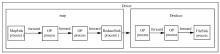
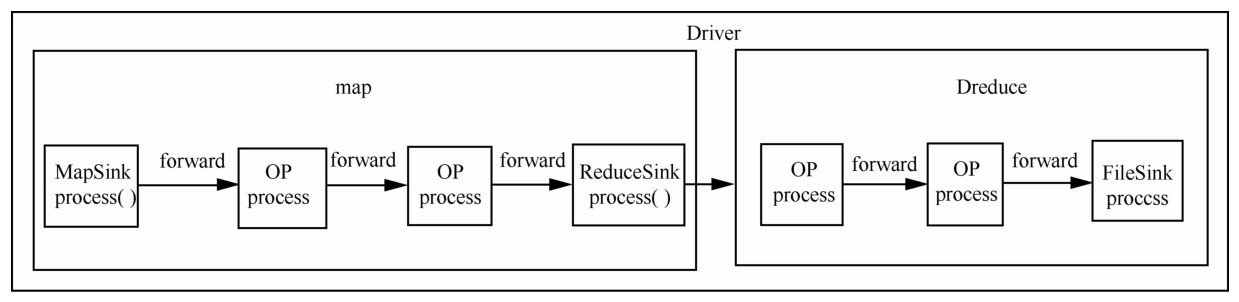
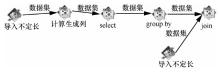
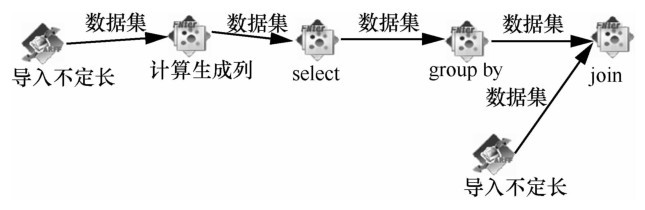
| 1 |
Dean J , Ghemawat S . MapReduce:simplified data processing on large clusters . Proceedings of the 6th Conference on Symposium on Opearting Systems Resign&Implementation , San Francisco, USA, 2004
|
| 2 |
Apache. Hive. , 2013
|
| 3 |
Chen S T . Cheetah:a high performance, custom data warehouse on top of MapReduce. Proceedings of the VLDB Endowment, 2010,3(1):1459~1468
|
| 4 |
Melnik S , Gubarev A , Long J J , et al. Dremel: interactive analysis of web-scale datasets. Communications of the ACM, 2011,54(6):114~123
|
| 5 |
Cloudera. Impala. ,
|
| 6 |
Olston C , Reed B , Srivastava U , et al. Pig Latin: a not-so-foreign language for data processing. Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, 2008: 1099~1110
|
| 7 |
IBM. JAQL. ,
|
| 8 |
Chambers C , Raniwala A , Perry F , et al. FlumeJava: easy, efficient data-parallel pipelines. ACM SIGPLAN Notices, 2010,45(6): 363~375
|
| 9 |
Cascading. , 2012
|
| 10 |
Horton Works. Tez. , 2013
|
| 11 |
Bu Y Y , Howe B , Balazinska M , et al. HaLoop: efficient iterative data processing on large clusters. Proceedings of the VLDB Endowment, 2010,3(1/2): 285~296
|
| 12 |
Bu Y Y , Ekanayake J , Li H , Zhang B J , et al. Twister: a runtime for iterative MapReduce. Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, Iuinois, 2010: 810~818
|