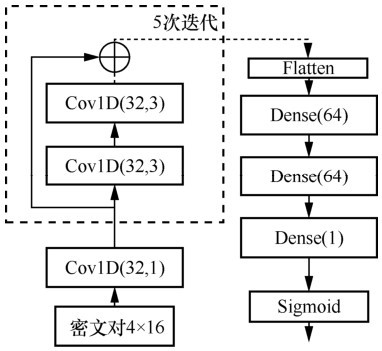
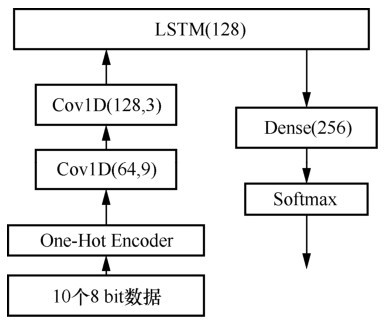
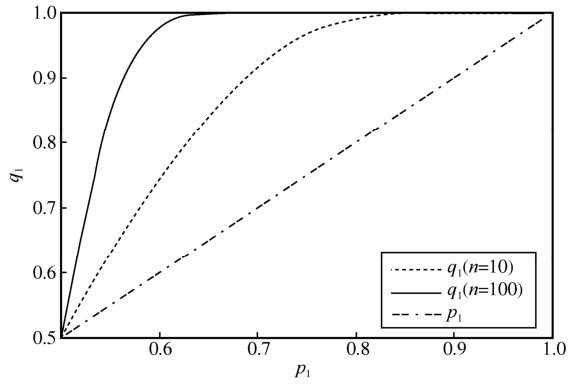
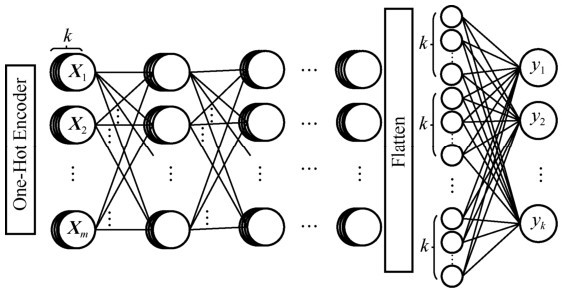
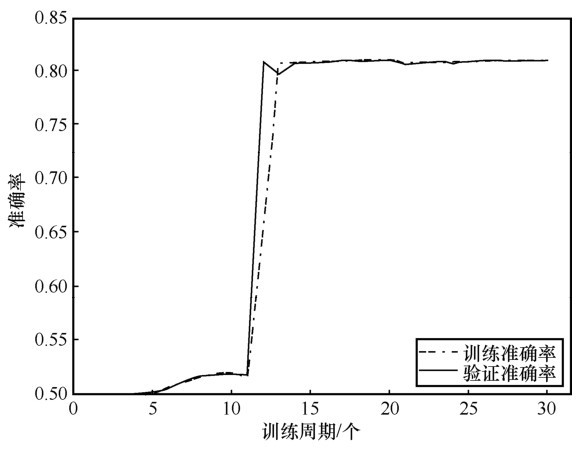
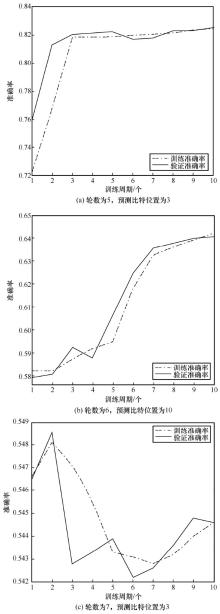
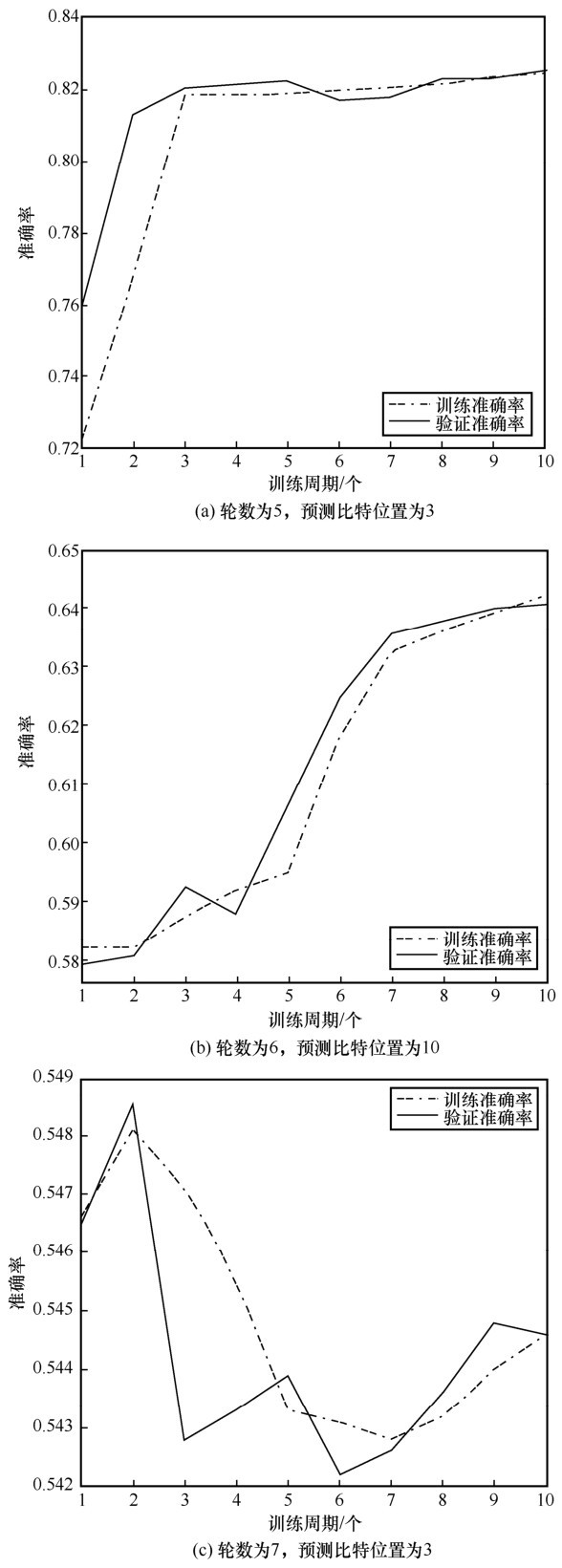
| [1] |
BOYAR J . Inferring sequences produced by a linear congruential generator missing low-order bits[J]. Journal of Cryptology, 1989,1(3): 177-184.
|
| [2] |
MATSUMOTO M , NISHIMURA T . Mersenne twister:a 623- dimensionally equidistributed uniform pseudo-random number generator[J]. ACM Transactions on Modeling and Computer Simulation, 1998,8(1): 3-30.
|
| [3] |
RUKHIN A , SOTO J , NECHVATAL J . A statistical test suite for random and pseudorandom number generators for cryptographic applications[R]. 2001.
|
| [4] |
KILLMANN W , SCHINDLER W . Functionality classes and evaluation methodology for true (physical) random number generators:AIS 31[S].(2001-09-25).
|
| [5] |
国家密码管理局. 随机性检测规范:GM/T 0005—2021[S]. 北京:中国标准出版社, 2021.
|
|
State Cryptography Administration. Randomness testing specifications:GM/T 0005—2021[S. Beijing:Standards Press of China, 2021.
|
| [6] |
SULAK F . Statistical analysis of block ciphers and hash functions[D]. Ankara:Middle East Technical University, 2011.
|
| [7] |
ALANI M M . Applications of machine learning in cryptography:a survey[C]// Proceedings of the 3rd International Conference on Cryptography,Security and Privacy. New York:ACM Press, 2019: 23-27.
|
| [8] |
GOHR A . Improving attacks on round-reduced speck32/64 using deep learning[C]// Proceedings of Annual International Cryptology Conference. Berlin:Springer, 2019: 150-179.
|
| [9] |
BENAMIRA A , GERAULT D , PEYRIN T ,et al. A deeper look at machine learning-based cryptanalysis[C]// Proceedings of Annual International Conference on the Theory and Applications of Cryptographic Techniques. Berlin:Springer, 2021: 805-835.
|
| [10] |
BAO Z Z , GUO J , LIU M C ,et al. Enhancing differential-neural cryptanalysis[C]// Proceedings of International Conference on the Theory and Application of Cryptology and Information Security. Berlin:Springer, 2022: 318-347.
|
| [11] |
PATERSON K , POETTERING B , SCHULDT J C N . Big bias hunting in Amazonia:large-scale computation and exploitation of RC4 biases[C]// Proceedings of International Conference on the Theory and Application of Cryptology and Information Security. Berlin:Springer, 2014: 398-419.
|
| [12] |
MISHRA G , GUPTA I , MURTHY S V S S N V G K ,et al. Deep learning based cryptanalysis of stream ciphers[J]. Defence Science Journal, 2021,71(4): 499-506.
|
| [13] |
SAVICKY P , ROBNIK-?IKONJA M . Learning random numbers:a MATLAB anomaly[J]. Applied Artificial Intelligence, 2008,22(3): 254-265.
|
| [14] |
FAN F L , WANG G . Learning from pseudo-randomness with an artificial neural network-does God play pseudo-dice?[J]. IEEE Access, 2018,6: 22987-22992.
|
| [15] |
FISCHER T . Testing cryptographically secure pseudo random number generators with artificial neural networks[C]// Proceedings of 2018 17th IEEE International Conference on Trust,Security and Privacy In Computing and Communications/ 12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE). Piscataway:IEEE Press, 2018: 1214-1223.
|
| [16] |
TRUONG N D , HAW J Y , ASSAD S M ,et al. Machine learning cryptanalysis of a quantum random number generator[J]. IEEE Transactions on Information Forensics and Security, 2019,14(2): 403-414.
|
| [17] |
LI C , ZHANG J G , SANG L X ,et al. Deep learning-based security verification for a random number generator using white chaos[J]. Entropy, 2020,22(10): 1134.
|
| [18] |
YANG J , ZHU S Y , CHEN T Y ,et al. Neural network based min-entropy estimation for random number generators[C]// Proceedings of International Conference on Security and Privacy in Communication Systems. Berlin:Springer, 2018: 231-250.
|
| [19] |
ZHU S Y , MA Y , LI X S ,et al. On the analysis and improvement of min-entropy estimation on time-varying data[J]. IEEE Transactions on Information Forensics and Security, 2020,15: 1696-1708.
|
| [20] |
AHMADZADEH E , KIM H , JEONG O ,et al. A novel dynamic attack on classical ciphers using an attention-based LSTM encoder-decoder model[J]. IEEE Access, 2021,9: 60960-60970.
|