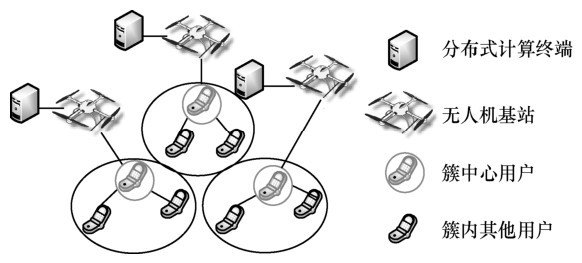
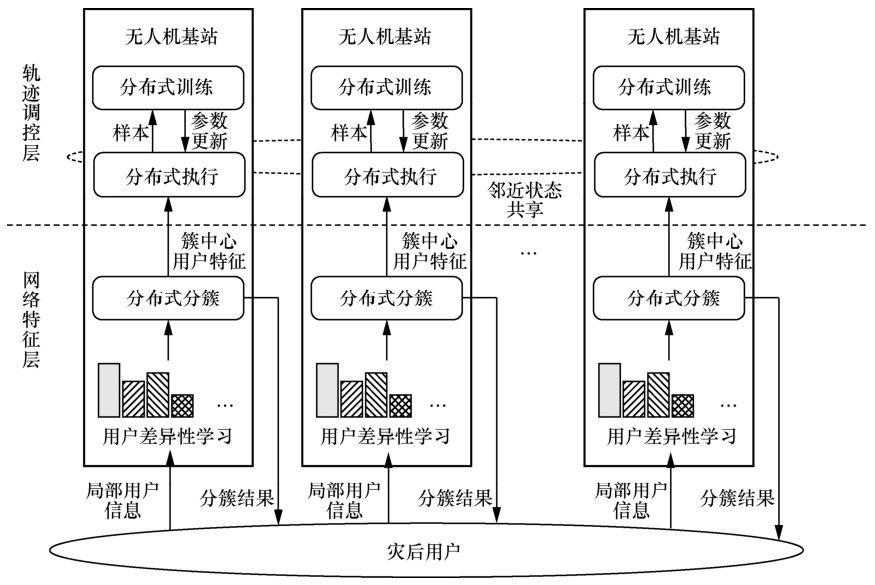
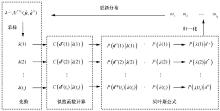
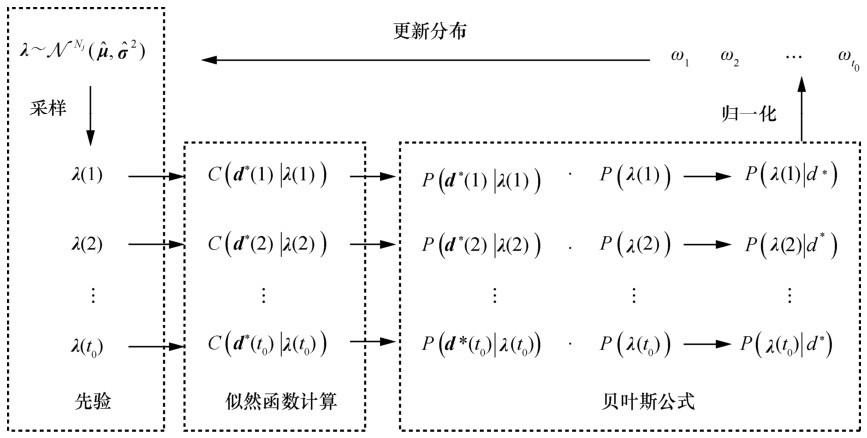
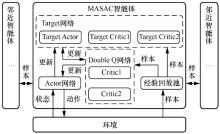
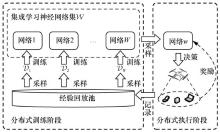
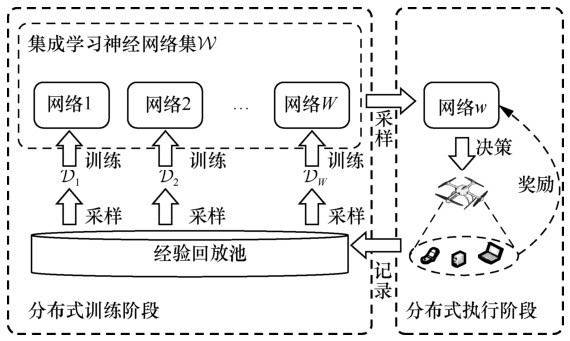
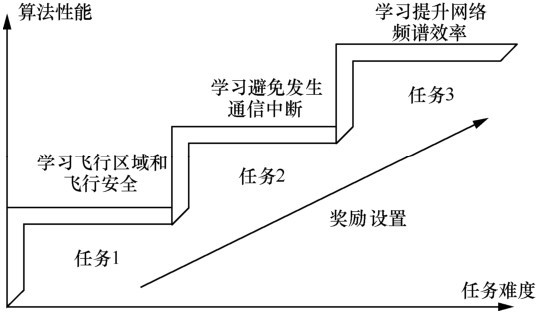
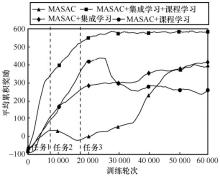
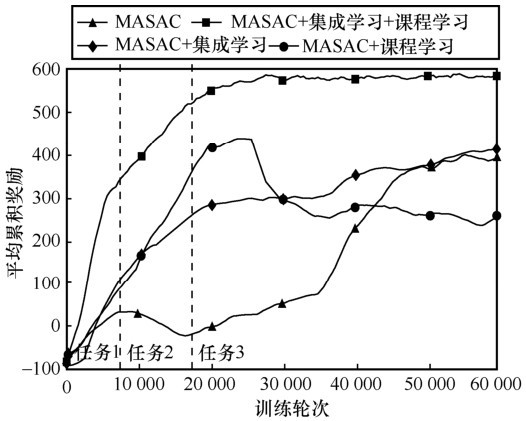
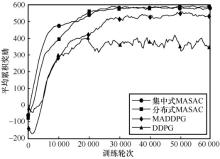
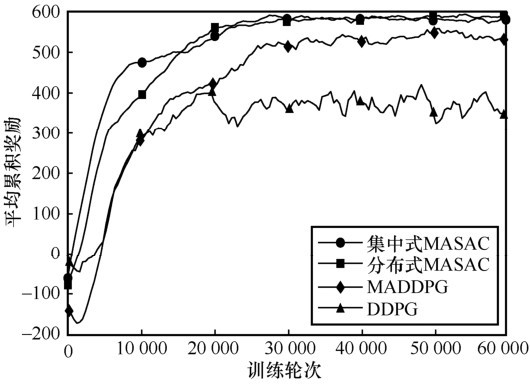
| [1] |
DEEPAK G C , LADAS A , SAMBO Y A ,et al. An overview of post-disaster emergency communication systems in the future networks[J]. IEEE Wireless Communications, 2019,26(6): 132-139.
|
| [2] |
GUO H Z , LI J Y , LIU J J ,et al. A survey on space-air-ground-sea integrated network security in 6G[J]. IEEE Communications Surveys& Tutorials, 2022,24(1): 53-87.
|
| [3] |
ZHOU Y Q , LIU L , WANG L ,et al. Service-aware 6G:an intelligent and open network based on the convergence of communication,computing and caching[J]. Digital Communications and Networks, 2020,6(3): 253-260.
|
| [4] |
ZHANG P , XU W J , GAO H ,et al. Toward wisdom-evolutionary and primitive-concise 6G:a new paradigm of semantic communication networks[J]. Engineering, 2022,8: 60-73.
|
| [5] |
张平, 许晓东, 韩书君 ,等. 智简无线网络赋能行业应用[J]. 北京邮电大学学报, 2020,43(6): 1-9.
|
|
ZHANG P , XU X D , HAN S J ,et al. Entropy reduced mobile networks empowering industrial applications[J]. Journal of Beijing University of Posts and Telecommunications, 2020,43(6): 1-9.
|
| [6] |
ZHOU Y Q , TIAN L , LIU L ,et al. Fog computing enabled future mobile communication networks:a convergence of communication and computing[J]. IEEE Communications Magazine, 2019,57(5): 20-27.
|
| [7] |
KANG Z Y , YOU C S , ZHANG R . 3D placement for multi-UAV relaying:an iterative Gibbs-sampling and block coordinate descent optimization approach[J]. IEEE Transactions on Communications, 2021,69(3): 2047-2062.
|
| [8] |
YIN S X , LI L H , YU F R . Resource allocation and basestation placement in downlink cellular networks assisted by multiple wireless powered UAVs[J]. IEEE Transactions on Vehicular Technology, 2020,69(2): 2171-2184.
|
| [9] |
ZHANG Y X , CHENG W C . Trajectory and power optimization for multi-UAV enabled emergency wireless communications networks[C]// Proceedings of International Conference on Communications Workshops. Piscataway:IEEE Press, 2019: 1-6.
|
| [10] |
LI X , WANG Q , LIU J ,et al. Trajectory design and generalization for UAV enabled networks:a deep reinforcement learning approach[C]// Proceedings of Wireless Communications and Networking Conference. Piscataway:IEEE Press, 2020: 1-6.
|
| [11] |
LIU X , LIU Y W , CHEN Y . Reinforcement learning in multiple-UAV networks:deployment and movement design[J]. IEEE Transactions on Vehicular Technology, 2019,68(8): 8036-8049.
|
| [12] |
CHALLITA U , SAAD W , BETTSTETTER C . Interference management for cellular-connected UAVs:a deep reinforcement learning approach[J]. IEEE Transactions on Wireless Communications, 2019,18(4): 2125-2140.
|
| [13] |
ZHAO N , LIU Z H , CHENG Y Q . Multi-agent deep reinforcement learning for trajectory design and power allocation in multi-UAV networks[J]. IEEE Access, 8: 139670-139679.
|
| [14] |
QIN Z Q , LIU Z H , HAN G J ,et al. Distributed UAV-BSs trajectory optimization for user-level fair communication service with multi-agent deep reinforcement learning[J]. IEEE Transactions on Vehicular Technology, 2021,70(12): 12290-12301.
|
| [15] |
LOWE R , WU Y , TAMAR A ,et al. Multi-agent actor-critic for mixed cooperative-competitive environments[J]. arXiv Preprint,arXiv:1706.02275, 2017.
|
| [16] |
HAARNOJA T , TANG H R , ABBEEL P ,et al. Reinforcement learning with deep energy-based policies[J]. arXiv Preprint,arXiv:1702.08165, 2017.
|
| [17] |
NAVARRO-ORTIZ J , ROMERO-DIAZ P , SENDRA S ,et al. A survey on 5G usage scenarios and traffic models[J]. IEEE Communications Surveys & Tutorials, 2020,22(2): 905-929.
|
| [18] |
3GPP. Technical specification group (TSG) RAN WG4; RF system scenarios:TR 25.942 v2.1.3[S]. 2000.
|
| [19] |
WANG L T , SUN L T , TOMIZUKA M ,et al. Socially-compatible behavior design of autonomous vehicles with verification on real human data[J]. IEEE Robotics and Automation Letters, 2021,6(2): 3421-3428.
|
| [20] |
PEI S , NIE F , WANG R ,et al. Efficient clustering based on a unified view of k-means and ratio-cut[J]. Advances in Neural Information Processing Systems, 2020,33: 14855-14866.
|
| [21] |
HAARNOJA T , ZHOU A , ABBEEL P ,et al. Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]// International Conference on Machine Learning. New York:PMLR, 2018: 1861-1870.
|
| [22] |
HASSELT H V , GUEZ A , SILVER D . Deep reinforcement learning with double Q-learning[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2016: 2094-2100.
|
| [23] |
DONG X B , YU Z W , CAO W M ,et al. A survey on ensemble learning[J]. Frontiers of Computer Science, 2020,14(2): 241-258.
|
| [24] |
NARVEKAR S , PENG B , LEONETTI M ,et al. Curriculum learning for reinforcement learning domains:a framework and survey[J]. arXiv Preprint,arXiv:2003.04960, 2020.
|
| [25] |
SUTTON R S , BARTO A G . Reinforcement learning:an introduction[M]. Massachusetts: MIT Press, 1998.
|