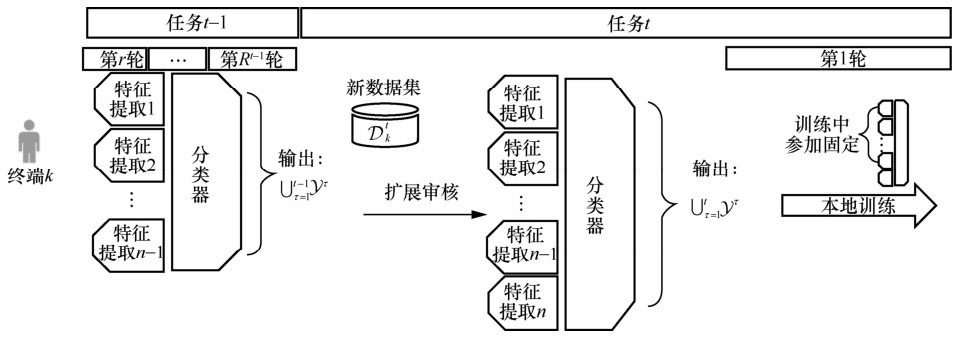
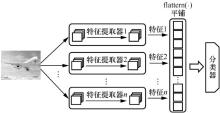
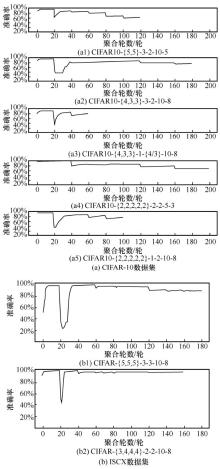
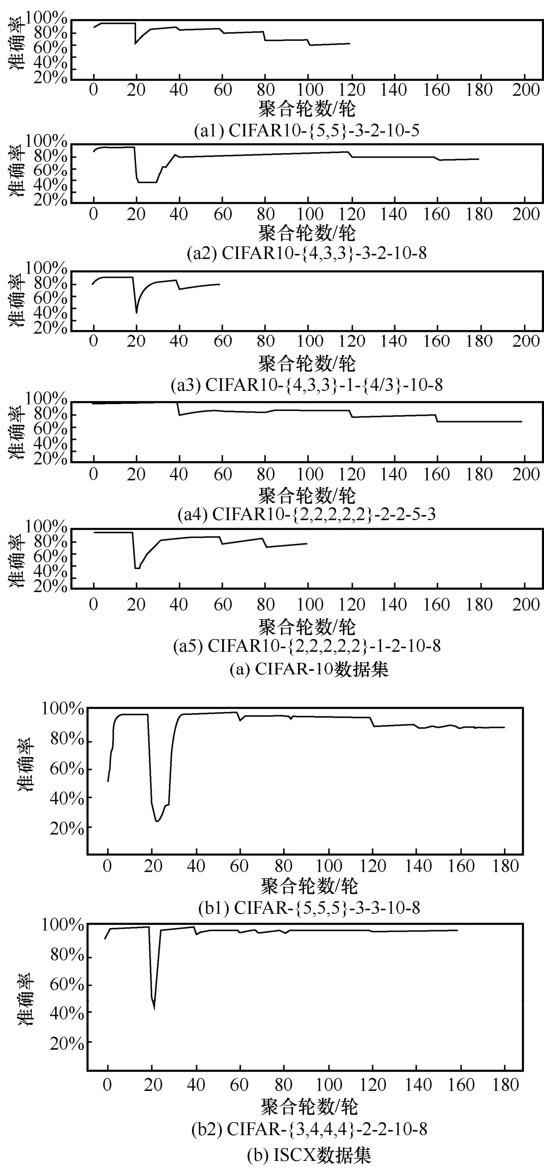
| [1] |
麻省理工科技评论. 2021 年中国数字经济时代人工智能生态白皮书[R]. 2022.
|
|
MIT Technology Review. 2021 white paper on artificial intelligence ecology in China's digital economy era[R]. 2022.
|
| [2] |
BILOGREVIC I , JADLIWALA M , KALKAN K ,et al. Privacy in mobile computing for location-sharing-based services[C]// Inter national Symposium on Privacy Enhancing Technologies Symposium. Berlin:Springer, 2011: 77-96.
|
| [3] |
LIANG X H , LI X , LUAN T H ,et al. Morality-driven data forwarding with privacy preservation in mobile social networks[J]. IEEE Transactions on Vehicular Technology, 2012,61(7): 3209-3222.
|
| [4] |
KONE?NY J , MCMAHAN H B , RAMAGE D ,et al. Federated optimization:distributed machine learning for on-device intelligence[J]. arXiv Preprint,arXiv:1610.02527, 2016.
|
| [5] |
LE J Q , LEI X Y , MU N K ,et al. Federated continuous learning with broad network architecture[J]. IEEE Transactions on Cybernetics, 2021,51(8): 3874-3888.
|
| [6] |
SERRA J , SURIS D , MIRON M ,et al. Overcoming catastrophic forgetting with hard attention to the task[C]// Proceedings of the International Conference on Machine Learning. New York:ACM Press, 2018: 4548-4557.
|
| [7] |
WU Y , CHEN Y P , WANG L J ,et al. Large scale incremental learning[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2020: 374-382.
|
| [8] |
HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2016: 770-778.
|
| [9] |
CASTRO F M , MARíN-JIMéNEZ M J , GUIL N ,et al. End-to-end incremental learning[C]// European Conference on Computer Vision. Berlin:Springer, 2018: 241-257.
|
| [10] |
MASANA M , LIU X L , TWARDOWSKI B ,et al. Class-incremental learning:survey and performance evaluation on image classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023,45(5): 5513-5533.
|
| [11] |
LI Z Z , HOIEM D . Learning without forgetting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(12): 2935-2947.
|
| [12] |
REBUFFI S A , KOLESNIKOV A , SPERL G ,et al. iCaRL:incremental classifier and representation learning[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2017: 5533-5542.
|
| [13] |
YAN S P , XIE J W , HE X M . D:dynamically expandable representation for class incremental learning[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2021: 3013-3022.
|
| [14] |
MUN H , LEE Y . Internet traffic classification with federated learning[J]. Electronics, 2020,10(1): 27.
|
| [15] |
DONG J H , WANG L X , FANG Z ,et al. Federated class-incremental learning[C]// Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2022: 10154-10163.
|
| [16] |
LI T , SANJABI M , BEIRAMI A ,et al. Fair resource allocation in federated learning[J]. arXiv Preprint,arXiv:1905.10497, 2019.
|
| [17] |
ABAD M S H , OZFATURA E , GUNDUZ D ,et al. Hierarchical federated learning ACROSS heterogeneous cellular networks[C]// Proceed ings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Piscataway:IEEE Press, 2020: 8866-8870.
|
| [18] |
LONG G , XIE M , SHEN T ,et al. Multi-center federated learning:clients clustering for better personalization[J]. arXiv Preprint,arXiv:2005.01026, 2020.
|
| [19] |
KRIZHEVSKY A , SUTSKEVER I , GEOFFREY E H . Learning multiple layers of features from tiny images[J]. Communications of the ACM, 2012,60(6): 84-90.
|
| [20] |
DRAPER-GIL G , LASHKARI A H , MAMUN M S I ,et al. Characterization of encrypted and VPN traffic using time-related features[C]// Pro ceedings of the 2nd International Conference on Information Systems Security and Privacy. [S.l]:Scite Press, 2016: 407-414.
|
| [21] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017,60(6): 84-90.
|
| [22] |
骆子铭, 许书彬, 刘晓东 . 基于机器学习的TLS恶意加密流量检测方案[J]. 网络与信息安全学报, 2020,60(1): 77-83.
|
|
LUO Z M , XU S B , LIU X D . Scheme for identifying malware traffic with TLS data based on machine learning[J]. Chinese Journal of Network and Information Security, 2020,60(1): 77-83.
|
| [23] |
PACHECO F , EXPOSITO E , GINESTE M ,et al. Towards the deployment of machine learning solutions in network traffic classification:a systematic survey[J]. IEEE Communications Surveys & Tutorials, 2019,21(2): 1988-2014.
|
| [24] |
XIE G R , LI Q , JIANG Y . Self-attentive deep learning method for online traffic classification and its interpretability[J]. Computer Networks, 2021,196:108267.
|