

通信学报 ›› 2024, Vol. 45 ›› Issue (2): 79-89.doi: 10.11959/j.issn.1000-436x.2024047
• 学术论文 • 上一篇
杨晓晗1, 程国振1,2, 刘文彦1,2, 张帅1, 郝兵3
修回日期:2023-12-20
出版日期:2024-02-01
发布日期:2024-02-01
作者简介:杨晓晗(1989− ),女,河南南阳人,博士,信息工程大学助理研究员,主要研究方向为网络空间安全、拟态防御、云计算安全等基金资助:Xiaohan YANG1, Guozhen CHENG1,2, Wenyan LIU1,2, Shuai ZHANG1, Bing HAO3
Revised:2023-12-20
Online:2024-02-01
Published:2024-02-01
Supported by:摘要:
针对软硬件差异化容易导致拟态裁决结果不一致所造成的假阳现象被误认为网络攻击的问题,提出了一种基于深度学习的拟态裁决方法。通过构建无监督的自编码-解码深度学习模型,挖掘不同执行体输出多样化正常响应数据的深度语义特征,分析归纳其统计规律,并通过设计基于离线学习-在线裁决联动的训练机制和基于反馈优化机制来解决假阳现象,从而准确检测网络攻击,提高目标系统的安全弹性。鉴于软硬件差异导致正常响应数据间的统计规律已被深度学习模型理解掌握,因此不同执行体间拟态裁决结果将保持一致,即目标系统处于安全状态。一旦目标系统受到网络攻击,执行体的响应数据将偏离深度学习模型的统计规律,致使拟态裁决结果不一致,即目标系统存在潜在安全威胁。实验结果表明,所提方法的检测性能显著优于主流的拟态裁决方法,且平均预测准确度提升了14.89%,有利于将该方法集成到真实应用的拟态化改造来增强系统的防护能力。
中图分类号:
杨晓晗, 程国振, 刘文彦, 张帅, 郝兵. 基于深度学习的拟态裁决方法研究[J]. 通信学报, 2024, 45(2): 79-89.
Xiaohan YANG, Guozhen CHENG, Wenyan LIU, Shuai ZHANG, Bing HAO. Research on mimic decision method based on deep learning[J]. Journal on Communications, 2024, 45(2): 79-89.
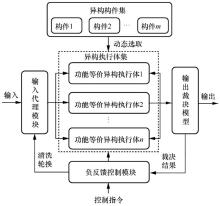
图1
拟态防御的DHR架构"


图2
基于深度学习的拟态裁决架构"


图3
预处理流程"


图4
自编码-解码的深度学习模型"

表1
自编码-解码深度学习模型的参数构成"
| 网络层 | 输出尺寸 | 设置 |
| FC1 | 1×256 | 激活函数ReLU |
| FC2 | 1×25 | 激活函数ReLU |
| FC3 | 1×2 | 激活函数ReLU |
| FC4 | 1×25 | 激活函数ReLU |
| FC5 | 1×256 | — |

图5
离线学习-在线裁决联动的训练机制"

表2
功能等价结构各异的执行体的硬件和软件"
| 执行体 | 硬件 | 软件 |
| 执行体1 | CPU架构:X86 | ubuntu20.04 |
| 执行体2 | CPU架构:X86 | centos7.9 |
| 执行体3 | CPU架构:ARM(鲲鹏920) | centos7.9 |

图6
正常样本样例"

表3
不同方法ACC、DR、FAR和时延的性能对比"
| 方法 | ACC | DR | FAR | 时延(180个样本)/ms |
| 全体一致性裁决 | 60.00% | 5.70% | 0 | 226 |
| 多数裁决 | 81.60% | 50.90% | 0 | 182 |
| 自适应增量式裁决 | 82.56% | 53.42% | 0 | 468 |
| 余弦相似度裁决 | 78.76% | 42.33% | 0 | 238 |
| GANomaly | 99.47% | 99.02% | 0 | 113 |
| 自编码-解码0 | 90.38% | 85.93% | 0 | 17 |
| 自编码-解码1 | 99.51% | 98.95% | 0 | 34 |
| 本文方法 | 99.50% | 99.00% | 0 | 19 |

图7
时延对比"

表4
不同网络结构ACC、DR和FAR对比"
| 网络结构 | ACC | DR | FAR |
| 1个自编码层和1个解码层 | 87.5% | 75.0% | 0 |
| 2个自编码层和2个解码层 | 0 | ||
| 3个自编码层和3个解码层 | 97.5% | 95.0% | 0 |
表5
不同Epoch下ACC、DR和FAR对比"
| Epoch | ACC | DR | FAR |
| 50 | 90.0% | 80.2% | 0 |
| 100 | 90.8% | 81.6% | 0 |
| 150 | 98.0% | 95.7% | 0 |
| 200 | 0 | ||
| 250 | 0 |
表6
反馈优化机制下不同方法ACC、DR和FAR对比"
| 方法 | ACC | DR | FAR |
| 未引入反馈优化机制 | 98.5% | 97.1% | 0 |
| 本文方法 | 0 |

图8
某效能考核管理平台"
表7
真实场景下不同方法ACC、DR和FAR对比"
| 方法 | ACC | DR | FAR |
| 全体一致性裁决 | 48.61% | 3.27% | 22.83% |
| 多数裁决 | 62.35% | 44.21% | 19.45% |
| 自适应增量式裁决 | 65.54% | 50.07% | 14.56% |
| 余弦相似度裁决 | 62.13% | 48.74% | 17.89% |
| 本文方法 |
表8
不同网络结构下不同方法的 ACC、DR、FAR和时延对比"
| 方法 | ACC | DR | FAR | 时延(180个样本)/ms |
| GANomaly | 99.47% | 99.02% | 0 | 113 |
| 自编码-解码1 | 99.51% | 98.95% | 0 | 34 |
| 本文方法 | 99.50% | 99.00% | 0 | 19 |
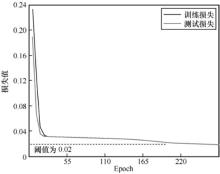
图9
损失函数的变化曲线"

表9
不同阈值下ACC、DR和FAR对比"
| 阈值 | ACC | DR | FAR |
| 0.01 | 72.51% | 68.35% | 0 |
| 0.015 | 83.36% | 76.82% | 0 |
| 0.03 | 79.84% | 98.86% | 59.81% |
| 本文阈值0.02 | 0 |
表10
FC3层不同输出尺寸时ACC、DR、FAR和时延对比"
| FC3层输出 | ACC | DR | FAR | 时延(180个样本)/ms |
| 1×20 | 99.50% | 98.97% | 0 | 30 |
| 1×10 | 99.48% | 99.01% | 0 | 28 |
| 1×5 | 99.50% | 99.00% | 0 | 25 |
| 1×2 | 99.50% | 99.00% | 0 | 19 |
| 1×1 | 94.23% | 91.86% | 0 | 19 |
| [1] | YANG A M , LU C M , LI J ,et al. Application of meta-learning in cyberspace security:a survey[J]. Digital Communications and Networks, 2023,9(1): 67-78. |
| [2] | WU J X . Development paradigms of cyberspace endogenous safety and security[J]. Science China Information Sciences, 2022,65(5): 156301. |
| [3] | SEPCZUK M . Dynamic Web application firewall detection supported by cyber mimic defense approach[J]. Journal of Network and Computer Applications, 2023,213:103596. |
| [4] | MOLINA-CORONADO B , MORI U , MENDIBURU A ,et al. Survey of network intrusion detection methods from the perspective of the knowledge discovery in databases process[J]. IEEE Transactions on Network and Service Management, 2020,17(4): 2451-2479. |
| [5] | ZHAO R J , GUI G , XUE Z ,et al. A novel intrusion detection method based on lightweight neural network for Internet of things[J]. IEEE Internet of Things Journal, 2022,9(12): 9960-9972. |
| [6] | WU Y H , HU X D . Industrial Internet security protection based on an industrial firewall[C]// Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA). Piscataway:IEEE Press, 2021: 239-247. |
| [7] | 邬江兴 . 网络空间拟态防御研究[J]. 信息安全学报, 2016,1(4): 1-10. |
| WU J X . Research on cyber mimic defense[J]. Journal of Cyber Security, 2016,1(4): 1-10. | |
| [8] | 吴铤, 胡程楠, 陈庆南 ,等. 基于执行体划分的防御增强型动态异构冗余架构[J]. 通信学报, 2021,42(3): 122-134. |
| WU T , HU C N , CHEN Q N ,et al. Defense-enhanced dynamic heterogeneous redundancy architecture based on executor partition[J]. Journal on Communications, 2021,42(3): 122-134. | |
| [9] | 周大成, 陈鸿昶, 程国振 ,等. 面向持久性连接的自适应拟态表决器设计与实现[J]. 通信学报, 2022,43(6): 71-84. |
| ZHOU D C , CHEN H C , CHENG G Z ,et al. Design and implementation of adaptive mimic voting device oriented to persistent connection[J]. Journal on Communications, 2022,43(6): 71-84. | |
| [10] | 张进, 葛强, 徐伟海 ,等. 拟态路由器BGP代理的设计实现与形式化验证[J]. 通信学报, 2023,44(3): 33-44. |
| ZHANG J , GE Q , XU W H ,et al. Design,implementation and formal verification of BGP proxy for mimic router[J]. Journal on Communications, 2023,44(3): 33-44. | |
| [11] | 姚东, 张铮, 张高斐 ,等. 多变体执行安全防御技术研究综述[J]. 信息安全学报, 2020,5(5): 77-94. |
| YAO D , ZHANG Z , ZHANG G F ,et al. A survey on multi-variant execution security defense technology[J]. Journal of Cyber Security, 2020,5(5): 77-94. | |
| [12] | ZHENG Y , LI Z , XU X L ,et al. Dynamic defenses in cyber security:techniques,methods and challenges[J]. Digital Communications and Networks, 2022,8(4): 422-435. |
| [13] | 邬江兴 . 论网络空间内生安全问题及对策[J]. 中国科学:信息科学, 2022,52(10): 1929-1937. |
| WU J X . On endogenous security problems in cyberspace and countermeasures[J]. Scientia Sinica (Informationis), 2022,52(10): 1929-1937. | |
| [14] | 邬江兴 . 拟态防御技术构建国家信息网络空间内生安全[J]. 信息通信技术, 2019,13(6): 4-6. |
| WU J X . Mimicry defense technology to build endogenous security in national information network space[J]. Information and Communications Technologies, 2019,13(6): 4-6. | |
| [15] | PARHAMI B . Voting algorithms[J]. IEEE Transactions on Reliability, 1994,43(4): 617-629. |
| [16] | CHOI J , GOH K . Dynamics of consensus formation on multiplex networks:the majority-vote model[C]// Proceedings of APS March Meeting. California:APS Press, 2018: 1-15. |
| [17] | VIHINEN M . Majority vote and other problems when using computational tools[J]. Human Mutation, 2014,35(8): 912-914. |
| [18] | 武兆琪, 张帆, 郭威 ,等. 一种基于执行体异构度的拟态裁决优化方法[J]. 计算机工程, 2020,46(5): 12-18. |
| WU Z Q , ZHANG F , GUO W ,et al. A mimic arbitration optimization method based on heterogeneous degree of executors[J]. Computer Engineering, 2020,46(5): 12-18. | |
| [19] | 沈丛麒, 陈双喜, 吴春明 ,等. 基于信誉度与相异度的自适应拟态控制器研究[J]. 通信学报, 2018,39(S2): 173-180. |
| SHEN C Q , CHEN S X , WU C M ,et al. Research on adaptive mimicry controller based on credibility and dissimilarity[J]. Journal on Communications, 2018,39(S2): 173-180. | |
| [20] | ZHANG P Y , LI C H , WANG C B . VisCode:embedding information in visualization images using encoder-decoder network[J]. IEEE Transactions on Visualization and Computer Graphics, 2021,27(2): 326-336. |
| [21] | BECHTLE S , MOLCHANOV A , CHEBOTAR Y ,et al. Meta learning via learned loss[C]// Proceedings of the 25th International Conference on Pattern Recognition (ICPR). Piscataway:IEEE Press, 2021: 4161-4168. |
| [22] | 祝永胜, 张铮, 李继忠 . 一种 Web 服务用户代理/表决器设计方法[J]. 信息工程大学学报, 2017,18(5): 613-617. |
| ZHU Y S , ZHANG Z , LI J Z . Web server user agent/voter design method[J]. Journal of Information Engineering University, 2017,18(5): 613-617. | |
| [23] | 李卫超, 张铮, 王立群 ,等. 基于拟态防御架构的多余度裁决建模与风险分析[J]. 信息安全学报, 2018,3(5): 64-74. |
| LI W C , ZHANG Z , WANG L Q ,et al. The modeling and risk assessment on redundancy adjudication of mimic defense[J]. Journal of Cyber Security, 2018,3(5): 64-74. | |
| [24] | AKCAY S , ATAPOUR-ABARGHOUEI A , BRECKON T P . GANomaly:semi-supervised anomaly detection via adversarial training[C]// Proceedings of Asian Conference on Computer Vision. Berlin:Springer, 2019: 622-637. |
| [25] | YANG G , ZHANG Y . Investigating the relationship between compression ratio,anomaly detection and generative capability of deep autoencoder networks[J]. Neurcomputing, 2019,342(1): 202-211. |
| [1] | 王涛, 冯浩, 秘蓉新, 李林, 何振学, 傅奕茗, 吴姝. 基于改进YOLOv3-SPP算法的道路车辆检测[J]. 通信学报, 2024, 45(2): 68-78. |
| [2] | 禹树文, 许威, 姚嘉铖. 面向智能无人通信系统的因果性对抗攻击生成算法[J]. 通信学报, 2024, 45(1): 54-62. |
| [3] | 张学军, 张奉鹤, 盖继扬, 杜晓刚, 周文杰, 蔡特立, 赵博. mVulSniffer:一种多类型源代码漏洞检测方法[J]. 通信学报, 2023, 44(9): 149-160. |
| [4] | 李勉, 李洋, 张纵辉, 史清江. Massive MIMO中通信高效的分布式预编码设计[J]. 通信学报, 2023, 44(8): 37-48. |
| [5] | 王慧娇, 张鑫, 韦永壮, 李灵琛. 基于深度学习的SM4密码算法新型区分器[J]. 通信学报, 2023, 44(7): 171-184. |
| [6] | 李荣鹏, 汪丙炎, 张宏纲, 赵志峰. 知识增强的语义通信接收端设计[J]. 通信学报, 2023, 44(6): 70-76. |
| [7] | 陈东昱, 陈华, 范丽敏, 付一方, 王舰. 基于深度学习的随机性检验策略研究[J]. 通信学报, 2023, 44(6): 23-33. |
| [8] | 马帅, 裴科, 祁华艳, 李航, 曹雯, 王洪梅, 熊海良, 李世银. 基于生成模型的地磁室内高精度定位算法研究[J]. 通信学报, 2023, 44(6): 211-222. |
| [9] | 张进, 葛强, 徐伟海, 江逸茗, 马海龙, 于洪涛. 拟态路由器BGP代理的设计实现与形式化验证[J]. 通信学报, 2023, 44(3): 33-44. |
| [10] | 张昀, 周婧, 黄经纬, 于舒娟, 黄丽亚. 基于深度学习的正交频分复用系统信道估计[J]. 通信学报, 2023, 44(12): 124-133. |
| [11] | 谢刚, 王荃毅, 谢新林, 王健安. 融合多尺度深度卷积的轻量级Transformer交通场景语义分割算法[J]. 通信学报, 2023, 44(10): 213-225. |
| [12] | 杨洁, 董标, 付雪, 王禹, 桂冠. 基于轻量化分布式学习的自动调制分类方法[J]. 通信学报, 2022, 43(7): 134-142. |
| [13] | 周大成, 陈鸿昶, 程国振, 何威振, 商珂, 扈红超. 面向持久性连接的自适应拟态表决器设计与实现[J]. 通信学报, 2022, 43(6): 71-84. |
| [14] | 杨秀璋, 彭国军, 李子川, 吕杨琦, 刘思德, 李晨光. 基于Bert和BiLSTM-CRF的APT攻击实体识别及对齐研究[J]. 通信学报, 2022, 43(6): 58-70. |
| [15] | 廖育荣, 王海宁, 林存宝, 李阳, 方宇强, 倪淑燕. 基于深度学习的光学遥感图像目标检测研究进展[J]. 通信学报, 2022, 43(5): 190-203. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||