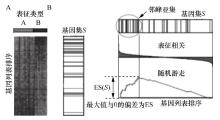
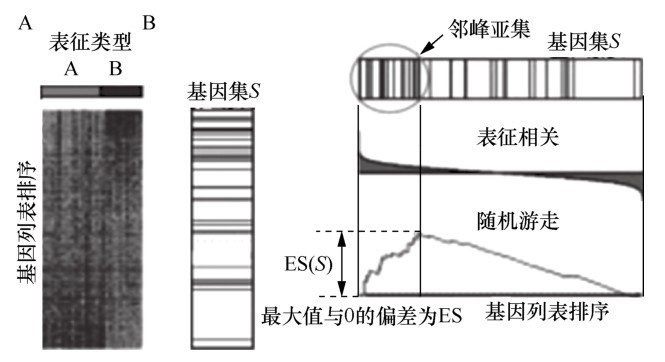
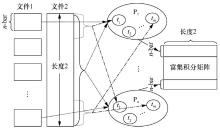
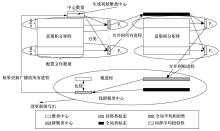
| [1] |
PARK H S , JUN C H . A simple and fast algorithm for K-medoids clustering[J]. Expert Systems with Applications, 2009,36(2): 3336-3341.
|
| [2] |
BARRETT T , TROUP D B , WILHITE S E ,et al. NCBI GEO:archive for functional genomics data sets[J]. Nucleic Acids Research, 2013,41(Database Issue): 991-995.
|
| [3] |
PARKINSON H , KAPUSHESKY M , SHOJATALAB M ,et al. ArrayExpress-a public database of microarray experiments and gene expression profiles[J]. Nucleic Acids Research, 2007,35(Database Issue): 747-750.
|
| [4] |
KATARZYNA T , PATRYCJA C , MACIEJ W . The Cancer Genome Atlas (TCGA):an immeasurable source of knowledge[J]. Contemporary Oncology, 2015,19(1A): 68-77.
|
| [5] |
WON S J , WU H C , LIN K T ,et al. Disc overy of molecular mechanisms of lignan justicidin a using L1000 gene expr ession profiles and the Library of Integrated Network-based Cellular Signatures database[J]. Journal of Functional Foods, 2015,16: 81-93.
|
| [6] |
张威, 张扬, 曹文君 ,等. GAGE和GSEA在基因集研究中的有效性比较[J]. 现代生物医学进展, 2013,13(10): 1849-1852.
|
|
ZHANG W , ZHANG Y , CAO W J ,et al. Comparative study of GAGE and GSEA in Gene-set analysis[J]. Progress in Modern Biomedicine, 2013,13(10): 1849-1852.
|
| [7] |
冯春琼, 邹亚光, 周其赵 ,等. GSEA在全基因组表达谱芯片数据分析中的应用[J]. 现代生物医学进展, 2009,9(13): 2553-2557.
|
|
FENG C Q , ZOU Y G , ZHOU Q Z ,et al. The application of GSEA in data analysis of Genome microarray[J]. Progress in Modern Biomedicine, 2009,9(13): 2553-2557.
|
| [8] |
SUBRAMANIAN A , TAMAYO P , MOOTHA V K ,et al. Gene set enrichment analysis:a knowledge-based approach for interpreting genome-wide expression profiles[J]. Proceedings of the National Academy of Sciences of the United States of America, 2005,102(43): 15545-15550.
|
| [9] |
DONGARRA J . Visit to the National University for Defense Technology Changsha,China[R]. 2013.
|
| [10] |
MOOTHA V K , LINDGREN C M , ERIKSSON K F ,et al. PGC-1alpharesponsive genes involved in oxidative phosphorylation are coordinately downregulated in human diabetes[J]. Nature Genetics, 2003,34(3): 267-273.
|
| [11] |
DINU I , POTTER J D , MUELLER T ,et al. Improving gene set analysis of microarray data by SAM-GS[J]. BMC Bioinformatics, 2007,8(1): 1-13.
|
| [12] |
CARRO M S , WEI K L , ALVAREZ M J ,et al. The transcriptional network for mesenchymal transformation of brain tumors[J]. Nature, 2010,463(7279): 318-325.
|
| [13] |
GAGGERO M , LEO S , MANCA S ,et al. Parallelizing bioinformatics applications with MapReduce[J]. ResearchGate, 2008: 1-6.
|
| [14] |
MACQUEEN J B , . Some Methods for classification and Analysis of Multivariate Observations[C]// The 5th Berkeley Symposium on Mathematical Statistics and Probability,June 21-July 18,1965,California,USA. Berkeley:University of California Press, 1967: 281-297.
|
| [15] |
刘小凤 . 适用于R NA二级结构预测的改进K-medoids聚类算法研究[D]. 秦皇岛:燕山大学, 2014.
|
|
LIU X F . Research of suitable K-medoids clustering algorithm for RNA secondary structures prediction[D]. Qinhuangdao:Yanshan University, 2014.
|