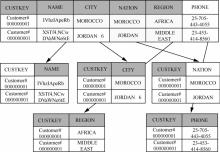
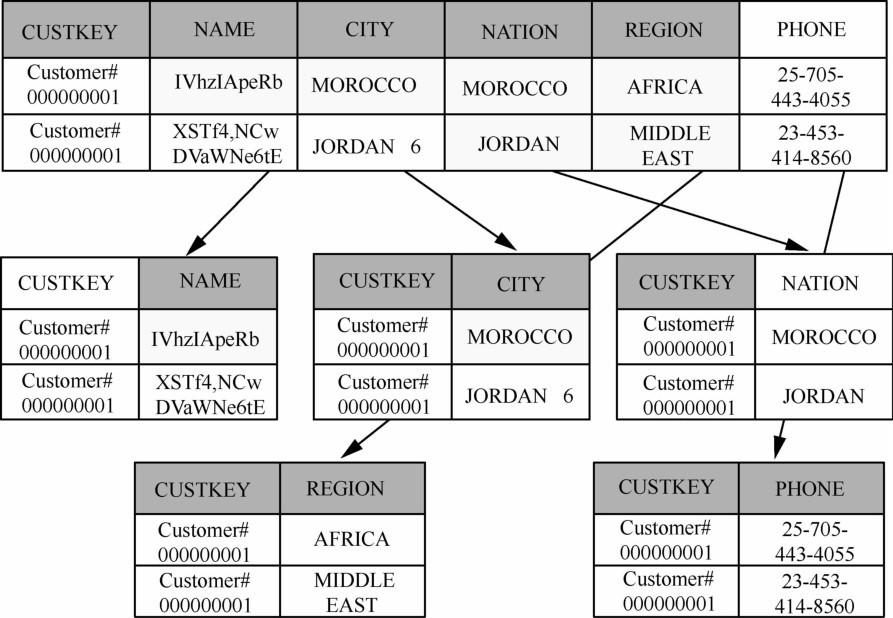
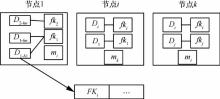
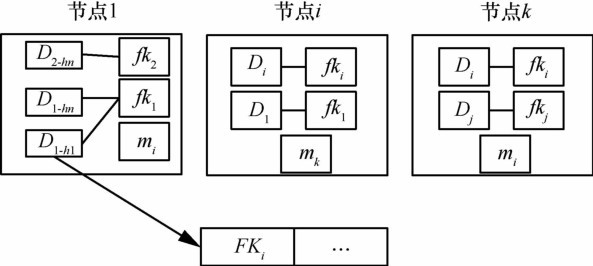
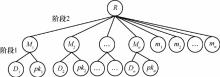
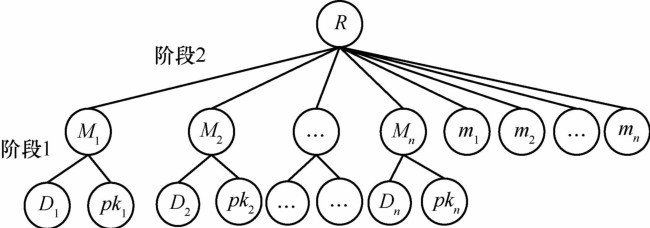
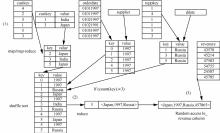
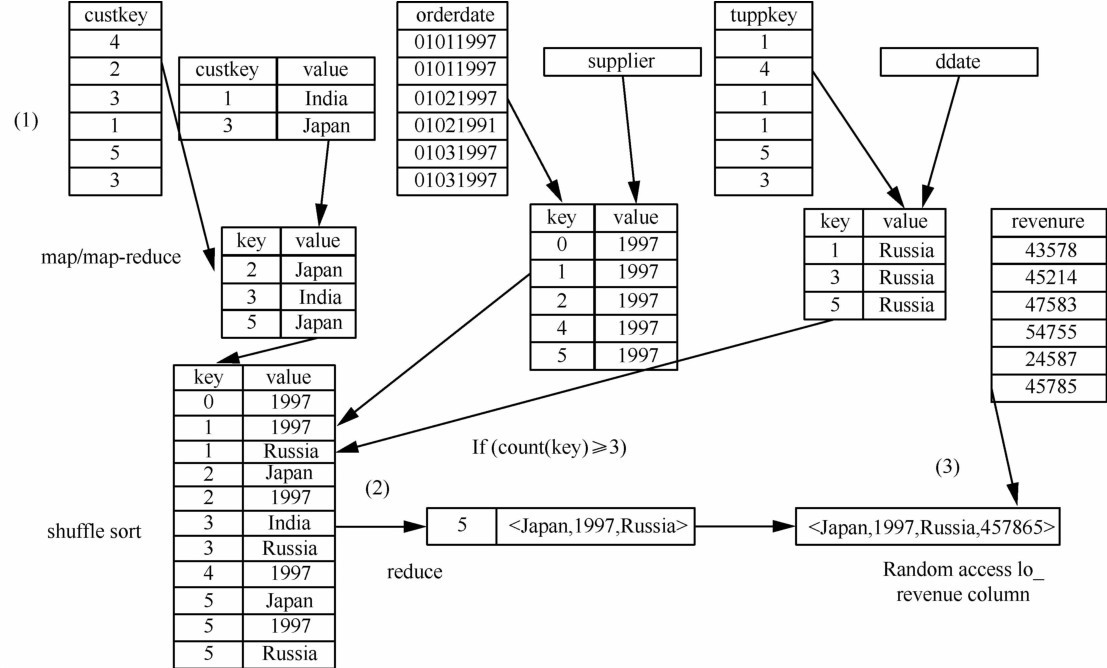
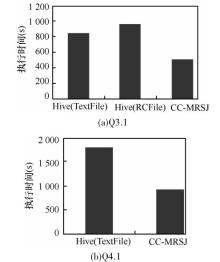
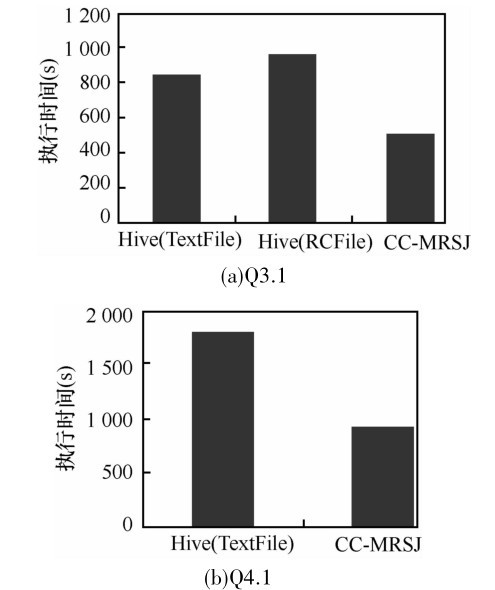
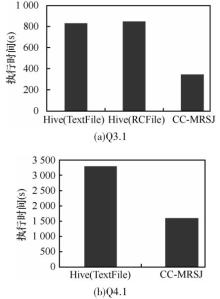
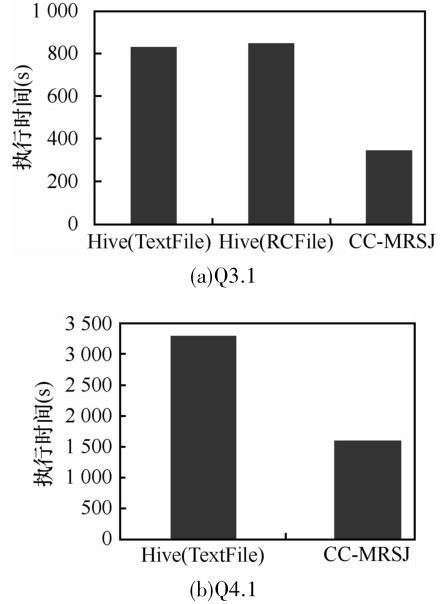
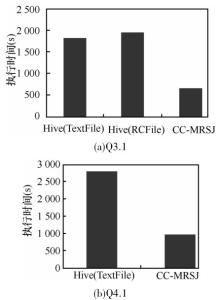
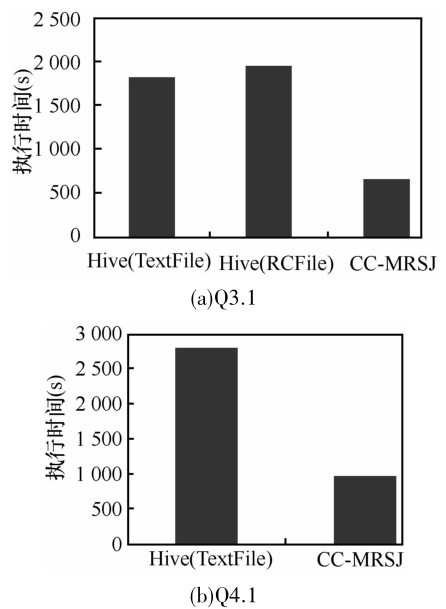
| 1 |
Dean J , Ghemawat S . MapReduce:simplified data processing on large clusters. Communications of the ACM, 2008(1)
|
| 2 |
Chang F , Dean J , Ghemawat S ,et al. Bigtable:a distributed storage system for structured data. ACM Transactions on Computer Systems, 2008(2)
|
| 3 |
Thusoo A , Sarma J S , Jain N ,et al. Hive-a warehousing solution over a MapReduce framework. Proceedings of the VLDB Endowment, 2009,2(2): 1626~1629
|
| 4 |
Gates A , Natkovich O , Chopra S ,et al. Srivastava,building a high level dataflow system on top of MapReduce:the pig experience. Proceedings of the VLDB Endowment, 2009,2(2): 1414~1425
|
| 5 |
Stonebraker M , Abadi D J , Batkin A ,et al. C-store:a column-oriented dbms. Proceedings of the 31st International Conference on Very Large Data Bases,Trondheim,Norway, 2005: 553~564
|
| 6 |
Abadi D J , Madden S , Hachem N . Column-stores vs row-stores:how different are they really. Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data,Vancouver, 2008: 967~980
|
| 7 |
Ailamaki A , DeWitt D J , Hill M D ,et al. Weaving relations for cache performance. Proceedings of the 27th International Conference on Very Large Data Bases,Roma, 2001: 169~180
|
| 8 |
Lee R , Yin H , Zheng S ,et al. RCFile:a fast and space-efficient data place-ment structure in MapReduce-based warehouse systems. ICDE 2011,Hannover,HGermany: 2001: 1199~1208
|
| 9 |
Floratou A , Patel J M , Shekita E J ,et al. Column-oriented storage techniques for MapReduce. Proceedings of the VLDB Endowment, 2011(7)
|
| 10 |
Lin Y T , Agrawal D , Chen C ,et al. Llama:leveraging columnar storage for scalable join processing in the MapReduce framework. Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data,Athens,Greece, 2011
|
| 11 |
Blanas S , Patel J M , Ercegovac V ,et al. A comparison of join algorithms for log processing in mapreduce. Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data Indiana,USA, 2010:975~986
|
| 12 |
Han H , Jung H S , Eom H S ,et al. Yeom:scatter-gather-merge:an efficient star-join query processing algorithm for data-parallel frameworks. Cluster Computing, 2011,14(2):183~197
|
| 13 |
Rao J , Ross K A . Cache conscious indexing for decision-support in main memory. Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data Indiana,USA, 2010:975~986
|
| 14 |
Brewer E A , . Towards robust distributed systems. Proceedings of the Nineteenth Annual ACM Symposium on Principles of Distributed Computing,Portland,Oregon, 2000
|
| 15 |
Zhang S B , Han J Z , Liu Z Y . Accelerating MapReduce with distributed memory cache. ICPADS 2009,Shenzhen,China, 2009:472~478
|
| 16 |
Shinnar A , Cunningham D , Saraswat V ,et al. M3R:increased performance for in-memory Hadoop jobs. Proceedings of the VLDB Endowment, 2012(5)
|
| 17 |
O'Neil P , O'Neil E , Chen X . The star schema benchmark,. SchemaB.PDF,Minneapdis, 2007
|
| 18 |
Apache Hadoop. , 2012
|
| 19 |
Lee R , Luo T , Huai Y ,et al. YSmart:Yet another SQL-to-MapReduce translator. Proceedings of the 31st International Conference on Minneapolis,MN,USA, 2011:25~36
|
| 20 |
Huai Y , Lee R , Zhang S ,et al. A matrix model for analyzing,optimizing and deploying software for big data analytics in distributed systems. Proceedings of the 2nd ACM Symposium on Cloud Computing,Cascais, 2011
|