

通信学报 ›› 2021, Vol. 42 ›› Issue (11): 121-132.doi: 10.11959/j.issn.1000-436x.2021186
陈天柱1,2,3, 李凤华1,2, 郭云川1,2, 李子孚1
修回日期:2021-10-09
出版日期:2021-11-25
发布日期:2021-11-01
作者简介:陈天柱(1987− ),男,河北秦皇岛人,博士,中国电子科技集团公司工程师,主要研究方向为自然语言处理基金资助:Tianzhu CHEN1,2,3, Fenghua LI1,2, Yunchuan GUO1,2, Zifu LI1
Revised:2021-10-09
Online:2021-11-25
Published:2021-11-01
Supported by:摘要:
针对现有标签缺失下多标签学习方案未能有效解决标签缺失的问题,提出了基于实例结构的不完备多标签学习方案,考虑实例特征和标签结构特点,利用数据标签向量几何相似度来补全缺失标签,利用加权排序来降低正关系学为负关系所带来的模型偏差,并利用低秩结构来俘获模型低秩结构。具体地,通过确保数据预测标签几何相似度与数据标签几何相似度的一致性来俘获数据流型结构;通过度量完备标签下和不完备标签下的排序损失来区分标签与实例的相关程度。实验结果表明,所提方案优于典型的标签缺失下的多标签学习方案,甚至在一些评估标准下其精度比最好对比方案提升了10%以上。
中图分类号:
陈天柱, 李凤华, 郭云川, 李子孚. 基于实例结构的不完备多标签学习[J]. 通信学报, 2021, 42(11): 121-132.
Tianzhu CHEN, Fenghua LI, Yunchuan GUO, Zifu LI. Instance structure based multi-label learning with missing labels[J]. Journal on Communications, 2021, 42(11): 121-132.

图1
模型流型正则和标签排序正则步骤"
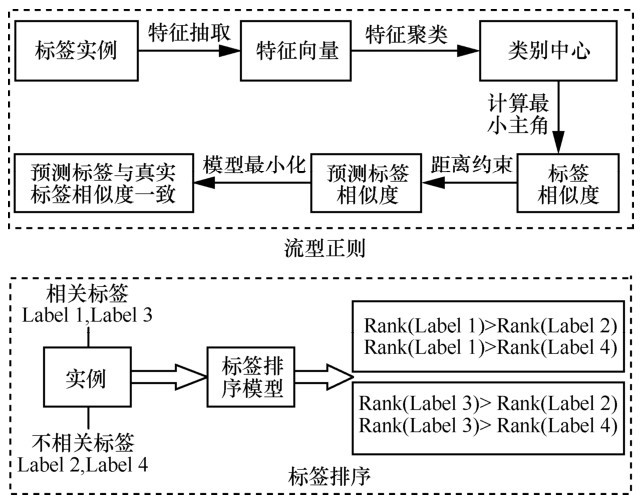
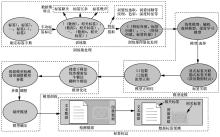
图2
标签标记流程"
表1
实验数据统计信息"
| 数据集 | 实例个数 | 特征维数 | 标签个数 | 数据类型 | 实例平均标签个数 | 领域 |
| Emotions | 593 | 72 | 6 | numeric | 1.869 | music |
| Scene | 2407 | 294 | 6 | numeric | 1.074 | image |
| Birds | 645 | 258 | 19 | numeric | 1.014 | audio |
| Mediamill | 43 907 | 120 | 101 | numeric | 4.376 | video |
| Delicious | 16 105 | 500 | 983 | nominal | 9.020 | text |
| NUS-WIDE-B | 269 648 | 128 | 81 | numeric | 1.869 | images |
表2
6个数据集上的Hamming Loss比较"
| 数据集 | BR | WSABIE | LEML | SLRM | ICVL | SLCR |
| Emotions | 0.2186 | 0.2648 | 0.2054 | 0.2096 | 0.2145 | 0.1125 |
| Scene | 0.1169 | 0.1322 | 0.1264 | 0.1158 | 0.1319 | 0.2079 |
| Birds | 0.0859 | 0.2858 | 0.1055 | 0.0875 | 0.0994 | 0.1257 |
| Mediamill | 0.0314 | 0.0331 | 0.0314 | 0.0315 | 0.0314 | 0.0311 |
| Delicious | 0.0181 | 0.0331 | 0.0181 | 0.0203 | 0.0667 | 0.0345 |
| NUS-WIDE-B | 0.0262 | 0.0250 | 0.0251 | 0.0250 | 0.0311 | 0.0260 |
表3
6个数据集上的Recall比较"
| 数据集 | BR | WSABIE | LEML | SLRM | ICVL | SLCR |
| Emotions | 0.5338 | 0.5859 | 0.5850 | 0.5503 | 0.5486 | 0.6411 |
| Scene | 0.5247 | 0.5447 | 0.5438 | 0.5113 | 0.5192 | 0.5665 |
| Birds | 0.3046 | 0.5429 | 0.3511 | 0.3206 | 0.3928 | 0.5248 |
| Mediamill | 0.4761 | 0.5142 | 0.5084 | 0.5024 | 0.4621 | 0.5633 |
| Delicious | 0.1193 | 0.1778 | 0.1097 | 0.1210 | 0.2571 | 0.2922 |
| NUS-WIDE-B | 0.1875 | 0.2350 | 0.2210 | 0.2228 | 0.1677 | 0.3078 |
表4
6个数据集上的F1-Measure比较"
| 数据集 | BR | WSABIE | LEML | SLRM | ICVL | SLCR |
| Emotions | 0.5731 | 0.6064 | 0.6206 | 0.5951 | 0.5607 | 0.6587 |
| Scene | 0.5258 | 0.5311 | 0.5366 | 0.5131 | 0.4969 | 0.5629 |
| Birds | 0.3189 | 0.2595 | 0.3357 | 0.3353 | 0.3744 | 0.4430 |
| Mediamill | 0.5929 | 0.6014 | 0.6102 | 0.6053 | 0.5456 | 0.6390 |
| Delicious | 0.1860 | 0.2436 | 0.1735 | 0.1863 | 0.2484 | 0.2942 |
| NUS-WIDE-B | 0.2328 | 0.2807 | 0.2657 | 0.2668 | 0.1830 | 0.3556 |
表5
6个数据集上的F1 macro比较"
| 数据集 | BR | WSABIE | LEML | SLRM | ICVL | SLCR |
| Emotions | 0.6153 | 0.5132 | 0.6527 | 0.6329 | 0.6275 | 0.6702 |
| Scene | 0.6139 | 0.5953 | 0.6051 | 0.6110 | 0.5826 | 0.6409 |
| Birds | 0.4158 | 0.2793 | 0.3915 | 0.4257 | 0.4268 | 0.4483 |
| Mediamill | 0.5486 | 0.5533 | 0.5663 | 0.5642 | 0.5419 | 0.5907 |
| Delicious | 0.1911 | 0.2213 | 0.1790 | 0.1755 | 0.1262 | 0.2654 |
| NUS-WIDE-B | 0.3043 | 0.3480 | 0.3310 | 0.3370 | 0.2592 | 0.3895 |
表6
6个数据集上的F1 micro比较"
| 数据集 | BR | WSABIE | LEML | SLRM | ICVL | SLCR |
| Emotions | 0.5313 | 0.5960 | 0.5865 | 0.5489 | 0.6072 | 0.6416 |
| Scene | 0.5135 | 0.5373 | 0.5350 | 0.5055 | 0.5867 | 0.5543 |
| Birds | 0.2625 | 0.1459 | 0.2502 | 0.2681 | 0.3138 | 0.3286 |
| Mediamill | 0.4194 | 0.4501 | 0.4504 | 0.4475 | 0.0443 | 0.4994 |
| Delicious | 0.1112 | 0.1694 | 0.1026 | 0.1123 | 0.0587 | 0.2856 |
| NUS-WIDE-B | 0.1923 | 0.2328 | 0.2169 | 0.2216 | 0.0377 | 0.2899 |

图3
Mediamill数据集上预测效果对比"
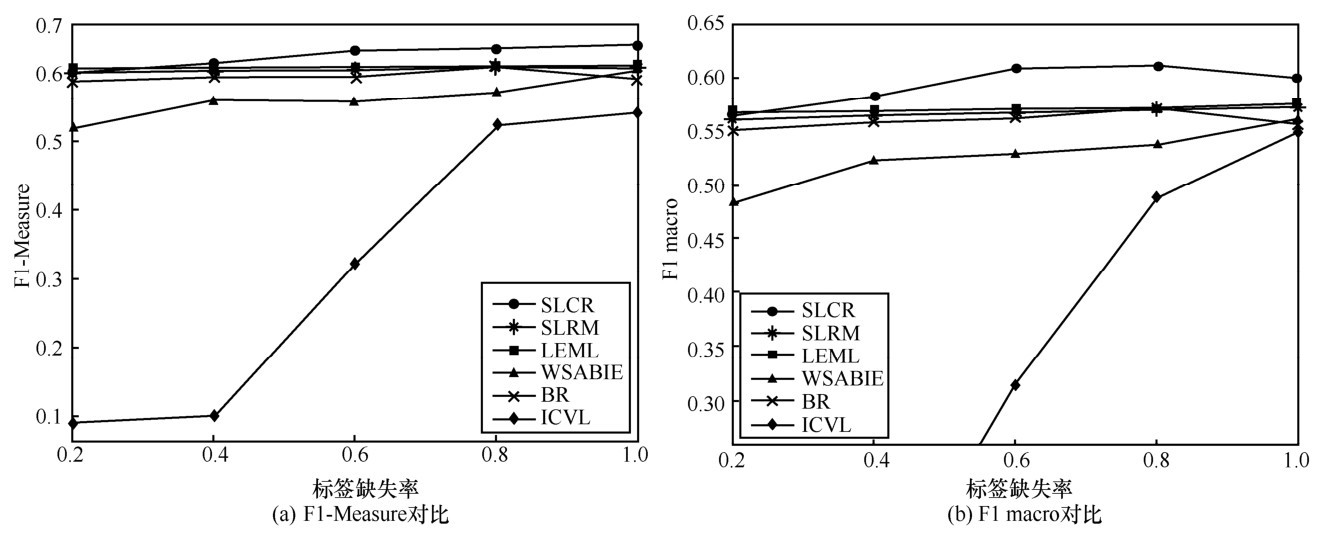

图4
Emotions数据集上预测效果对比"
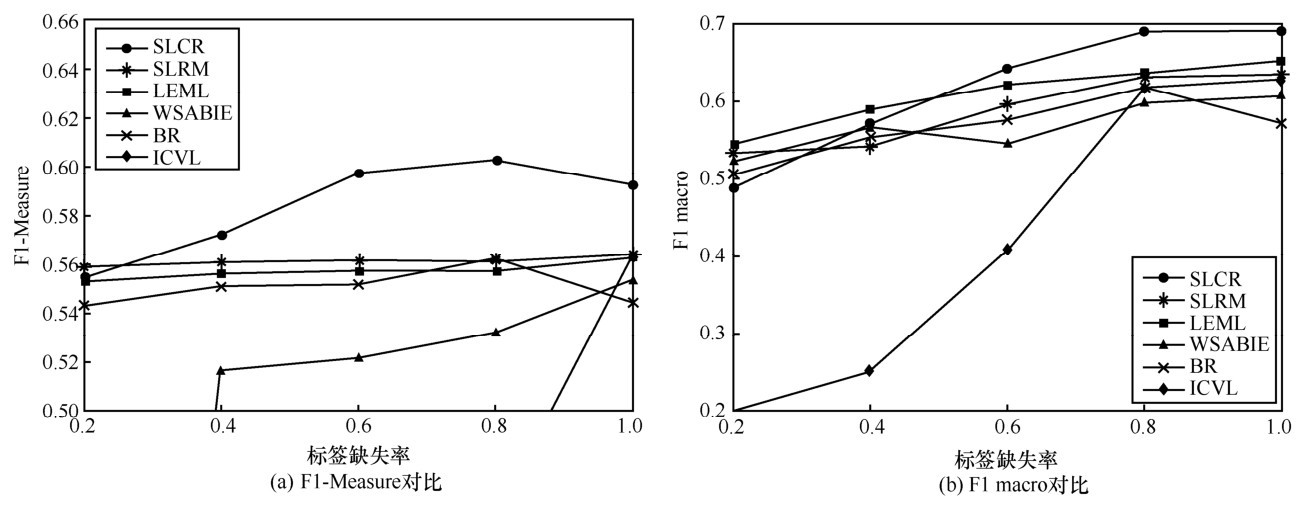

图5
Birds数据集上预测效果对比"
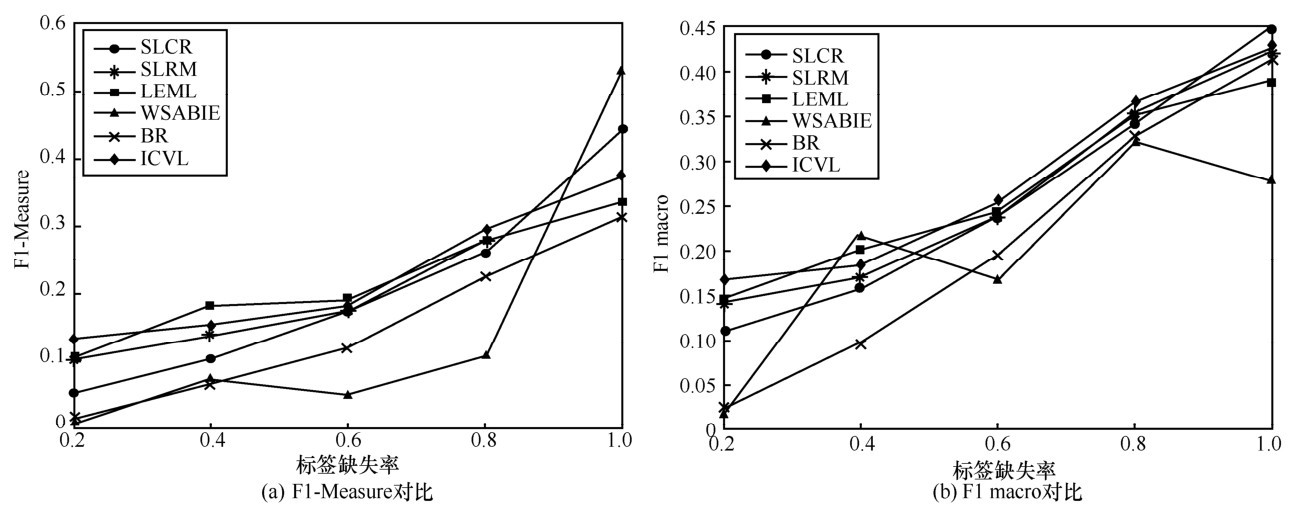

图6
Scene数据集上预测效果对比"
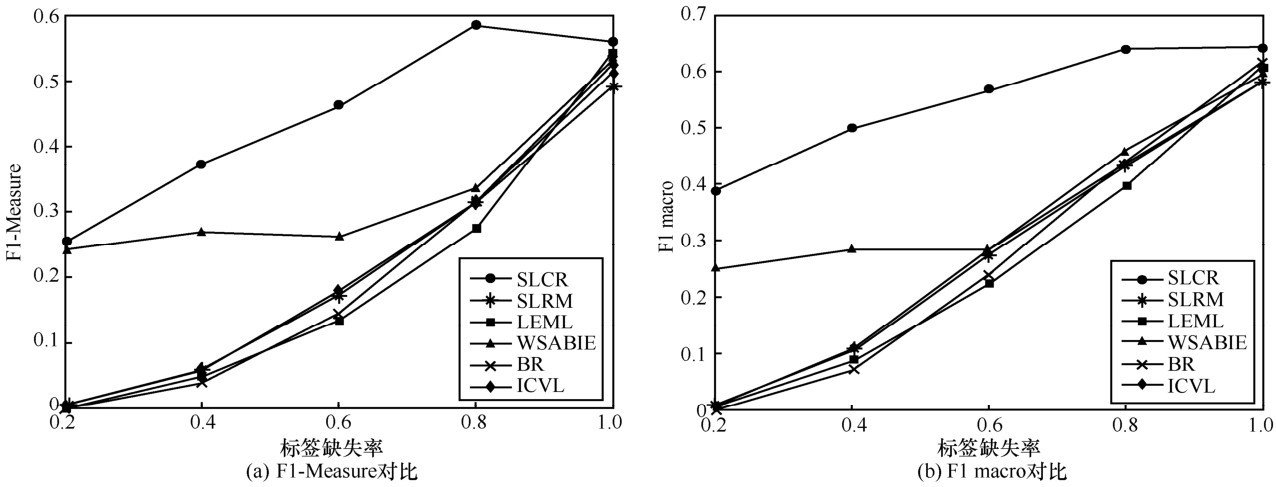

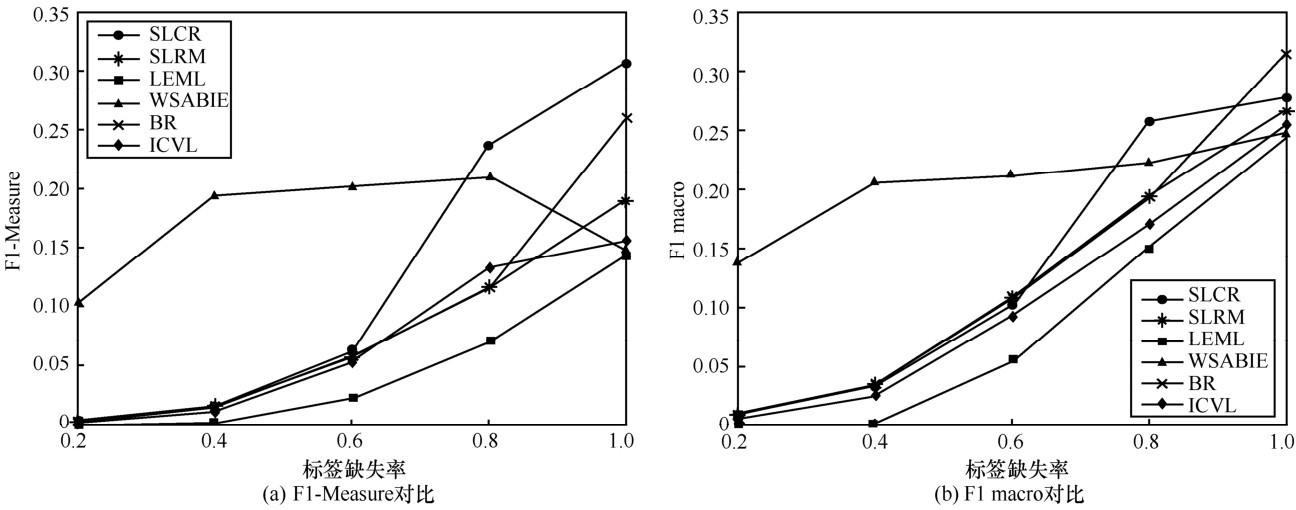
图7
NUS-WIDE-B数据集上预测效果对比"
| [1] | LI Y M , XU Z L , ZHANG Z F . Learning with incomplete labels[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2018: 3588-3595. |
| [2] | WU B Y , LIU Z L , WANG S F ,et al. Multi-label learning with missing labels[C]// Proceedings of 2014 22nd International Conference on Pattern Recognition. Piscataway:IEEE Press, 2014: 1964-1968. |
| [3] | LI X , ZHAO F P , GUO Y H . Conditional restricted Boltzmann machines for multi-label learning with incomplete labels[C]// Proceedings of the International Conference on Artificial Intelligence and Statistics. Massachusetts:MIT Press, 2015: 635-643. |
| [4] | WU B Y , LYU S W , GHANEM B . ML-MG:multi-label learning with missing labels using a mixed graph[C]// Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2015: 4157-4165. |
| [5] | ZHANG Y , SCHNEIDER J G . Multi-label output codes using canonical correlation analysis[C]// Proceedings of International Conference on Artificial Intelligence and Statistics. Berlin:Springer, 2011: 873-882. |
| [6] | YU H F , JAIN P , KAR P ,et al. Large-scale multi-label learning with missing labels[C]// Proceedings of the International Conference on Machine Learning. Saarland:DBLP, 2014: 593-601. |
| [7] | WESTON J , BENGIO S , USUNIER N . WSABIE:scaling up to large vocabulary image annotation[C]// Proceedings of the International Joint Conference on Artificial Intelligence. San Francisco:Margan Kaufmann, 2011: 1-7. |
| [8] | GONG Y , JIA Y , LEUNG T ,et al. Deep convolutional ranking for multi-label image annotation[J]. arXiv Preprint,arXiv:1312.4894, 2013. |
| [9] | ZHU Y , KWOK J T , ZHOU Z H . Multi-label learning with global and local label correlation[J]. IEEE Transactions on Knowledge and Data Engineering, 2018,30(6): 1081-1094. |
| [10] | HUANG J , QIN F , ZHENG X ,et al. Improving multi-label classification with missing labels by learning label-specific features[J]. Information Sciences, 2019,492: 124-146. |
| [11] | TAI F , LIN H T . Multi-label classification with principle label space transformation[J]. Neural Computation, 2012,24(9): 2508-2542. |
| [12] | ZHANG Y , SCHNEIDER J G . Maximum margin output coding[C]// Proceedings of the International Conference on Machine Learning. New York:ACM Press, 2012: 1-8. |
| [13] | JIN R , WANG S J , ZHOU Z H . Learning a distance metric from multi-instance multi-label data[C]// Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2009: 896-902. |
| [14] | JING L P , YANG L , YU J ,et al. Semi-supervised low-rank mapping learning for multi-label classification[C]// Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2015: 1483-1491. |
| [15] | LI Y C , YANG Y L . Label embedding for multi-label classification via dependence maximization[J]. Neural Processing Letters, 2020,52(2): 1651-1674. |
| [16] | GUPTA V , WADBUDE R , NATARAJAN N ,et al. Distributional semantics meets multi-label learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33: 3747-3754. |
| [17] | LIU W W , SHEN X B . Sparse extreme multi-label learning with oracle property[C]// Proceedings of the International Conference on Machine Learning. New York:ACM Press, 2019: 4032-4041. |
| [18] | USUNIER N , BUFFONI D , GALLINARI P . Ranking with ordered weighted pairwise classification[C]// Proceedings of the 26th Annual International Conference on Machine Learning. New York:ACM Press, 2009: 1057-1064. |
| [19] | DURAND T , THOME N , CORD M . MANTRA:minimum maximum latent structural SVM for image classification and ranking[C]// Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2015: 2713-2721. |
| [20] | RECHT B , FAZEL M , PARRILO P A . Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization[J]. SIAM Review, 2010,52(3): 471-501. |
| [21] | BENGIO Y , GOODFELLOW I , COURVILLE A . Deep learning[M]. The MIT Press, 2016. |
| [22] | BELKIN M , NIYOGI P , SINDHWANI V . Manifold regularization:a geometric framework for learning from labeled and unlabeled examples[J]. Journal of Machine Learning Research, 2006,7(1): 2399-2434. |
| [23] | WANG J , SHI D M , CHENG D S ,et al. LRSR:low-rank-sparse representation for subspace clustering[J]. Neurocomputing, 2016,214: 1026-1037. |
| [24] | CAI J F , CANDèS E J , SHEN Z W . A singular value thresholding algorithm for matrix completion[J]. SIAM Journal on Optimization, 2010,20(4): 1956-1982. |
| [25] | FAN R E , CHANG K W , HSIE C J ,et al. LIBLINEAR:a library for large linear classification[J]. Journal of Machine Learning Research, 2008,9: 1871-1874. |
| [26] | ZHANG M L , ZHOU Z H . A review on multi-label learning algorithms[J]. IEEE Transactions on Knowledge and Data Engineering, 2014,26(8): 1819-1837. |
| [1] | 姜慧, 何天流, 刘敏, 孙胜, 王煜炜. 面向异构流式数据的高性能联邦持续学习算法[J]. 通信学报, 2023, 44(5): 123-136. |
| [2] | 田有亮, 袁延森, 高鸿峰, 杨旸, 熊金波. 基于激励相容的权益分散共识算法[J]. 通信学报, 2022, 43(12): 101-112. |
| [3] | 曹进, 卜秋雨, 杨元元, 李晖, 刘樵, 马懋德. 基于位置密钥的增强型北斗用户设备接入认证协议[J]. 通信学报, 2022, 43(11): 80-89. |
| [4] | 神显豪, 曾紫玲, 牛少华. 面向异构网络的可重构智能表面辅助资源优化方法[J]. 通信学报, 2022, 43(11): 171-182. |
| [5] | 金伟, 李凤华, 余铭洁, 郭云川, 周紫妍, 房梁. 面向HDFS的密钥资源控制机制[J]. 通信学报, 2022, 43(9): 27-41. |
| [6] | 范绍帅, 吴剑波, 田辉. 面向能量受限工业物联网设备的联邦学习资源管理[J]. 通信学报, 2022, 43(8): 65-77. |
| [7] | 王继锋, 王国峰. 边缘计算模式下密文搜索与共享技术研究[J]. 通信学报, 2022, 43(4): 227-238. |
| [8] | 邢智童, 李云, 彭德义, 张本思, 刘凯明, 刘元安. OFDM中一种有效的基于分段非线性压扩的PAPR抑制算法[J]. 通信学报, 2021, 42(12): 44-53. |
| [9] | 俞东进, 韦懿杰, 孙笑笑, 倪可, 沈沪军. 编排图驱动的区块链业务过程管理框架[J]. 通信学报, 2021, 42(9): 120-132. |
| [10] | 胡九川, 范东睿, 程建聪, 严龙, 叶笑春, 李灵枝, 万良易, 钟海斌. 内存与片上渗透缓存之间数据迁移的理论分析[J]. 通信学报, 2021, 42(8): 217-225. |
| [11] | 高红民, 曹雪莹, 陈忠昊, 花再军, 李臣明, 陈月. 基于多尺度近端特征拼接网络的高光谱图像分类方法[J]. 通信学报, 2021, 42(2): 92-102. |
| [12] | 董学文, 刘昊哲, 乔慧, 郑佳伟. 支持冷启动用户推荐的区块链服务发布方案[J]. 通信学报, 2021, 42(1): 57-66. |
| [13] | 谢绒娜, 李晖, 史国振, 郭云川, 张铭, 董秀则. 基于区块链的可溯源访问控制机制[J]. 通信学报, 2020, 41(12): 82-93. |
| [14] | 高红民,曹雪莹,杨耀,花再军,李臣明. 基于CNN的双边融合网络在高光谱图像分类中的应用[J]. 通信学报, 2020, 41(11): 132-140. |
| [15] | 李家印,郭文忠,李小燕,刘西蒙. 基于智能交通的隐私保护道路状态实时监测方案[J]. 通信学报, 2020, 41(7): 73-83. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||