

网络与信息安全学报 ›› 2023, Vol. 9 ›› Issue (5): 138-149.doi: 10.11959/j.issn.2096-109x.2023078
• 学术论文 • 上一篇
赵彧然, 薛傥, 刘功申
修回日期:2023-03-02
出版日期:2023-10-01
发布日期:2023-10-01
作者简介:赵彧然(1998−),男,河南安阳人,上海交通大学硕士生,主要研究方向为自然语言处理基金资助:Yuran ZHAO, Tang XUE, Gongshen LIU
Revised:2023-03-02
Online:2023-10-01
Published:2023-10-01
Supported by:摘要:
预训练语言模型是自然语言处理领域一类十分重要的模型,预训练-微调成为许多下游任务的标准范式。先前的研究表明,将BERT等预训练语言模型融合至神经机器翻译模型能改善其性能。但目前仍不清楚这部分性能提升的来源是更强的语义建模能力还是句法建模能力。此外,预训练语言模型的知识是否以及如何影响神经机器翻译模型的鲁棒性仍不得而知。为此,使用探针方法对两类神经翻译模型编码器的句法建模能力进行测试,发现融合预训模型的翻译模型能够更好地建模句子的词序。在此基础上,提出了基于词序扰动的攻击方法,检验神经机器翻译模型的鲁棒性。多个语言对上的测试结果表明,即使受到词序扰动攻击,融合BERT的神经机器翻译模型的表现基本上优于传统的神经机器翻译模型,证明预训练模型能够提升翻译模型的鲁棒性。但在英语-德语翻译任务中,融合预训练模型的翻译模型生成的译文质量反而更差,表明英语BERT将损害翻译模型的鲁棒性。进一步分析显示,融合英语BERT的翻译模型难以应对句子受到词序扰动攻击前后的语义差距,导致模型出现更多错误的复制行为以及低频词翻译错误。因此,预训练并不总能为下游任务带来提高,研究者应该根据任务特性考虑是否使用预训练模型。
中图分类号:
赵彧然, 薛傥, 刘功申. 基于词序扰动的神经机器翻译模型鲁棒性研究[J]. 网络与信息安全学报, 2023, 9(5): 138-149.
Yuran ZHAO, Tang XUE, Gongshen LIU. Research on the robustness of neural machine translation systems in word order perturbation[J]. Chinese Journal of Network and Information Security, 2023, 9(5): 138-149.
表1
句法探针任务的示例Table 1 Examples for each syntactic probing task"
| 任务 | 示例 | 标签 |
| Distance | why not just bring up the idea of staying in your current lab with your advisor ? | 3 |
| word: idea, current | ||
| Depth | Budget negotiations between the mayor and the city council are entering high gear . | 3 |
| word: mayo | ||
| BShift | She wondered how time much had passed . | Inverted |
| TreeDepth | Who knew who would be there ? | 10 |
| TopConst | I wanted to start asking questions now , but forced myself to wait . | NP_VP_ |
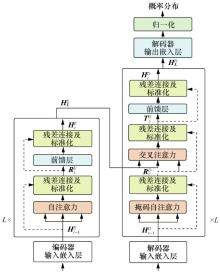
图1
NMT模型的整体结构Figure 1 The whole structure of the NMT model"
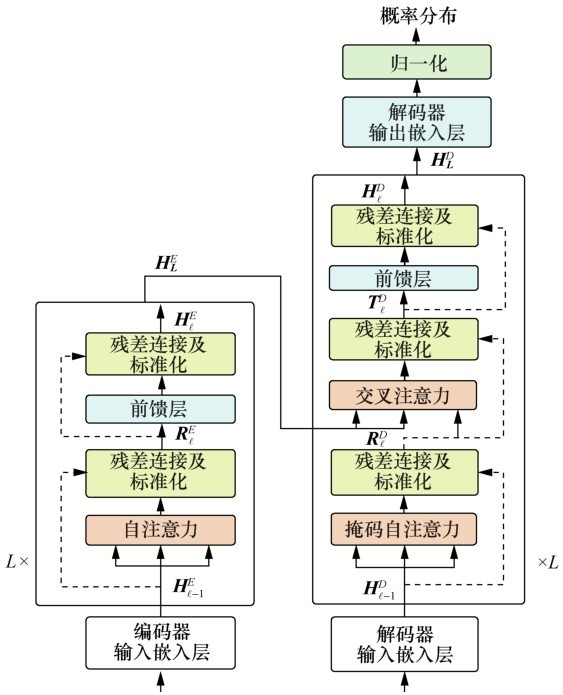
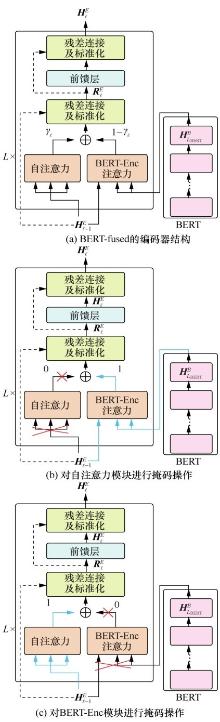
图2
BERT-fused编码器结构和掩码操作示意Figure 2 Overview of the structure of BERT-fused encoder and masking methods"
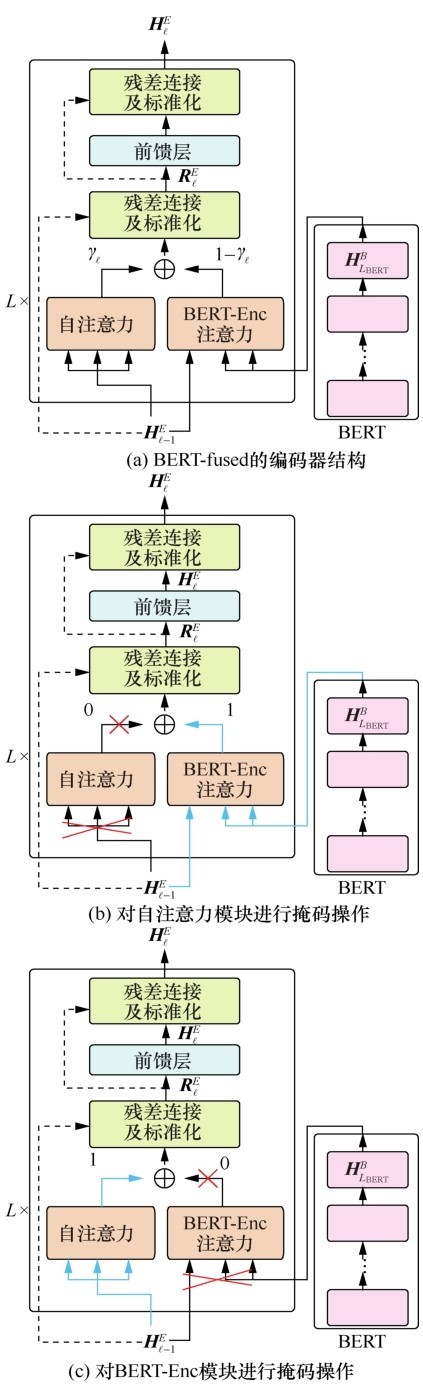
表2
句法相关的探针任务实验结果Table 2 Results of syntactic probing tasks"
| 模型 | 准确率 | ||||
| Distance | Depth | BShift | TreeDepth | TopConst | |
| BERT | 74.16% | 78.79% | 88.77% | 36.21% | 72.62% |
| NMT编码器 | 80.86% | 83.53% | 70.66% | 39.94% | 75.26% |
| BERT-NMT编码器 | 81.09% | 83.97% | 85.14% | 40.66% | 70.27% |
| 掩码自注意力模块 | 77.91% | 79.96% | 85.97% | 38.75% | 71.74% |
| 掩码BERT-Enc注意力模块 | 80.22% | 82.07% | 66.63% | 39.80% | 74.04% |
表3
使用攻击方法按照不同概率生成的样例Table 3 Examples generated by attacking method according to different probabilities"
| p | 句子 |
| 0.0 | Two sets of lights so close to one another: inten-tional or just a silly error? |
| 0.1 | Two sets of lights so close to one another: inten-tional or just silly a error? |
| 0.2 | Two sets of so lights close to one another: or inten-tional a just silly error? |
| 0.3 | Two of sets lights so to close another one intentional or: just a silly error? |
| 0.4 | Two sets of so lights to one close: another or inten-tional just a silly error? |
| 0.5 | Two sets lights of close to so one another intention-al: or just silly a error? |
表4
NMT和BERT-NMT在相应测试集上的BLEUScore和BERTScore Table 4 BLEUScore and BERTScore for NMT and BERT-NMT on corresponding test sets"
| 模型 | De-En BLEUScore/BERTScore | En-De BLEUScore/BERTScore | Fi-En BLEUScore/BERTScore | Tr-En BLEUScore/BERTScore | Zh-En BLEUScore/BERTScore |
| NMT | 31.1/85.8 | 27.1/85.5 | 25.9/83.8 | 16.0/75.5 | 22.8/82.4 |
| BERT-NMT | 32.4/86.8 | 29.0/86.1 | 26.9/84.9 | 18.8/78.6 | 23.2/82.7 |
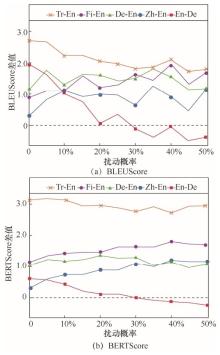
图3
BERT-NMT和NMT在BLEUScore和BERTScore上的差值Figure 3 Plots of differences between BERT-NMT and NMT in terms of BLEUScore and BERTScore"
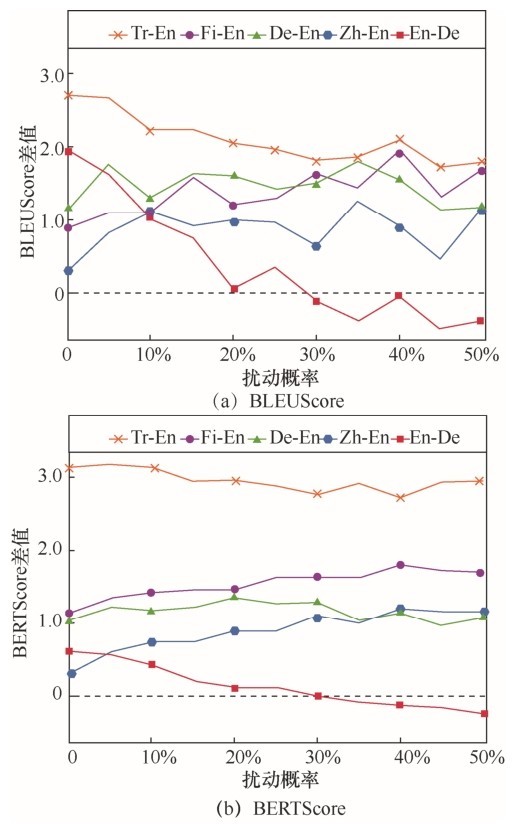
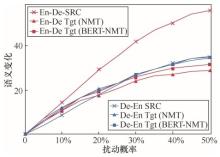
图4
源语言和目标语言端语义变化Figure 4 Changes of semantics in the source side and target side"
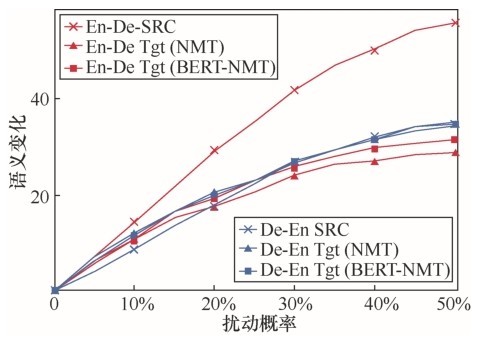
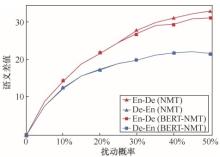
图5
源语言和目标语言端间的语义差值Figure 5 Semantic difference between the source side and target side"
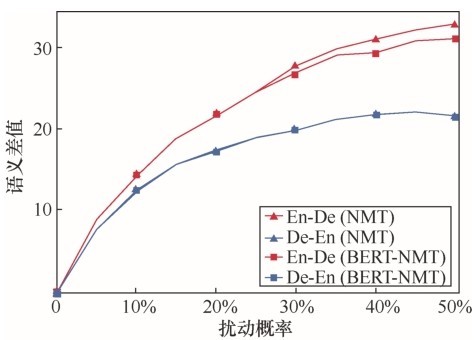
表5
当输入分别为未受攻击的句子和扰动后的句子时NMT和BERT-NMT生成的翻译样例Table 5 Translation examples generated by NMT and BERT-NMT when presented with undamaged and perturbed source sentence"
| 条件 | 句子 |
| 源语言句子 | In Cameroon, there is only one doctor for every 5 000 people, according to the World Health Organization. |
| 参考翻译 | In Kamerun gibt es nur einen Arzt für je 5 000 Menschen, so die Weltgesundheitsorganisation. |
| NMT | Nach Angaben der Weltgesundheitsorganisation gibt es in Kamerun nur einen Arzt für jeden 5 000 Menschen. |
| BERT-NMT | In Kamerun gibt es laut Weltgesundheitsorganisation nur einen Arzt pro 5 000 Menschen. |
| 源语言句子(p=0.5) | In, there is only one Cameroon for every 5 000 people, according to doctor the Health Organization World. |
| NMT(p=0.5) | In, gibt es nur ein Kamerun für jeden 5 000 Menschen, so der Arzt der Weltgesundheitsorganisation World. |
| BERT-NMT (p=0.5) | In, there is only one Cameroon for each 5 000 people, according to doctor the Health Organization World. |
表6
Tr-En中不同频率单词NMT和BERT-NMT的翻译F1值Table 6 Word prediction F1 score of NMT and BERT-NMT on words with different frequencies in Tr-En"
| 模型(攻击概率) | F1值 | ||
| 低频词 | 中频词 | 高频词 | |
| NMT(p=0) | 24.1 | 28.4 | 46.8 |
| BERT-NMT(p=0) | 27.1 | 32.3 | 50.7 |
| NMT(p=0.5) | 19.0 | 22.9 | 41.7 |
| BERT-NMT(p=0.5) | 19.4 | 24.9 | 44.5 |
表7
En-De中不同频率单词NMT和BERT-NMT的翻译F1值Table 7 Word prediction F1 score of NMT and BERT-NMT on words with different frequencies in En-De"
| 模型(攻击概率) | F1值 | ||
| 低频词 | 中频词 | 高频词 | |
| NMT(p=0) | 31.6 | 40.5 | 53.0 |
| BERT-NMT(p=0) | 33.5 | 43.2 | 54.9 |
| NMT(p=0.5) | 20.1 | 26.1 | 40.7 |
| BERT-NMT(p=0.5) | 19.8 | 26.4 | 41.1 |
| [20] | ZHANG T , KISHORE V , WU F ,et al. BERTScore:evaluating text generation with BERT[C]// 8th International Conference on Learning Representations. 2020: 1-43. |
| [21] | CLINCHANT S , JUNG K W , NIKOULINA V . On the use of BERT for neural machine translation[C]// Proceedings of the 3rd Workshop on Neural Generation and Translation. 2019: 108-117. |
| [22] | ROTHE S , NARAYAN S , SEVERYN A . Leveraging pre-trained checkpoints for sequence generation tasks[J]. Transactions of the Association for Computational Linguistics, 2020,8: 264-280. |
| [23] | GUO J , ZHANG Z , XU L ,et al. Incorporating bert into parallel sequence decoding with adapters[J]. Advances in Neural Information Processing Systems. 2020,33: 10843-10854. |
| [24] | GUO J , ZHANG Z , XU L ,et al. Adaptive adapters:an efficient way to incorporate BERT into neural machine translation[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2021,29: 1740-1751. |
| [25] | XU H , VAN DURME B , MURRAY K . BERT,mBERT,or BiBERT? a study on Contextualized Embeddings for Neural Machine Translation[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 6663-6675. |
| [26] | CONNEAU A , LAMPLE G . Cross-lingual language model pretraining[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. 2019: 7059-7069. |
| [27] | SONG K , TAN X , QIN T ,et al. MASS:masked sequence to sequence pre-training for language generation[C]// International Conference on Machine Learning. 2019: 5926-5936. |
| [28] | LIU Y , GU J , GOYAL N ,et al. Multilingual denoising pre-training for neural machine translation[J]. Transactions of the Association for Computational Linguistics, 2020,8: 726-742. |
| [29] | LIN Z , PAN X , WANG M ,et al. Pre-training multilingual neural machine translation by leveraging alignment information[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 2649-2663. |
| [30] | PAN X , WANG M , WU L ,et al. Contrastive learning for many-to-many multilingual neural machine translation[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. 2021: 244-258. |
| [31] | LI P , LI L , ZHANG M ,et al. Universal conditional masked language pre-training for neural machine translation[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. 2022: 6379-6391. |
| [32] | BELINKOV Y , BISK Y . Synthetic and natural noise both break neural machine translation[C]// 6th International Conference on Learning Representations. 2018: 1-13. |
| [33] | CHENG Y , TU Z , MENG F ,et al. Towards robust neural machine translation[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2018: 1756-1766. |
| [34] | VAIBHAV V , SINGH S , STEWART C ,et al. Improving robustness of machine translation with synthetic noise[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. 2019: 1916-1920. |
| [35] | MICHEL P , LI X , NEUBIG G ,et al. On evaluation of adversarial perturbations for sequence-to-sequence models[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. 2019: 3103-3114. |
| [36] | SATO M , SUZUKI J , KIYONO S . Effective adversarial regularization for neural machine translation[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 204-210. |
| [37] | CHENG Y , JIANG L , MACHEREY W ,et al. AdvAug:robust adversarial augmentation for neural machine translation[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 5961-5970. |
| [38] | SENNRICH R , HADDOW B , BIRCH A . Neural machine translation of rare words with subword units[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. 2016: 1715-1725. |
| [39] | MICHEL P , NEUBIG G . MTNT:a testbed for machine translation of noisy text[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 543-553. |
| [40] | WU Z , WU L , MENG Q ,et al. UniDrop:a simple yet effective technique to improve transformer without extra cost[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. 2021: 3865-3878. |
| [41] | CHENG Y , WANG W , JIANG L ,et al. Self-supervised and supervised joint training for resource-rich machine translation[C]// International Conference on Machine Learning. 2021: 1825-1835. |
| [42] | AGIRRE E , CER D , DIAB M ,et al. SemEval-2012 task 6:A pilot on semantic textual similarity[C]// Proceedings of the Main Conference and the Shared Task,and Volume 2:Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012). 2012: 385-393. |
| [1] | DEVLIN J , CHANG M W , LEE K ,et al. BERT:pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. 2019: 4171-4186. |
| [2] | ZHU J , XIA Y , WU L ,et al. Incorporating BERT into neural machine translation[C]// 8th International Conference on Learning Representations. 2020: 1-16. |
| [3] | BAZIOTIS C , HADDOW B , BIRCH A . Language model prior for low-resource neural machine translation[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 7622-7634. |
| [4] | AN T , SONG J , LIU W . Incorporating pre-trained model into neural machine translation[C]// 2021 4th International Conference on Artificial Intelligence and Big Data (ICAIBD). 2021: 212-216. |
| [5] | LIU X , WANG L , WONG D F ,et al. On the complementarity between pre-training and back-translation for neural machine translation[C]// Findings of the Association for Computational Linguistics:EMNLP 2021. 2021: 2900-2907. |
| [6] | PETERS M E , NEUMANN M , ZETTLEMOYER L ,et al. Dissecting contextual word embeddings:architecture and representation[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 1499-1509. |
| [7] | JAWAHAR G , SAGOT B , SEDDAH D . What does BERT learn about the structure of language[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3651-3657. |
| [8] | TENNEY I , DAS D , PAVLICK E . BERT rediscovers the classical NLP pipeline[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 4593-4601. |
| [9] | TENNEY I , XIA P , CHEN B ,et al. What do you learn from context? Probing for sentence structure in contextualized word representations[C]// 7th International Conference on Learning Representations. 2019: 1-17. |
| [10] | HEWITT J , MANNING C D . A structural probe for finding syntax in word representations[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. 2019: 4129-4138. |
| [11] | GOLDBERG Y . Assessing BERT's syntactic abilities[J]. arXiv preprint arXiv:1901.05287, 2019. |
| [43] | AGIRRE E , CER D , DIAB M ,et al. * SEM 2013 shared task:semantic textual similarity[C]// Proceedings of the Main Conference and the shared task:Semantic Textual Similarity. 2013: 32-43. |
| [44] | AGIRRE E , BANEA C , CARDIE C ,et al. Multilingual semantic Textual Similarity[C]// Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). 2014: 81-91. |
| [45] | AGIRRE E , BANEA C , CARDIE C ,et al. Semantic textual similarity,english,spanish and pilot on interpretability[C]// Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015). 2015: 252-263. |
| [46] | AGIRRE E , BANEA C , CER D ,et al. Semantic Textual Similarity,Monolingual and Cross-Lingual Evaluation[C]// Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). 2016: 497-511. |
| [47] | QI P , ZHANG Y , ZHANG Y ,et al. Stanza:a python natural language processing toolkit for many human languages[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics:System Demonstrations. 2020: 101-108. |
| [48] | CONNEAU A , KIELA D . SentEval:an evaluation toolkit for universal sentence representations[C]// Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). 2018: 1699-1704. |
| [49] | WOLF T , DEBUT L , SANH V ,et al. Transformers:state-of-the-art natural language processing[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing:System Demonstrations. 2020: 38-45. |
| [50] | OTT M , EDUNOV S , BAEVSKI A ,et al. Fairseq:a fast,extensible toolkit for sequence modeling[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). 2019: 48-53. |
| [51] | KINGMA D P , BA J . Adam:a method for stochastic optimization[C]// 3rd International Conference on Learning Representations. 2015: 1-15. |
| [52] | POST M . A call for clarity in reporting BLEU scores[C]// Proceedings of the Third Conference on Machine Translation:Research Papers. 2018: 186-191. |
| [53] | OTT M , AULI M , GRANGIER D ,et al. Analyzing uncertainty in neural machine translation[C]// International Conference on Machine Learning. 2018: 3956-3965. |
| [12] | SUNDARARAMAN D , SUBRAMANIAN V , WANG G ,et al. Syntax-infused transformer and bert models for machine translation and natural language understanding[J]. arXiv preprint arXiv:1911.06156, 2019. |
| [13] | WENG R , YU H , HUANG S ,et al. Acquiring knowledge from pre-trained model to neural machine translation[C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2020: 9266-9273. |
| [14] | YANG J , WANG M , ZHOU H ,et al. Towards making the most of bert in neural machine translation[C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2020: 9378-9385. |
| [15] | SHAVARANI H S , SARKAR A . Better neural machine translation by extracting linguistic information from BERT[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. 2021: 2772-2783. |
| [16] | HAUSER J , MENG Z , PASCUAL D ,et al. BERT is robust! a case against synonym-based adversarial examples in text classification[J]. arXiv preprint arXiv:2109.07403, 2021. |
| [17] | VASWANI A , SHAZEER N , PARMAR N ,et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010. |
| [18] | CONNEAU A , KRUSZEWSKI G , LAMPLE G ,et al. What you can cram into a single $ &!#* vector:probing sentence embeddings for linguistic properties[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). 2018: 2126-2136. |
| [19] | PAPINENI K , ROUKOS S , WARD T ,et al. Bleu:a method for automatic evaluation of machine translation[C]// Proceedings of the 40th annual Meeting of the Association for Computational Linguistics. 2002: 311-318. |
| [54] | NEUBIG G , DOU Z Y , HU J ,et al. compare-mt:a tool for holistic comparison of language generation systems[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). 2019: 35-41. |
| [1] | 张明英, 华冰, 张宇光, 李海东, 郑墨泓. 基于鸽群的鲁棒强化学习算法[J]. 网络与信息安全学报, 2022, 8(5): 66-74. |
| [2] | 林点, 潘理, 易平. 面向图像识别的卷积神经网络鲁棒性研究进展[J]. 网络与信息安全学报, 2022, 8(3): 111-122. |
| [3] | 王鹏程, 郑海斌, 邹健飞, 庞玲, 李虎, 陈晋音. 面向商用活体检测平台的鲁棒性评估[J]. 网络与信息安全学报, 2022, 8(1): 180-189. |
| [4] | 石灏苒, 吉立新, 刘树新, 王庚润. 基于半局部结构的异常连边识别算法[J]. 网络与信息安全学报, 2022, 8(1): 63-72. |
| [5] | 王正龙, 张保稳. 生成对抗网络研究综述[J]. 网络与信息安全学报, 2021, 7(4): 68-85. |
| [6] | 陈晋音, 张敦杰, 黄国瀚, 林翔, 鲍亮. 面向图神经网络的对抗攻击与防御综述[J]. 网络与信息安全学报, 2021, 7(3): 1-28. |
| [7] | 吴奇,陈鸿昶. 低故障恢复开销的软件定义网络控制器布局算法[J]. 网络与信息安全学报, 2020, 6(6): 97-104. |
| [8] | 谢博,申国伟,郭春,周燕,于淼. 基于残差空洞卷积神经网络的网络安全实体识别方法[J]. 网络与信息安全学报, 2020, 6(5): 126-138. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||