

Journal on Communications ›› 2022, Vol. 43 ›› Issue (6): 28-40.doi: 10.11959/j.issn.1000-436x.2022093
• Topics: Key Technologies of 6G Oriented Intellicise Network • Previous Articles Next Articles
Ang LI1,2, Jianxin CHEN1,2, Xin WEI1,2, Liang ZHOU1,2
Revised:2022-03-22
Online:2022-06-01
Published:2022-06-01
Supported by:CLC Number:
Ang LI, Jianxin CHEN, Xin WEI, Liang ZHOU. 6G-oriented cross-modal signal reconstruction technology[J]. Journal on Communications, 2022, 43(6): 28-40.

"
"
| 采集设备 | 采集信号 | 设备参数 |
| 铁三角单向拾音器 | 立体声/单声道:单声道 | |
| AT9912 | 音频 | 频率响应:70~16 000 Hz |
| 灵敏度:-39 dB | ||
| 海康威视高清摄像头 | 视频 | 最高分辨率:1 920×1 280 |
| DS-U32W | 视频帧率:30 frame/s | |
| 镜头焦距:2.7~13 mm | ||
| 因时机械手RH56BFX-2L | 触觉 | 采样频率:100 Hz |
| 指关节力传感器 | 力分辨率:0.5 N |
"
| 样本大类 | 样本小类 | 类别数量/种 |
| 塑料 | 聚对苯二甲酸乙二醇酯、高密度聚乙烯、聚氯乙烯、低密度聚乙烯、聚丙烯、聚苯乙烯 | 6 |
| 金属 | 铁、铝、镍、锌、钛、铟、铜、钽、钼 | 9 |
| 木材 | 樱桃木、松木、黑胡桃、竹 | 4 |
| 纸 | 打印纸、报纸、硬纸板 | 3 |
| 陶瓷 | 传统陶瓷、特种陶瓷 | 2 |
| 橡胶 | 天然橡胶、合成橡胶 | 2 |
| 天然纺织品 | 棉、亚麻、丝绸 | 3 |
| 合成纺织品 | 锦纶、涤纶、腈纶、维伦、丙纶、氨纶、碳纤维 | 7 |
| 玻璃 | 普通玻璃、石英玻璃 | 2 |
| 皮革 | 牛皮、羊皮、人造皮革 | 3 |
| 石头 | 花岗岩、大理岩、石灰岩、板岩、泥岩、安山岩 | 6 |
"
| 数据集名称 | 内容 | 类别数量/种 | 帧数量 |
| C4S[ | 音频、视频 | 1 | 十万级 |
| URMP[ | 音频、视频 | 14 | 百万级 |
| MUSIC[ | 音频、视频 | 12 | 百万级 |
| Solos[ | 音频、视频 | 13 | 百万级 |
| HMMD[ | 音频、视频 | 7 | 百万级 |
| AVA-ActiveSpeaker[ | 音频、视频 | — | 百万级 |
| AIST[ | 音频、视频 | — | 百万级 |
| AIST++ [ | 音频、视频 | — | 百万级 |
| HIMV-200K [ | 音频、视频 | — | 百万级 |
| VisGel[ | 视频、触觉 | 195 | 百万级 |
| STAG[ | 触觉 | 26 | 十万级 |
| VisTouch | 音频、视频、触觉 | 47 | 千万级 |

"


"


"
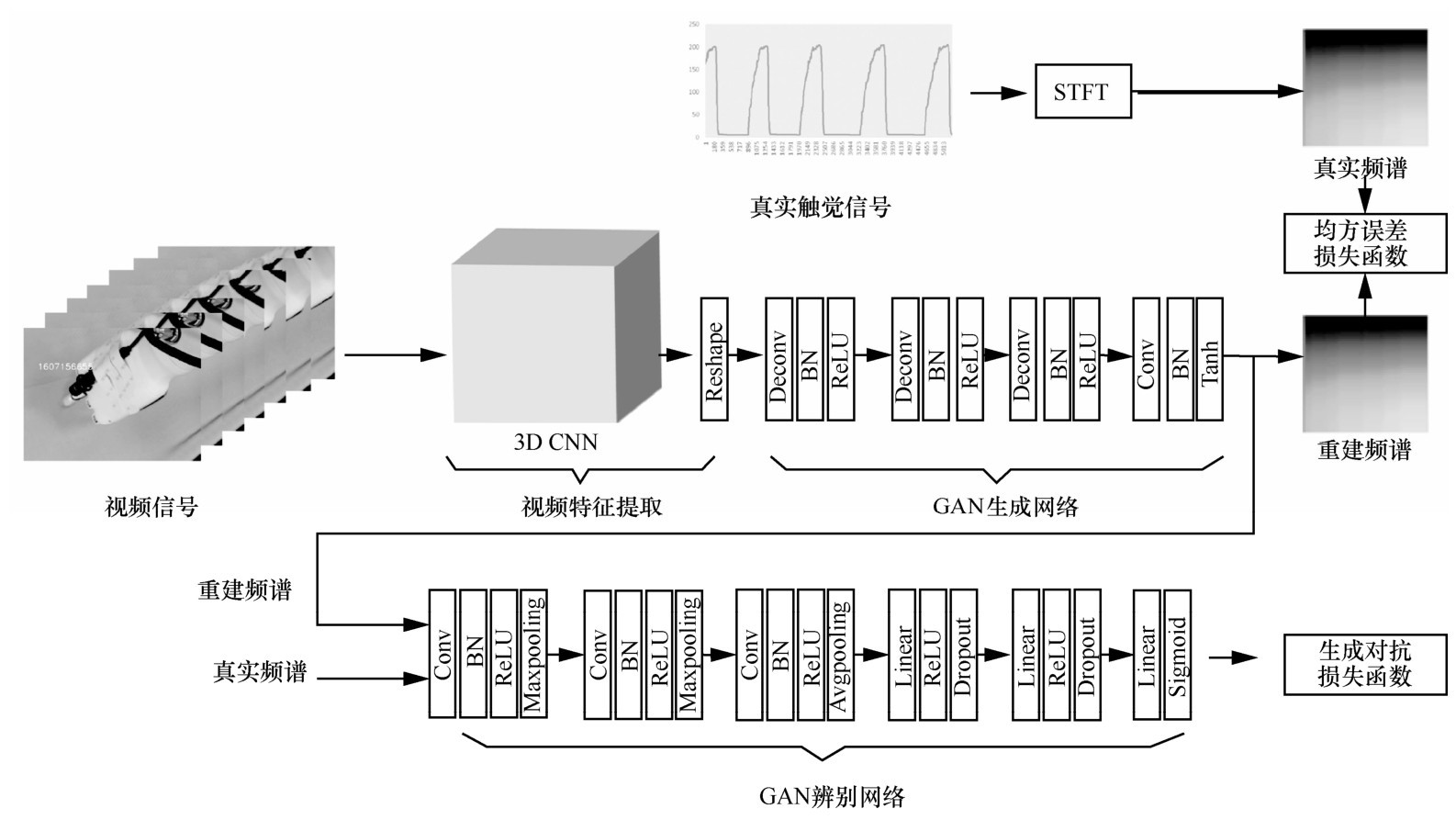
"
| 模块序号 | 模块参数 | 输出张量尺寸 |
| 1.1 | 输入 | 4 096×7×7 |
| 2.1 | 反卷积层k=(3,3),p=(1,0),s=1 | 256×7×9 |
| 2.2 | 批归一化层 | 256×7×9 |
| 2.3 | ReLU激活函数 | 256×7×9 |
| 3.1 | 反卷积层k=(2,5),p=(0,0),s=2 | 128×14×21 |
| 3.2 | 批归一化层 | 128×14×21 |
| 3.3 | ReLU激活函数 | 128×14×21 |
| 4.1 | 反卷积层k=(4,5),p=(2,2),s=2 | 64×26×41 |
| 4.2 | 批归一化层 | 64×26×41 |
| 4.3 | ReLU激活函数 | 64×26×41 |
| 5.1 | 卷积层k=(1,1),p=(0,0),s=1 | 2×26×41 |
| 5.2 | 批归一化层 | 2×26×41 |
| 5.3 | Tanh激活函数 | 2×26×41 |
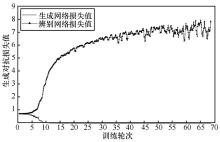
"

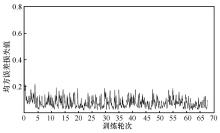
"
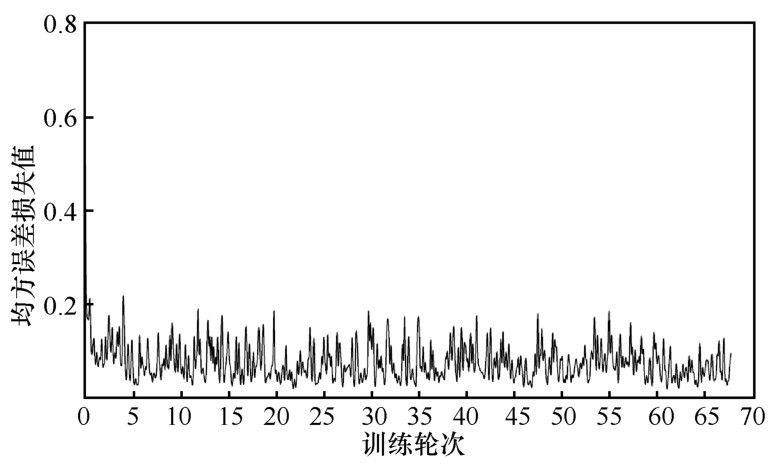
"
| 模型 | MAE | ACC |
| 模型1 | 0.093 3 | 0.57 |
| 模型2 | 0.058 6 | 0.65 |
| 本文模型 | 0.013 5 | 0.78 |

"
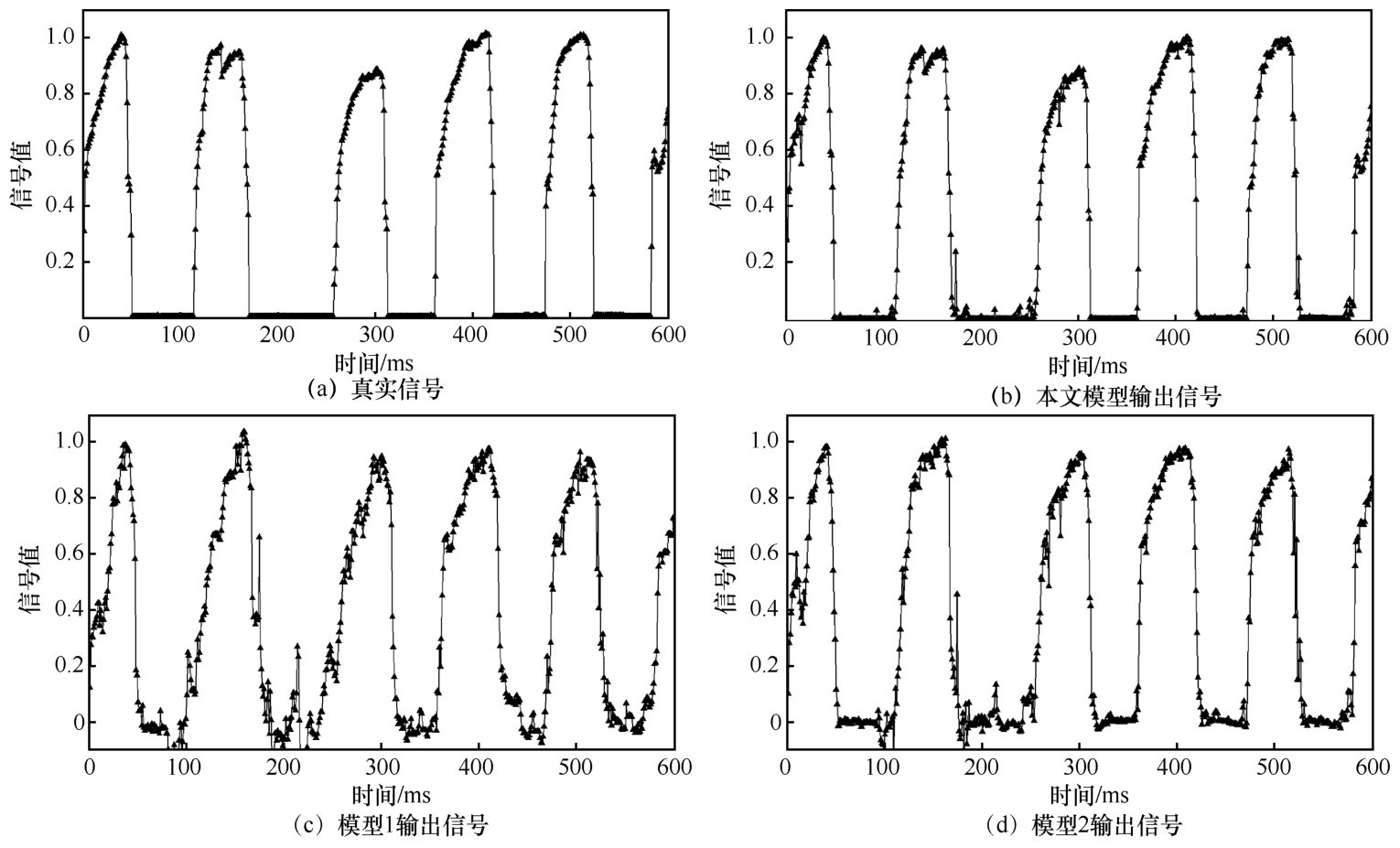
"
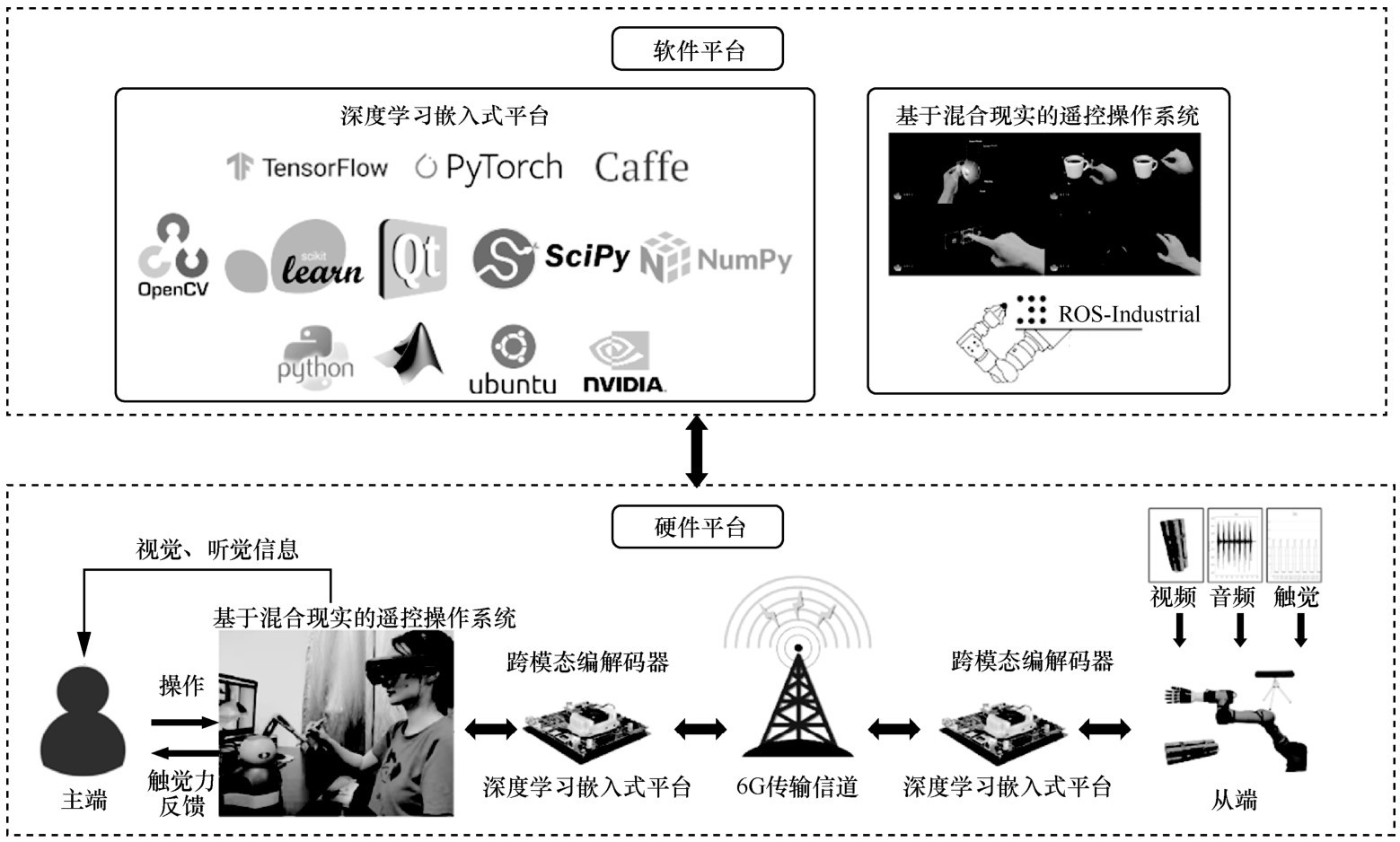
"
| 指标 | 评估结果 |
| MAE | 0.012 6 |
| 发送与反馈总时延/ms | 127 |
| 重建模型时延/ms | 98 |
| 触觉真实性满意度(均值,方差) | (4.43, 0.72) |
| 时延满意度(均值,方差) | (3.87, 1.07) |
| [1] | 中国信息通信研究院. 6G 总体愿景与潜在关键技术白皮书[R]. 2021. |
| China Academy of Information and Communications Technology.. 6G overall vision and potential key technology white paper[R]. 2021. | |
| [2] | VAN D B D , GLANS R , KONING D D ,et al. Challenges in haptic communications over the tactile Internet[J]. IEEE Access, 2017,5: 23502-23518. |
| [3] | ZHOU L , WU D , CHEN J X ,et al. Cross-modal collaborative communications[J]. IEEE Wireless Communications, 2020,27(2): 112-117. |
| [4] | WEI X , ZHOU L . AI-enabled cross-modal communications[J]. IEEE Wireless Communications, 2021,28(4): 182-189. |
| [5] | 高赟, 魏昕, 周亮 . 跨模态通信理论及关键技术初探[J]. 中国传媒大学学报(自然科学版), 2021,28(1): 55-63. |
| GAO Y , WEI X , ZHOU L . Preliminary study on theory and key technology of cross-modal communications[J]. Journal of Communication University of China (Science and Technology), 2021,28(1): 55-63. | |
| [6] | KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017,60(6): 84-90. |
| [7] | SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition[J]. arXiv Preprint,arXiv:1409.1556, 2014. |
| [8] | HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778. |
| [9] | BAZZICA A , VAN GEMERT J C , LIEM C C S ,et al. Vision-based detection of acoustic timed events:a case study on clarinet note onsets[J]. arXiv Preprint,arXiv:1706.09556, 2017. |
| [10] | LI B C , LIU X Z , DINESH K ,et al. Creating a multitrack classical music performance dataset for multimodal music analysis:challenges,insights,and applications[J]. IEEE Transactions on Multimedia, 2019,21(2): 522-535. |
| [11] | ZHAO H , GAN C , ROUDITCHENKO A ,et al. The sound of pixels[C]// Proceedings of the European Conference on Computer Vision. Berlin:Springer, 2018: 570-586. |
| [12] | MONTESINOS J F , SLIZOVSKAIA O , HARO G . Solos:a dataset for audio-visual music analysis[C]// Proceedings of 2020 IEEE 22nd International Workshop on Multimedia Signal Processing. Piscataway:IEEE Press, 2020: 1-6. |
| [13] | KURMI V K , BAJAJ V , PATRO B N ,et al. Collaborative learning to generate audio-video jointly[C]// Proceedings of 2021 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2021: 4180-4184. |
| [14] | ROTH J , CHAUDHURI S , KLEJCH O ,et al. Ava active speaker:an audio-visual dataset for active speaker detection[C]// Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 4492-4496. |
| [15] | TSUCHIDA S , FUKAYAMA S , HAMASAKI M ,et al. AIST dance video database:multi-genre,multi-dancer,and multi-camera database for dance information processing[C]// Proceedings of the 20th International Society for Music Information Retrieval Conference.[S.l.:s.n.], 2019: 501-510. |
| [16] | LI R L , YANG S , ROSS D A ,et al. AI choreographer:music conditioned 3D dance generation with AIST++[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2021: 13381-13392. |
| [17] | HONG S , IM W , YANG H S . Content-based video-music retrieval using soft intra-modal structure constraint[J]. arXiv Preprint,arXiv:1704.06761, 2017. |
| [18] | LI Y Z , ZHU J Y , TEDRAKE R ,et al. Connecting touch and vision via cross-modal prediction[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2019: 10601-10610. |
| [19] | YUAN W Z , DONG S Y , ADELSON E H . GelSight:high-resolution robot tactile sensors for estimating geometry and force[J]. Sensors (Basel,Switzerland), 2017,17(12): 2762. |
| [20] | SUNDARAM S , KELLNHOFER P , LI Y Z ,et al. Learning the signatures of the human grasp using a scalable tactile glove[J]. Nature, 2019,569(7758): 698-702. |
| [21] | DUAN B , WANG W , TANG H ,et al. Cascade attention guided residue learning GAN for cross-modal translation[C]// Proceedings of 2020 25th International Conference on Pattern Recognition (ICPR). Piscataway:IEEE Press, 2021: 1336-1343. |
| [22] | HAO W L , ZHANG Z X , GUAN H . CMCGAN:a uniform framework for cross-modal visual-audio mutual generation[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2018: 6886-6893. |
| [23] | CHATTERJEE M , CHERIAN A . Sound2Sight:generating visual dynamics from sound and context[C]// European Conference on Computer Vision. Berlin:Springer, 2020: 701-719. |
| [24] | WEI X , SHI Y Y , ZHOU L . Haptic signal reconstruction for cross-modal communications[J]. IEEE Transactions on Multimedia, 2021:doi.org/10.1109/TMM.2021.3119860. |
| [25] | 王万良, 李卓蓉 . 生成式对抗网络研究进展[J]. 通信学报, 2018,39(2): 135-148. |
| WANG W L , LI Z R . Advances in generative adversarial network[J]. Journal on Communications, 2018,39(2): 135-148. |
| [1] | Yuling LIU, Cuilin WANG, Zhangjie FU. Generative text steganography method based on emotional expression in semantic space [J]. Journal on Communications, 2023, 44(4): 176-186. |
| [2] | Feibo JIANG, Yubo PENG, Li DONG. Deep image semantic communication model for 6G [J]. Journal on Communications, 2023, 44(3): 198-208. |
| [3] | Xiaoyun WANG, Xiaozhou ZHANG, Liang MA, Yajuan WANG, Mengting LOU, Tao JIANG, Jing JIN, Qixing WANG, Guangyi LIU. Research and optimization on the sensing algorithm for 6G integrated sensing and communication network [J]. Journal on Communications, 2023, 44(2): 219-230. |
| [4] | Jingya YANG, Xiaogang TANG, Yiqing ZHOU, Ling LIU, Wang Jiangzhou. 6G native intelligence network architecture enabled by intent abstraction and knowledge [J]. Journal on Communications, 2023, 44(2): 12-26. |
| [5] | Chao XIA, Yaqi LIU, Qingxiao GUAN, Xin JIN, Yanshuo ZHANG, Shengwei XU. Steganalysis of JPEG images using non-linear residuals [J]. Journal on Communications, 2023, 44(1): 142-152. |
| [6] | Hui LI, Jiali JIN, Shuyu JIN, Weijiao MA. Text steganography method based on automatic selection coding and dynamic word selection strategy [J]. Journal on Communications, 2022, 43(9): 240-253. |
| [7] | Haijun ZHANG, Anqi CHEN, Yabo LI, Keping LONG. Key technologies of 6G mobile network [J]. Journal on Communications, 2022, 43(7): 189-202. |
| [8] | Jianxin LIAO, Xiaoyuan FU, Qi QI, Jingyu WANG, Haifeng SUN. 6G-ADM: knowledge based 6G network management and control architecture [J]. Journal on Communications, 2022, 43(6): 3-15. |
| [9] | Zhiqin WANG, Jiamo JIANG, Peixi LIU, Xiaowen CAO, Yang LI, Kaifeng HAN, Ying DU, Guangxu ZHU. New design paradigm for federated edge learning towards 6G:task-oriented resource management strategies [J]. Journal on Communications, 2022, 43(6): 16-27. |
| [10] | Chuanhong LIU, Caili GUO, Yang YANG, Jiujiu CHEN, Meiyi ZHU, Lu’nan SUN. Intelligent task-oriented semantic communications:theory, technology and challenges [J]. Journal on Communications, 2022, 43(6): 41-57. |
| [11] | Xiaodan WANG, Jingtai LI, Yafei SONG. DDAC: a feature extraction method for model of image steganalysis based on convolutional neural network [J]. Journal on Communications, 2022, 43(5): 68-81. |
| [12] | Pan TANG, Jiaxin LIN, Jianhua ZHANG, Lei TIAN, Zhaowei CHANG, Liang XIA, Qixing WANG. Research on reflection characteristics of the terahertz channel for 6G [J]. Journal on Communications, 2022, 43(5): 102-109. |
| [13] | Xiaoxi ZHANG, Yongjun XU. Survey on backscatter communication for zero-power IoT [J]. Journal on Communications, 2022, 43(11): 199-212. |
| [14] | Wei SHE, Xinpeng RONG, Wei LIU, Zhao TIAN. Generative blockchain-based covert communication model based on Markov chain [J]. Journal on Communications, 2022, 43(10): 121-132. |
| [15] | Xiaoyuan YANG, Xinliang BI, Jia LIU, Siyuan HUANG. High-capacity image steganography algorithm combining image encryption and deep learning [J]. Journal on Communications, 2021, 42(9): 96-105. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||