

Telecommunications Science ›› 2021, Vol. 37 ›› Issue (2): 82-98.doi: 10.11959/j.issn.1000-0801.2021031
• Research and Development • Previous Articles Next Articles
Qiuyang GU1, Chunhua JU2, Gongxing WU2
Revised:2021-01-30
Online:2021-02-20
Published:2021-02-01
Supported by:CLC Number:
Qiuyang GU, Chunhua JU, Gongxing WU. Fusion of auto encoders and multi-modal data based video recommendation method[J]. Telecommunications Science, 2021, 37(2): 82-98.
"
| 参数符号 | 参数定义 |
| 在推荐框架中使用的第k种项目模态,即本文中的文本模态和视觉模态 | |
| j项目在 | |
| U ,V | 分别表示框架中的用户集和项目集 |
| u ,v | 分别表示框架中的任意用户和项目 |
| m ,n | 分别表示数据集中的用户数量和项目数量 |
| 表示所有用户偏好/项目偏好对的矩阵 | |
| ru ,v | 用户u给予项目v的评分 |
| λ ,β | 正则化系数 |
| α | 用于协同和模态信息的平衡参数 |
| 项目相似矩阵 | |
| 聚集系数矩阵 | |
| 融合k个原始项目模态后的项目表示矩阵 | |
| L (*) | 自编码器的损耗函数 |
| φ (*) | 自编码器的激活函数 |
| W | 用于自编码器神经网络结构的权重 |
| b | 用于自编码器神经网络结构的偏权向量 |
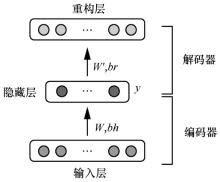
"
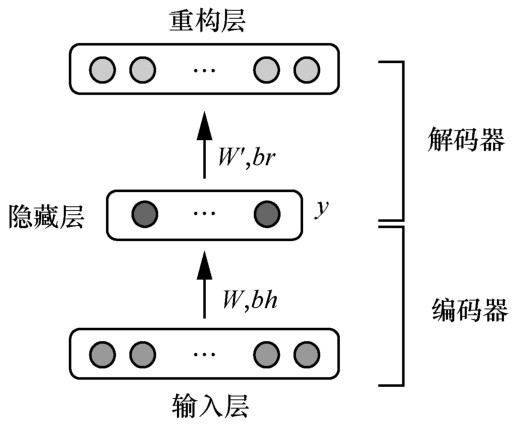
"

"
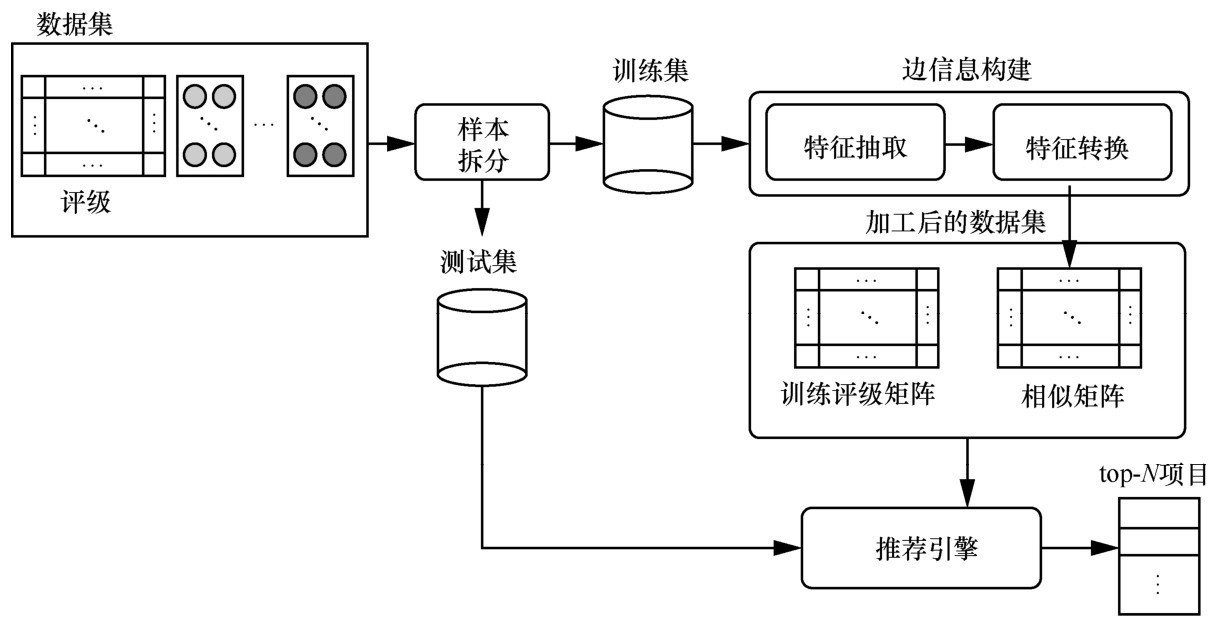
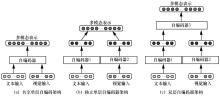
"
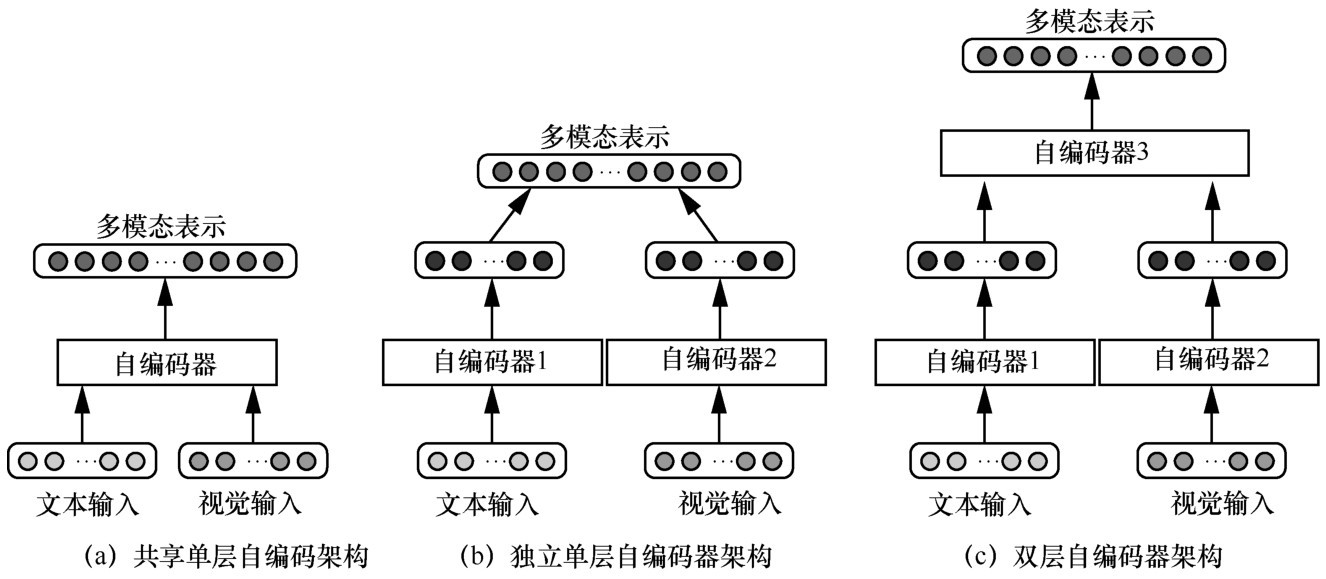
"
| 数据集名称 | 视频数量 | 用户数量 | 评级数量 | 帧数/视频 | 字数/视频 |
| MovieLens-1M | 3 582 | 6 383 | 1 023 839 | 2 943 | 24 |
| MovieLens-10M | 8 923 | 75 124 | 11 293 834 | 2 856 | 21 |
| 豆瓣 | 2 445 | 2 694 | 601 543 | 1 933 | 17 |
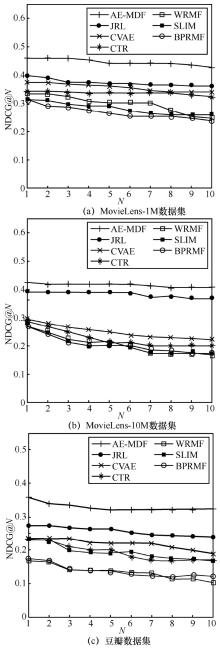
"

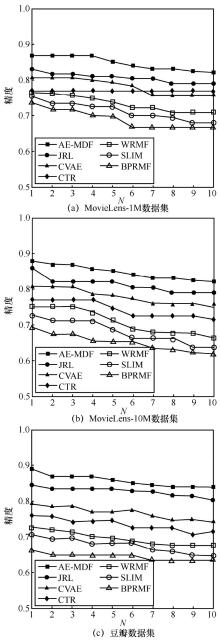
"
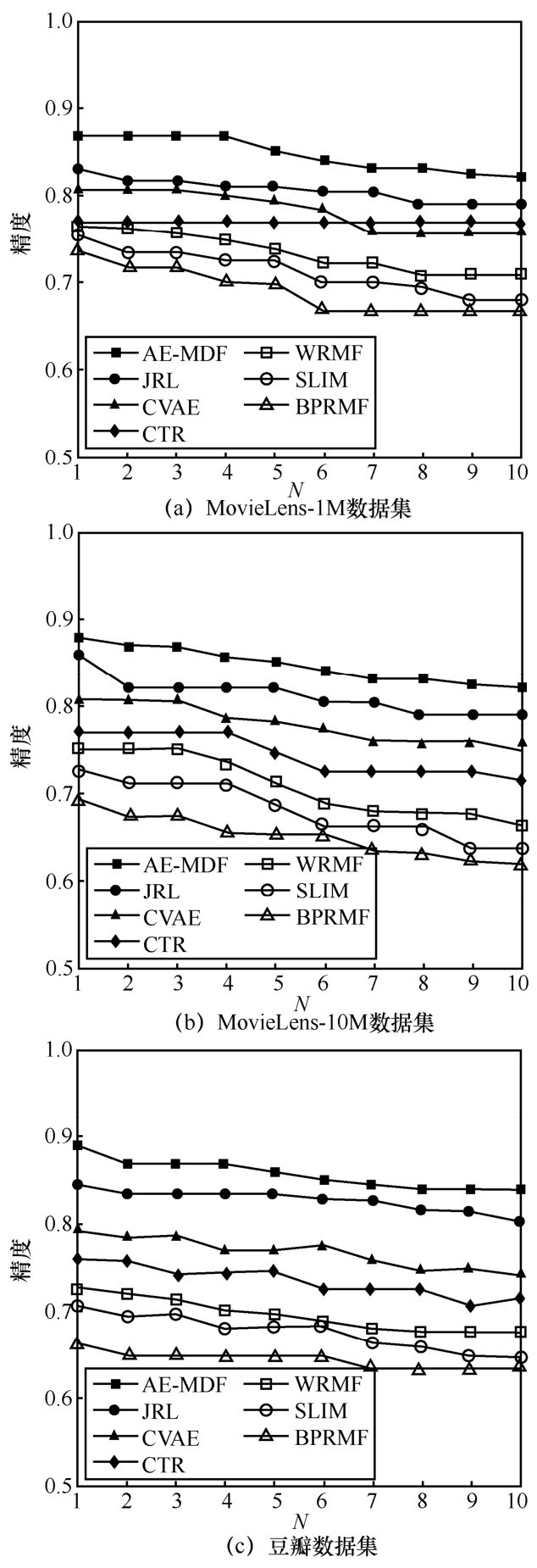
"
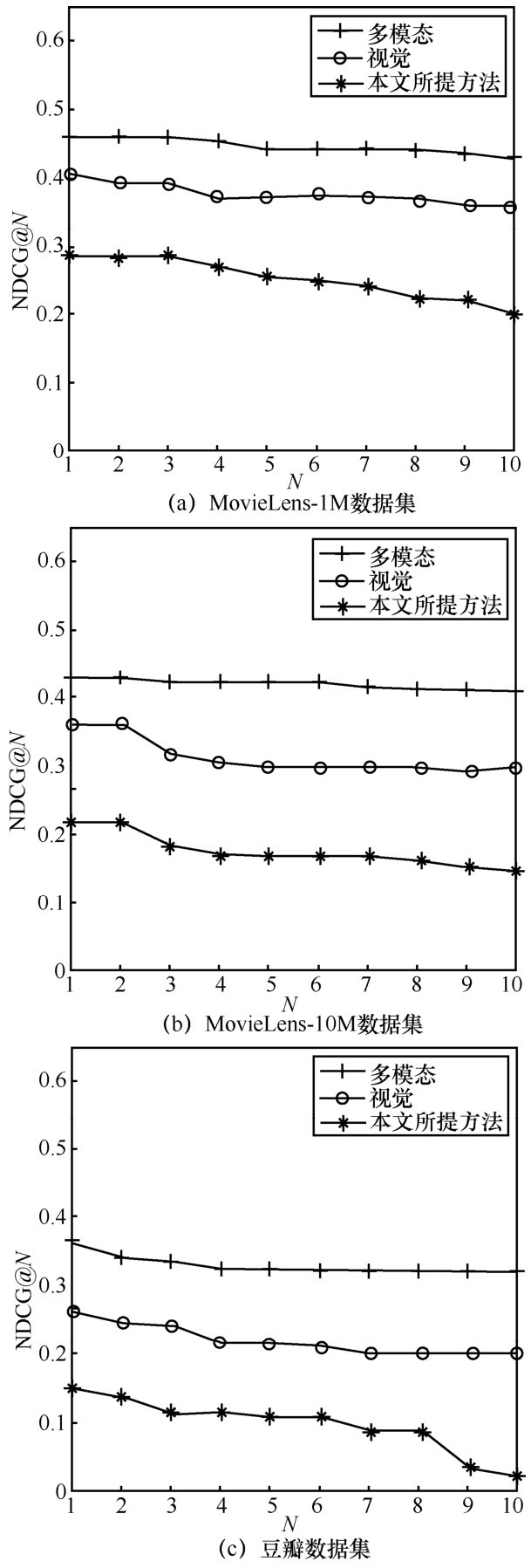

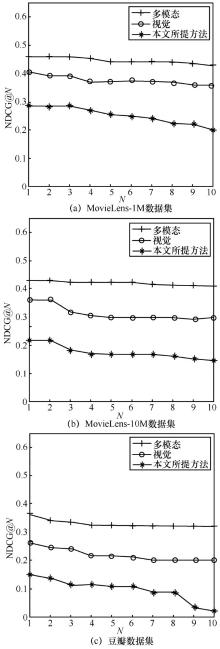
"
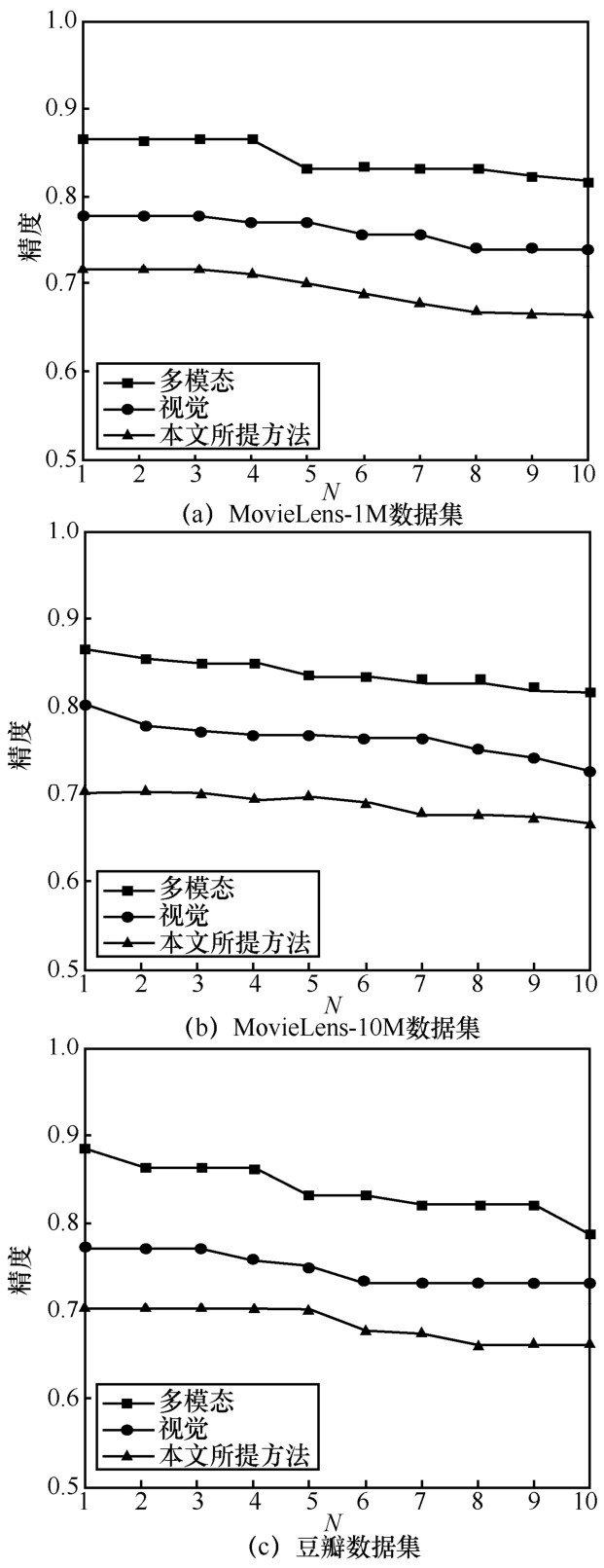
"
| 融合策略 | MovieLens-1M数据集 | MovieLens-10M数据集 | 豆瓣数据集 | ||||||||
| 文本 | 视觉 | 多模态 | 文本 | 视觉 | 多模态 | 文本 | 视觉 | 多模态 | |||
| NOAE | 0.153 | 0.224 | 0.228 | 0.124 | 0.238 | 0.237 | 0.001 | 0.231 | 0.239 | ||
| UAE | 0.182 | 0.352 | 0.369 | 0.139 | 0.001 | 0.192 | 0.211 | ||||
| DAE | 0.104 | 0.279 | 0.342 | 0.127 | 0.273 | 0.273 | 0.001 | 0.179 | 0.228 | ||
| SAE | 0.285 | 0.319 | |||||||||
| 注:加粗项为每列最佳项。 | |||||||||||

"
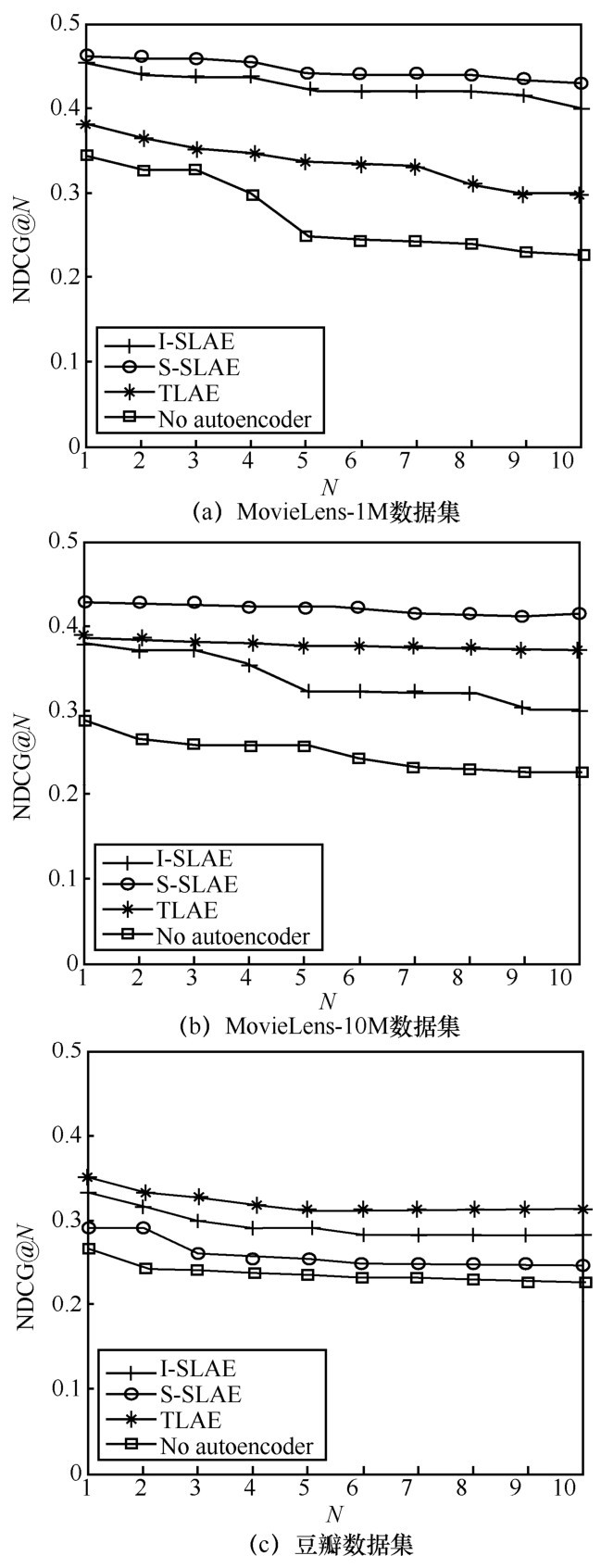
| [1] | BOBADILLA J , ORTEGA F , HERNANDO A ,et al. Recom-mender systems survey[J]. Knowledge-based systems, 2013(46): 109-132. |
| [2] | HU Y , KOREN Y , VOLINSKY C . Collaborative filtering for implicit feedback datasets[C]// Proceedings of 2008 Eighth IEEE International Conference on Data Mining. Piscataway:IEEE Press, 2008: 263-272. |
| [3] | LI Z , PENG J Y , GENG G H ,et al. Video recommendation based on multi-modal information and multiple kernel[J]. Mul-timedia Tools and Applications, 2015,74(13): 4599-4616. |
| [4] | NING X , KARYPIS G . Slim:sparse linear methods for top-n recommender systems[C]// Proceedings of 2011 IEEE 11th In-ternational Conference on Data Mining. Piscataway:IEEE Press, 2011: 497-506. |
| [5] | RENDLE S , FREUDENTHALER C , GANTNER Z ,et al. Bpr:Bayesian personalized ranking from implicit feedback.UAI’09[J]. Arlington,Virginia,United States, 2009: 452-461. |
| [6] | WANG C , BLEI D M . Collaborative topic modeling for re-commending scientific articles[C]// Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Dis-covery and Data Mining. New York:ACM Press, 2011: 448-456. |
| [7] | KABBUR S , NING X , KARYPIS G . Fism:factored item simi-larity models for top-N recommender systems[C]// Proceedings of the 19th ACM SIGKDD International Conference on Know-ledge Discovery and Data Mining. New York:ACM Press, 2013: 659-667. |
| [8] | DESHPANDE M , KARYPIS G . Item-based top-n recommenda-tion algorithms[J]. ACM Transactions on Information Systems, 2004,22(1): 143-177. |
| [9] | NING X , KARYPIS G . Sparse linear methods with side information for top-N recommendations[C]// Proceedings of the Sixth ACM Conference on Recommender Systems. New York:ACM Press, 2012: 155-162. |
| [10] | 任永功, 杨柳, 刘洋 . 基于热扩散影响力传播的社交网络个性化推荐算法[J]. 模式识别与人工智能, 2019,32(8): 746-757. |
| REN Y G , YANG L , LIU Y . Heat diffusion influence propaga-tion based personalized recommendation algorithm for social network[J]. Pattern Recognition and Artificial Intelligence, 2019,32(8): 746-757. | |
| [11] | RUMELHART D E , HINTON G E , WILLIAMS R J . Learning representations by back-propagating errors[J]. Nature, 1986,323(6088): 533-536. |
| [12] | DAVIDSON J , LIEBALD B , LIU J ,et al. The YouTube video recommendation system[C]// Proceedings of the Fourth ACM Conference on Recommender Systems. New York:ACM Press, 2010: 293-296. |
| [13] | ZHOU R , KHEMMARAT S , GAO L . The impact of YouTube recommendation system on video views[C]// Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement. New York:ACM Press, 2010: 404-410. |
| [14] | LINDEN G , SMITH B , YORK J.Amazon . com recommenda-tions:Item-to-item collaborative filtering[J]. IEEE Internet Computing, 2003,7(1): 76-80. |
| [15] | AHMED M , IMTIAZ M T , KHAN R . Movie recommendation system using clustering and pattern recognition net-work[C]// Proceedings of 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC). Piscata-way:IEEE Press, 2018: 143-147. |
| [16] | BEEL J , GIPP B , LANGER S ,et al. paper recommender sys-tems:a literature survey[J]. International Journal on Digital Li-braries, 2016,17(4): 305-338. |
| [17] | BOBADILLA J , HERNANDO A , ORTEGA F ,et al. Collabora-tive filtering based on significances[J]. Information Sciences, 2012,185(1): 1-17. |
| [18] | LAO N , COHEN W W . Relational retrieval using a combination of path-constrained random walks[J]. Machine Learning, 2010,81(1): 53-67. |
| [19] | NASCIMENTO C , LAENDER A H F , DA SILVA A S ,et al. A source independent framework for research paper recommenda-tion[C]// Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries. New York:ACM Press, 2011: 297-306. |
| [20] | KIM H N , JI A T , HA I ,et al. Collaborative filtering based on collaborative tagging for enhancing the quality of recommenda-tion[J]. Electronic Commerce Research and Applications, 2010,9(1): 73-83. |
| [21] | YANG C , CHEN X , LIU L ,et al. A hybrid movie recommenda-tion method based on social similarity and item attributes[C]// Proceedings of International Conference on Sensing and Imag-ing. Heidelberg:Springer, 2018: 275-285. |
| [22] | CHRISTAKOU C , VRETTOS S , STAFYLOPATIS A . A hybrid movie recommender system based on neural networks[J]. In-ternational Journal on Artificial Intelligence Tools, 2007,16(5): 771-792. |
| [23] | BEUTEL A , COVINGTON P , JAIN S ,et al. Latent cross:mak-ing use of context in recurrent recommender sys-tems[C]// Proceedings of the Eleventh ACM International Con-ference on Web Search and Data Mining. New York:ACM Press, 2018: 46-54. |
| [24] | 黄立威, 江碧涛, 吕守业 ,等. 基于深度学习的推荐系统研究综述[J]. 计算机学报, 2018,41(7): 1619-1647. |
| HUANG L W , JIANG B T , LV S Y ,et al. A review of recom-mendation Systems based on deep learning[J]. Journal of Com-puter Science, 2018,41(7): 1619-1647. | |
| [25] | COVINGTON P , ADAMS J , SARGIN E . Deep neural networks for youtube recommendations[C]// Proceedings of the 10th ACM Conference on Recommender Systems. New York:ACM Press, 2016: 191-198. |
| [26] | FAN Y , WANG Y , YU H ,et al. Movie recommendation based on visual features of trailers[C]// Proceedings of International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing. Heidelberg:Springer, 2017: 242-253. |
| [27] | CHENG H T , KOC L , HARMSEN J ,et al. Wide & deep learning for recommender systems[C]// Proceedings of the 1st Workshop on Deep Learning for Recommender Systems.[S.l.:s.n.], 2016: 7-10. |
| [28] | ZHANG Y , AI Q , CHEN X ,et al. Joint representation learning for top-N recommendation with heterogeneous information sources[C]// Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. New York:ACM Press, 2017: 1449-1458. |
| [29] | LI Z , PENG J Y , GENG G H ,et al. Video recommendation based on multi-modal information and multiple kernel[J]. Multimedia Tools and Applications, 2015,74(13): 4599-4616. |
| [30] | 王娜, 何晓明, 刘志强 ,等. 一种基于用户播放行为序列的个性化视频推荐策略[J]. 计算机学报, 2020,43(1): 123-135. |
| WANG N , HE X M , LIU Z Q ,et al. Personalized video recom-mendation strategy based on user’s playback behavior se-quence[J]. Journal of Computer Science, 2020,43(1): 123-135. | |
| [31] | 苏赋, 吕沁, 罗仁泽 . 基于深度学习的图像分类研究综述[J]. 电信科学, 2019,35(11): 58-74. |
| SU F , LV Q , LUO R Z . Review of image classification based on deep learning[J]. Telecommunications Science, 2019,35(11): 58-74. | |
| [32] | FELIPE L A , CONCEIC A L C , Pádua A L A C ,et al. Multi-modal data fusion framework based on autoencoders for top-N recommender systems[J]. Applied Intelligence, 2019,49(9) 3267-3282. |
| [33] | CREMONESI P , KOREN Y , TURRIN R . Performance of re-commender algorithms on top-N recommendation tasks[C]// Proceedings of the fourth ACM conference on Recommender systems. New York:ACM Press, 2010: 39-46. |
| [34] | LECUN Y , BOSER B , DENKER J S ,et al. Backpropagation applied to handwritten zip code recognition[J]. Neural computa-tion, 1989,1(4): 541-551. |
| [35] | NASCIMENTO G , LARANIEIRA C , BRAZ V ,et al. A robust indoor scene recognition method based on sparse representa-tion[C]// Proceedings of Iberoamerican Congress on Pattern Recognition. Heidelberg:Springer, 2017: 408-415. |
| [36] | DEFFERRARD M , BRESSON X , VANDERGHEYNST P . Convolutional neural networks on graphs with fast localized spectral filtering[C]// Advances in Neural Information Processing Systems.[S.l.:s.n.], 2016: 3844-3852. |
| [37] | YANG J , NGUYEN M N , SAN P P ,et al. Deep convolutional neural networks on multichannel time series for human activity recognition[C]// Proceedings of Twenty-Fourth International Joint Conference on Artificial Intelligence.[S.l.:s.n.], 2015: 3995-4001. |
| [38] | CUNNINGHAM J P , BYRON M Y . Dimensionality reduction for large-scale neural recordings[J]. Nature Neuroscience, 2014,17(11): 1500-1509. |
| [39] | BAEZA-YATES R , RIBEIRO-NETO B . Modern information retrieval[M]. New York: ACM Press, 1999. |
| [40] | SZEGEDY C , VANHOUCKE V , IOFFE S ,et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 2818-2826. |
| [41] | RUSSAKOVSKY O , DENG J , SU H ,et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015,115(3): 211-252. |
| [42] | LE Q , MIKOLOY T . Distributed representations of sentences and documents[C]// Proceedings of International Conference on Machine Learning.[S.l.:s.n.], 2014: 1188-1196. |
| [43] | JIA Y , SHELHAMER E , DONAHUE J ,et al. Caffe:Convolutional architecture for fast feature embedding[C]// Proceedings of the 22nd ACM International Conference on Multimedia. New York:ACM Press, 2014: 675-678. |
| [44] | 胡春华, 童小芹, 梁伟 . 基于信任和不信任关系的实值受限玻尔兹曼机推荐算法[J]. 系统工程理论与实践, 2019,39(7): 1817-1830. |
| HU C H , TONG X X , LIANG W . The real-value restricted Boltzmann machine recommendation algorithm based on trust-distrust relationship[J]. Systems Engineering-Theory &Practice, 2019,39(7): 1817-1830. | |
| [45] | 肖云鹏, 孙华超, 戴天骥 ,等. 一种基于云模型的社交网络推荐系统评分预测方法[J]. 电子学报, 2018,46(7): 1762-1767. |
| XIAO Y P , SUN H C , DAI T J ,et al. A rating prediction method based on cloud model in social recommendation system[J]. Acta Electronica Sinica, 2018,46(7): 1762-1767. |
| [1] | Huahua CHEN, Zhe CHEN. Research on anomaly detection algorithm based on sparse variational autoencoder using spike and slab prior [J]. Telecommunications Science, 2022, 38(12): 65-77. |
| [2] | Huahua CHEN, Zhe CHEN, Chunsheng GUO, Na YING, Xueyi YE, Jianwu ZHANG. Anomaly detection algorithm based on Gaussian mixture variational auto encoder network [J]. Telecommunications Science, 2021, 37(4): 54-61. |
| [3] | Wenbin CHENG,Lei DU,Yiyi LIU. Design of home fire detection system based on wireless multi-sensor data fusion [J]. Telecommunications Science, 2017, 33(9): 174-181. |
| [4] | Fushun Ke,Xiaohui Yao. Collaborating Filtering Method Based on Multiple Data Sources [J]. Telecommunications Science, 2015, 31(7): 86-89. |
| [5] | Yongmei Gao,Chunhua Ju,Fuguang Bao. The telecommunications customer service model based on big data and data fusion strategy research [J]. Telecommunications Science, 2014, 30(7): 62-69. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||