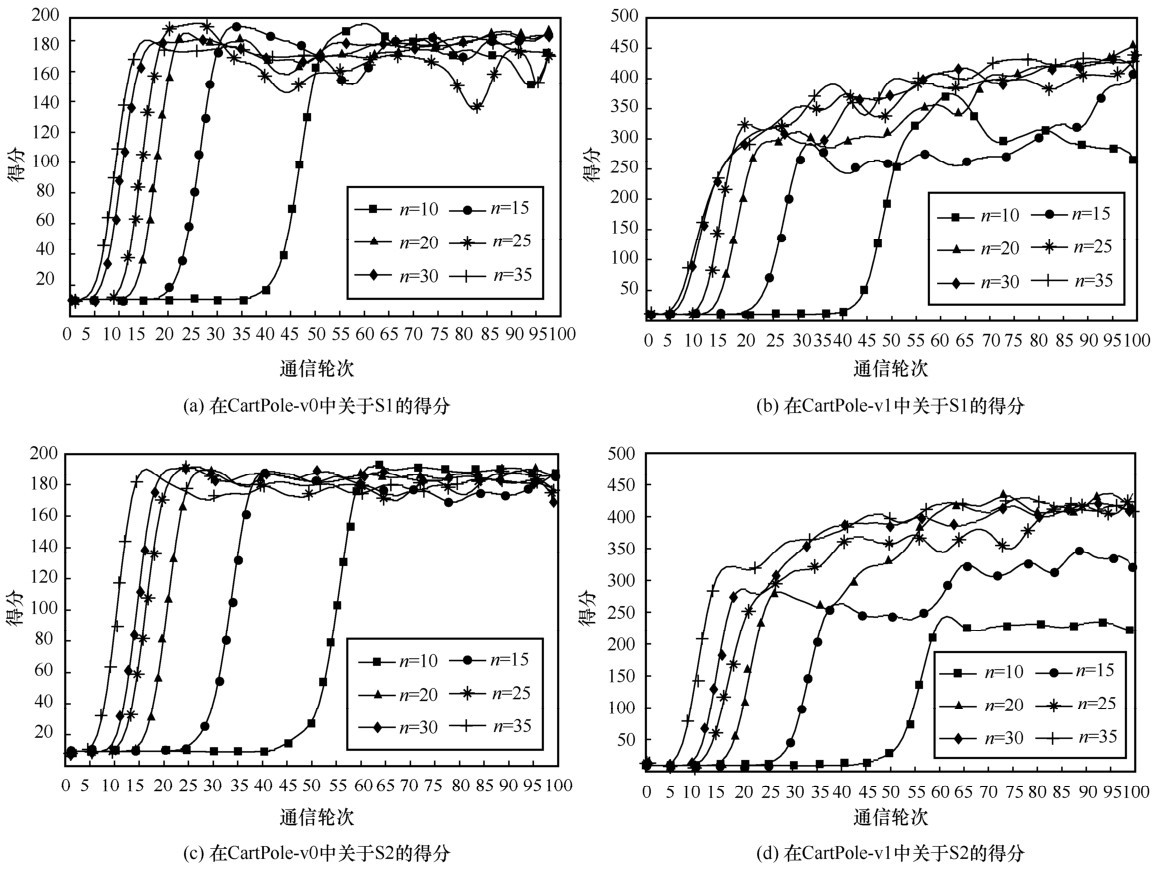

图5
搭载Actor Critic智能体的GenFedRL的得分"
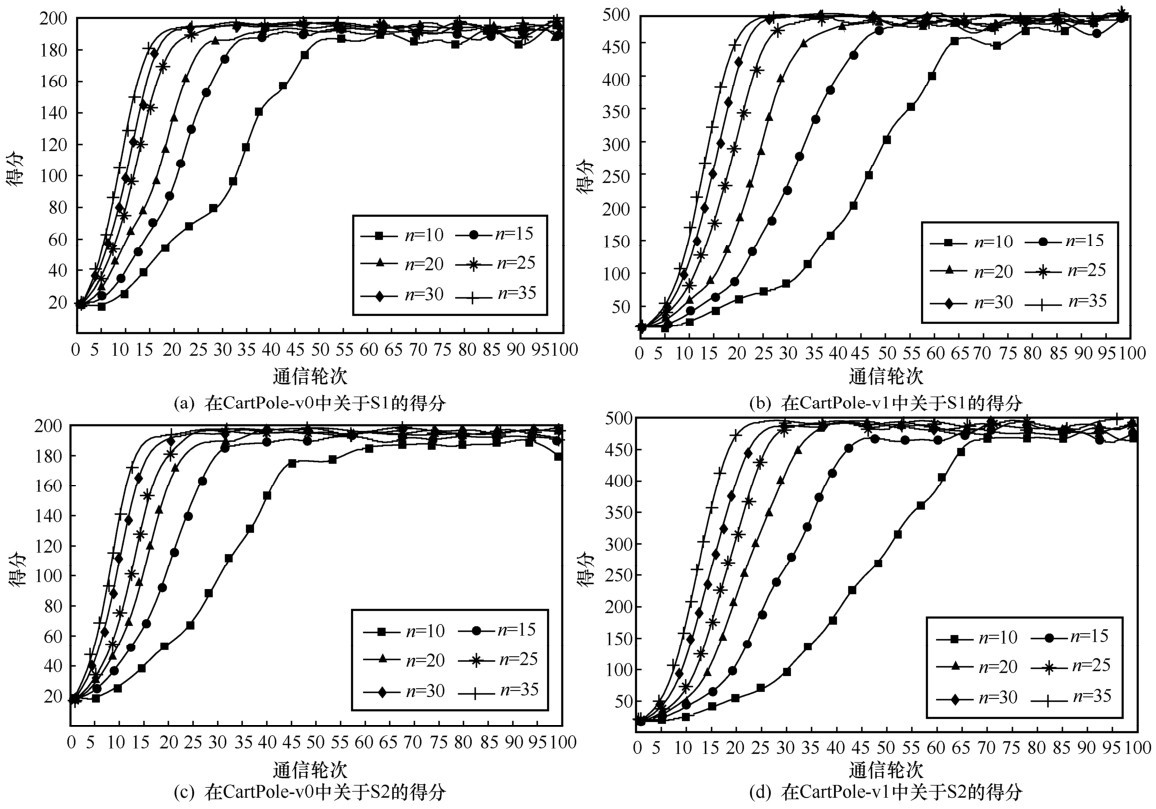

图6
搭载PPO智能体的GenFedRL的得分"
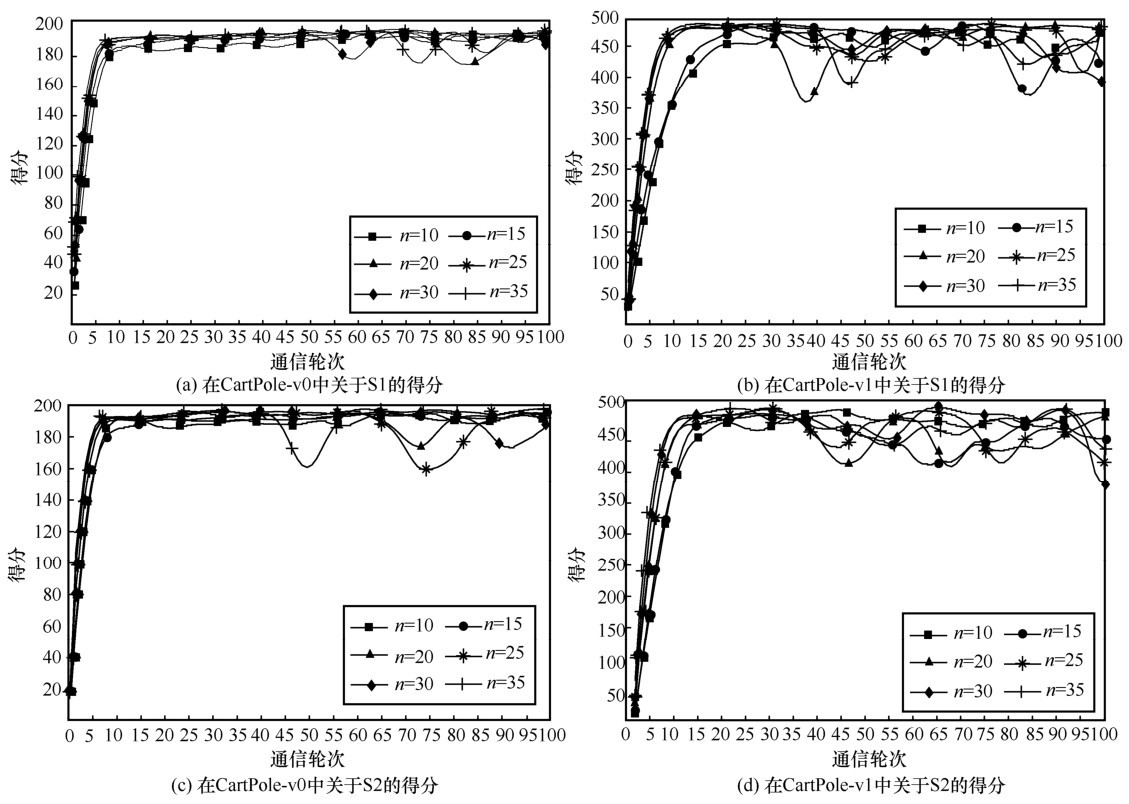

图7
搭载DDPG智能体的GenFedRL的得分"


图8
搭载SAC智能体的GenFedRL的得分"

表2
GenFedRL在CartPole-v0中首次达到对应基准所需通信轮次"
| 算法 | n=10 | n=15 | n=20 | n=25 | n=30 | n=35 |
| reinforce | 91 (—) | 73(68) | 45(44) | 36(47) | 42(31) | 27(33) |
| DQN | 57 (61) | 32 (—) | 99 (93) | 20 (23) | 99 (21) | —(16) |
| Actor Critic | 83 (90) | 40 (42) | 35 (33) | 24 (23) | 19 (19) | 17 (16) |
| PPO | 49 (10) | 19 (17) | 7 (8) | 10 (7) | 8 (7) | 6 (6) |
表3
GenFedRL在CartPole-v1中首次达到对应基准所需通信轮次"
| 算法 | n=10 | n=15 | n=20 | n=25 | n=30 | n=35 |
| reinforce | —(—) | 81 (84) | 69 (60) | 55 (49) | 50 (40) | 44 (28) |
| DQN | —(—) | 99 (—) | 69 (59) | 87 (81) | 57 (70) | 50 (45) |
| Actor Critic | 59 (61) | 40 (38) | 29 (29) | 23 (23) | 19 (20) | 17 (16) |
| PPO | 13 (10) | 11 (9) | 7 (7) | 6 (7) | 5 (6) | 5 (5) |
表4
GenFedRL在Pendulum-v1中首次达到对应基准所需通信轮次"
| 算法 | n=5 | n=10 | n=15 | n=20 | n=25 | n=30 | n=35 |
| DDPG | 26 (31) | 12 (12) | 12 (8) | 10 (9) | 6 (7) | 6 (7) | 6 (7) |
| SAC | 16 (17) | 10 (14) | 7 (9) | 6 (9) | 6 (16) | 5 (11) | 8 (15) |
| [1] | MCMAHAN H B , MOORE E , RAMAGE D ,et al. Communication-efficient learning of deep networks from decentralized data[J]. arXiv Preprint,arXiv:1602.05629, 2016. |
| [2] | SILVER D , SCHRITTWIESER J , SIMONYAN K ,et al. Mastering the game of GO without human knowledge[J]. Nature, 2017,550(7676): 354-359. |
| [3] | HESSEL M , SOYER H , ESPEHOLT L ,et al. Multi-task deep reinforcement learning with PopArt[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2019: 3796-3803. |
| [4] | ANDRYCHOWICZ O M , BAKER B , CHOCIEJ M ,et al. Learning dexterous in-hand manipulation[J]. International Journal of Robotics Research, 2020,39(1): 3-20. |
| [5] | HAO J Y , YANG T P , TANG H Y ,et al. Exploration in deep reinforcement learning:from single-agent to multiagent domain[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023:doi.org/10.1109/TNNLS.2023.3236361. |
| [6] | 杨强, 刘洋, 程勇 ,等. 联邦学习[M]. 北京: 电子工业出版社, 2020. |
| YANG Q , LIU Y , CHENG Y ,et al. Federated learning[M. Beijing: Publishing House of Electronics Industry, 2020. | |
| [7] | ESPEHOLT L , SOYER H , MUNOS R ,et al. IMPALA:scalable distributed deep-RL with importance weighted actor-learner architectures[C]// Proceedings of International Conference on Machine Learning. New York:ACM Press, 2018: 1407-1416. |
| [8] | KAPTUROWSKI S , OSTROVSKI G , QUAN J ,et al. Recurrent experience replay in distributed reinforcement learning[C]// Proceedings of International Conference on Learning Representations. [s.l.:Open Review, 2019: 1-19. |
| [9] | ESPEHOLT L , MARINIER R , STANCZYK P ,et al. SEED RL:scalable and efficient deep-RL with accelerated central inference[J]. arXiv Preprint,arXiv:1910.06591, 2019. |
| [10] | KRISHNAN S , LAM M , CHITLANGIA S ,et al. QuaRL:quantization for fast and environmentally sustainable reinforcement learning[J]. arXiv Preprint,arXiv:1910.01055, 2019. |
| [11] | SCHAUL T , QUAN J , ANTONOGLOU I ,et al. Prioritized experience replay[J]. arXiv Preprint,arXiv:1511.05952, 2015. |
| [12] | 王志勤, 江甲沫, 刘沛西 ,等. 6G 联邦边缘学习新范式:基于任务导向的资源管理策略[J]. 通信学报, 2022,43(6): 16-27. |
| WANG Z Q , JIANG J M , LIU P X ,et al. New design paradigm for federated edge learning towards 6G:task-oriented resource management strategies[J. Journal on Communications, 2022,43(6): 16-27. | |
| [13] | ZHOU Z , TIAN Y L , XIONG J B ,et al. Blockchain-enabled secure and trusted federated data sharing in IIoT[J]. IEEE Transactions on Industrial Informatics, 2023,19(5): 6669-6681. |
| [14] | 贺文晨, 郭少勇, 邱雪松 ,等. 基于 DRL 的联邦学习节点选择方法[J]. 通信学报, 2021,42(6): 62-71. |
| HE W C , GUO S Y , QIU X S ,et al. Node selection method in federated learning based on deep reinforcement learning[J. Journal on Communications, 2021,42(6): 62-71. | |
| [15] | MIAO Q , LIN H , WANG X ,et al. Federated deep reinforcement learning based secure data sharing for Internet of things[J]. Computer Networks, 2021,197:108327. |
| [16] | MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533. |
| [17] | TESAURO G . Temporal difference learning and TD-Gammon[J]. Communications of the ACM, 1995,38(3): 58-68. |
| [18] | NADIGER C , KUMAR A , ABDELHAK S . Federated reinforcement learning for fast personalization[C]// Proceedings of 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering. Piscataway:IEEE Press, 2019: 123-127. |
| [19] | LIU B Y , WANG L J , LIU M . Lifelong federated reinforcement learning:a learning architecture for navigation in cloud robotic systems[J]. IEEE Robotics and Automation Letters, 2019,4(4): 4555-4562. |
| [20] | MOWLA N I , TRAN N H , DOH I ,et al. AFRL:adaptive federated reinforcement learning for intelligent jamming defense in FANET[J]. Journal of Communications and Networks, 2020,22(3): 244-258. |
| [21] | WANG X F , WANG C Y , LI X H ,et al. Federated deep reinforcement learning for Internet of things with decentralized cooperative edge caching[J]. IEEE Internet of Things Journal, 2020,7(10): 9441-9455. |
| [22] | HASSELT H V , GUEZ A , SILVER D . Deep reinforcement learning with double Q-learning[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2016: 2094-2100. |
| [23] | WILLIAMS R J . Simple statistical gradient-following algorithms for connectionist reinforcement learning[J]. Machine Learning, 1992,8(3): 229-256. |
| [24] | SUTTON R S , MCALLESTER D , SINGH S ,et al. Policy gradient methods for reinforcement learning with function approximation[C]// Proceedings of the 12th International Conference on Neural Information Processing Systems. New York:ACM, 1999: 1057-1063. |
| [25] | KONDA V , TSITSIKLIS J . Actor-critic algorithms[J]. Advances in Neural Information Processing Systems, 1999,12: 1008-1014. |
| [26] | ZHAO G Q , XU J M , LIU A D ,et al. Research on proximal policy optimization algorithm based on N-step update[C]// Proceedings of International Conference on Communications,Information System and Computer Engineering. Piscataway:IEEE Press, 2021: 854-857. |
| [27] | SEYED M S M , BAGHI V , MIANDOAB E M ,et al. Duplicated replay buffer for asynchronous deep deterministic policy gradient[C]// Proceedings of the 26th International Computer Conference,Computer Society of Iran. Piscataway:IEEE Press, 2021: 1-6. |
| [28] | HAARNOJA T , ZHOU A , ABBEEL P ,et al. Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]// 2018 International Conference on Machine Learning. New York:ACM Press, 2018: 1861-1870. |
| [29] | LIM H K , KIM J B , HEO J S ,et al. Federated reinforcement learning for training control policies on multiple IoT devices[J]. Sensors, 2020,20(5): 1359. |
| [30] | YOO S , LEE W . Federated reinforcement learning based AANs with LEO satellites and UAVs[J]. Sensors, 2021,21(23): 8111. |
| [31] | HU Y Q , HUA Y , LIU W Y ,et al. Reward shaping based federated reinforcement learning[J]. IEEE Access, 2021,9: 67259-67267. |
| [32] | NG A Y , HARADA D , RUSSELL S J . Policy invariance under reward transformations:theory and application to reward shaping[C]// Proceedings of the 16th International Conference on Machine Learning. New York:ACM Press, 1999: 278-287. |
| [33] | KINGMA D P , BA J . Adam:a method for stochastic optimization[J]. arXiv Preprint,arXiv:1412.6980, 2014. |
| [34] | LE G T , MARJOU X , LEMLOUMA T ,et al. A multi-agent OpenAI gym environment for telecom providers cooperation[C]// Proceedings of the 24th Conference on Innovation in Clouds,Internet and Networks and Workshops. Piscataway:IEEE Press, 2021: 28-32. |
| [35] | BARTO A G , SUTTON R S , ANDERSON C W . Neuronlike adaptive elements that can solve difficult learning control problems[J]. IEEE Transactions on Systems,Man,and Cybernetics, 1983,SMC-13(5): 834-846. |
| [36] | MOHASSEL P , ZHANG Y P . SecureML:a system for scalable privacy-preserving machine learning[C]// Proceedings of IEEE Symposium on Security and Privacy. Piscataway:IEEE Press, 2017: 19-38. |
| [37] | ACAR A , AKSU H , ULUAGAC A S ,et al. A survey on homomorphic encryption schemes:theory and implementation[J]. ACM Computing Surveys, 2018,51(4): 1-35. |
| [38] | EL-YAHYAOUI A , ECH-CHERIF E K M D . A verifiable fully homomorphic encryption scheme for cloud computing security[J]. Technologies, 2019,7(1): 21. |
| [39] | DWORK C , MCSHERRY F , NISSIM K ,et al. Calibrating noise to sensitivity in private data analysis[C]// Proceedings of Third Theory of Cryptography Conference. Berlin:Springer, 2006: 265-284. |
| [40] | DWORK C , FELDMAN V , HARDT M ,et al. Preserving statistical validity in adaptive data analysis[C]// Proceedings of the 47th Annual ACM Symposium on Theory of Computing. New York:ACM Press, 2015: 117-126. |
| [1] | 马鑫迪, 李清华, 姜奇, 马卓, 高胜, 田有亮, 马建峰. 面向Non-IID数据的拜占庭鲁棒联邦学习[J]. 通信学报, 2023, 44(6): 138-153. |
| [2] | 田有亮, 吴柿红, 李沓, 王林冬, 周骅. 基于激励机制的联邦学习优化算法[J]. 通信学报, 2023, 44(5): 169-180. |
| [3] | 李元诚, 秦永泰. 基于深度强化学习的软件定义安全中台QoS实时优化算法[J]. 通信学报, 2023, 44(5): 181-192. |
| [4] | 张佳乐, 朱诚诚, 孙小兵, 陈兵. 基于GAN的联邦学习成员推理攻击与防御方法[J]. 通信学报, 2023, 44(5): 193-205. |
| [5] | 李开菊, 许强, 王豪. 冗余数据去除的联邦学习高效通信方法[J]. 通信学报, 2023, 44(5): 79-93. |
| [6] | 余晟兴, 陈泽凯, 陈钟, 刘西蒙. DAGUARD:联邦学习下的分布式后门攻击防御方案[J]. 通信学报, 2023, 44(5): 110-122. |
| [7] | 姜慧, 何天流, 刘敏, 孙胜, 王煜炜. 面向异构流式数据的高性能联邦持续学习算法[J]. 通信学报, 2023, 44(5): 123-136. |
| [8] | 许国良, 谭峰, 冉泳屹, 陈丰. 面向多波束卫星系统的波束跳变与覆盖控制联合优化算法[J]. 通信学报, 2023, 44(4): 78-86. |
| [9] | 余晟兴, 陈钟. 基于同态加密的高效安全联邦学习聚合框架[J]. 通信学报, 2023, 44(1): 14-28. |
| [10] | 汤凌韬, 王迪, 刘盛云. 面向非独立同分布数据的联邦学习数据增强方案[J]. 通信学报, 2023, 44(1): 164-176. |
| [11] | 沙宗轩, 霍如, 孙闯, 汪硕, 黄韬. 基于深度强化学习的转发效能感知流量调度算法[J]. 通信学报, 2022, 43(8): 30-40. |
| [12] | 范绍帅, 吴剑波, 田辉. 面向能量受限工业物联网设备的联邦学习资源管理[J]. 通信学报, 2022, 43(8): 65-77. |
| [13] | 张宇, 程旻. NDN中边缘计算与缓存的联合优化[J]. 通信学报, 2022, 43(8): 164-175. |
| [14] | 莫梓嘉, 高志鹏, 杨杨, 林怡静, 孙山, 赵晨. 面向车联网数据隐私保护的高效分布式模型共享策略[J]. 通信学报, 2022, 43(4): 83-94. |
| [15] | 张先超, 赵耀, 叶海军, 樊锐. 无线网络多用户干扰下智能发射功率控制算法[J]. 通信学报, 2022, 43(2): 15-21. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||