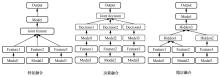
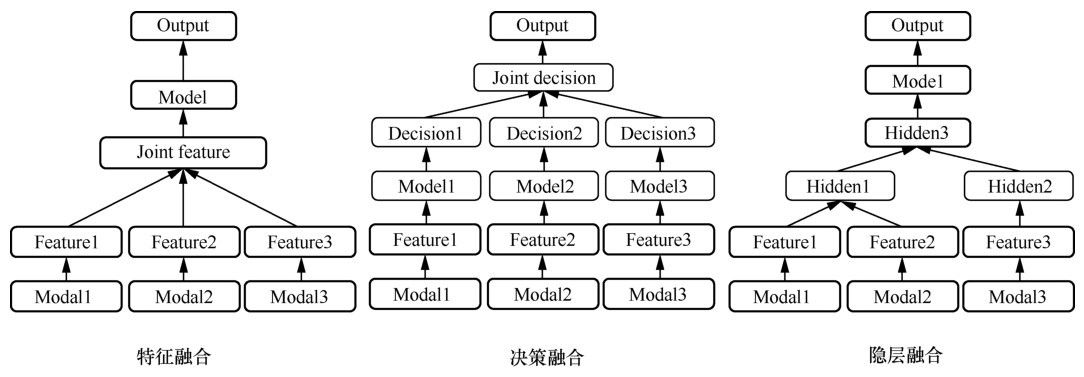
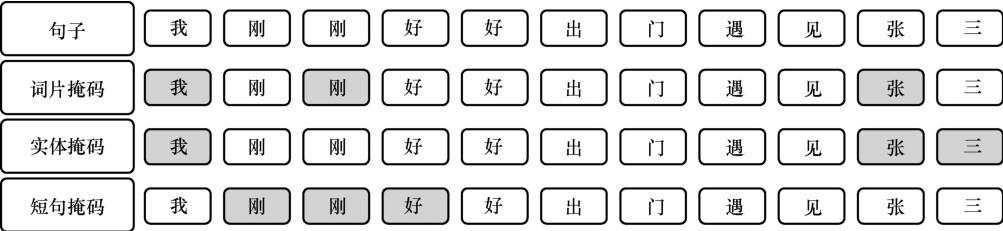
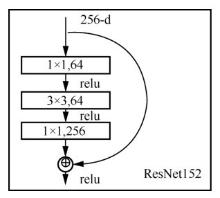
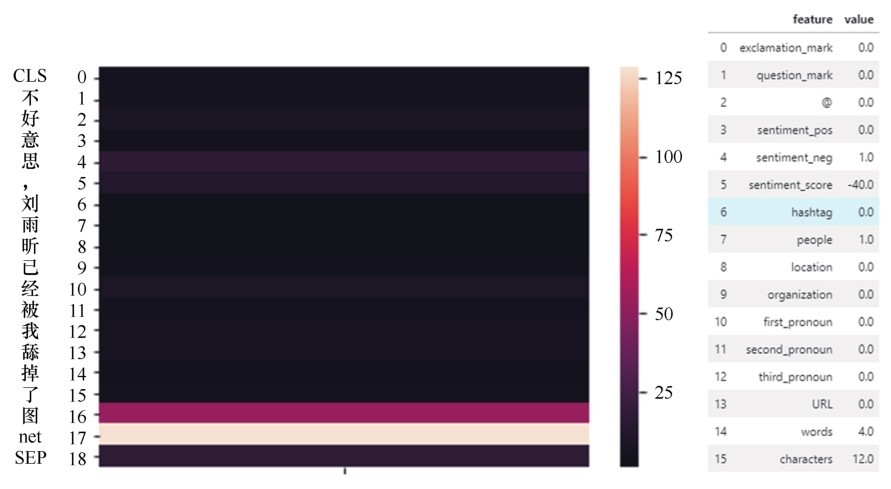
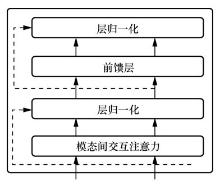
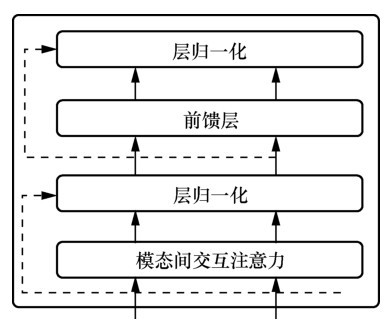
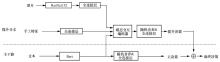
| [1] |
ZADEH A , ZELLERS R , PINCUS E ,et al. Mosi:multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[EB]. arXiv preprint, 2016,arXiv:1606.06259.
|
| [2] |
PORIA S , CAMBRIA E , HAZARIKA D ,et al. Multi-level multiple attentions for contextual multimodal sentiment analysis[C]// Proceedings of 2017 IEEE International Conference on Data Mining (ICDM). Piscataway:IEEE Press, 2017: 1033-1038.
|
| [3] |
GUO W , WANG J , WANG S . Deep multimodal representation learning:a survey[J]. IEEE Access, 2019,7: 63373-63394.
|
| [4] |
CAMBRIA E , HAZARIKA D , PORIA S ,et al. Benchmarking multimodal sentiment analysis[M]. Computational linguistics and intelligent text processing. Cham: Springer, 2018: 166-179.
|
| [5] |
ZADEH A , CHEN M H , PORIA S ,et al. Tensor fusion network for multimodal sentiment analysis[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:Association for Computational Linguistics, 2017: 1103-1114.
|
| [6] |
ZADEH A , LIANG P P , MAZUMDER N ,et al. Memory fusion network for multiview sequential learning[C]// Proceedings of the AAAI Conference on Artificial Intelligence.[S.l.:s.n.], 2018.
|
| [7] |
DEVLIN J , CHANG M W , LEE K ,et al. Bert:pre-training of deep bidirectional transformers for language understanding[EB]. arXiv preprint 2018,arXiv:1810.04805.
|
| [8] |
SUN Y , WANG S , LI Y ,et al. Ernie:enhanced representation through knowledge integration[EB]. arXiv preprint, 2019,arXiv:1904.09223.
|
| [9] |
CUI Y M , CHE W X , LIU T ,et al. Revisiting pre-trained models for Chinese natural language processing[C]// Proceedings of Findings of the Association for Computational Linguistics:EMNLP 2020. Stroudsburg:Association for Computational Linguistics, 2020: 657-668.
|
| [10] |
LIU Y , OTT M , GOYAL N ,et al. Roberta:a robustly optimized bert pretraining approach[EB]. arXiv preprint, 2019,arXiv:1907.11692.
|
| [11] |
SENNRICH R , HADDOW B , BIRCH A . Neural machine translation of rare words with subword units[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg:Association for Computational Linguistics, 2016: 1715-1725.
|
| [12] |
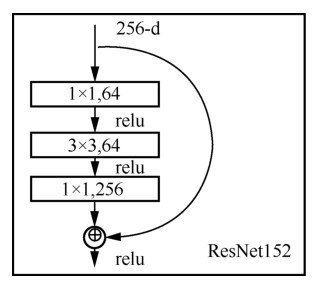
HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778.
|
| [13] |
PETERS M E , NEUMANN M , IYYER M ,et al. Deep contextualized word representations[EB]. arXiv preprint, 2018,arXiv:1802.05365.
|
| [14] |
RADFORD A , NARASIMHAN K , SALIMANS T ,et al. Improving language understanding by generative pretraining[Z]. OpenAI, 2018.
|
| [15] |
VASWANI A , SHAZEER N , PARMAR N ,et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York:ACM, 2017: 6000-6010.
|
| [16] |
IOFFE S , SZEGEDY C . Batch normalization:accelerating deep network training by reducing internal covariate shift[C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. New York:ACM, 2015: 448-456.
|
| [17] |
HENDRYCKS D , GIMPEL K . Gaussian error linear units (GELUs)[EB]. arXivpreprint, 2016,arXiv:1606.08415.
|
| [18] |
QI P , CAO J , YANG T Y ,et al. Exploiting multi-domain visual information for fake news detection[C]// Proceedings of 2019 IEEE International Conference on Data Mining. Piscataway:IEEE Press, 2020: 518-527.
|
| [19] |
JIN Z W , CAO J , GUO H ,et al. Multimodal fusion with recurrent neural networks for rumor detection on microblogs[C]// Proceedings of the 25th ACM international conference on Multimedia. New York:ACM, 2017: 795-816.
|
| [20] |
BOIDIDOU C , PAPADOPOULOS S , KOMPATSIARIS Y ,et al. Challenges of computational verification in social multimedia[C]// Proceedings of the 23rd International Conference on World Wide Web. New York:ACM, 2014: 743-748.
|
| [21] |
ANTOL S , AGRAWAL A , LU J ,et al. Vqa:visual question answering[C]// Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2015: 2425-2433.
|
| [22] |
VINYALS O , TOSHEV A , BENGIO S ,et al. Show and tell:a neural image caption generator[C]// Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway:IEEE Press, 2015: 3156-3164.
|
| [23] |
WANG Y Q , MA F L , JIN Z W ,et al. EANN:event adversarial neural networks for multi-modal fake news detection[C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York:ACM, 2018: 849-857.
|
| [24] |
JINSHUO L , KUO F , PAN J Z ,et al. MSRD:multi-modal web rumor detection method[J]. Journal of Computer Research and Development, 2020,57(11): 2328-2336.
|
| [25] |
JIANA M , XIAOPEI W , TING L ,et al. Cross-modal rumor detection based on adversarial neural network[J]. Data Analysis and Knowledge Discovery, 2023,6(12): 32-42.
|
| [26] |
MIYATO T , DAI A M , GOODFELLOW I ,et al. Adversarial training methods for semisupervised text classification[EB]. arXiv preprint, 2016,arXiv:605.07725.
|
| [27] |
MADRY A , MAKELOV A , SCHMIDT L ,et al. Towards deep learning models resistant to adversarial attacks[EB]. arXiv preprint, 2017,arXiv:1706.06083.
|