游戏智能中的 AI:从多角色博弈到平行博弈
1
2020
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
游戏智能中的 AI:从多角色博弈到平行博弈
1
2020
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
AlphaGo 的突破与兵棋推演的挑战
1
2017
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
AlphaGo 的突破与兵棋推演的挑战
1
2017
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
兵棋推演系统设计与建模研究
2
2011
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
... 基于规则的 AI(简称规则 AI)主要是结合博弈对抗环境的领域知识,构建基于专家经验知识的规则AI.这类规则AI主要以高水平玩家的经验知识为基础,对领域知识进行程序化,进而形成具有一定智能性的推演AI.近年,在国内的智能博弈比赛中,参赛团队还是普遍以规则 AI 为基础,对规则AI进行改良和设计进而参赛[3].在2020年的智能兵棋比赛中,大部分团队及基准 AI 还是以规则AI为主流.当然,单纯基于知识的规则也存在各种局限,如智能性普遍较低、通用性较差等.但是,规则 AI 的好处就是便于分析设计,可以快速构建具有一定智能性的博弈对抗AI环境.规则AI可以作为对手模型进行构建,让强化学习AI与规则AI进行对抗,初步验证强化学习的智能性.同时,通过规则驱动结合强化学习的智能 AI 构建,也是当前国内智能兵棋的研究热点,利用高水平玩家快速构建基于规则的AI,让agent快速学习有效动作并存入模型中,方便神经网络直接提取有效经验,进而实现强化学习的快速收敛,加快学习进程.国内也有研究尝试利用知识驱动结合数据驱动,通过知识牵引 AI的整体策略,以数据驱动AI的具体动作,设计出基于知识牵引与数据驱动的兵棋AI框架[18]. ...
兵棋推演系统设计与建模研究
2
2011
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
... 基于规则的 AI(简称规则 AI)主要是结合博弈对抗环境的领域知识,构建基于专家经验知识的规则AI.这类规则AI主要以高水平玩家的经验知识为基础,对领域知识进行程序化,进而形成具有一定智能性的推演AI.近年,在国内的智能博弈比赛中,参赛团队还是普遍以规则 AI 为基础,对规则AI进行改良和设计进而参赛[3].在2020年的智能兵棋比赛中,大部分团队及基准 AI 还是以规则AI为主流.当然,单纯基于知识的规则也存在各种局限,如智能性普遍较低、通用性较差等.但是,规则 AI 的好处就是便于分析设计,可以快速构建具有一定智能性的博弈对抗AI环境.规则AI可以作为对手模型进行构建,让强化学习AI与规则AI进行对抗,初步验证强化学习的智能性.同时,通过规则驱动结合强化学习的智能 AI 构建,也是当前国内智能兵棋的研究热点,利用高水平玩家快速构建基于规则的AI,让agent快速学习有效动作并存入模型中,方便神经网络直接提取有效经验,进而实现强化学习的快速收敛,加快学习进程.国内也有研究尝试利用知识驱动结合数据驱动,通过知识牵引 AI的整体策略,以数据驱动AI的具体动作,设计出基于知识牵引与数据驱动的兵棋AI框架[18]. ...
基于规则的计算机兵棋系统技术研究
1
2010
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
基于规则的计算机兵棋系统技术研究
1
2010
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
智能决策问题探讨——从游戏博弈到作战指挥,距离还有多远
2
2020
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
智能决策问题探讨——从游戏博弈到作战指挥,距离还有多远
2
2020
... 以2016年AlphaGo的成功研发为起点,对智能博弈领域的研究获得突飞猛进的进展.2016年之前,对兵棋推演的研究还主要集中在基于事件驱动、规则驱动等比较固定的思路.到2016年,受AlphaGo的启发,研究人员发现智能兵棋、智能作战推演的实现并没有想象得那么遥远.随着机器学习技术的发展,很多玩家十分憧憬游戏中有 AI 加入从而改善自己的游戏体验[1].同时,在智能作战推演领域,不断发展的机器学习游戏 AI 技术也为智能作战推演的发展提供了可行思路[2].传统作战推演AI主要以基于规则的AI和分层状态机的AI决策为主,同时以基于事件驱动的机制进行推演[3-4].然而,随着近些年国内外在各种棋类、策略类游戏领域取得新突破,智能作战推演的发展迎来了新的机遇[5]. ...
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
Supervised learning achieves human-level performance in MOBA games:a case study of honor of kings
5
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
... [6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
... 在现有策略对抗游戏中利用深度学习技术结合强化学习来实现游戏AI已成为主流研究方向[52].其主要思路为在游戏对抗过程中利用图像特征的卷积提取技术.如在《觉悟AI》中,图像特征的提取采取了分层的思想,在主视野和小地图中,对不同种类的要素进行提取并合并到一个层中,最终每层都提取到一类关键属性节点信息,形成“英雄”“野怪”“小兵”位置矩阵[6].最终将多尺度特征的信息融合形成全局态势特征信息,这一工作同样应用在AlphaStar中.对于作战推演来说,态势理解一直是研究的难点,那么考虑利用深度学习技术来实现态势图像特征的提取,进而最终输出态势图的关键信息将是解决方案之一.此外,笔者所在团队也尝试利用深度学习技术对态势信息进行卷积提取,然后将提取信息与语义模型结合,生成当前态势的直观文本语义.而在前端利用强化学习进行实体单元控制,这样就可以将强化学习、深度学习、自然语言处理融合,在推演过程中实时生成方便人类理解的智能决策文本语义信息,这一工作对于实现推演系统中的人机融合具有积极意义. ...
... 智能博弈的 AI 建模普遍存在适应性不高的问题,有部分研究人员开发的 AI 是针对某个固定想定开发的,导致更换博弈想定后AI性能大幅下降.考虑到大部分数据或任务是存在相关性的,通过迁移学习可以将已经学到的模型参数通过某种方式分享给新模型,从而加快优化模型效率.中国科学院自动化研究所的研究人员引入了课程迁移学习,将强化学习模型扩展到各种不同博弈场景,并且提升了采样效率[81].DeepMind 在 AlphaZero 中使用同样的算法设置、网络架构和超参数,得到了一种适用于围棋、国际象棋和将棋的通用算法,并战胜了基于其他技术的棋类游戏AI[82].《觉悟AI》引入了课程学习方法,将训练至符合要求的参数迁移至同一个神经网络再次训练、迭代、修正以提高效率,使《觉悟AI》模型能熟练掌握40多个“英雄”[6,36].在作战推演中,更需要这种适用性强的通用 AI 算法,不需要在更换作战想定后重新训练模型,也只有这样才可以更加适应实时性要求极高的作战场景. ...
Deep multi-agent reinforcement learning with discrete-continuous hybrid action spaces
1
2019
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
SCC:an efficient deep reinforcement learning agent mastering the game of StarCraft II
2
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
战略战役兵棋演习系统兵力聚合问题研究
1
2017
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
战略战役兵棋演习系统兵力聚合问题研究
1
2017
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
人机对抗智能技术
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
人机对抗智能技术
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
Tactical intention recognition in wargame
2
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
Research and implementation of intelligent decision based on a priori knowledge and DQN algorithms in wargame environment
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于博弈对抗的空战智能决策关键技术
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于博弈对抗的空战智能决策关键技术
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于多智能体深度强化学习的空战博弈对抗策略训练模型
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于多智能体深度强化学习的空战博弈对抗策略训练模型
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
一种基于深度强化学习的无监督智能作战推演系统:CN109636699A
1
2019
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
一种基于深度强化学习的无监督智能作战推演系统:CN109636699A
1
2019
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于近端策略优化的作战实体博弈对抗算法
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于近端策略优化的作战实体博弈对抗算法
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
Actor-Critic 框架下的多智能体决策方法及其在兵棋上的应用
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
Actor-Critic 框架下的多智能体决策方法及其在兵棋上的应用
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
知识牵引与数据驱动的兵棋AI设计及关键技术
2
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
... 基于规则的 AI(简称规则 AI)主要是结合博弈对抗环境的领域知识,构建基于专家经验知识的规则AI.这类规则AI主要以高水平玩家的经验知识为基础,对领域知识进行程序化,进而形成具有一定智能性的推演AI.近年,在国内的智能博弈比赛中,参赛团队还是普遍以规则 AI 为基础,对规则AI进行改良和设计进而参赛[3].在2020年的智能兵棋比赛中,大部分团队及基准 AI 还是以规则AI为主流.当然,单纯基于知识的规则也存在各种局限,如智能性普遍较低、通用性较差等.但是,规则 AI 的好处就是便于分析设计,可以快速构建具有一定智能性的博弈对抗AI环境.规则AI可以作为对手模型进行构建,让强化学习AI与规则AI进行对抗,初步验证强化学习的智能性.同时,通过规则驱动结合强化学习的智能 AI 构建,也是当前国内智能兵棋的研究热点,利用高水平玩家快速构建基于规则的AI,让agent快速学习有效动作并存入模型中,方便神经网络直接提取有效经验,进而实现强化学习的快速收敛,加快学习进程.国内也有研究尝试利用知识驱动结合数据驱动,通过知识牵引 AI的整体策略,以数据驱动AI的具体动作,设计出基于知识牵引与数据驱动的兵棋AI框架[18]. ...
知识牵引与数据驱动的兵棋AI设计及关键技术
2
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
... 基于规则的 AI(简称规则 AI)主要是结合博弈对抗环境的领域知识,构建基于专家经验知识的规则AI.这类规则AI主要以高水平玩家的经验知识为基础,对领域知识进行程序化,进而形成具有一定智能性的推演AI.近年,在国内的智能博弈比赛中,参赛团队还是普遍以规则 AI 为基础,对规则AI进行改良和设计进而参赛[3].在2020年的智能兵棋比赛中,大部分团队及基准 AI 还是以规则AI为主流.当然,单纯基于知识的规则也存在各种局限,如智能性普遍较低、通用性较差等.但是,规则 AI 的好处就是便于分析设计,可以快速构建具有一定智能性的博弈对抗AI环境.规则AI可以作为对手模型进行构建,让强化学习AI与规则AI进行对抗,初步验证强化学习的智能性.同时,通过规则驱动结合强化学习的智能 AI 构建,也是当前国内智能兵棋的研究热点,利用高水平玩家快速构建基于规则的AI,让agent快速学习有效动作并存入模型中,方便神经网络直接提取有效经验,进而实现强化学习的快速收敛,加快学习进程.国内也有研究尝试利用知识驱动结合数据驱动,通过知识牵引 AI的整体策略,以数据驱动AI的具体动作,设计出基于知识牵引与数据驱动的兵棋AI框架[18]. ...
基于遗传模糊系统的兵棋推演关键点推理方法
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于遗传模糊系统的兵棋推演关键点推理方法
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
军事智能博弈对抗系统设计框架研究
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
军事智能博弈对抗系统设计框架研究
1
2020
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于深度强化学习的多机协同空战方法研究
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于深度强化学习的多机协同空战方法研究
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于卷积神经网络的陆战兵棋战术机动策略学习
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
基于卷积神经网络的陆战兵棋战术机动策略学习
1
2021
... 国内游戏 AI 领域取得了标志性的进步.腾讯《王者荣耀》的《觉悟AI》作为一款策略对抗游戏取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队[6].网易伏羲人工智能实验室在很多游戏环境都进行了强化学习游戏 AI 的尝试[6],如《潮人篮球》《逆水寒》《倩女幽魂》.超参数科技(深圳)有限公司打造了游戏AI平台“Delta”,集成机器学习、强化学习、大系统工程等技术,通过将AI与游戏场景结合,提供人工智能解决方案[7].启元AI“星际指挥官”在与职业选手的对抗中也取得了胜利[8].北京字节跳动科技有限公司也收购了上海沐瞳科技有限公司和北京深极智能科技有限公司,准备在游戏AI领域发力.除了游戏AI领域,国内在智能兵棋推演领域也发展迅速.国防大学兵棋团队研制了战略、战役级兵棋系统,并分析了将人工智能特别是深度学习技术运用在兵棋系统上需要解决的问题[9].中国科学院自动化研究所在2017年首次推出《CASIA-先知1.0》兵棋推演人机对抗AI[10],并在近期上线“庙算·智胜”即时策略人机对抗平台[11].此外,由中国指挥与控制学会和北京华戍防务技术有限公司共同推出的专业级兵棋《智戎·未来指挥官》在第三届、第四届全国兵棋推演大赛中成为官方指定平台.中国电科认知与智能技术重点实验室开发了MaCA智能博弈平台,也成功以此平台为基础举办了相关智能博弈赛事.南京大学、中国人民解放军陆军工程大学、中国电子科技集团公司第五十二研究所等相关单位也开发研制了具有自主知识产权的兵棋推演系统[12,13,14,15].2020年,国内举办了4次大型智能兵棋推演比赛,这些比赛对于国内智能博弈推演的发展、作战推演领域的推进具有积极影响.游戏 AI 和智能兵棋的发展也逐渐获得了国内学者的关注,胡晓峰等人[5]提出了从游戏博弈到作战指挥的决策差异,分析了将现有主流人工智能技术应用到战争对抗过程中的局限性.南京理工大学张振、李琛等人利用PPO、A3C算法实现了简易环境下的智能兵棋推演,取得了较好的智能性[16-17].中国人民解放军陆军工程大学程恺、张可等人利用知识驱动及遗传模糊算法等提高了兵棋推演的智能性[18-19].中国人民解放军海军研究院和中国科学院自动化研究所分别设计和开发了智能博弈对抗系统,对于国内智能兵棋推演系统的开发具有重要参考价值[20].中国人民解放军国防科技大学刘忠教授团队利用深度强化学习技术在《墨子•未来指挥官系统》中进行了一系列智能博弈的研究,取得了突出的成果[21].中国科学院大学人工智能学院倪晚成团队提出一种基于深度神经网络从复盘数据中学习战术机动策略模型的方法,对于智能博弈中的态势认知研究具有重要参考价值[22]. ...
Deep reinforcement learning:a survey
1
2020
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
Human-level control through deep reinforcement learning
3
2015
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
... DeepMind在2015年第一次利用DQN(deep Q network)算法在Atari游戏环境中实现了高水平的智能AI,该AI综合评定达到了人类专业玩家的水平[24].这也使得DQN算法成为强化学习的经典算法.DQN算法通过神经网络拟合Q值,通过训练不断调整神经网络中的权重,获得精准的预测 Q值,并通过最大的Q值进行动作选择.DQN算法有效地解决了Q-learning算法中存储的Q值有限的问题,可以解决大量的离散动作估值问题,并且DQN算法主要使用经验回放机制(experience replay),即将每次和环境交互得到的奖励与状态更新情况都保存起来,用于后面的Q值更新,从而明显增强了算法的适应性.DQN由于对价值函数做了近似表示,因此强化学习算法有了解决大规模强化学习问题的能力.但是 DQN 算法主要被应用于离散的动作空间,且DQN算法的训练不一定能保证Q值网络收敛,这就会导致在状态比较复杂的情况下,训练出的模型效果很差.在 DQN 算法的基础上,衍生出了一系列新的改进 DQN 算法,如 DDQN (double DQN )算法[51]、优先级经验回放 DQN (prioritized experience replay DQN)算法[52]、竞争构架Q网络(dueling DQN)算法[53]等.这些算法主要是在改进Q网络过拟合、改进经验回放中的采样机制、改进目标Q值计算等方面提升传统DQN算法网络的性能.总体来说,DQN系列强化学习算法都属于基于值函数的强化学习算法类型.基于值函数的强化学习算法主要存在 3点不足:对连续动作的处理能力不足、对受限状态下的问题处理能力不足、无法解决随机策略问题.由于这些原因,基于值函数的强化学习方法不能适用所有的场景,因此需要新的方法解决上述问题,例如基于策略的强化学习方法. ...
Mastering the game of Go with deep neural networks and tree search
4
2016
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 对于动作空间,还需要考虑其是离散的还是连续的,Atari和围棋这类游戏动作都是离散动作空间[25,39-40],《星际争霸》《CMANO》《墨子·未来指挥官系统》这类游戏主要是连续动作空间[38].对于离散动作,可以考虑基于值函数的强化学习进行训练,而对于连续动作,可以考虑利用基于策略函数的强化学习进行训练.同时,离散动作和连续动作也可以互相转化.国内某兵棋推演平台由原先的回合制改为时间连续推演,即把回合制转化为固定的时间表达.同时对于连续动作,也可以在固定节点提取对应的动作,然后将其转化为离散动作. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
... 统计前向规划算法使用仿真模型(也称为前向模型)自适应地搜索有效的动作序列,此类算法提供了一种简单通用的方法,为各种游戏提供快速自适应的AI控制.常见的经典模型为MCTS算法, MCTS算法最重要的优点是不需要领域特定知识,可以在不了解游戏规则的情况下应用,这使得它很容易适用于任何可以使用树进行建模的领域.像Go[25]这样的游戏,分支因子明显具有高数量级特征,而有用的启发式又很难形成,这类问题就需要使用MCTS算法解决[80].尽管 MCTS 算法在大范围的博弈中提供了更强的决策能力,但将其应用在作战推演领域仍存在很多挑战和瓶颈.在作战推演领域,当需要搜索的图的分支因子和深度被限定,作战推演非常耗费CPU、GPU资源时,MCTS算法是否仍然是指导作战推演的最佳方法是一个有待研究的问题. ...
Mastering the game of Go without human knowledge
1
2017
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
Grandmaster level in StarCraft II using multi-agent reinforcement learning
2
2019
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 在多个智能博弈对抗游戏中普遍存在一个小地图,用来辅助玩家快速了解整体态势.AlphaStar利用 ResNet 在小地图中进行特征提取,获得对抗博弈中的关键属性信息,最终形成一个离散的单元特征图.AlphaStar正是通过小地图+单位列表+标量信息(资源信息)汇总输出各种智能决策给出的执行方案.在实际作战推演中,也需要考虑针对某个战场的全局地图信息,指挥员可能关注某个局部作战场景,同时也应该考虑全局的作战信息的获取[27].因此,在作战推演中智能决策 AI 的训练也需要设计小地图机制,来辅助深度强化学习智能AI进行训练. ...
Dota 2 with large scale deep reinforcement learning
1
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
Superhuman AI for multiplayer poker
3
2019
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 战争迷雾主要是指在博弈对抗过程中存在信息的不完全情况,我方并不了解未探索的区域实际的态势信息.围棋、国际象棋这类博弈对抗游戏中不存在这类问题.但是在《星际争霸》《Dota 2》《王者荣耀》以及《CMANO》等RTS游戏中设计了这一机制.实际的作战推演过程中同样也存在此类问题,但是情况更加复杂.在实际作战推演中,可以考虑利用不完全信息博弈解决这个问题,已有学者利用不完全信息博弈解决了德州扑克中的不完全信息问题[29],但是在实际作战推演中这一问题还需要进一步探讨研究. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
Mastering Atari,Go,chess and shogi by planning with a learned model
3
2020
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 博弈对抗的胜利是一局游戏结束的标志.而不同游戏中的胜利条件类型也不同,围棋、国际象棋这些棋类博弈对抗过程中有清晰明确的获胜条件[30].而 Atari 这类游戏[40]只需要获得足够的分数即可获得胜利.对于《王者荣耀》这类推塔游戏,不管过程如何,只要最终攻破敌方水晶就可以获取胜利.这些胜利条件使得基于深度强化学习技术的游戏AI开发相对容易,在回报值设置中给予最终奖励更高的回报值,总归能训练出较好的 AI 智能.然而对于策略对抗游戏,甚至实际作战推演来说,获胜条件更加复杂,目标更多.比如,有时可能需要考虑在我方损失最低的情况下实现作战目标,而有时则需要不计代价地快速实现作战目标,这些复杂多元的获胜条件设置将使得强化学习的回报值设置不能是简单地根据专家经验进行赋值,而需要根据真实演习数据构建奖赏函数,通过逆强化学习技术满足复杂多变的作战场景中不同阶段、不同目标的作战要求. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
What impact do VR controllers have on the traditional strategy game genre
1
2019
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
Reinforcing deterrence on NATO’s eastern flank:wargaming the defense of the baltics
1
2016
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
Using convolution neural networks to develop robust combat behaviors through reinforcement learning
1
2021
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
美俄人工智能军事应用发展分析
2
2020
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 动作空间是指在策略对抗游戏中玩家控制算子或游戏单元可以进行的所有动作的集合.对于围棋来说,动作空间为361个,是棋盘上所有可以落子的点.对于《王者荣耀》和《Dota》这类游戏来说,动作空间主要是玩家控制一个“英雄”进行的一系列操作,玩家平均水平是每秒可以进行一个动作,但是需要结合走位、释放技能、查看资源信息等操作.例如《觉悟AI》的玩家有几十个动作选项,包括24个方向的移动按钮和一些释放位置/方向的技能按钮[34].因此每局多人在线战术竞技(multiplayer online battle arena,MOBA)游戏的动作空间可以达到1060 000+.假设游戏时长为45 min,每秒30帧,共计81 000帧,AI每4帧进行一次操作,共计20 250次操作,这是游戏长度.任何时刻每个“英雄”可能的操作数是170 000,但考虑到其中大部分是不可执行的(例如使用一个尚处于冷却状态的技能),平均的可执行动作数约为1 000,即动作空间[37].因此,操作序列空间约等于1 00020 250= 1060 750.而对于《星际争霸》这类实时策略对抗游戏来说,因为需要控制大量的作战单元和建筑单元,动作空间可以达到1052 000[38].而对于《CMANO》和《墨子·未来指挥官系统》这类更加贴近军事作战推演的游戏来说,需要对每个作战单元进行大量精细的控制.在作战推演中,每个作战单元实际都包括大量的具体执行动作,以作战飞机为例,应包括飞行航向、飞行高度、飞行速度、自动开火距离、导弹齐射数量等.因此,实际作战推演需要考虑的动作空间可以达到10100 000+.可以看出,对于作战推演来说,庞大的动作空间一直是游戏 AI 迈进实际作战推演的门槛.现有的解决思路主要是考虑利用宏观AI训练战略决策,根据战略决策构建一系列绑定的宏函数,进行动作脚本设计.这样的好处是有效降低了动作空间设计的复杂度,同时也方便高效训练,但是实际问题是训练出来的 AI 总体缺乏灵活性,过于僵化. ...
美俄人工智能军事应用发展分析
2
2020
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
... 动作空间是指在策略对抗游戏中玩家控制算子或游戏单元可以进行的所有动作的集合.对于围棋来说,动作空间为361个,是棋盘上所有可以落子的点.对于《王者荣耀》和《Dota》这类游戏来说,动作空间主要是玩家控制一个“英雄”进行的一系列操作,玩家平均水平是每秒可以进行一个动作,但是需要结合走位、释放技能、查看资源信息等操作.例如《觉悟AI》的玩家有几十个动作选项,包括24个方向的移动按钮和一些释放位置/方向的技能按钮[34].因此每局多人在线战术竞技(multiplayer online battle arena,MOBA)游戏的动作空间可以达到1060 000+.假设游戏时长为45 min,每秒30帧,共计81 000帧,AI每4帧进行一次操作,共计20 250次操作,这是游戏长度.任何时刻每个“英雄”可能的操作数是170 000,但考虑到其中大部分是不可执行的(例如使用一个尚处于冷却状态的技能),平均的可执行动作数约为1 000,即动作空间[37].因此,操作序列空间约等于1 00020 250= 1060 750.而对于《星际争霸》这类实时策略对抗游戏来说,因为需要控制大量的作战单元和建筑单元,动作空间可以达到1052 000[38].而对于《CMANO》和《墨子·未来指挥官系统》这类更加贴近军事作战推演的游戏来说,需要对每个作战单元进行大量精细的控制.在作战推演中,每个作战单元实际都包括大量的具体执行动作,以作战飞机为例,应包括飞行航向、飞行高度、飞行速度、自动开火距离、导弹齐射数量等.因此,实际作战推演需要考虑的动作空间可以达到10100 000+.可以看出,对于作战推演来说,庞大的动作空间一直是游戏 AI 迈进实际作战推演的门槛.现有的解决思路主要是考虑利用宏观AI训练战略决策,根据战略决策构建一系列绑定的宏函数,进行动作脚本设计.这样的好处是有效降低了动作空间设计的复杂度,同时也方便高效训练,但是实际问题是训练出来的 AI 总体缺乏灵活性,过于僵化. ...
An experiment in tactical wargaming with platforms enabled by artificial intelligence
1
2020
... 国外游戏 AI 领域则取得了一系列突出成果,尤其是深度强化学习技术的不断发展,游戏 AI 开始称霸各类型的游戏[23].2015年DeepMind团队发表了深度Q网络的文章,认为深度强化学习可以实现人类水平的控制[24].2017年,DeepMind团队根据深度学习和策略搜索的方法推出了AlphaGo[25],击败了围棋世界冠军李世石.此后,基于深度强化学习的 AlphaGo Zero[26]在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo.2019年, DeepMind 团队基于多智能体(agent)深度强化学习推出的AlphaStar[27]在《星际争霸II》游戏中达到了人类大师级的水平,并且在《星际争霸II》的官方排名中超越了 99.8%的人类玩家.《Dota 2》AI“OpenAI Five”在电竞游戏中击败世界冠军[28], Pluribus 在 6 人无限制德州扑克中击败人类职业选手[29].同时DeepMind推出的MuZero在没有传授棋类运行规则的情况下,通过自我观察掌握围棋、国际象棋、将棋和雅达利(Atari)游戏[30].与军事推演直接相关的《CMANO》和《战争游戏:红龙》(Wargame:Red Dragon),同样也结合了最新的机器学习技术提升了其智能性[31].美国兰德公司也对兵棋推演的应用进行相关研究,利用兵棋推演假设分析了俄罗斯和北大西洋公约组织之间的对抗结果,并利用智能兵棋推演去发现新的战术[32].兰德研究员也提出将兵棋作为美国军事人员学习战术战法的工具[33].美国海军研究院尝试使用深度强化学习技术开发能够在多种单元和地形类型的简单场景中学习最佳行为的人工智能代理,并将其应用到军事训练及军事演习[34-35]. ...
Mastering complex control in MOBA games with deep reinforcement learning
3
2020
... 状态空间是作战推演中的每个作战实体的位置坐标、所处环境、所处状态等要素的表现,是深度强化学习进行训练的基础.在围棋中,状态空间就是棋盘上每个点是否有棋子.在《觉悟AI》中,状态空间是每一帧、每个单位可能有的状态,如生命值、级别、金币[36,37,38,39].在《墨子·未来指挥官系统》中,状态空间主要是每个作战单元实体的状态信息,是由想定中敌我双方所有的作战单元信息汇聚形成的.本节尤其要明确状态空间和可观察空间是可区分的,可观察空间主要是每个 agent 可以观察到的状态信息,是整个状态空间的一部分.作战推演中的状态空间将更加复杂,具有更多的作战单位和单位状态.针对敌我双方的不同作战单位、不同单位属性、不同环境属性等定义作战推演的状态空间属性.例如敌我双方坦克单元应包括坐标、速度、朝向、载弹量、攻击武器、规模等.陆战环境应包括周围道路信息、城镇居民地、夺控点等. ...
... 博弈对抗过程中最核心的环节是设置回报值,合理有效的回报值可以保证高效地训练出高水平AI.对于《星际争霸》《王者荣耀》等游戏,可以按照固定的条件设置明确的回报值,例如将取得最终胜利设置为固定的回报值.但是一局游戏的时间有时较长,在整局对抗过程中,如果只有最终的回报值将导致训练非常低效.这就是作战推演中遇到的一个难题,即回报值稀疏问题.为了解决这个难题,现有的解决方案都是在对抗过程中设置许多细节条件,如获得回报值或损失回报值的具体行为.比如在“庙算·智胜”平台中的博弈对抗,可以设置坦克击毁对手、占领夺控点即可获得回报值,如果被打击、失去夺控点等则会损失回报值,甚至为了加快收敛防止算子长期不能达到有效地点,会在每步(step)都损失微小的回报值.《觉悟AI》也同样设置了详细的奖赏表[36],从资源、KDA(杀人率(kill,K),死亡率(death,D),支援率(assista, A))、打击、推进、输赢 5 个维度设置了非常详细的具体动作回报值.这样就可以有效解决回报值稀疏的问题.但是,对于复杂的作战推演来说,设计回报函数可能还需要更多的细节.因为作战情况将更加复杂多样,需要利用逆强化学习[41-42],通过以往的作战数据反向构建奖赏函数. ...
... 智能博弈的 AI 建模普遍存在适应性不高的问题,有部分研究人员开发的 AI 是针对某个固定想定开发的,导致更换博弈想定后AI性能大幅下降.考虑到大部分数据或任务是存在相关性的,通过迁移学习可以将已经学到的模型参数通过某种方式分享给新模型,从而加快优化模型效率.中国科学院自动化研究所的研究人员引入了课程迁移学习,将强化学习模型扩展到各种不同博弈场景,并且提升了采样效率[81].DeepMind 在 AlphaZero 中使用同样的算法设置、网络架构和超参数,得到了一种适用于围棋、国际象棋和将棋的通用算法,并战胜了基于其他技术的棋类游戏AI[82].《觉悟AI》引入了课程学习方法,将训练至符合要求的参数迁移至同一个神经网络再次训练、迭代、修正以提高效率,使《觉悟AI》模型能熟练掌握40多个“英雄”[6,36].在作战推演中,更需要这种适用性强的通用 AI 算法,不需要在更换作战想定后重新训练模型,也只有这样才可以更加适应实时性要求极高的作战场景. ...
OpenAI gym
4
... 状态空间是作战推演中的每个作战实体的位置坐标、所处环境、所处状态等要素的表现,是深度强化学习进行训练的基础.在围棋中,状态空间就是棋盘上每个点是否有棋子.在《觉悟AI》中,状态空间是每一帧、每个单位可能有的状态,如生命值、级别、金币[36,37,38,39].在《墨子·未来指挥官系统》中,状态空间主要是每个作战单元实体的状态信息,是由想定中敌我双方所有的作战单元信息汇聚形成的.本节尤其要明确状态空间和可观察空间是可区分的,可观察空间主要是每个 agent 可以观察到的状态信息,是整个状态空间的一部分.作战推演中的状态空间将更加复杂,具有更多的作战单位和单位状态.针对敌我双方的不同作战单位、不同单位属性、不同环境属性等定义作战推演的状态空间属性.例如敌我双方坦克单元应包括坐标、速度、朝向、载弹量、攻击武器、规模等.陆战环境应包括周围道路信息、城镇居民地、夺控点等. ...
... 动作空间是指在策略对抗游戏中玩家控制算子或游戏单元可以进行的所有动作的集合.对于围棋来说,动作空间为361个,是棋盘上所有可以落子的点.对于《王者荣耀》和《Dota》这类游戏来说,动作空间主要是玩家控制一个“英雄”进行的一系列操作,玩家平均水平是每秒可以进行一个动作,但是需要结合走位、释放技能、查看资源信息等操作.例如《觉悟AI》的玩家有几十个动作选项,包括24个方向的移动按钮和一些释放位置/方向的技能按钮[34].因此每局多人在线战术竞技(multiplayer online battle arena,MOBA)游戏的动作空间可以达到1060 000+.假设游戏时长为45 min,每秒30帧,共计81 000帧,AI每4帧进行一次操作,共计20 250次操作,这是游戏长度.任何时刻每个“英雄”可能的操作数是170 000,但考虑到其中大部分是不可执行的(例如使用一个尚处于冷却状态的技能),平均的可执行动作数约为1 000,即动作空间[37].因此,操作序列空间约等于1 00020 250= 1060 750.而对于《星际争霸》这类实时策略对抗游戏来说,因为需要控制大量的作战单元和建筑单元,动作空间可以达到1052 000[38].而对于《CMANO》和《墨子·未来指挥官系统》这类更加贴近军事作战推演的游戏来说,需要对每个作战单元进行大量精细的控制.在作战推演中,每个作战单元实际都包括大量的具体执行动作,以作战飞机为例,应包括飞行航向、飞行高度、飞行速度、自动开火距离、导弹齐射数量等.因此,实际作战推演需要考虑的动作空间可以达到10100 000+.可以看出,对于作战推演来说,庞大的动作空间一直是游戏 AI 迈进实际作战推演的门槛.现有的解决思路主要是考虑利用宏观AI训练战略决策,根据战略决策构建一系列绑定的宏函数,进行动作脚本设计.这样的好处是有效降低了动作空间设计的复杂度,同时也方便高效训练,但是实际问题是训练出来的 AI 总体缺乏灵活性,过于僵化. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
... 在游戏博弈对抗过程中必然需要考虑多 agent建模,而在作战推演中利用多 agent 技术实现不同作战单元的协同合作也是博弈智能研究的重点之一.在这方面OpenAI和AlphaStar在多agent深度强化学习方面使用了不同的技术思路.OpenAI 使用的是分布异构的多agent建模思路,每一个agent都有一个相同的训练神经网络,但是没有全局控制网络[37,47].AlphaStar则是使用了一个集中的控制网络对不同的单元进行控制.还有一种思路是对于每一个agent,都建立属于各自的神经网络进行训练.第三种思路是最理想的,但是训练过程复杂,也难以适用于大规模的推演过程[43].对于实际作战推演来说,除了要考虑多 agent 建模方法,还需要让每个 agent 具有柔性加入的能力,在对抗过程中可以按照需要随时加入所需要的作战单元,而不需要每次加入作战单元后,再重新训练一遍网络.基于此考虑,让每一个 agent 具有自己独立的神经网络将是更好的选择. ...
Alphastar:an evolutionary computation perspective
2
2019
... 状态空间是作战推演中的每个作战实体的位置坐标、所处环境、所处状态等要素的表现,是深度强化学习进行训练的基础.在围棋中,状态空间就是棋盘上每个点是否有棋子.在《觉悟AI》中,状态空间是每一帧、每个单位可能有的状态,如生命值、级别、金币[36,37,38,39].在《墨子·未来指挥官系统》中,状态空间主要是每个作战单元实体的状态信息,是由想定中敌我双方所有的作战单元信息汇聚形成的.本节尤其要明确状态空间和可观察空间是可区分的,可观察空间主要是每个 agent 可以观察到的状态信息,是整个状态空间的一部分.作战推演中的状态空间将更加复杂,具有更多的作战单位和单位状态.针对敌我双方的不同作战单位、不同单位属性、不同环境属性等定义作战推演的状态空间属性.例如敌我双方坦克单元应包括坐标、速度、朝向、载弹量、攻击武器、规模等.陆战环境应包括周围道路信息、城镇居民地、夺控点等. ...
... 对于动作空间,还需要考虑其是离散的还是连续的,Atari和围棋这类游戏动作都是离散动作空间[25,39-40],《星际争霸》《CMANO》《墨子·未来指挥官系统》这类游戏主要是连续动作空间[38].对于离散动作,可以考虑基于值函数的强化学习进行训练,而对于连续动作,可以考虑利用基于策略函数的强化学习进行训练.同时,离散动作和连续动作也可以互相转化.国内某兵棋推演平台由原先的回合制改为时间连续推演,即把回合制转化为固定的时间表达.同时对于连续动作,也可以在固定节点提取对应的动作,然后将其转化为离散动作. ...
Towards playing full MOBA games with deep reinforcement learning
4
... 状态空间是作战推演中的每个作战实体的位置坐标、所处环境、所处状态等要素的表现,是深度强化学习进行训练的基础.在围棋中,状态空间就是棋盘上每个点是否有棋子.在《觉悟AI》中,状态空间是每一帧、每个单位可能有的状态,如生命值、级别、金币[36,37,38,39].在《墨子·未来指挥官系统》中,状态空间主要是每个作战单元实体的状态信息,是由想定中敌我双方所有的作战单元信息汇聚形成的.本节尤其要明确状态空间和可观察空间是可区分的,可观察空间主要是每个 agent 可以观察到的状态信息,是整个状态空间的一部分.作战推演中的状态空间将更加复杂,具有更多的作战单位和单位状态.针对敌我双方的不同作战单位、不同单位属性、不同环境属性等定义作战推演的状态空间属性.例如敌我双方坦克单元应包括坐标、速度、朝向、载弹量、攻击武器、规模等.陆战环境应包括周围道路信息、城镇居民地、夺控点等. ...
... 对于动作空间,还需要考虑其是离散的还是连续的,Atari和围棋这类游戏动作都是离散动作空间[25,39-40],《星际争霸》《CMANO》《墨子·未来指挥官系统》这类游戏主要是连续动作空间[38].对于离散动作,可以考虑基于值函数的强化学习进行训练,而对于连续动作,可以考虑利用基于策略函数的强化学习进行训练.同时,离散动作和连续动作也可以互相转化.国内某兵棋推演平台由原先的回合制改为时间连续推演,即把回合制转化为固定的时间表达.同时对于连续动作,也可以在固定节点提取对应的动作,然后将其转化为离散动作. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
Playing atari with deep reinforcement learning
3
... 对于动作空间,还需要考虑其是离散的还是连续的,Atari和围棋这类游戏动作都是离散动作空间[25,39-40],《星际争霸》《CMANO》《墨子·未来指挥官系统》这类游戏主要是连续动作空间[38].对于离散动作,可以考虑基于值函数的强化学习进行训练,而对于连续动作,可以考虑利用基于策略函数的强化学习进行训练.同时,离散动作和连续动作也可以互相转化.国内某兵棋推演平台由原先的回合制改为时间连续推演,即把回合制转化为固定的时间表达.同时对于连续动作,也可以在固定节点提取对应的动作,然后将其转化为离散动作. ...
... 博弈对抗的胜利是一局游戏结束的标志.而不同游戏中的胜利条件类型也不同,围棋、国际象棋这些棋类博弈对抗过程中有清晰明确的获胜条件[30].而 Atari 这类游戏[40]只需要获得足够的分数即可获得胜利.对于《王者荣耀》这类推塔游戏,不管过程如何,只要最终攻破敌方水晶就可以获取胜利.这些胜利条件使得基于深度强化学习技术的游戏AI开发相对容易,在回报值设置中给予最终奖励更高的回报值,总归能训练出较好的 AI 智能.然而对于策略对抗游戏,甚至实际作战推演来说,获胜条件更加复杂,目标更多.比如,有时可能需要考虑在我方损失最低的情况下实现作战目标,而有时则需要不计代价地快速实现作战目标,这些复杂多元的获胜条件设置将使得强化学习的回报值设置不能是简单地根据专家经验进行赋值,而需要根据真实演习数据构建奖赏函数,通过逆强化学习技术满足复杂多变的作战场景中不同阶段、不同目标的作战要求. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
基于逆强化学习的示教学习方法综述
2
2019
... 博弈对抗过程中最核心的环节是设置回报值,合理有效的回报值可以保证高效地训练出高水平AI.对于《星际争霸》《王者荣耀》等游戏,可以按照固定的条件设置明确的回报值,例如将取得最终胜利设置为固定的回报值.但是一局游戏的时间有时较长,在整局对抗过程中,如果只有最终的回报值将导致训练非常低效.这就是作战推演中遇到的一个难题,即回报值稀疏问题.为了解决这个难题,现有的解决方案都是在对抗过程中设置许多细节条件,如获得回报值或损失回报值的具体行为.比如在“庙算·智胜”平台中的博弈对抗,可以设置坦克击毁对手、占领夺控点即可获得回报值,如果被打击、失去夺控点等则会损失回报值,甚至为了加快收敛防止算子长期不能达到有效地点,会在每步(step)都损失微小的回报值.《觉悟AI》也同样设置了详细的奖赏表[36],从资源、KDA(杀人率(kill,K),死亡率(death,D),支援率(assista, A))、打击、推进、输赢 5 个维度设置了非常详细的具体动作回报值.这样就可以有效解决回报值稀疏的问题.但是,对于复杂的作战推演来说,设计回报函数可能还需要更多的细节.因为作战情况将更加复杂多样,需要利用逆强化学习[41-42],通过以往的作战数据反向构建奖赏函数. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
基于逆强化学习的示教学习方法综述
2
2019
... 博弈对抗过程中最核心的环节是设置回报值,合理有效的回报值可以保证高效地训练出高水平AI.对于《星际争霸》《王者荣耀》等游戏,可以按照固定的条件设置明确的回报值,例如将取得最终胜利设置为固定的回报值.但是一局游戏的时间有时较长,在整局对抗过程中,如果只有最终的回报值将导致训练非常低效.这就是作战推演中遇到的一个难题,即回报值稀疏问题.为了解决这个难题,现有的解决方案都是在对抗过程中设置许多细节条件,如获得回报值或损失回报值的具体行为.比如在“庙算·智胜”平台中的博弈对抗,可以设置坦克击毁对手、占领夺控点即可获得回报值,如果被打击、失去夺控点等则会损失回报值,甚至为了加快收敛防止算子长期不能达到有效地点,会在每步(step)都损失微小的回报值.《觉悟AI》也同样设置了详细的奖赏表[36],从资源、KDA(杀人率(kill,K),死亡率(death,D),支援率(assista, A))、打击、推进、输赢 5 个维度设置了非常详细的具体动作回报值.这样就可以有效解决回报值稀疏的问题.但是,对于复杂的作战推演来说,设计回报函数可能还需要更多的细节.因为作战情况将更加复杂多样,需要利用逆强化学习[41-42],通过以往的作战数据反向构建奖赏函数. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
基于深度强化学习的智能博弈对抗关键技术
2
2019
... 博弈对抗过程中最核心的环节是设置回报值,合理有效的回报值可以保证高效地训练出高水平AI.对于《星际争霸》《王者荣耀》等游戏,可以按照固定的条件设置明确的回报值,例如将取得最终胜利设置为固定的回报值.但是一局游戏的时间有时较长,在整局对抗过程中,如果只有最终的回报值将导致训练非常低效.这就是作战推演中遇到的一个难题,即回报值稀疏问题.为了解决这个难题,现有的解决方案都是在对抗过程中设置许多细节条件,如获得回报值或损失回报值的具体行为.比如在“庙算·智胜”平台中的博弈对抗,可以设置坦克击毁对手、占领夺控点即可获得回报值,如果被打击、失去夺控点等则会损失回报值,甚至为了加快收敛防止算子长期不能达到有效地点,会在每步(step)都损失微小的回报值.《觉悟AI》也同样设置了详细的奖赏表[36],从资源、KDA(杀人率(kill,K),死亡率(death,D),支援率(assista, A))、打击、推进、输赢 5 个维度设置了非常详细的具体动作回报值.这样就可以有效解决回报值稀疏的问题.但是,对于复杂的作战推演来说,设计回报函数可能还需要更多的细节.因为作战情况将更加复杂多样,需要利用逆强化学习[41-42],通过以往的作战数据反向构建奖赏函数. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
基于深度强化学习的智能博弈对抗关键技术
2
2019
... 博弈对抗过程中最核心的环节是设置回报值,合理有效的回报值可以保证高效地训练出高水平AI.对于《星际争霸》《王者荣耀》等游戏,可以按照固定的条件设置明确的回报值,例如将取得最终胜利设置为固定的回报值.但是一局游戏的时间有时较长,在整局对抗过程中,如果只有最终的回报值将导致训练非常低效.这就是作战推演中遇到的一个难题,即回报值稀疏问题.为了解决这个难题,现有的解决方案都是在对抗过程中设置许多细节条件,如获得回报值或损失回报值的具体行为.比如在“庙算·智胜”平台中的博弈对抗,可以设置坦克击毁对手、占领夺控点即可获得回报值,如果被打击、失去夺控点等则会损失回报值,甚至为了加快收敛防止算子长期不能达到有效地点,会在每步(step)都损失微小的回报值.《觉悟AI》也同样设置了详细的奖赏表[36],从资源、KDA(杀人率(kill,K),死亡率(death,D),支援率(assista, A))、打击、推进、输赢 5 个维度设置了非常详细的具体动作回报值.这样就可以有效解决回报值稀疏的问题.但是,对于复杂的作战推演来说,设计回报函数可能还需要更多的细节.因为作战情况将更加复杂多样,需要利用逆强化学习[41-42],通过以往的作战数据反向构建奖赏函数. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
Behind DeepMind’s AlphaStar AI that reached grandmaster level in StarCraft II
5
2020
... 这里需要对智能博弈中的观察信息与游戏状态空间进行区分,观察信息主要是指博弈的 agent在当前态势下可以获取的态势信息,是部分状态信息.由于在智能博弈对抗过程中会产生战争迷雾问题,因此需要在处理博弈信息时设置 agent 可以获取到的信息.《星际争霸》中观察信息主要有两层意思,一个层面是屏幕限制的区域更易于获取态势信息,因为玩家更直观的注意力在屏幕局域,部分注意力在小地图局域.为了更加符合实际, AlphaStar也按照这种限制对《星际争霸》中的注意力区域进行限制,从而更好地防止 AI 产生作弊行为.而这也是部分《星际争霸》AI被人诟病的原因,即没有限制机器的关注区域.另一个层面是对《星际争霸》中作战单元可观察区域内的态势信息进行获取,对于不能获取的态势信息则只能评估预测,而这一部分则涉及对手建模部分,主要利用部分可观察马尔可夫决策过程(partially observable Markov decision process,POMDP)[43],这一技术明显难于完全信息博弈.而对于围棋游戏来说,其中的态势信息是完全可获取的,属于完全信息博弈,态势信息即观察信息.并且围棋游戏属于回合制,相对于即时策略游戏,其有更加充分的获取态势信息的时间.因此,则可以利用蒙特卡洛树搜索(Monte Carlo tree search,MCTS)算法对所获取的围棋游戏中的观察信息进行详细分析,计算出所有可能的结果,进而得出最佳的方案策略.《Dota 2》中的观察信息是指所控制的某个“英雄”所获取的态势信息,其主要也是对主屏幕的态势信息和小地图的态势信息进行结合处理.《王者荣耀》也与此类似,其主要以小地图的宏观信息进行训练,然后以此为基础为战略方案提供支持,如游戏中的“英雄”是去野区发育还是去中路对抗.同时,对主屏幕态势信息进行特征提取,结合强化学习训练,可以得出战术层面的方案和建议,是去选择回塔防御还是进草丛躲避,或者推塔进攻.墨子兵棋推演系统和《CMANO》则更加接近真实作战推演,在作战信息获取各个方面都高度模拟了作战推演的场景,需要获取具体的对空雷达、对地雷达、导弹探测、舰艇雷达等信息后才能判断态势信息,这部分可观察信息非常复杂,需要结合各种情况才能发现部分目标,对于战争迷雾更加真实.因此,作战推演观察信息完全可以借鉴POMDP进行可观察信息建模,但还需要设置各种更加符合真实装备的作战情况,需要在环境中提前设置有针对性的条件. ...
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
... 在游戏博弈对抗过程中必然需要考虑多 agent建模,而在作战推演中利用多 agent 技术实现不同作战单元的协同合作也是博弈智能研究的重点之一.在这方面OpenAI和AlphaStar在多agent深度强化学习方面使用了不同的技术思路.OpenAI 使用的是分布异构的多agent建模思路,每一个agent都有一个相同的训练神经网络,但是没有全局控制网络[37,47].AlphaStar则是使用了一个集中的控制网络对不同的单元进行控制.还有一种思路是对于每一个agent,都建立属于各自的神经网络进行训练.第三种思路是最理想的,但是训练过程复杂,也难以适用于大规模的推演过程[43].对于实际作战推演来说,除了要考虑多 agent 建模方法,还需要让每个 agent 具有柔性加入的能力,在对抗过程中可以按照需要随时加入所需要的作战单元,而不需要每次加入作战单元后,再重新训练一遍网络.基于此考虑,让每一个 agent 具有自己独立的神经网络将是更好的选择. ...
... 在智能博弈领域,国际上的 Atari、AlphaGo、AlphaStar、OpenAI都取得了显著的成果,国内《觉悟AI》《墨子•未来指挥官系统》AI、《CASIA-先知1.0》也都取得了突破性的进展.这些工作主要以深度强化学习技术为主,但均搭配使用了其他相关的人工智能技术.总体来说,单纯地利用深度强化学习技术并不能很有效地实现智能AI,有必要在训练过程中结合其他技术提高 AI 性能.同时,如果想要实现特别突出的 AI 智能,那么将在训练的过程中花费大量的成本.AlphaStar的训练过程持续了10个月,使用了51 000个CPU.该工作同时有30个博士生参与,花费数百万美元的成本,才在游戏智能博弈领域实现了超过职业选手水平的AI智能[43]. ...
Monte-Carlo planning in large POMDPs
2
2010
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
... 强化学习的核心思想是不断地在环境中探索试错,并通过得到的回报值来判定当前动作的好坏,从而训练出高水平的智能AI[50].马尔可夫决策过程(Markov decision process,MDP)是强化学习的基础模型,环境通过状态与动作建模,描述agent与环境的交互过程.一般地,MDP可表示为四元组<S,A,R,T >[44]: ...
Does it matter how well I know what you’re thinking? Opponent modelling in an RTS game
1
2020
... 在博弈对抗过程中对手 AI 的建模也是至关重要的,不同水平的AI会导致博弈对抗的胜率不同,并且直接影响推演对抗的价值[39,40,41,42,43,44,45].如果对手 AI水平过低,就不能逼真地模拟假设对手,博弈过程和推演结果也价值不高.在 DeepMind 开发的AlphaGo和AlphaStar中,AI性能已经可以击败职业选手,通过训练后产生的决策方案已经可以给职业选手新的战术启发.国内《墨子•未来指挥官系统》也与国内高校合作,研发的基于深度强化学习的智能 AI 已经可以击败全国兵棋大赛十强选手.而在中国科学院自动化研究所开发的“庙算•智胜”上,积分排名前三名的均是AI选手,胜率均在80%以上[11].但是,现有对手建模主要还是聚焦在一对一的对手建模,很少学者研究多方博弈,而这在实际作战推演中更加需要.在实际作战对抗博弈过程中普遍会考虑多方博弈,如在《墨子•未来指挥官系统》的海峡大潮想定中,红方不仅面对蓝方,还有绿方,蓝方和绿方属于联盟关系.这就需要在对手建模中充分考虑这种复杂的博弈关系. ...
Measuring the size of large no-limit poker games
1
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
Navrep:unsupervised representations for reinforcement learning of robot navigation in dynamic human environments
1
2021
... 在游戏博弈对抗过程中必然需要考虑多 agent建模,而在作战推演中利用多 agent 技术实现不同作战单元的协同合作也是博弈智能研究的重点之一.在这方面OpenAI和AlphaStar在多agent深度强化学习方面使用了不同的技术思路.OpenAI 使用的是分布异构的多agent建模思路,每一个agent都有一个相同的训练神经网络,但是没有全局控制网络[37,47].AlphaStar则是使用了一个集中的控制网络对不同的单元进行控制.还有一种思路是对于每一个agent,都建立属于各自的神经网络进行训练.第三种思路是最理想的,但是训练过程复杂,也难以适用于大规模的推演过程[43].对于实际作战推演来说,除了要考虑多 agent 建模方法,还需要让每个 agent 具有柔性加入的能力,在对抗过程中可以按照需要随时加入所需要的作战单元,而不需要每次加入作战单元后,再重新训练一遍网络.基于此考虑,让每一个 agent 具有自己独立的神经网络将是更好的选择. ...
A survey of real-time strategy game AI research and competition in StarCraft
1
2013
... 在 1993 年就有人尝试用遗传算法训练神经网络,但是当时的计算机算力不足,导致这个方向并没有引起过多关注[66,67,68].随着深度强化学习技术的火热发展以及算力的显著提高,部分学者和机构又开始关注这一结合点.OpenAI在2017年尝试直接利用进化算法来代替强化学习技术,在 MuJoCo (multi-joint dynamics with contact)和Atari上取得了一定的效果.但是这一工作的前提是需要大量的CPU进行大规模训练,且实验环境比较简单[69].优步(Uber)AI在2017年尝试将基于种群的遗传算法和深度神经网络结合,利用进化策略而不是梯度策略来更新权重参数,取得的算法性能在一定程度上优于 A3C、DQN 算法[70].除了在优化网络参数方面进行结合,将进化策略和多 agent 强化学习结合也是一个有意义的方向.DeepMind就是在AlphaStar中利用了联盟赛制,在训练出的agent中不断优化筛选出更加优秀的 agent,从而不断演化,最终训练出超过职业选手水平的游戏AI[48]. ...
Combinatorial game complexity:an introduction with poset games
1
... 本节针对智能作战推演所需要的关键属性,结合当前游戏AI、智能兵棋等相关博弈平台,利用相关文献[6,8,24-25,29-30,37-39,43,46-49]进行分析,经过对比不难发现游戏 AI 过渡到智能兵棋,甚至是智能作战推演的难度,各个关键属性也是未来需要研究突破的关键点,具体见表1. ...
Reinforcement learning:an introduction
1
2005
... 强化学习的核心思想是不断地在环境中探索试错,并通过得到的回报值来判定当前动作的好坏,从而训练出高水平的智能AI[50].马尔可夫决策过程(Markov decision process,MDP)是强化学习的基础模型,环境通过状态与动作建模,描述agent与环境的交互过程.一般地,MDP可表示为四元组<S,A,R,T >[44]: ...
Deep reinforcement learning with double q-learning
1
2016
... DeepMind在2015年第一次利用DQN(deep Q network)算法在Atari游戏环境中实现了高水平的智能AI,该AI综合评定达到了人类专业玩家的水平[24].这也使得DQN算法成为强化学习的经典算法.DQN算法通过神经网络拟合Q值,通过训练不断调整神经网络中的权重,获得精准的预测 Q值,并通过最大的Q值进行动作选择.DQN算法有效地解决了Q-learning算法中存储的Q值有限的问题,可以解决大量的离散动作估值问题,并且DQN算法主要使用经验回放机制(experience replay),即将每次和环境交互得到的奖励与状态更新情况都保存起来,用于后面的Q值更新,从而明显增强了算法的适应性.DQN由于对价值函数做了近似表示,因此强化学习算法有了解决大规模强化学习问题的能力.但是 DQN 算法主要被应用于离散的动作空间,且DQN算法的训练不一定能保证Q值网络收敛,这就会导致在状态比较复杂的情况下,训练出的模型效果很差.在 DQN 算法的基础上,衍生出了一系列新的改进 DQN 算法,如 DDQN (double DQN )算法[51]、优先级经验回放 DQN (prioritized experience replay DQN)算法[52]、竞争构架Q网络(dueling DQN)算法[53]等.这些算法主要是在改进Q网络过拟合、改进经验回放中的采样机制、改进目标Q值计算等方面提升传统DQN算法网络的性能.总体来说,DQN系列强化学习算法都属于基于值函数的强化学习算法类型.基于值函数的强化学习算法主要存在 3点不足:对连续动作的处理能力不足、对受限状态下的问题处理能力不足、无法解决随机策略问题.由于这些原因,基于值函数的强化学习方法不能适用所有的场景,因此需要新的方法解决上述问题,例如基于策略的强化学习方法. ...
Prioritized experience replay
3
... DeepMind在2015年第一次利用DQN(deep Q network)算法在Atari游戏环境中实现了高水平的智能AI,该AI综合评定达到了人类专业玩家的水平[24].这也使得DQN算法成为强化学习的经典算法.DQN算法通过神经网络拟合Q值,通过训练不断调整神经网络中的权重,获得精准的预测 Q值,并通过最大的Q值进行动作选择.DQN算法有效地解决了Q-learning算法中存储的Q值有限的问题,可以解决大量的离散动作估值问题,并且DQN算法主要使用经验回放机制(experience replay),即将每次和环境交互得到的奖励与状态更新情况都保存起来,用于后面的Q值更新,从而明显增强了算法的适应性.DQN由于对价值函数做了近似表示,因此强化学习算法有了解决大规模强化学习问题的能力.但是 DQN 算法主要被应用于离散的动作空间,且DQN算法的训练不一定能保证Q值网络收敛,这就会导致在状态比较复杂的情况下,训练出的模型效果很差.在 DQN 算法的基础上,衍生出了一系列新的改进 DQN 算法,如 DDQN (double DQN )算法[51]、优先级经验回放 DQN (prioritized experience replay DQN)算法[52]、竞争构架Q网络(dueling DQN)算法[53]等.这些算法主要是在改进Q网络过拟合、改进经验回放中的采样机制、改进目标Q值计算等方面提升传统DQN算法网络的性能.总体来说,DQN系列强化学习算法都属于基于值函数的强化学习算法类型.基于值函数的强化学习算法主要存在 3点不足:对连续动作的处理能力不足、对受限状态下的问题处理能力不足、无法解决随机策略问题.由于这些原因,基于值函数的强化学习方法不能适用所有的场景,因此需要新的方法解决上述问题,例如基于策略的强化学习方法. ...
... 在现有策略对抗游戏中利用深度学习技术结合强化学习来实现游戏AI已成为主流研究方向[52].其主要思路为在游戏对抗过程中利用图像特征的卷积提取技术.如在《觉悟AI》中,图像特征的提取采取了分层的思想,在主视野和小地图中,对不同种类的要素进行提取并合并到一个层中,最终每层都提取到一类关键属性节点信息,形成“英雄”“野怪”“小兵”位置矩阵[6].最终将多尺度特征的信息融合形成全局态势特征信息,这一工作同样应用在AlphaStar中.对于作战推演来说,态势理解一直是研究的难点,那么考虑利用深度学习技术来实现态势图像特征的提取,进而最终输出态势图的关键信息将是解决方案之一.此外,笔者所在团队也尝试利用深度学习技术对态势信息进行卷积提取,然后将提取信息与语义模型结合,生成当前态势的直观文本语义.而在前端利用强化学习进行实体单元控制,这样就可以将强化学习、深度学习、自然语言处理融合,在推演过程中实时生成方便人类理解的智能决策文本语义信息,这一工作对于实现推演系统中的人机融合具有积极意义. ...
... 智能博弈对抗的建模过程面临两个难题,一个是动作空间庞大,另一个是奖励稀疏问题.面对这两个问题,有研究人员提出了分层强化学习的解决思路.该思路的核心是对动作进行分层,将低层级(low-level)动作组成高层级(high-level)动作,这样搜索空间就会被减小[52].同时基于分层的思想,在一个预训练的环境中学习有用的技能,这些技能是通用的,与要解决的对抗任务的关系不太紧密.学习一个高层的控制策略能够使 agent 根据状态调用技能,并且该方法能够很好地解决探索效率较低的问题,该方法已在一系列稀疏奖励的任务中表现出色[61-62].《觉悟 AI》同样设计了分层强化学习的动作标签来控制“英雄”的微观操作.具体来说,每个标签由两个层级(或子标签)组成,它们表示一级和二级操作.第一个动作,即一级动作,表示要采取的动作,包括移动、普通攻击、一技能、二技能、三技能、回血、回城等.第二个是二级动作,它告诉玩家如何根据动作类型具体地执行动作.例如,如果第一个层级是移动动作,那么第二个层级就是选择一个二维坐标来选择移动的方向;当第一个层级为普通攻击时,第二个层级将成为选择攻击目标;如果第一个层级是一技能(或二技能、三技能),那么第二个层级将针对不同技能选择释放技能的类型、目标和区域.这对于作战推演中不同算子如何执行动作也具有参考价值,每一个类型的算子同样存在不同的动作,例如坦克可以选择直瞄射击、间瞄射击、移动方向等,实际作战推演不同装备同样具有众多复杂的动作,通过这样的特征和标签设计,可以将人工智能建模任务作为一个层次化的多类分类问题来完成.具体来说,一个深层次的神经网络模型被训练以预测在给定的情境下要采取的行动.作战推演也可以参考层次化的动作标签来不断细化动作执行过程,进而训练解决复杂的动作执行难题.在作战推演中完全可以借鉴这种思路设计适用于作战场景的分层强化学习框架.南京大学的研究人员利用分层强化学习建立宏观策略模型和微观策略模型,根据具体的态势评估宏观策略模型,然后利用宏函数批量绑定选择微观动作,这样可以在不同的局势下选择对应的一系列动作,进而实现了分层强化学习在《星际争霸》环境中的应用[63].分层强化学习比较通用的框架是两层,顶层策略被称为元控制器(meta-controller),负责生成总体宏观目标,底层策略被称为控制器(controller),负责完成给定的子目标,这种机制本质也对应作战推演中的战略、战役、战术3个层次,不同层次关注的作战目标各有不同,但又互相关联.其他相关改进是学者在奖赏函数设置、增加分层结构、保持分层同步、提高采样效率等方面改进分层强化学习[64]. ...
Dueling network architectures for deep reinforcement learning
1
... DeepMind在2015年第一次利用DQN(deep Q network)算法在Atari游戏环境中实现了高水平的智能AI,该AI综合评定达到了人类专业玩家的水平[24].这也使得DQN算法成为强化学习的经典算法.DQN算法通过神经网络拟合Q值,通过训练不断调整神经网络中的权重,获得精准的预测 Q值,并通过最大的Q值进行动作选择.DQN算法有效地解决了Q-learning算法中存储的Q值有限的问题,可以解决大量的离散动作估值问题,并且DQN算法主要使用经验回放机制(experience replay),即将每次和环境交互得到的奖励与状态更新情况都保存起来,用于后面的Q值更新,从而明显增强了算法的适应性.DQN由于对价值函数做了近似表示,因此强化学习算法有了解决大规模强化学习问题的能力.但是 DQN 算法主要被应用于离散的动作空间,且DQN算法的训练不一定能保证Q值网络收敛,这就会导致在状态比较复杂的情况下,训练出的模型效果很差.在 DQN 算法的基础上,衍生出了一系列新的改进 DQN 算法,如 DDQN (double DQN )算法[51]、优先级经验回放 DQN (prioritized experience replay DQN)算法[52]、竞争构架Q网络(dueling DQN)算法[53]等.这些算法主要是在改进Q网络过拟合、改进经验回放中的采样机制、改进目标Q值计算等方面提升传统DQN算法网络的性能.总体来说,DQN系列强化学习算法都属于基于值函数的强化学习算法类型.基于值函数的强化学习算法主要存在 3点不足:对连续动作的处理能力不足、对受限状态下的问题处理能力不足、无法解决随机策略问题.由于这些原因,基于值函数的强化学习方法不能适用所有的场景,因此需要新的方法解决上述问题,例如基于策略的强化学习方法. ...
Asynchronous methods for deep reinforcement learning
1
2016
... 2016 年 DeepMind 在国际机器学习大会(International Conference on Machine Learning)提出了A3C算法[54].之前的DQN算法为了方便收敛使用了经验回放的技巧;AC 也可以使用经验回放的技巧.A3C更进一步,还克服了一些经验回放的问题,主要采取随机性策略[55].这里确定性策略和随机性策略是相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这导致动作的空间维度极大.如果使用随机性策略,即像DQN算法一样研究它所有的可能动作的概率,并计算各个可能动作的价值,那需要的样本量是非常大的.于是DeepMind就想出使用确定性策略来简化这个问题[56].作为深度确定性策略梯度(deep deterministic policy gradient)、critic目标网络和深度双Q网络(double DQN )的当前Q网络,目标Q网络的功能定位基本类似,但是DDPG有自己的actor策略网络,因此不需要贪婪法这样的选择方法,这部分DDQN的功能到了DDPG可以在actor当前网络完成.而对经验回放池中采样的下一状态s'使用贪婪法选择动作a',这部分工作的作用是估计目标 Q 值,因此可以放到 actor 目标网络完成. ...
深度强化学习算法与应用研究现状综述
1
2020
... 2016 年 DeepMind 在国际机器学习大会(International Conference on Machine Learning)提出了A3C算法[54].之前的DQN算法为了方便收敛使用了经验回放的技巧;AC 也可以使用经验回放的技巧.A3C更进一步,还克服了一些经验回放的问题,主要采取随机性策略[55].这里确定性策略和随机性策略是相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这导致动作的空间维度极大.如果使用随机性策略,即像DQN算法一样研究它所有的可能动作的概率,并计算各个可能动作的价值,那需要的样本量是非常大的.于是DeepMind就想出使用确定性策略来简化这个问题[56].作为深度确定性策略梯度(deep deterministic policy gradient)、critic目标网络和深度双Q网络(double DQN )的当前Q网络,目标Q网络的功能定位基本类似,但是DDPG有自己的actor策略网络,因此不需要贪婪法这样的选择方法,这部分DDQN的功能到了DDPG可以在actor当前网络完成.而对经验回放池中采样的下一状态s'使用贪婪法选择动作a',这部分工作的作用是估计目标 Q 值,因此可以放到 actor 目标网络完成. ...
深度强化学习算法与应用研究现状综述
1
2020
... 2016 年 DeepMind 在国际机器学习大会(International Conference on Machine Learning)提出了A3C算法[54].之前的DQN算法为了方便收敛使用了经验回放的技巧;AC 也可以使用经验回放的技巧.A3C更进一步,还克服了一些经验回放的问题,主要采取随机性策略[55].这里确定性策略和随机性策略是相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这导致动作的空间维度极大.如果使用随机性策略,即像DQN算法一样研究它所有的可能动作的概率,并计算各个可能动作的价值,那需要的样本量是非常大的.于是DeepMind就想出使用确定性策略来简化这个问题[56].作为深度确定性策略梯度(deep deterministic policy gradient)、critic目标网络和深度双Q网络(double DQN )的当前Q网络,目标Q网络的功能定位基本类似,但是DDPG有自己的actor策略网络,因此不需要贪婪法这样的选择方法,这部分DDQN的功能到了DDPG可以在actor当前网络完成.而对经验回放池中采样的下一状态s'使用贪婪法选择动作a',这部分工作的作用是估计目标 Q 值,因此可以放到 actor 目标网络完成. ...
Continuous control with deep reinforcement learning
1
... 2016 年 DeepMind 在国际机器学习大会(International Conference on Machine Learning)提出了A3C算法[54].之前的DQN算法为了方便收敛使用了经验回放的技巧;AC 也可以使用经验回放的技巧.A3C更进一步,还克服了一些经验回放的问题,主要采取随机性策略[55].这里确定性策略和随机性策略是相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这导致动作的空间维度极大.如果使用随机性策略,即像DQN算法一样研究它所有的可能动作的概率,并计算各个可能动作的价值,那需要的样本量是非常大的.于是DeepMind就想出使用确定性策略来简化这个问题[56].作为深度确定性策略梯度(deep deterministic policy gradient)、critic目标网络和深度双Q网络(double DQN )的当前Q网络,目标Q网络的功能定位基本类似,但是DDPG有自己的actor策略网络,因此不需要贪婪法这样的选择方法,这部分DDQN的功能到了DDPG可以在actor当前网络完成.而对经验回放池中采样的下一状态s'使用贪婪法选择动作a',这部分工作的作用是估计目标 Q 值,因此可以放到 actor 目标网络完成. ...
Multi-agent actor-critic for mixed cooperative-competitive environments
1
2018
... 此外,actor当前网络也会基于critic目标网络计算出的目标Q值进行网络参数的更新,并定期将网络参数复制到 actor 目标网络.DDPG 参考了DDQN的算法思想,通过双网络和经验回放,以及一些其他的优化,比较好地解决了AC难收敛的问题.因此在实际产品中尤其是与自动化相关的产品中使用得比较多,是一个比较成熟的AC算法.2017年, Open AI在神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems)上又提出了改进的多 agent 深度确定性策略梯度(multi-agent deep deterministic policy gradient)算法[57],把强化学习算法进一步推广应用到多agent环境.在AC框架下,比较经典的算法还有近端策略优化(proximal policy optimization)算法[58]、柔性演员-评论家(soft actor-critic)算法[59]、双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient)算法[60]等,这些算法也都是在样本提取效率、探索能力增强方面进一步改进优化AC框架的. ...
Proximal policy optimization algorithms
1
... 此外,actor当前网络也会基于critic目标网络计算出的目标Q值进行网络参数的更新,并定期将网络参数复制到 actor 目标网络.DDPG 参考了DDQN的算法思想,通过双网络和经验回放,以及一些其他的优化,比较好地解决了AC难收敛的问题.因此在实际产品中尤其是与自动化相关的产品中使用得比较多,是一个比较成熟的AC算法.2017年, Open AI在神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems)上又提出了改进的多 agent 深度确定性策略梯度(multi-agent deep deterministic policy gradient)算法[57],把强化学习算法进一步推广应用到多agent环境.在AC框架下,比较经典的算法还有近端策略优化(proximal policy optimization)算法[58]、柔性演员-评论家(soft actor-critic)算法[59]、双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient)算法[60]等,这些算法也都是在样本提取效率、探索能力增强方面进一步改进优化AC框架的. ...
Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor
1
2018
... 此外,actor当前网络也会基于critic目标网络计算出的目标Q值进行网络参数的更新,并定期将网络参数复制到 actor 目标网络.DDPG 参考了DDQN的算法思想,通过双网络和经验回放,以及一些其他的优化,比较好地解决了AC难收敛的问题.因此在实际产品中尤其是与自动化相关的产品中使用得比较多,是一个比较成熟的AC算法.2017年, Open AI在神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems)上又提出了改进的多 agent 深度确定性策略梯度(multi-agent deep deterministic policy gradient)算法[57],把强化学习算法进一步推广应用到多agent环境.在AC框架下,比较经典的算法还有近端策略优化(proximal policy optimization)算法[58]、柔性演员-评论家(soft actor-critic)算法[59]、双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient)算法[60]等,这些算法也都是在样本提取效率、探索能力增强方面进一步改进优化AC框架的. ...
Addressing function approximation error in actor-critic methods
1
2018
... 此外,actor当前网络也会基于critic目标网络计算出的目标Q值进行网络参数的更新,并定期将网络参数复制到 actor 目标网络.DDPG 参考了DDQN的算法思想,通过双网络和经验回放,以及一些其他的优化,比较好地解决了AC难收敛的问题.因此在实际产品中尤其是与自动化相关的产品中使用得比较多,是一个比较成熟的AC算法.2017年, Open AI在神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems)上又提出了改进的多 agent 深度确定性策略梯度(multi-agent deep deterministic policy gradient)算法[57],把强化学习算法进一步推广应用到多agent环境.在AC框架下,比较经典的算法还有近端策略优化(proximal policy optimization)算法[58]、柔性演员-评论家(soft actor-critic)算法[59]、双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient)算法[60]等,这些算法也都是在样本提取效率、探索能力增强方面进一步改进优化AC框架的. ...
Stochastic neural networks for hierarchical reinforcement learning
1
... 智能博弈对抗的建模过程面临两个难题,一个是动作空间庞大,另一个是奖励稀疏问题.面对这两个问题,有研究人员提出了分层强化学习的解决思路.该思路的核心是对动作进行分层,将低层级(low-level)动作组成高层级(high-level)动作,这样搜索空间就会被减小[52].同时基于分层的思想,在一个预训练的环境中学习有用的技能,这些技能是通用的,与要解决的对抗任务的关系不太紧密.学习一个高层的控制策略能够使 agent 根据状态调用技能,并且该方法能够很好地解决探索效率较低的问题,该方法已在一系列稀疏奖励的任务中表现出色[61-62].《觉悟 AI》同样设计了分层强化学习的动作标签来控制“英雄”的微观操作.具体来说,每个标签由两个层级(或子标签)组成,它们表示一级和二级操作.第一个动作,即一级动作,表示要采取的动作,包括移动、普通攻击、一技能、二技能、三技能、回血、回城等.第二个是二级动作,它告诉玩家如何根据动作类型具体地执行动作.例如,如果第一个层级是移动动作,那么第二个层级就是选择一个二维坐标来选择移动的方向;当第一个层级为普通攻击时,第二个层级将成为选择攻击目标;如果第一个层级是一技能(或二技能、三技能),那么第二个层级将针对不同技能选择释放技能的类型、目标和区域.这对于作战推演中不同算子如何执行动作也具有参考价值,每一个类型的算子同样存在不同的动作,例如坦克可以选择直瞄射击、间瞄射击、移动方向等,实际作战推演不同装备同样具有众多复杂的动作,通过这样的特征和标签设计,可以将人工智能建模任务作为一个层次化的多类分类问题来完成.具体来说,一个深层次的神经网络模型被训练以预测在给定的情境下要采取的行动.作战推演也可以参考层次化的动作标签来不断细化动作执行过程,进而训练解决复杂的动作执行难题.在作战推演中完全可以借鉴这种思路设计适用于作战场景的分层强化学习框架.南京大学的研究人员利用分层强化学习建立宏观策略模型和微观策略模型,根据具体的态势评估宏观策略模型,然后利用宏函数批量绑定选择微观动作,这样可以在不同的局势下选择对应的一系列动作,进而实现了分层强化学习在《星际争霸》环境中的应用[63].分层强化学习比较通用的框架是两层,顶层策略被称为元控制器(meta-controller),负责生成总体宏观目标,底层策略被称为控制器(controller),负责完成给定的子目标,这种机制本质也对应作战推演中的战略、战役、战术3个层次,不同层次关注的作战目标各有不同,但又互相关联.其他相关改进是学者在奖赏函数设置、增加分层结构、保持分层同步、提高采样效率等方面改进分层强化学习[64]. ...
Learning representations in model-free hierarchical reinforcement learning
1
2019
... 智能博弈对抗的建模过程面临两个难题,一个是动作空间庞大,另一个是奖励稀疏问题.面对这两个问题,有研究人员提出了分层强化学习的解决思路.该思路的核心是对动作进行分层,将低层级(low-level)动作组成高层级(high-level)动作,这样搜索空间就会被减小[52].同时基于分层的思想,在一个预训练的环境中学习有用的技能,这些技能是通用的,与要解决的对抗任务的关系不太紧密.学习一个高层的控制策略能够使 agent 根据状态调用技能,并且该方法能够很好地解决探索效率较低的问题,该方法已在一系列稀疏奖励的任务中表现出色[61-62].《觉悟 AI》同样设计了分层强化学习的动作标签来控制“英雄”的微观操作.具体来说,每个标签由两个层级(或子标签)组成,它们表示一级和二级操作.第一个动作,即一级动作,表示要采取的动作,包括移动、普通攻击、一技能、二技能、三技能、回血、回城等.第二个是二级动作,它告诉玩家如何根据动作类型具体地执行动作.例如,如果第一个层级是移动动作,那么第二个层级就是选择一个二维坐标来选择移动的方向;当第一个层级为普通攻击时,第二个层级将成为选择攻击目标;如果第一个层级是一技能(或二技能、三技能),那么第二个层级将针对不同技能选择释放技能的类型、目标和区域.这对于作战推演中不同算子如何执行动作也具有参考价值,每一个类型的算子同样存在不同的动作,例如坦克可以选择直瞄射击、间瞄射击、移动方向等,实际作战推演不同装备同样具有众多复杂的动作,通过这样的特征和标签设计,可以将人工智能建模任务作为一个层次化的多类分类问题来完成.具体来说,一个深层次的神经网络模型被训练以预测在给定的情境下要采取的行动.作战推演也可以参考层次化的动作标签来不断细化动作执行过程,进而训练解决复杂的动作执行难题.在作战推演中完全可以借鉴这种思路设计适用于作战场景的分层强化学习框架.南京大学的研究人员利用分层强化学习建立宏观策略模型和微观策略模型,根据具体的态势评估宏观策略模型,然后利用宏函数批量绑定选择微观动作,这样可以在不同的局势下选择对应的一系列动作,进而实现了分层强化学习在《星际争霸》环境中的应用[63].分层强化学习比较通用的框架是两层,顶层策略被称为元控制器(meta-controller),负责生成总体宏观目标,底层策略被称为控制器(controller),负责完成给定的子目标,这种机制本质也对应作战推演中的战略、战役、战术3个层次,不同层次关注的作战目标各有不同,但又互相关联.其他相关改进是学者在奖赏函数设置、增加分层结构、保持分层同步、提高采样效率等方面改进分层强化学习[64]. ...
On reinforcement learning for full-length game of StarCraft
1
2019
... 智能博弈对抗的建模过程面临两个难题,一个是动作空间庞大,另一个是奖励稀疏问题.面对这两个问题,有研究人员提出了分层强化学习的解决思路.该思路的核心是对动作进行分层,将低层级(low-level)动作组成高层级(high-level)动作,这样搜索空间就会被减小[52].同时基于分层的思想,在一个预训练的环境中学习有用的技能,这些技能是通用的,与要解决的对抗任务的关系不太紧密.学习一个高层的控制策略能够使 agent 根据状态调用技能,并且该方法能够很好地解决探索效率较低的问题,该方法已在一系列稀疏奖励的任务中表现出色[61-62].《觉悟 AI》同样设计了分层强化学习的动作标签来控制“英雄”的微观操作.具体来说,每个标签由两个层级(或子标签)组成,它们表示一级和二级操作.第一个动作,即一级动作,表示要采取的动作,包括移动、普通攻击、一技能、二技能、三技能、回血、回城等.第二个是二级动作,它告诉玩家如何根据动作类型具体地执行动作.例如,如果第一个层级是移动动作,那么第二个层级就是选择一个二维坐标来选择移动的方向;当第一个层级为普通攻击时,第二个层级将成为选择攻击目标;如果第一个层级是一技能(或二技能、三技能),那么第二个层级将针对不同技能选择释放技能的类型、目标和区域.这对于作战推演中不同算子如何执行动作也具有参考价值,每一个类型的算子同样存在不同的动作,例如坦克可以选择直瞄射击、间瞄射击、移动方向等,实际作战推演不同装备同样具有众多复杂的动作,通过这样的特征和标签设计,可以将人工智能建模任务作为一个层次化的多类分类问题来完成.具体来说,一个深层次的神经网络模型被训练以预测在给定的情境下要采取的行动.作战推演也可以参考层次化的动作标签来不断细化动作执行过程,进而训练解决复杂的动作执行难题.在作战推演中完全可以借鉴这种思路设计适用于作战场景的分层强化学习框架.南京大学的研究人员利用分层强化学习建立宏观策略模型和微观策略模型,根据具体的态势评估宏观策略模型,然后利用宏函数批量绑定选择微观动作,这样可以在不同的局势下选择对应的一系列动作,进而实现了分层强化学习在《星际争霸》环境中的应用[63].分层强化学习比较通用的框架是两层,顶层策略被称为元控制器(meta-controller),负责生成总体宏观目标,底层策略被称为控制器(controller),负责完成给定的子目标,这种机制本质也对应作战推演中的战略、战役、战术3个层次,不同层次关注的作战目标各有不同,但又互相关联.其他相关改进是学者在奖赏函数设置、增加分层结构、保持分层同步、提高采样效率等方面改进分层强化学习[64]. ...
Hierarchical reinforcement learning with advantage-based auxiliary rewards
1
... 智能博弈对抗的建模过程面临两个难题,一个是动作空间庞大,另一个是奖励稀疏问题.面对这两个问题,有研究人员提出了分层强化学习的解决思路.该思路的核心是对动作进行分层,将低层级(low-level)动作组成高层级(high-level)动作,这样搜索空间就会被减小[52].同时基于分层的思想,在一个预训练的环境中学习有用的技能,这些技能是通用的,与要解决的对抗任务的关系不太紧密.学习一个高层的控制策略能够使 agent 根据状态调用技能,并且该方法能够很好地解决探索效率较低的问题,该方法已在一系列稀疏奖励的任务中表现出色[61-62].《觉悟 AI》同样设计了分层强化学习的动作标签来控制“英雄”的微观操作.具体来说,每个标签由两个层级(或子标签)组成,它们表示一级和二级操作.第一个动作,即一级动作,表示要采取的动作,包括移动、普通攻击、一技能、二技能、三技能、回血、回城等.第二个是二级动作,它告诉玩家如何根据动作类型具体地执行动作.例如,如果第一个层级是移动动作,那么第二个层级就是选择一个二维坐标来选择移动的方向;当第一个层级为普通攻击时,第二个层级将成为选择攻击目标;如果第一个层级是一技能(或二技能、三技能),那么第二个层级将针对不同技能选择释放技能的类型、目标和区域.这对于作战推演中不同算子如何执行动作也具有参考价值,每一个类型的算子同样存在不同的动作,例如坦克可以选择直瞄射击、间瞄射击、移动方向等,实际作战推演不同装备同样具有众多复杂的动作,通过这样的特征和标签设计,可以将人工智能建模任务作为一个层次化的多类分类问题来完成.具体来说,一个深层次的神经网络模型被训练以预测在给定的情境下要采取的行动.作战推演也可以参考层次化的动作标签来不断细化动作执行过程,进而训练解决复杂的动作执行难题.在作战推演中完全可以借鉴这种思路设计适用于作战场景的分层强化学习框架.南京大学的研究人员利用分层强化学习建立宏观策略模型和微观策略模型,根据具体的态势评估宏观策略模型,然后利用宏函数批量绑定选择微观动作,这样可以在不同的局势下选择对应的一系列动作,进而实现了分层强化学习在《星际争霸》环境中的应用[63].分层强化学习比较通用的框架是两层,顶层策略被称为元控制器(meta-controller),负责生成总体宏观目标,底层策略被称为控制器(controller),负责完成给定的子目标,这种机制本质也对应作战推演中的战略、战役、战术3个层次,不同层次关注的作战目标各有不同,但又互相关联.其他相关改进是学者在奖赏函数设置、增加分层结构、保持分层同步、提高采样效率等方面改进分层强化学习[64]. ...
Long short-term memory
1
1997
... 《觉悟 AI》在设计过程中利用深度学习不断提取游戏界面的态势信息.利用深度学习虽然可以把一个对抗界面的所有特征提取出来,但是提取的是静态的某一帧的界面信息,并没有把时间步之间的信息关联起来.时间步一般指一帧,也可以指多帧,其关键是将历史的帧信息和现在的信息关联起来.基于此,需要引入长短期记忆(long short-term memory,LSTM)网络.让 LSTM 一次接收多个时间步信息来学习这些时间步之间的关联信息,从而让 LSTM 帮助“英雄”学习技能组合,并选择“英雄”应该关注的主视野和小地图的具体方面,进而综合输出合理的动作,也通过 LSTM 关联历史数据来训练强化学习的神经网络模型[65].在实际作战推演过程中同样需要考虑这种情况,防止出现训练的AI为了某个战术目标而忽视了整体战略目标. ...
A review of evolutionary artificial neural networks
1
1993
... 在 1993 年就有人尝试用遗传算法训练神经网络,但是当时的计算机算力不足,导致这个方向并没有引起过多关注[66,67,68].随着深度强化学习技术的火热发展以及算力的显著提高,部分学者和机构又开始关注这一结合点.OpenAI在2017年尝试直接利用进化算法来代替强化学习技术,在 MuJoCo (multi-joint dynamics with contact)和Atari上取得了一定的效果.但是这一工作的前提是需要大量的CPU进行大规模训练,且实验环境比较简单[69].优步(Uber)AI在2017年尝试将基于种群的遗传算法和深度神经网络结合,利用进化策略而不是梯度策略来更新权重参数,取得的算法性能在一定程度上优于 A3C、DQN 算法[70].除了在优化网络参数方面进行结合,将进化策略和多 agent 强化学习结合也是一个有意义的方向.DeepMind就是在AlphaStar中利用了联盟赛制,在训练出的agent中不断优化筛选出更加优秀的 agent,从而不断演化,最终训练出超过职业选手水平的游戏AI[48]. ...
Evolutionary artificial neural networks:a review
1
2013
... 在 1993 年就有人尝试用遗传算法训练神经网络,但是当时的计算机算力不足,导致这个方向并没有引起过多关注[66,67,68].随着深度强化学习技术的火热发展以及算力的显著提高,部分学者和机构又开始关注这一结合点.OpenAI在2017年尝试直接利用进化算法来代替强化学习技术,在 MuJoCo (multi-joint dynamics with contact)和Atari上取得了一定的效果.但是这一工作的前提是需要大量的CPU进行大规模训练,且实验环境比较简单[69].优步(Uber)AI在2017年尝试将基于种群的遗传算法和深度神经网络结合,利用进化策略而不是梯度策略来更新权重参数,取得的算法性能在一定程度上优于 A3C、DQN 算法[70].除了在优化网络参数方面进行结合,将进化策略和多 agent 强化学习结合也是一个有意义的方向.DeepMind就是在AlphaStar中利用了联盟赛制,在训练出的agent中不断优化筛选出更加优秀的 agent,从而不断演化,最终训练出超过职业选手水平的游戏AI[48]. ...
A new evolutionary system for evolving artificial neural networks
1
1997
... 在 1993 年就有人尝试用遗传算法训练神经网络,但是当时的计算机算力不足,导致这个方向并没有引起过多关注[66,67,68].随着深度强化学习技术的火热发展以及算力的显著提高,部分学者和机构又开始关注这一结合点.OpenAI在2017年尝试直接利用进化算法来代替强化学习技术,在 MuJoCo (multi-joint dynamics with contact)和Atari上取得了一定的效果.但是这一工作的前提是需要大量的CPU进行大规模训练,且实验环境比较简单[69].优步(Uber)AI在2017年尝试将基于种群的遗传算法和深度神经网络结合,利用进化策略而不是梯度策略来更新权重参数,取得的算法性能在一定程度上优于 A3C、DQN 算法[70].除了在优化网络参数方面进行结合,将进化策略和多 agent 强化学习结合也是一个有意义的方向.DeepMind就是在AlphaStar中利用了联盟赛制,在训练出的agent中不断优化筛选出更加优秀的 agent,从而不断演化,最终训练出超过职业选手水平的游戏AI[48]. ...
Evolution strategies as a scalable alternative to reinforcement learning
1
... 在 1993 年就有人尝试用遗传算法训练神经网络,但是当时的计算机算力不足,导致这个方向并没有引起过多关注[66,67,68].随着深度强化学习技术的火热发展以及算力的显著提高,部分学者和机构又开始关注这一结合点.OpenAI在2017年尝试直接利用进化算法来代替强化学习技术,在 MuJoCo (multi-joint dynamics with contact)和Atari上取得了一定的效果.但是这一工作的前提是需要大量的CPU进行大规模训练,且实验环境比较简单[69].优步(Uber)AI在2017年尝试将基于种群的遗传算法和深度神经网络结合,利用进化策略而不是梯度策略来更新权重参数,取得的算法性能在一定程度上优于 A3C、DQN 算法[70].除了在优化网络参数方面进行结合,将进化策略和多 agent 强化学习结合也是一个有意义的方向.DeepMind就是在AlphaStar中利用了联盟赛制,在训练出的agent中不断优化筛选出更加优秀的 agent,从而不断演化,最终训练出超过职业选手水平的游戏AI[48]. ...
Deep neuroevolution:genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning
1
... 在 1993 年就有人尝试用遗传算法训练神经网络,但是当时的计算机算力不足,导致这个方向并没有引起过多关注[66,67,68].随着深度强化学习技术的火热发展以及算力的显著提高,部分学者和机构又开始关注这一结合点.OpenAI在2017年尝试直接利用进化算法来代替强化学习技术,在 MuJoCo (multi-joint dynamics with contact)和Atari上取得了一定的效果.但是这一工作的前提是需要大量的CPU进行大规模训练,且实验环境比较简单[69].优步(Uber)AI在2017年尝试将基于种群的遗传算法和深度神经网络结合,利用进化策略而不是梯度策略来更新权重参数,取得的算法性能在一定程度上优于 A3C、DQN 算法[70].除了在优化网络参数方面进行结合,将进化策略和多 agent 强化学习结合也是一个有意义的方向.DeepMind就是在AlphaStar中利用了联盟赛制,在训练出的agent中不断优化筛选出更加优秀的 agent,从而不断演化,最终训练出超过职业选手水平的游戏AI[48]. ...
决策树分类技术研究
1
2004
... 决策树方法是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,并判断其可行性的决策分析方法,是直观运用概率分析的一种图解法[71].其本身是一种树形结构,其中每个内部节点表示一个行为判断,每个分支代表一个判断结果的输出,每个叶节点代表一种分类结果. ...
决策树分类技术研究
1
2004
... 决策树方法是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,并判断其可行性的决策分析方法,是直观运用概率分析的一种图解法[71].其本身是一种树形结构,其中每个内部节点表示一个行为判断,每个分支代表一个判断结果的输出,每个叶节点代表一种分类结果. ...
面向作战推演的博弈与决策模型及应用研究
1
2013
... 在作战推演建模的早期研究中,决策树是一种非常重要且常用的建模方法[72],其易于构建作战实体的行为规则,有利于分析基于决策树的作战实体行为模型[73],这在作战推演的初期是一种快速建立对手模型的高效办法,并且基于决策树的作战AI 也具有一定的初步智能性.在现在的游戏智能博弈对抗过程中,虽然基于决策树的研究总体比较少,但是衍生出了一些重要的算法,如南京大学Zhou Z H 等人[74]提出的深度森林算法就是在决策树的基础上拓展而来的.这些工作都为后面的智能博弈领域的研究提供了重要的理论基础. ...
面向作战推演的博弈与决策模型及应用研究
1
2013
... 在作战推演建模的早期研究中,决策树是一种非常重要且常用的建模方法[72],其易于构建作战实体的行为规则,有利于分析基于决策树的作战实体行为模型[73],这在作战推演的初期是一种快速建立对手模型的高效办法,并且基于决策树的作战AI 也具有一定的初步智能性.在现在的游戏智能博弈对抗过程中,虽然基于决策树的研究总体比较少,但是衍生出了一些重要的算法,如南京大学Zhou Z H 等人[74]提出的深度森林算法就是在决策树的基础上拓展而来的.这些工作都为后面的智能博弈领域的研究提供了重要的理论基础. ...
基于决策树的作战实体行为规则建模
1
2020
... 在作战推演建模的早期研究中,决策树是一种非常重要且常用的建模方法[72],其易于构建作战实体的行为规则,有利于分析基于决策树的作战实体行为模型[73],这在作战推演的初期是一种快速建立对手模型的高效办法,并且基于决策树的作战AI 也具有一定的初步智能性.在现在的游戏智能博弈对抗过程中,虽然基于决策树的研究总体比较少,但是衍生出了一些重要的算法,如南京大学Zhou Z H 等人[74]提出的深度森林算法就是在决策树的基础上拓展而来的.这些工作都为后面的智能博弈领域的研究提供了重要的理论基础. ...
基于决策树的作战实体行为规则建模
1
2020
... 在作战推演建模的早期研究中,决策树是一种非常重要且常用的建模方法[72],其易于构建作战实体的行为规则,有利于分析基于决策树的作战实体行为模型[73],这在作战推演的初期是一种快速建立对手模型的高效办法,并且基于决策树的作战AI 也具有一定的初步智能性.在现在的游戏智能博弈对抗过程中,虽然基于决策树的研究总体比较少,但是衍生出了一些重要的算法,如南京大学Zhou Z H 等人[74]提出的深度森林算法就是在决策树的基础上拓展而来的.这些工作都为后面的智能博弈领域的研究提供了重要的理论基础. ...
Deep forest
1
2019
... 在作战推演建模的早期研究中,决策树是一种非常重要且常用的建模方法[72],其易于构建作战实体的行为规则,有利于分析基于决策树的作战实体行为模型[73],这在作战推演的初期是一种快速建立对手模型的高效办法,并且基于决策树的作战AI 也具有一定的初步智能性.在现在的游戏智能博弈对抗过程中,虽然基于决策树的研究总体比较少,但是衍生出了一些重要的算法,如南京大学Zhou Z H 等人[74]提出的深度森林算法就是在决策树的基础上拓展而来的.这些工作都为后面的智能博弈领域的研究提供了重要的理论基础. ...
基于综合势能的作战行动序列生成方法研究
1
2020
... 国内研究人员借鉴物理学中的势能理论与方法,对指挥决策人员与战场要素间作用关系及其发展趋势进行量化分析和形式化表达,引导智能决策实体进行行动策略选择.并且从势能角度分析了作战指挥决策机理,尝试利用基于变权的动态势能模型和基于统计分析的静态势能模型,构建了基于综合势能的作战行动序列生成方法.并尝试在智能兵棋领域进行实验,验证了该算法优于多数规则及知识AI[75].实际上,该方法是利用离线和在线统计数据综合分析出智能兵棋推演 AI 的.可以尝试将该方法与强化学习结合,弥补强化学习开始阶段训练收敛速度过慢的缺陷,并在强化学习算法执行过程中,结合综合势能进行动作校正,从而生成更加智能化的作战行动序列. ...
基于综合势能的作战行动序列生成方法研究
1
2020
... 国内研究人员借鉴物理学中的势能理论与方法,对指挥决策人员与战场要素间作用关系及其发展趋势进行量化分析和形式化表达,引导智能决策实体进行行动策略选择.并且从势能角度分析了作战指挥决策机理,尝试利用基于变权的动态势能模型和基于统计分析的静态势能模型,构建了基于综合势能的作战行动序列生成方法.并尝试在智能兵棋领域进行实验,验证了该算法优于多数规则及知识AI[75].实际上,该方法是利用离线和在线统计数据综合分析出智能兵棋推演 AI 的.可以尝试将该方法与强化学习结合,弥补强化学习开始阶段训练收敛速度过慢的缺陷,并在强化学习算法执行过程中,结合综合势能进行动作校正,从而生成更加智能化的作战行动序列. ...
Random forests
1
2001
... 在机器学习中,随机森林是一个包含多个决策树的分类器,并且输出的类别是由个别树输出的类别的众数而定的.Breiman L[76]推论出随机森林算法.随机森林的随机性主要体现在可以从原始数据中采取有放回的抽样构造子数据集,子数据集的数据量和原始数据集是相同的.随机森林可以随机选取待选特征,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,再在随机选取的特征中选取最优的特征.随机森林的优点是实现相对简单,训练速度较快,可以并行实现;相比单一的决策树,能学习到特征之间的相互影响,并且不容易过拟合;对于高维数据来说,不需要做特征选择,明显提高了训练效率. ...
Generating novice heuristics for post-flop poker
1
2018
... 在智能博弈对抗领域,与随机森林相关的研究其实较少,但是其在一定程度上可以作为训练数据的有效手段,进而弥补一些强化学习算法训练效率较低的缺陷.已有学者在德州扑克的博弈对抗环境中将策略空间设计为一种快速且高效的决策树,进而有利于使用多种方法来学习这种启发式的方法[77]. ...
基于人件服务的C4ISR服务视点扩展
1
2016
... 真实、完整地刻画人的直接参与特点,并且对人的服务角色进行统一管理和调度是构建人机融合系统的重要前提,人件技术能够更好地把人真正融入人机交互系统中,使该系统真正体现以人为本、强调智能的新型交互系统特点[78-79].在智能博弈对抗环境中,人件技术主要是在专家经验知识中进行考虑,主要利用高水平玩家的数据进行监督学习,方便快速高效地训练出高水平的深度强化学习AI.人件技术的核心是在训练过程中融入人的行为偏好,通过人类行为决策数据进行训练,训练出一个初步的模型.而强化学习算法可以直接从初步的模型中提取相关数据,进而能训练出更具有智能性的 AI.DeepMind 对 AlphaStar 做了一组关于专家经验的消融实验,该消融实验证明 AlphaStar在复杂环境中,单纯依靠强化学习进行训练很难获得效果.同时该实验证明在仅有监督学习技术的支持下,AlphaStar 可以达到较好的效果.在充分利用人类数据后,AlphaStar 的性能可以再次提高60%. ...
基于人件服务的C4ISR服务视点扩展
1
2016
... 真实、完整地刻画人的直接参与特点,并且对人的服务角色进行统一管理和调度是构建人机融合系统的重要前提,人件技术能够更好地把人真正融入人机交互系统中,使该系统真正体现以人为本、强调智能的新型交互系统特点[78-79].在智能博弈对抗环境中,人件技术主要是在专家经验知识中进行考虑,主要利用高水平玩家的数据进行监督学习,方便快速高效地训练出高水平的深度强化学习AI.人件技术的核心是在训练过程中融入人的行为偏好,通过人类行为决策数据进行训练,训练出一个初步的模型.而强化学习算法可以直接从初步的模型中提取相关数据,进而能训练出更具有智能性的 AI.DeepMind 对 AlphaStar 做了一组关于专家经验的消融实验,该消融实验证明 AlphaStar在复杂环境中,单纯依靠强化学习进行训练很难获得效果.同时该实验证明在仅有监督学习技术的支持下,AlphaStar 可以达到较好的效果.在充分利用人类数据后,AlphaStar 的性能可以再次提高60%. ...
面向新型决策系统的人件模型研究
1
2016
... 真实、完整地刻画人的直接参与特点,并且对人的服务角色进行统一管理和调度是构建人机融合系统的重要前提,人件技术能够更好地把人真正融入人机交互系统中,使该系统真正体现以人为本、强调智能的新型交互系统特点[78-79].在智能博弈对抗环境中,人件技术主要是在专家经验知识中进行考虑,主要利用高水平玩家的数据进行监督学习,方便快速高效地训练出高水平的深度强化学习AI.人件技术的核心是在训练过程中融入人的行为偏好,通过人类行为决策数据进行训练,训练出一个初步的模型.而强化学习算法可以直接从初步的模型中提取相关数据,进而能训练出更具有智能性的 AI.DeepMind 对 AlphaStar 做了一组关于专家经验的消融实验,该消融实验证明 AlphaStar在复杂环境中,单纯依靠强化学习进行训练很难获得效果.同时该实验证明在仅有监督学习技术的支持下,AlphaStar 可以达到较好的效果.在充分利用人类数据后,AlphaStar 的性能可以再次提高60%. ...
面向新型决策系统的人件模型研究
1
2016
... 真实、完整地刻画人的直接参与特点,并且对人的服务角色进行统一管理和调度是构建人机融合系统的重要前提,人件技术能够更好地把人真正融入人机交互系统中,使该系统真正体现以人为本、强调智能的新型交互系统特点[78-79].在智能博弈对抗环境中,人件技术主要是在专家经验知识中进行考虑,主要利用高水平玩家的数据进行监督学习,方便快速高效地训练出高水平的深度强化学习AI.人件技术的核心是在训练过程中融入人的行为偏好,通过人类行为决策数据进行训练,训练出一个初步的模型.而强化学习算法可以直接从初步的模型中提取相关数据,进而能训练出更具有智能性的 AI.DeepMind 对 AlphaStar 做了一组关于专家经验的消融实验,该消融实验证明 AlphaStar在复杂环境中,单纯依靠强化学习进行训练很难获得效果.同时该实验证明在仅有监督学习技术的支持下,AlphaStar 可以达到较好的效果.在充分利用人类数据后,AlphaStar 的性能可以再次提高60%. ...
基于统计前向规划算法的游戏通用人工智能
1
2019
... 统计前向规划算法使用仿真模型(也称为前向模型)自适应地搜索有效的动作序列,此类算法提供了一种简单通用的方法,为各种游戏提供快速自适应的AI控制.常见的经典模型为MCTS算法, MCTS算法最重要的优点是不需要领域特定知识,可以在不了解游戏规则的情况下应用,这使得它很容易适用于任何可以使用树进行建模的领域.像Go[25]这样的游戏,分支因子明显具有高数量级特征,而有用的启发式又很难形成,这类问题就需要使用MCTS算法解决[80].尽管 MCTS 算法在大范围的博弈中提供了更强的决策能力,但将其应用在作战推演领域仍存在很多挑战和瓶颈.在作战推演领域,当需要搜索的图的分支因子和深度被限定,作战推演非常耗费CPU、GPU资源时,MCTS算法是否仍然是指导作战推演的最佳方法是一个有待研究的问题. ...
基于统计前向规划算法的游戏通用人工智能
1
2019
... 统计前向规划算法使用仿真模型(也称为前向模型)自适应地搜索有效的动作序列,此类算法提供了一种简单通用的方法,为各种游戏提供快速自适应的AI控制.常见的经典模型为MCTS算法, MCTS算法最重要的优点是不需要领域特定知识,可以在不了解游戏规则的情况下应用,这使得它很容易适用于任何可以使用树进行建模的领域.像Go[25]这样的游戏,分支因子明显具有高数量级特征,而有用的启发式又很难形成,这类问题就需要使用MCTS算法解决[80].尽管 MCTS 算法在大范围的博弈中提供了更强的决策能力,但将其应用在作战推演领域仍存在很多挑战和瓶颈.在作战推演领域,当需要搜索的图的分支因子和深度被限定,作战推演非常耗费CPU、GPU资源时,MCTS算法是否仍然是指导作战推演的最佳方法是一个有待研究的问题. ...
StarCraft micromanagement with reinforcement learning and curriculum transfer learning
1
2019
... 智能博弈的 AI 建模普遍存在适应性不高的问题,有部分研究人员开发的 AI 是针对某个固定想定开发的,导致更换博弈想定后AI性能大幅下降.考虑到大部分数据或任务是存在相关性的,通过迁移学习可以将已经学到的模型参数通过某种方式分享给新模型,从而加快优化模型效率.中国科学院自动化研究所的研究人员引入了课程迁移学习,将强化学习模型扩展到各种不同博弈场景,并且提升了采样效率[81].DeepMind 在 AlphaZero 中使用同样的算法设置、网络架构和超参数,得到了一种适用于围棋、国际象棋和将棋的通用算法,并战胜了基于其他技术的棋类游戏AI[82].《觉悟AI》引入了课程学习方法,将训练至符合要求的参数迁移至同一个神经网络再次训练、迭代、修正以提高效率,使《觉悟AI》模型能熟练掌握40多个“英雄”[6,36].在作战推演中,更需要这种适用性强的通用 AI 算法,不需要在更换作战想定后重新训练模型,也只有这样才可以更加适应实时性要求极高的作战场景. ...
A general reinforcement learning algorithm that masters chess,shogi,and Go through self-play
1
2018
... 智能博弈的 AI 建模普遍存在适应性不高的问题,有部分研究人员开发的 AI 是针对某个固定想定开发的,导致更换博弈想定后AI性能大幅下降.考虑到大部分数据或任务是存在相关性的,通过迁移学习可以将已经学到的模型参数通过某种方式分享给新模型,从而加快优化模型效率.中国科学院自动化研究所的研究人员引入了课程迁移学习,将强化学习模型扩展到各种不同博弈场景,并且提升了采样效率[81].DeepMind 在 AlphaZero 中使用同样的算法设置、网络架构和超参数,得到了一种适用于围棋、国际象棋和将棋的通用算法,并战胜了基于其他技术的棋类游戏AI[82].《觉悟AI》引入了课程学习方法,将训练至符合要求的参数迁移至同一个神经网络再次训练、迭代、修正以提高效率,使《觉悟AI》模型能熟练掌握40多个“英雄”[6,36].在作战推演中,更需要这种适用性强的通用 AI 算法,不需要在更换作战想定后重新训练模型,也只有这样才可以更加适应实时性要求极高的作战场景. ...
Enhanced rolling horizon evolution algorithm with opponent model learning
1
2020
... 对手建模指在两个 agent 博弈的环境中,为了获得更高的收益,需要对对手的策略进行建模,利用模型(隐式)推断其所采取的策略来辅助决策.智能蓝方建模主要是在具有战争迷雾的情况下,对对手进行建模,并预测对手的未来动作.其前提通常是博弈环境存在战争迷雾,我方在无法获取准确的对手信息的情况下,针对对方进行预测评估.在对抗过程中,一种假设是对手是完全理性的,对对手(队友)进行建模是为了寻找博弈中的纳什均衡策略.为了解决这一难点问题,阿尔伯塔大学的研究人员提出了反事实遗憾最小化(counterfactual regret minimization,CFR)技术,该技术不再需要一次性推理一棵完整的博弈树,而是允许从博弈的当前状态使用启发式搜索.另外,对手建模可分为隐式建模和显式建模.通常隐式建模直接将对手信息作为自身博弈模型的一部分来处理对手信息缺失的问题,通过最大化agent期望回报的方式将对手的决策行为隐式引进自身模型,构成隐式建模方法.显式建模则直接根据观测到的对手历史行为数据进行推理优化,通过模型拟合对手行为策略,掌握对手意图,降低对手信息缺失带来的影响[83].总体来说,对手建模技术是智能博弈对抗是否有效的关键,只有建立一个可以高效预估对手行为的模型,才能保证智能博弈AI的有效性. ...
面向无人机集群路径规划的智能优化算法综述
1
2020
... 路径规划作为智能博弈中的重要组成部分,其主要任务是根据不同的想定,针对每个单元在起始点和终止点之间快速规划一条由多个路径点依次连接而成的最优路径[84].在智能博弈的背景下,最优路径的含义不仅仅是两点之间的距离最短,而是综合考虑博弈态势、资源情况和综合威胁后的最佳路径.但是,已有的路径规划算法主要以A-Star算法、Dijkstra算法、D*算法、LPA*算法、D* lite算法等为典型代表,在物流运输、无人驾驶、航空航天等领域都取得了显著成效.同时也有学者提出其他的路径规划算法,如基于神经网络和人工势场的协同博弈路径规划方法[85]等,但是在智能博弈的环境下,需要考虑的问题更加复杂,需要进一步对这些算法进行改进优化. ...
面向无人机集群路径规划的智能优化算法综述
1
2020
... 路径规划作为智能博弈中的重要组成部分,其主要任务是根据不同的想定,针对每个单元在起始点和终止点之间快速规划一条由多个路径点依次连接而成的最优路径[84].在智能博弈的背景下,最优路径的含义不仅仅是两点之间的距离最短,而是综合考虑博弈态势、资源情况和综合威胁后的最佳路径.但是,已有的路径规划算法主要以A-Star算法、Dijkstra算法、D*算法、LPA*算法、D* lite算法等为典型代表,在物流运输、无人驾驶、航空航天等领域都取得了显著成效.同时也有学者提出其他的路径规划算法,如基于神经网络和人工势场的协同博弈路径规划方法[85]等,但是在智能博弈的环境下,需要考虑的问题更加复杂,需要进一步对这些算法进行改进优化. ...
基于神经网络和人工势场的协同博弈路径规划
1
2019
... 路径规划作为智能博弈中的重要组成部分,其主要任务是根据不同的想定,针对每个单元在起始点和终止点之间快速规划一条由多个路径点依次连接而成的最优路径[84].在智能博弈的背景下,最优路径的含义不仅仅是两点之间的距离最短,而是综合考虑博弈态势、资源情况和综合威胁后的最佳路径.但是,已有的路径规划算法主要以A-Star算法、Dijkstra算法、D*算法、LPA*算法、D* lite算法等为典型代表,在物流运输、无人驾驶、航空航天等领域都取得了显著成效.同时也有学者提出其他的路径规划算法,如基于神经网络和人工势场的协同博弈路径规划方法[85]等,但是在智能博弈的环境下,需要考虑的问题更加复杂,需要进一步对这些算法进行改进优化. ...
基于神经网络和人工势场的协同博弈路径规划
1
2019
... 路径规划作为智能博弈中的重要组成部分,其主要任务是根据不同的想定,针对每个单元在起始点和终止点之间快速规划一条由多个路径点依次连接而成的最优路径[84].在智能博弈的背景下,最优路径的含义不仅仅是两点之间的距离最短,而是综合考虑博弈态势、资源情况和综合威胁后的最佳路径.但是,已有的路径规划算法主要以A-Star算法、Dijkstra算法、D*算法、LPA*算法、D* lite算法等为典型代表,在物流运输、无人驾驶、航空航天等领域都取得了显著成效.同时也有学者提出其他的路径规划算法,如基于神经网络和人工势场的协同博弈路径规划方法[85]等,但是在智能博弈的环境下,需要考虑的问题更加复杂,需要进一步对这些算法进行改进优化. ...
Modular architecture for StarCraft II with deep reinforcement learning
1
2018
... 现有的游戏平台中也有比较成熟的AI开发通用框架(如 pysc2[86-87]),但是相比成熟的作战推演通用框架还有较大差距.智能作战推演系统可以设计一个适用于复杂环境的通用框架,该框架包括作战推演算子、地图、规则、想定.同时最关键的是设计通用的算法接口,这些接口可以方便智能博弈算法的设计与实现,如环境加载接口、环境重置接口、环境渲染接口、动作随机选择接口、执行动作接口等.同时,也可以提前设计智能作战推演的基本功能框架,包括地图编辑模块、想定编辑模块、算子管理模块、规则编辑模块、推演设置模块、数据分析模块、系统配置模块.其中最核心的是推演设置模块可以自由选择每局推演使用的智能算法,从而实现智能算法设计和作战推演环境开发的解耦,这样才可以保证智能作战推演的灵活适应性.通用框架中另一个重要的因素是可以提供AI使用的工具,例如对于深度学习的分层态势显示,可以直观地提供一个通用接口进行展现,方便指挥人员快速调用该接口实现智能算法的辅助决策功能. ...
An efficient agent created in StarcCraft 2 using pysc2
1
2021
... 现有的游戏平台中也有比较成熟的AI开发通用框架(如 pysc2[86-87]),但是相比成熟的作战推演通用框架还有较大差距.智能作战推演系统可以设计一个适用于复杂环境的通用框架,该框架包括作战推演算子、地图、规则、想定.同时最关键的是设计通用的算法接口,这些接口可以方便智能博弈算法的设计与实现,如环境加载接口、环境重置接口、环境渲染接口、动作随机选择接口、执行动作接口等.同时,也可以提前设计智能作战推演的基本功能框架,包括地图编辑模块、想定编辑模块、算子管理模块、规则编辑模块、推演设置模块、数据分析模块、系统配置模块.其中最核心的是推演设置模块可以自由选择每局推演使用的智能算法,从而实现智能算法设计和作战推演环境开发的解耦,这样才可以保证智能作战推演的灵活适应性.通用框架中另一个重要的因素是可以提供AI使用的工具,例如对于深度学习的分层态势显示,可以直观地提供一个通用接口进行展现,方便指挥人员快速调用该接口实现智能算法的辅助决策功能. ...










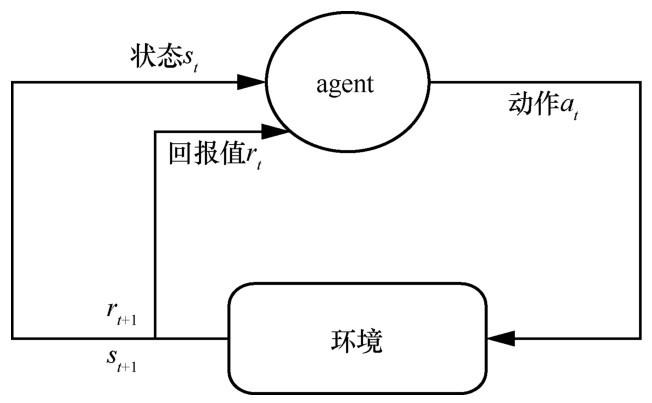

{kind=link}
{kind=link}