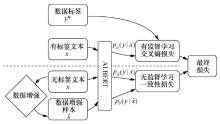
| [1] |
CHAPELLE O , SCHOLKOPF B , ZIEN E . Semi-supervised learning (Chapelle,O.et al.Eds.; 2006)[book reviews][J]. IEEE Transactions on Neural Networks, 2009,20(3): 542.
|
| [2] |
RASMUS A , VALPOLA H , HONKALA M ,et al. Semi-supervised learning with ladder network[J]. arXiv preprint,2015,arXiv:1507.02672.
|
| [3] |
LAINE S , AILA T M . Temporal ensembling for semi-supervised learning[J]. arXiv preprint,2016,arXiv:1610.02242.
|
| [4] |
TARVAINEN A , VALPOLA H . Weightaveraged,consistency targets improve semisupervised deep learning results[Z]. 2017.
|
| [5] |
BACHMAN P , ALSHARIF O , PRECUP D . Learning with pseudo-ensembles[J]. arXiv preprint,2014,arXiv:1412. 4864.
|
| [6] |
MIYATO T , MAEDA S I , KOYAMA M ,et al. Virtual adversarial training:a regularization method for supervised and semi-supervised learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019,41(8): 1979-1993.
|
| [7] |
SAJJADI M , JAVANMARDI M , TASDIZEN T . Regularization with stochastic transformations and perturbations for deep semi-supervised learning[J]. arXiv preprint,2016,arXiv:1606.04586.
|
| [8] |
CLARK K , LUONG M T , MANNING C D ,et al. Semi-supervised sequence modeling with cross-view training[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:Association for Computational Linguistics, 2018.
|
| [9] |
VERMA V , KAWAGUCHI K , LAMB A ,et al. Interpolation consistency training for semi-supervised learning[J]. arXiv preprint,2019,arXiv:1903.03825.
|
| [10] |
BERTHELOT D , CARLINI N , GOODFELLOW I J ,et al. MixMatch:a holistic approach to semi-supervised learning[J]. arXiv preprint,2019,arXiv:1905.02249.
|
| [11] |
XIE Q Z , DAI Z H , HOVY E ,et al. Unsupervised data augmentation for consistency training[J]. arXiv preprint,2019,arXiv:1904.12848.
|
| [12] |
RADFORD A , WU J , CHILD R ,et al. Language models are unsupervised multitask learners[Z]. 2019.
|
| [13] |
CHEN J A , CHEN J S , YU Z . Incorporating structured commonsense knowledge in story completion[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(1): 6244-6251.
|
| [14] |
AKBIK A , BERGMANN T , VOLLGRAF R . Pooled contextualized embeddings for named entity recognition[C]// Proceedings of the 2019 Conference of the North. Stroudsburg:Association for Computational Linguistics, 2019.
|
| [15] |
HOWARD J , RUDER S . Universal language model fine-tuning for text classification[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg:Association for Computational Linguistics, 2018.
|
| [16] |
MIKOLOV T , CHEN K , CORRADO G ,et al. Efficient estimation of word representations in vector space[J]. arXiv preprint,2013,arXiv:1301. 3781.
|
| [17] |
LAN Z Z , CHEN M D , GOODMAN S ,et al. ALBERT:a lite BERT for self-supervised learning of language representations[J]. arXiv preprint,2019,arXiv:1909.11942.
|
| [18] |
RADFORD A , NARASIMHAN K , SALIMANS T ,et al. Improving language understanding by generative pretraining[Z]. 2018.
|
| [19] |
DEVLIN J , CHANG M W , LEE K ,et al. BERT:pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint,2018,arXiv:1810.04805.
|
| [20] |
BEYER L , ZHAI X H , OLIVER A ,et al. S4L:self-supervised semi-supervised learning[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2019: 1476-1485.
|
| [21] |
OLIVER A , ODENA A , RAFFEL C ,et al. Realistic evaluation of deep semisupervised learning algorithms[J]. arXiv preprint,2018,arXiv:1804.09170.
|
| [22] |
PENNINGTON J , SOCHER R , MANNING C . Glove:global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:Association for Computational Linguistics, 2014.
|
| [23] |
PETERS M E , NEUMANN M , IYYER M ,et al. Deep contextualized word representations[J]. arXiv preprint,2018,arXiv:1802.05365.
|
| [24] |
JOULIN A , GRAVE E , BOJANOWSKI P ,et al. FastText.zip:compressing text classification models[J]. arXiv preprint,2016,arXiv:1612.03651.
|
| [25] |
GURURANGAN S , DANG T , CARD D ,et al. Variational pretraining for semisupervised text classification[J]. arXiv preprint,2019,arXiv:1906.02242.
|