

Journal on Communications ›› 2017, Vol. 38 ›› Issue (9): 133-147.doi: 10.11959/j.issn.1000-436x.2017188
• Papers • Previous Articles Next Articles
Chen BIAN1,Jiong1 YU1,Wei-rong XIU1,Bin LIAO2,Chang-tian YING1,Yu-rong QIAN1
Revised:2017-06-14
Online:2017-09-01
Published:2017-10-18
Supported by:CLC Number:
Chen BIAN,Jiong1 YU,Wei-rong XIU,Bin LIAO,Chang-tian YING,Yu-rong QIAN. Progressive filling partitioning and mapping algorithm for Spark based on allocation fitness degree[J]. Journal on Communications, 2017, 38(9): 133-147.
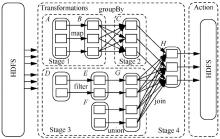
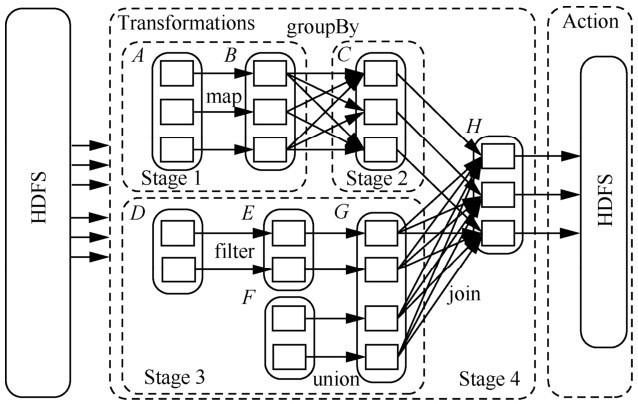
"
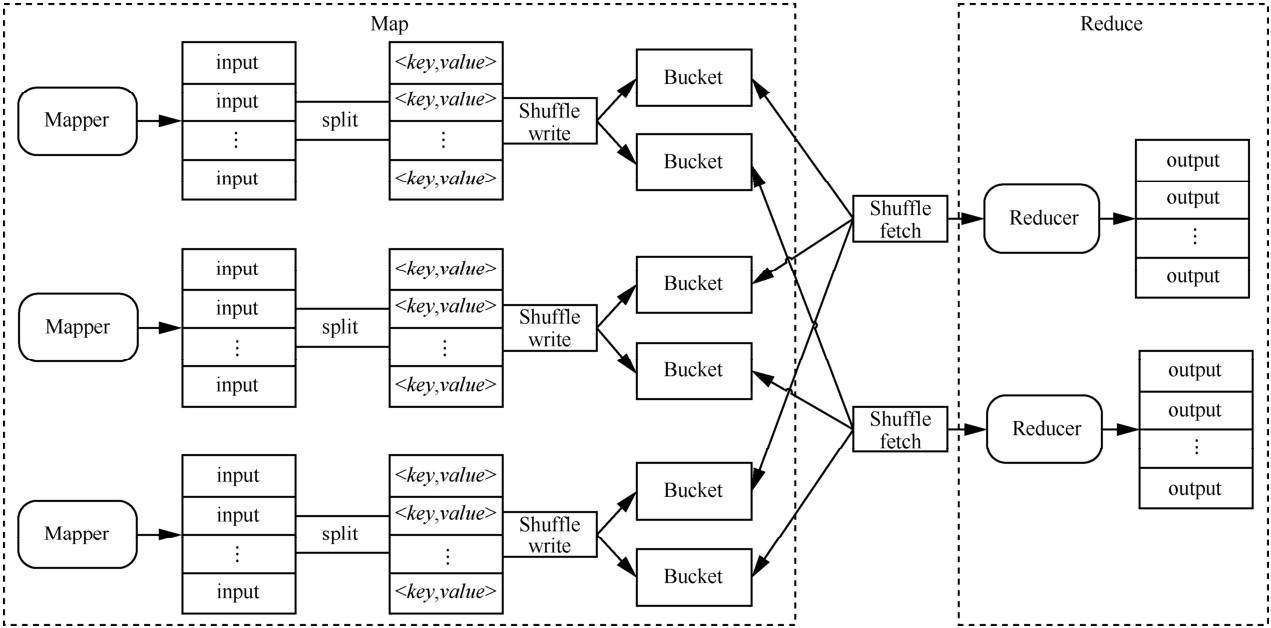
"
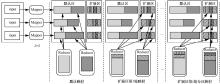
"
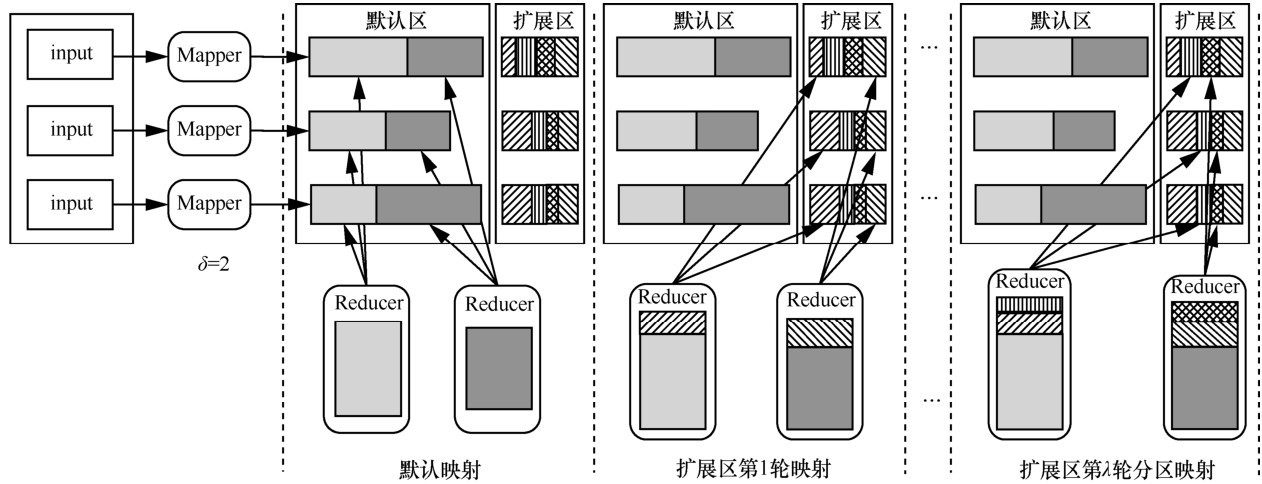
"
| 参数 | 值 |
| CPU | Intel CORE i7/2.2 GHZ |
| RAM | 4 GB |
| NIC | 1 000 Mbit/s |
| Hard Disk | 200 GB/SATA3.0(6 Gbit/s) |
| OS | Ubuntu 12.04 |
| Spark | Apache Spark 1.6.2 |
| Hadoop | Apache Hadoop 2.6 |
| Scala | Scala-2.10.4 |
| JDK | OpenJDK 1.8.0 25 |
"
| 数据名称 | 节点数 | 边数 |
| Cit-Patents | 3 774 768 | 16 518 948 |
| soc-pokec-relationships | 1 632 803 | 30 622 564 |
| Wiki-Talk | 2 394 385 | 5 021 410 |
| Web-Google | 875 713 | 5 105 039 |
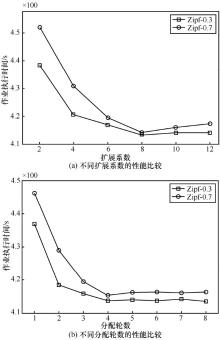
"

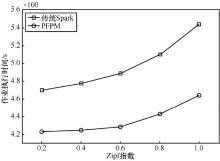
"
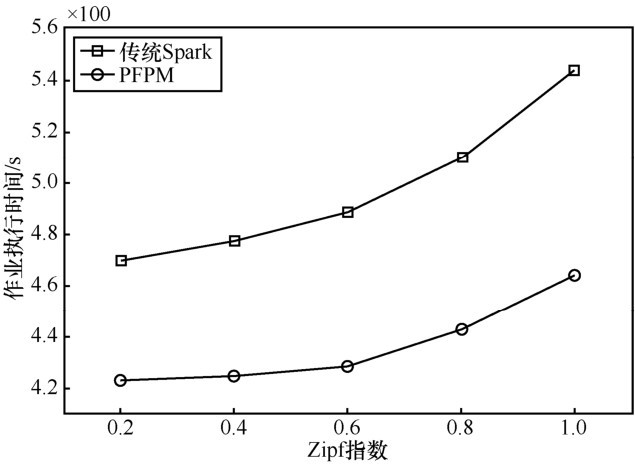

"
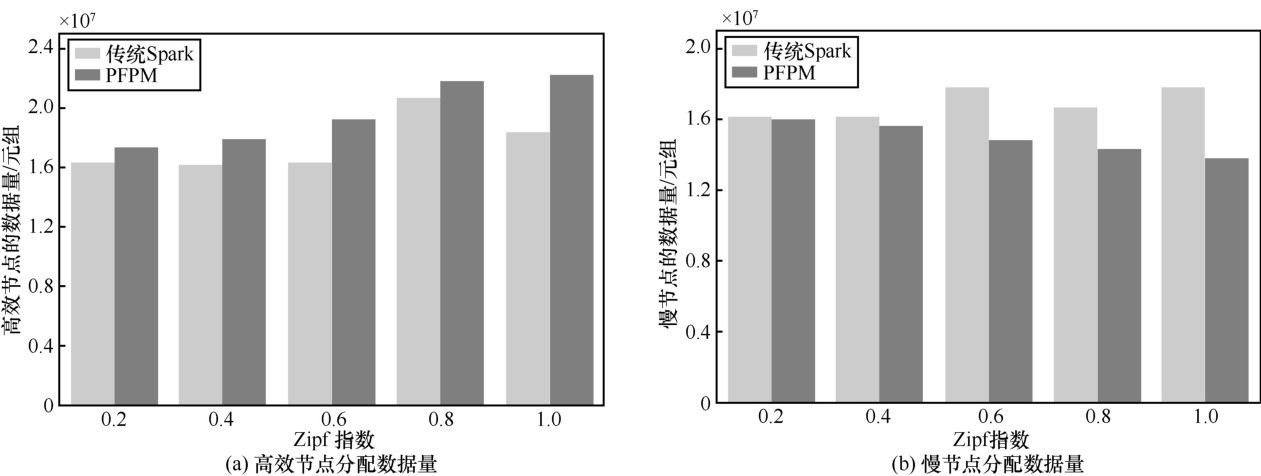

"
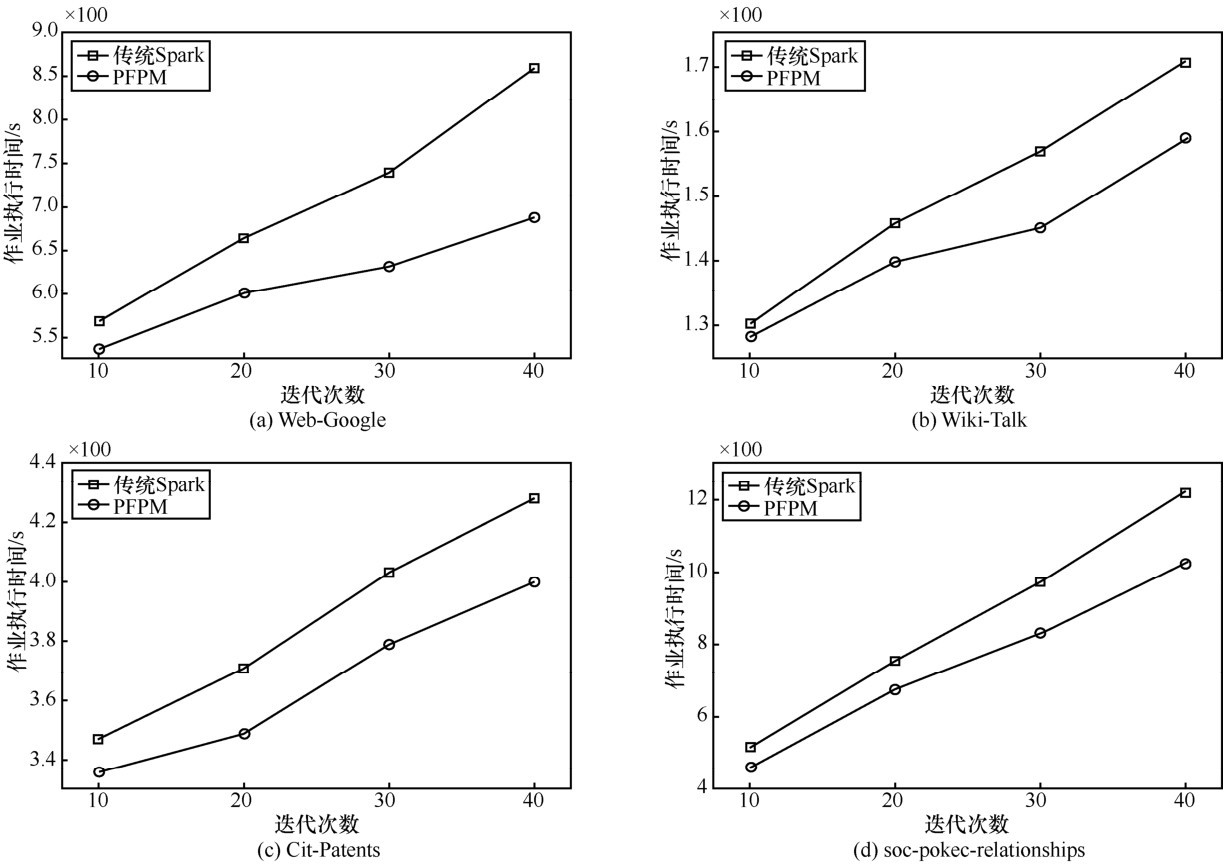
| [1] | 孟小峰, 慈祥 . 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013,50(1): 146-169. |
| MENG X F , CI X . Big data management:concepts,techniques and challenges[J]. Journal of Computer Research and Development, 2013,50(1): 146-169. | |
| [2] | 付钰, 李洪成, 吴晓平 ,等. 基于大数据分析的APT攻击检测研究综述[J]. 通信学报, 2015,36(11): 1-14. |
| FU Y , LI H C , WU X P ,et al. Detecting APT attacks:a survey from the perspective of big data analysis[J]. Journal on Communications, 2015,36(11): 1-14. | |
| [3] | STRANDE S M , CICOTTI P , SINKOVITS R S ,et al. Gordon:design,performance,and experiences deploying and supporting a data intensive supercomputer[C]// The 1st Conference on the Extreme Science and Engineering Discovery Environment. 2012: 1-8. |
| [4] | 杜小勇, 陈峻, 陈跃国 . 大数据探索式搜索研究[J]. 通信学报, 2015,36(12): 77-88. |
| DU X Y , CHEN J , CHEN Y G . Exploratory search on big data[J]. Journal on Communications, 2015,36(12): 77-88. | |
| [5] | ZAHARIA M , CHOWDHURY M , DAS T ,et al. Fast and interactive analytics over hadoop data with spark[J]. Login, 2012,37(4): 45-51. |
| [6] | ZAHARIA M , XIN R , WENDELL P ,et al. Apache Spark:a unified engine for big data processing[J]. Communications of the ACM, 2016,59(11): 56-65. |
| [7] | CARBONE P , EWEN S , HARIDI S ,et al. Apache flink:stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2015,36(4): 28-38. |
| [8] | TUMMALAPALLI S , MACHAVARAPU V R . Managing mysql cluster data using cloudera impala[J]. Procedia Computer Science, 2016,85(5): 463-474. |
| [9] | SIKKA V , LEHNER W , SANG K C ,et al. Efficient transaction processing in SAP HANA database:the end of a column store myth[C]// The 2012 ACM SIGMOD International Conference on Management of Data. 2012: 731-742. |
| [10] | DEAN J , GHEMAWAT S . MapReduce:simplifed data processing on large clusters[C]// The Conference on Operating System Design and Implementation (OSDI). 2004: 137-150. |
| [11] | ZAHARIA M , CHOWDHURY M , DAS T ,et al. Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]// The 9th USENIX Conference on Networked Systems Design and Implementation. 2012:2. |
| [12] | LIN X , WANG P , WU B . Log analysis in cloud computing environment with hadoop and spark[C]// The 5th IEEE International Conference on Broadband Network & Multimedia Technology (IC-BNMT). 2013: 273-276. |
| [13] | DONG X , XIE Y , MURALIMANOHAR N ,et al. Hybrid checkpointing using emerging nonvolatile memories for future exascale system[J]. ACM Transactions on Architecture and Code Optimization (TACO), 2011,8(2): 1-29. |
| [14] | 田俊峰, 张亚姣 . 基于马尔可夫的检查点可信评估方法[J]. 通信学报, 2015,36(1): 234-240. |
| TIAN J F , ZHANG Y J . Checkpoint trust evaluation method based on Markov[J]. Journal on Communications, 2015,36(1): 234-240. | |
| [15] | ARMBRUST M , XIN R S , LIAN C ,et al. Spark SQL:relational data processing in spark[C]// The 2015 ACM SIGMOD International Conference on Management of Data. 2015: 1383-1394. |
| [16] | IQBAL M H , SOOMRO T R . Big data analysis:apache storm perspective[J]. International Journal of Computer Trends & Technology, 2015,19(1): 9-14. |
| [17] | ZAHARIA M , DAS T , LI H Y ,et al. Discretized streams:fault-tolerant streaming computation at scale[C]// ACM Symposium on Operating Systems Principles. 2013: 423-438. |
| [18] | MENG X , BRADLEY J , YAVUZ B ,et al. MLlib:machine learning in apache Spark[J]. Journal of Machine Learning Research, 2015,17(1): 1235-1241. |
| [19] | GONZALEZ J E , XIN R S , DAVE A ,et al. GraphX:graph processing in a distributed dataflow framework[C]// The 11th USENIX conference on Operating Systems Design and Implementation. 2014: 599-613. |
| [20] | 廖彬, 于炯, 孙华 ,等. 基于存储结构重配置的分布式存储系统节能算法[J]. 计算机研究与发展, 2013,50(1): 3-18. |
| LIAO B , YU J , SUN H ,et al. Energy-efficient algorithms for distributed storage system based on data storage structure reconfiguration[J]. Journal of Computer Research and Development, 2013,50(1): 3-18. | |
| [21] | DEAN J , GHEMAWAT S . MapReduce:simplified data processing on large clusters[J]. Operating Systems Design & Implementation, 2004,5(1): 147-152. |
| [22] | KWON Y , BALAZINSKA M , HOWE B ,et al. A study of skew in MapReduce application[J]. Open Cirrus Summit, 2011,1: 1-5. |
| [23] | KWON Y , BALAZINSKA M , HOWE B ,et al. Skew-resistant parallel processing of feature-extracting scientific user-defined functions[C]// The 1st ACM Symposium on Cloud Computing. 2010: 75-86. |
| [24] | 王卓, 陈群, 李战怀 ,等. 基于增量式分区策略的MapReduce数据均衡方法[J]. 计算机学报, 2016,39(1): 19-35. |
| WANG Z , CHEN Q , LI Z H ,et al. An incremental partitioning strategy for data balance on MapReduce[J]. Chinese Journal of Computers, 2016,39(1): 19-35. | |
| [25] | KWON Y , BALAZINSKA M , HOWE B ,et al. SkewTune:mitigating skew in MapReduce applications[C]// The 2012 ACM SIGMOD International Conference on Management of Data. 2012: 25-36. |
| [26] | YAN W , XUE Y , MALIN B . Scalable and robust key group size estimation for reducer load balancing in MapReduce[C]// IEEE Int Conference on Big Data. 2013: 156-162. |
| [27] | RAMAKRISHNAN S R , SWART G , URMANOV A ,et al. Balancing reducer skew in MapReduce workloads using progressive sampling[C]// The 3rd ACM Symposium on Cloud Computing (SOCC’12). 2012: 1-14. |
| [28] | GUFLER B , AUGSTEN N , REISER A ,et al. Handing data skew in MapReduce[C]// The 1st International Conference on Cloud Computing and Services Science. 2011: 574-583. |
| [29] | GUFLER B , AUGSTEN N , REISER A ,et al. Load balancing in MapReduce based on scalable cardinality estimates[C]// The 28th IEEE International Conference on Data Engineering (ICDE). 2012: 522-533. |
| [30] | TANG Z , ZHANG X S , LI K ,et al. An intermediate data placement algorithm for load balancing in Spark computing[J]. Future Generation Computer Systems, 2016. |
| [31] | KOLB L , THOR A , RAHM E . Load balancing for MapReduce-based entity resolution[C]// The 28th IEEE International Conference on Big Data Engineering (ICDE). 2012: 618-629. |
| [32] | KOLB L , THOR A , RAHM E ,et al. Block-based load balancing for entity resolution with MapReduce[C]// The 20th ACM International Conference on Information and Knowledge Management (CIKM). 2011: 2397-2400. |
| [33] | CHEN Q , YAO J Y , XIAO Z . Libra:lightweight data skew mitigation in MapReduce[J]. IEEE Transactions on Parallel & Distributed Systems, 2015,26(9): 2520-2533. |
| [34] | RACHA S C . Load balancing MapReduce communications for efficient executions of applications in a cloud[M]. India,Bangalore: Indian Institute of Science, 2012: 12-16. |
| [35] | IBRAHIM S , JIN H , LU L ,et al. Handling partitioning skew in MapReduce using LEEN[J]. Peer-to-Peer Networking and Applications, 2013,6(4): 409-424. |
| [36] | DAI W , IBRAHIM I , BASSIOUNI M . Improving load balance for data-intensive computing on cloud platforms[C]// 2016 IEEE International Conference on Smart Cloud. 2016: 140-145. |
| [37] | TANG Z , ZHANG X S , LI K L ,et al. A data skew oriented reduce placement algorithm based on sampling[J]. IEEE Transactions on Cloud Computing, 2016. |
| [38] | FAN Y Q , WU W G , XU Y L ,et al. Improving MapReduce performance by balancing skewed loads[J]. Communications, 2014,11(8): 85-108. |
| [39] | TRIGUERO I , GALAR M , VLUYMANS S . Evolutionary undersampling for extremely imbalanced big data classification under apache spark[C]// 2016 IEEE Congress on Evolutionary Computation. 2016: 715-722. |
| [40] | MESTRE D G , PIRES C E , NASCIMENTO D C ,et al. An efficient spark-based adaptive windowing for entity matching[J]. Journal of Systems and Software, 2017,128(6): 1-10. |
| [41] | GHODSI A , ZAHARIA M , SHENKER S ,et al. Choosy:max-min fair sharing for datacenter jobs with constraints[C]// The 8th ACM European Conference on Computer Systems. 2013: 365-378. |
| [1] | Cheng ZHONG, Hui SUN. Parallel algorithm for sensitive sequence recognition from long-read genome data with high error rate [J]. Journal on Communications, 2023, 44(2): 160-171. |
| [2] | Yimin MAO, Dejin GAN, Liefa LIAO, Zhigang CHEN. Parallel division clustering algorithm based on Spark framework and ASPSO [J]. Journal on Communications, 2022, 43(3): 148-163. |
| [3] | Jianping CAI, Ximeng LIU, Jinbo XIONG, Zuobin YING, Yingjie WU. Approximation method of multiple consistency constraint under differential privacy [J]. Journal on Communications, 2021, 42(6): 107-117. |
| [4] | Nai-jin CHEN,Zhi-yong FENG,Jian-hui JIANG. Bypass node non-redundant adding algorithm for crossing-level data transmission in two-dimension reconfigurable cell array [J]. Journal on Communications, 2015, 36(4): 35-51. |
| [5] | Hao CHEN,Yu LI,Song-lin HU,Ying LIANG. Parallel complex event processing system based on S4 framework [J]. Journal on Communications, 2012, 33(Z1): 165-169. |
| [6] | Lei ZHANG,Bo YANG. Research and implemention of parallel particle swarm optimization algorithm [J]. Journal on Communications, 2005, 26(1A): 289-292. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||