

Journal on Communications ›› 2024, Vol. 45 ›› Issue (1): 201-213.doi: 10.11959/j.issn.1000-436x.2024004
• Correspondences • Previous Articles
Weijin JIANG1,2,3, Yilin CHEN1,3, Yuqing HAN1,3, Yuting WU1,3, Wei ZHOU1,3, Haijuan WANG3,4
Revised:2023-11-08
Online:2024-01-01
Published:2024-01-01
Supported by:CLC Number:
Weijin JIANG, Yilin CHEN, Yuqing HAN, Yuting WU, Wei ZHOU, Haijuan WANG. Shuffled differential privacy protection method for K-Modes clustering data collection and publication[J]. Journal on Communications, 2024, 45(1): 201-213.
"
| 数据集 | 用户数 | 属性名称 | 属性域大小 |
| Adult | 30 000 | Workclass | 7 |
| Education | 16 | ||
| Relationship | 6 | ||
| Sex | 2 | ||
| Race | 5 | ||
| IPUMS | 30 000 | School | 3 |
| Famsize | 15 | ||
| Sex | 2 | ||
| Race | 8 | ||
| Kosarak | 30 625 | User | 6 |
| Item | 10 |
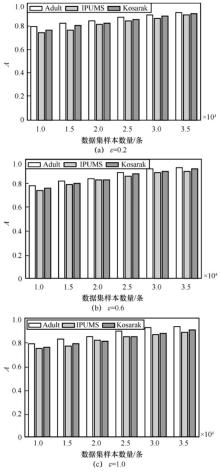
"
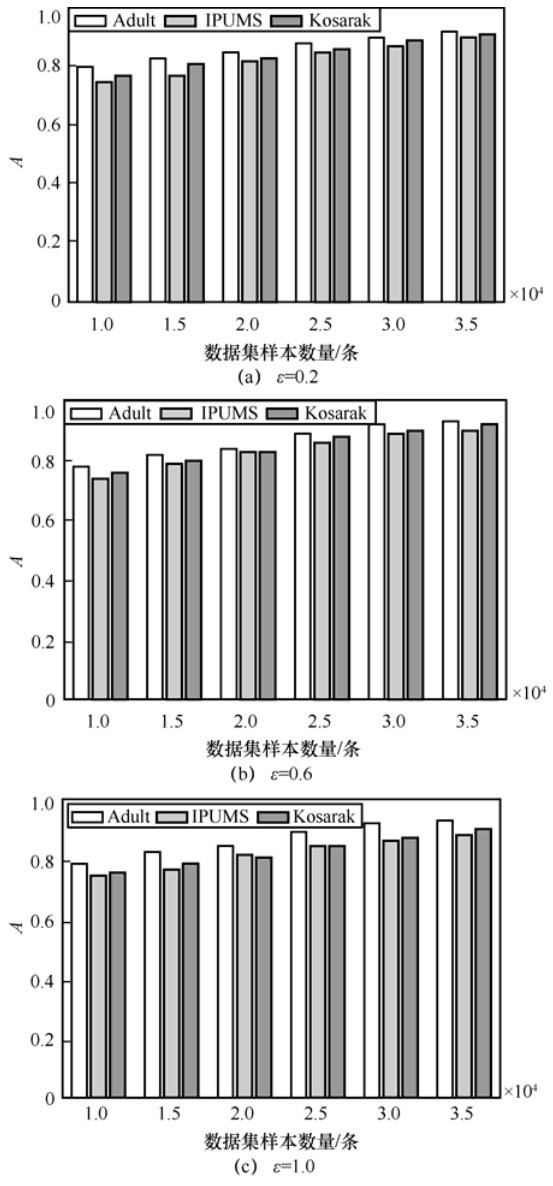
"
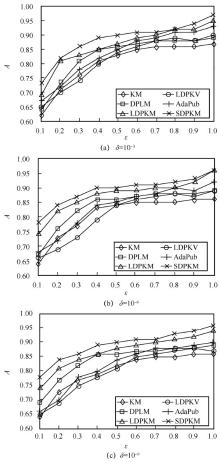
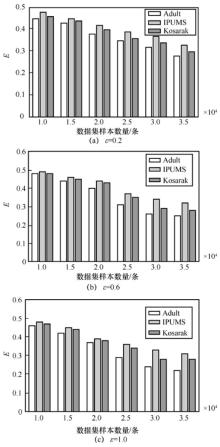
"
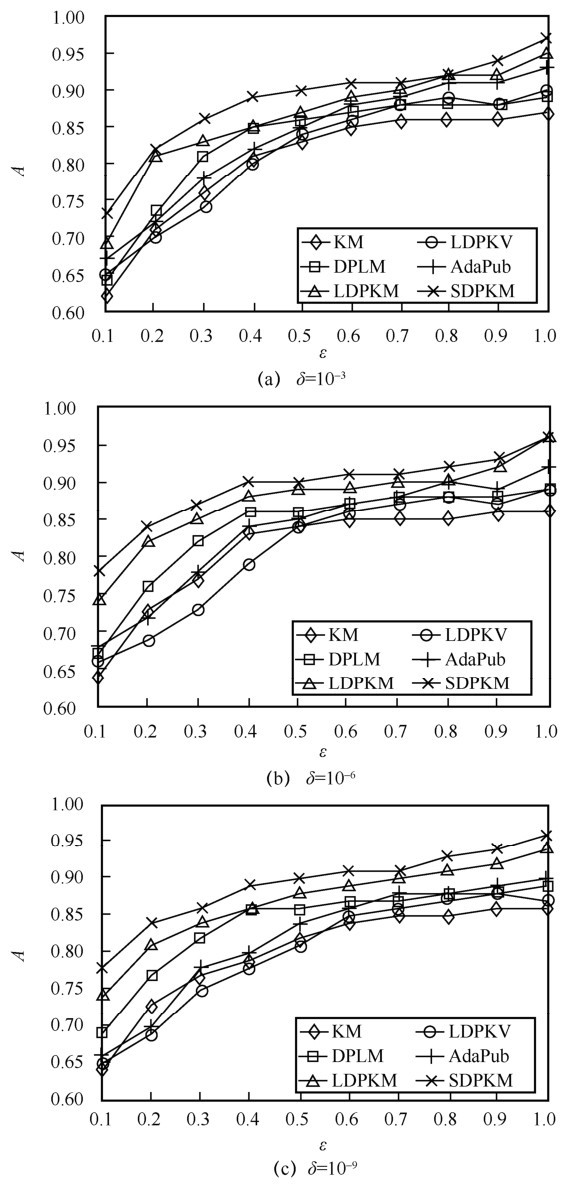
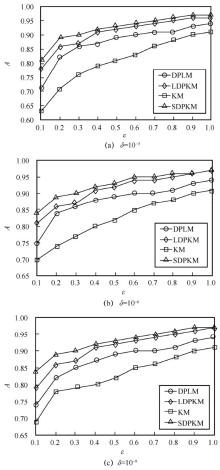
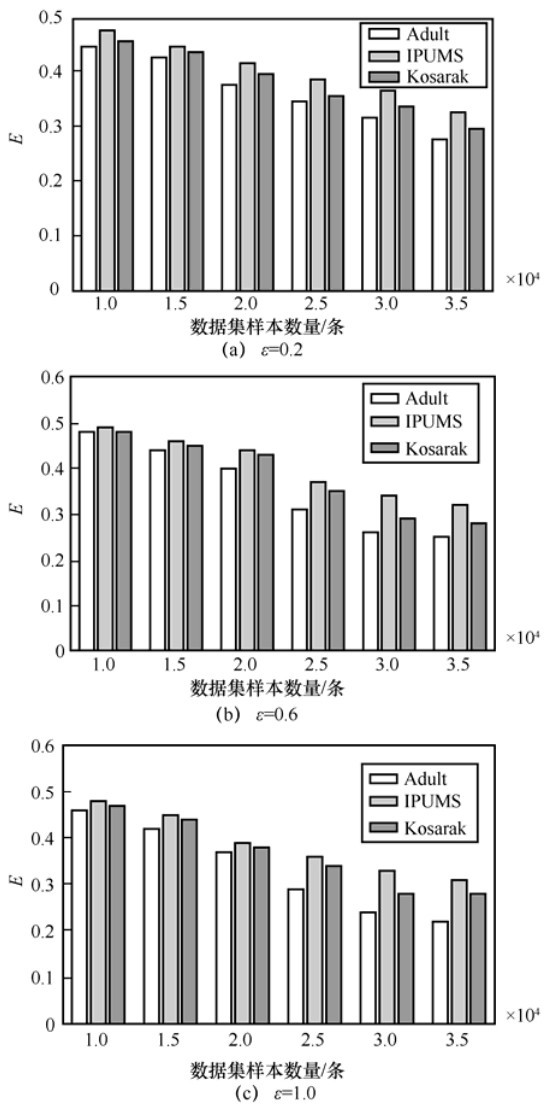
"
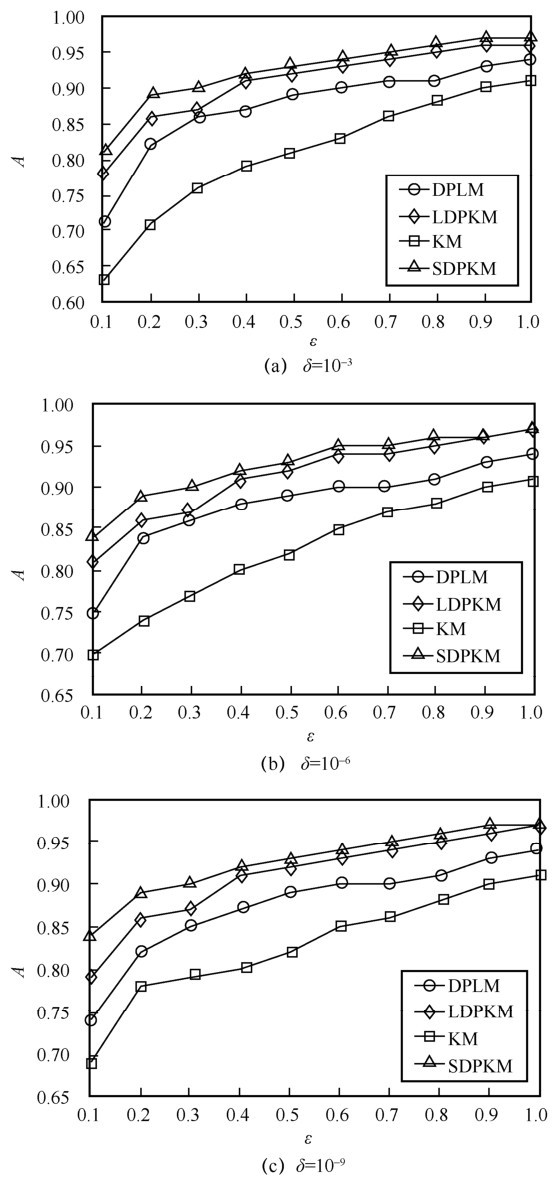
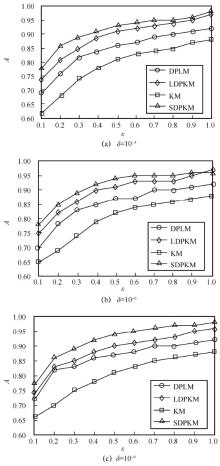
"
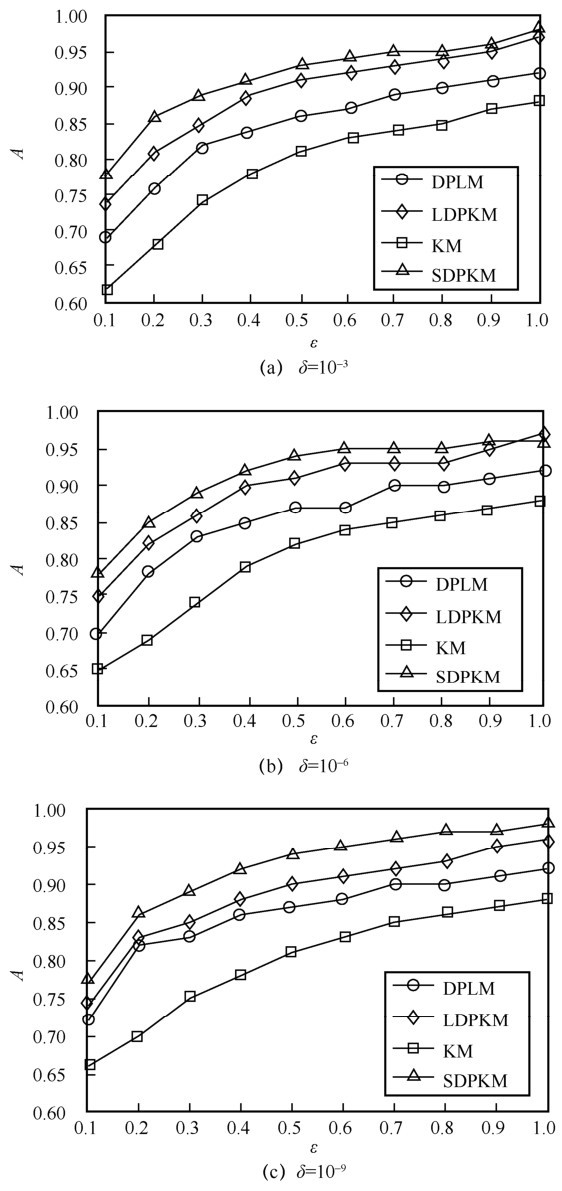
"
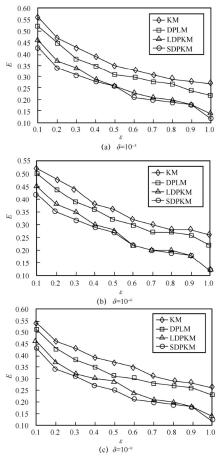
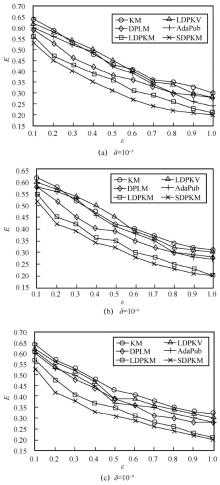
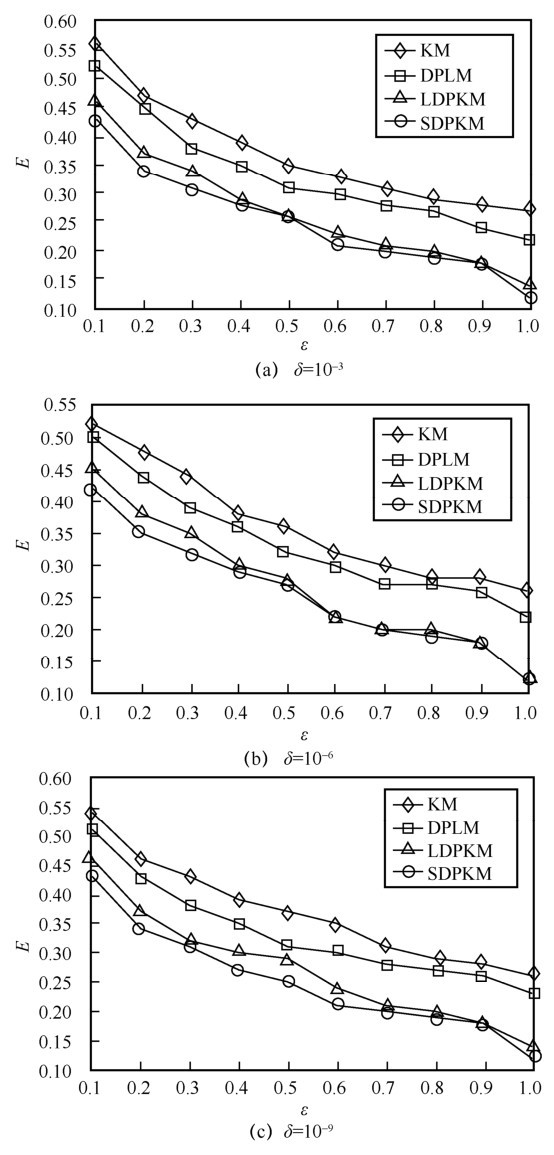
"
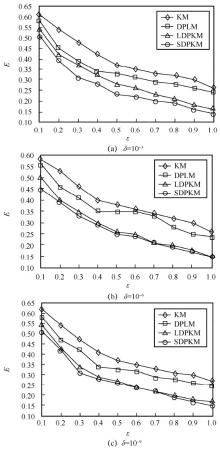
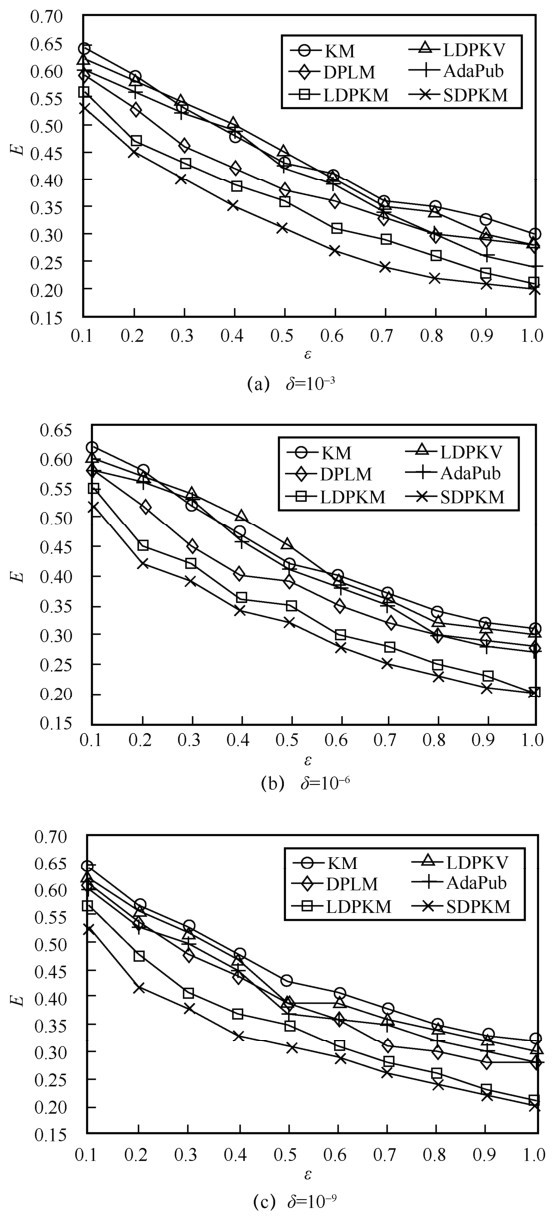
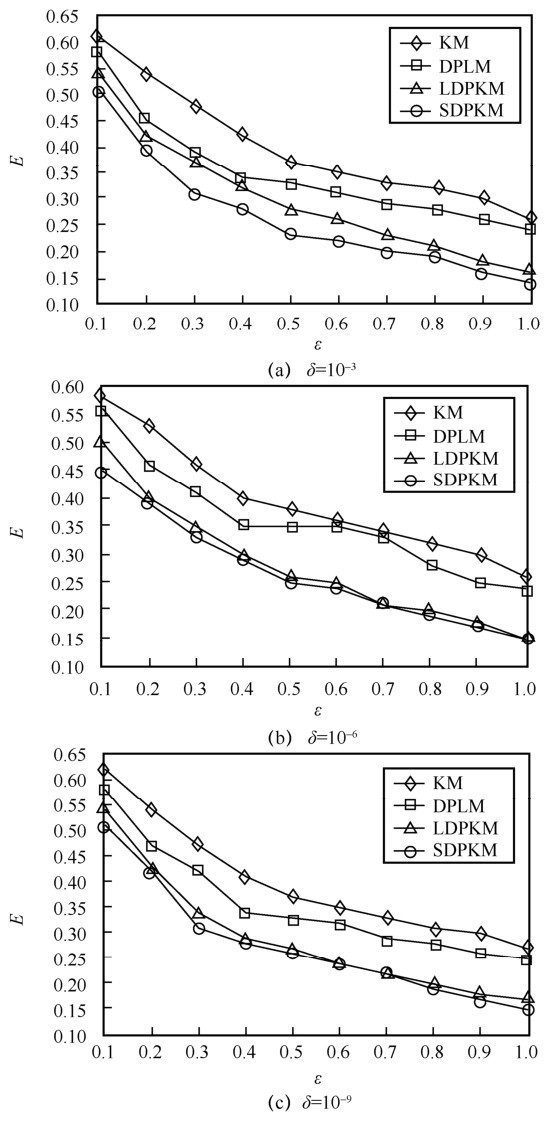
"
| [15] | BALCER V , CHEU A . Separating local & shuffled differential privacy via histograms[J]. arXiv Preprint,arXiv:1911.06879, 2019. |
| [16] | 方晨, 郭渊博, 王娜 ,等. 基于生成对抗网络的差分隐私数据发布方法[J]. 电子学报, 2020,48(10): 1983-1992. |
| FANG C , GUO Y B , WANG N ,et al. Differential private data publishing method based on generative adversarial network[J]. Acta Electronica Sinica, 2020,48(10): 1983-1992. | |
| [17] | LIU P J , LI H Y , WANG T Y ,et al. Multi-stage method for online vertical data partitioning based on spectral clustering[J]. Journal of Software, 2022,34(6): 2804-2832. |
| [18] | ZHANG X J , ZHANG J W , HUANG C ,et al. Verifiable encrypted medical data aggregation and statistical analysis scheme[J]. Journal of Software, 2022,33(11): 4285-4304. |
| [19] | LIANG W J , CHEN H , ZHAO S Y ,et al. A differentially private scheme for top-k frequent itemsets mining over data streams[J]. Chinese Journal of Computers, 2021,44(4): 741-760. |
| [20] | WANG J Y , LIU C , FU X C ,et al. Crucial patterns mining with differential privacy over data streams[J]. Journal of Software, 2019,30(3): 648-666. |
| [21] | CHEN S , FU A M , KE H F ,et al. MCDP:multi-cluster differential privacy data publishing method based on neural network[J]. Acta Electronica Sinica, 2020,48(12): 2297-2303. |
| [22] | TIAN F , WU Z Q , LU L F ,et al. Personalized differential privacy protection mechanism for trajectory data publishing[J]. Chinese Journal of Computer, 2021,44(4): 709-723. |
| [23] | 张东月, 倪巍伟, 张森 ,等. 一种基于本地化差分隐私的网格聚类方法[J]. 计算机学报, 2023,46(2): 422-435. |
| ZHANG D Y , NI W W , ZHANG S ,et al. A local differential privacy based privacy-preserving grid clustering method[J]. Chinese Journal of Computers, 2023,46(2): 422-435. | |
| [1] | XU S Z , CHENG X , SU S ,et al. Differentially private frequent sequence mining[J]. IEEE Transactions on Knowledge and Data Engineering, 2016,28(11): 2910-2926. |
| [2] | WANG N , XIAO X K , YANG Y ,et al. PrivSuper:a superset-first approach to frequent itemset mining under differential privacy[C]// Proceedings of 2017 IEEE 33rd International Conference on Data Engineering (ICDE). Piscataway:IEEE Press, 2017: 809-820. |
| [3] | REN X B , YU C M , YU W R ,et al. LoPub:high-dimensional crowdsourced data publication with local differential privacy[J]. IEEE Transactions on Information Forensics and Security, 2018,13(9): 2151-2166. |
| [4] | WANG T H , LI N H , JHA S . Locally differentially private frequent itemset mining[C]// Proceedings of 2018 IEEE Symposium on Security and Privacy (SP). Piscataway:IEEE Press, 2018: 127-143. |
| [5] | BALLE B , BELL J , GASCóN A , et al . The privacy blanket of the shuffle model[C]// Proceedings of Annual International Cryptology Conference. Cham:Springer, 2019: 638-667. |
| [6] | ERLINGSSON ú , FELDMAN V , MIRONOV I ,et al. Amplification by shuffling:from local to central differential privacy via anonymity[C]// Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms. New York:ACM Press, 2019: 2468-2479. |
| [7] | WANG T , DING B , XU M ,et al. Improving utility and security of the shuffler-based differential privacy[J]. arXiv Preprint,arXiv:1908.11515, 2019. |
| [8] | LIU Y F , WANG N , WANG Z G ,et al. Collecting and analyzing multidimensional categorical data under shuffled differential privacy[J]. Journal of Software, 2022,33(3): 1093-1110. |
| [9] | ZHANG S B , YUAN L J , MAO X J ,et al. Privacy protection method for K-Modes clustering data with local differential privacy[J]. Acta Electronica Sinica, 2022,50(9): 2181-2188. |
| [10] | SASSI D B , FRINI A , CHAIEB M ,et al. A rough set-based competitive intelligence approach for anticipating competitor’s action[J]. Expert Systems With Applications, 2022,204:117523. |
| [11] | COELHO A L V , SANDES N C . Data clustering via cooperative games:a novel approach and comparative study[J]. Information Sciences, 2021,545: 791-812. |
| [24] | 陆佳炜, 吴涵, 张元鸣 ,等. 融合功能语义关联计算与密度峰值检测的 Mashup 服务聚类方法[J]. 计算机学报, 2021,44(7): 1501-1515. |
| LU J W , WU H , ZHANG Y M ,et al. Mashup service clustering method via integrating functional semantic association calculation and density peak detection[J]. Chinese Journal of Computers, 2021,44(7): 1501-1515. | |
| [25] | LU S Y , WANG G H , QIU Z H ,et al. Differentially private algorithm for graphical bandits[J]. Journal of Software, 2022,33(9): 3223-3235. |
| [26] | BALAKRISHNAN S , SURESH KUMAR K , BALASUBRAMANIAN M ,et al. Opinion mining for breast cancer disease using apriori and k-modes clustering algorithm[C]// Rising Threats in Expert Applications and Solutions. Berlin:Springer, 2022: 43-51. |
| [27] | 张啸剑, 付楠, 孟小峰 . 基于本地差分隐私的键-值数据精确收集方法[J]. 计算机学报, 2020,43(8): 1479-1492. |
| ZHANG X J , FU N , MENG X F . Key-value data accurate collection under local differential privacy[J]. Chinese Journal of Computers, 2020,43(8): 1479-1492. | |
| [28] | TENG W , YANG X Y , REN X B ,et al. Data-adaptive privacy-preserving mechanism for data stream publishing in real-time[J]. 2021,doi:10.1360/SSI-2020-0076. |
| [29] | OUYANG J , YIN J , XIAO Z H ,et al. Transaction data collection for itemset mining under local differential privacy[J]. Journal of Software, 2021,32(11): 3541-3562. |
| [30] | MANCHINI C , OSPINA R , LEIVA V ,et al. A new approach to data differential privacy based on regression models under heteroscedasticity with applications to machine learning repository data[J]. Information Sciences, 2023,627: 280-300. |
| [12] | XIAO Y Y , HUANG C H , HUANG J Y ,et al. Optimal mathematical programming and variable neighborhood search for k-modes categorical data clustering[J]. Pattern Recognition, 2019,90: 183-195. |
| [13] | DUAN Y Q , YUAN H L , LAI C S ,et al. Fusing local and global information for one-step multi-view subspace clustering[J]. Applied Sciences, 2022,12(10): 5094. |
| [14] | ZHANG X J , XU Y X , XIA Q R . Histogram publication under shuffled differential privacy[J]. Journal of Software, 2022,33(6): 2348-2363. |
| [1] | Yuchao ZHU, Shaowei WANG. Coordinated UAV-UGV trajectory planning based on load balancing in IoT data collection [J]. Journal on Communications, 2024, 45(1): 41-53. |
| [2] | Zhiheng WANG, Yanyan XU. Survey on privacy protection indoor positioning [J]. Journal on Communications, 2023, 44(9): 188-204. |
| [3] | Xindi MA, Qinghua LI, Qi JIANG, Zhuo MA, Sheng GAO, Youliang TIAN, Jianfeng MA. Byzantine-robust federated learning over Non-IID data [J]. Journal on Communications, 2023, 44(6): 138-153. |
| [4] | Tao FENG, Liqiu CHEN, Junli FANG, Jianming SHI. Blockchain data sharing scheme based on localized difference privacy and attribute-based searchable encryption [J]. Journal on Communications, 2023, 44(5): 224-233. |
| [5] | Baiji HU, Xiaojuan ZHANG, Yuancheng LI, Rongxin LAI. Multi-function supported privacy protection data aggregation scheme for V2G network [J]. Journal on Communications, 2023, 44(4): 187-200. |
| [6] | Ming XU, Baojun ZHANG, Yiming WU, Chenduo YING, Ning ZHENG. Cyber attacks and privacy protection distributed consensus algorithm for multi-agent systems [J]. Journal on Communications, 2023, 44(3): 117-127. |
| [7] | Xuewang ZHANG, Zhihong LI, Jinzhao LIN. Privacy protection scheme based on fair blind signature and hierarchical encryption for consortium blockchain [J]. Journal on Communications, 2022, 43(8): 131-141. |
| [8] | Jifeng WANG, Guofeng WANG. Research on ciphertext search and sharing technology in edge computing mode [J]. Journal on Communications, 2022, 43(4): 227-238. |
| [9] | Huamin FENG, Rui SHI, Feng YUAN, Yanjun LI, Yang YANG. Efficient strong privacy protection and transferable attribute-based ticket scheme [J]. Journal on Communications, 2022, 43(3): 63-75. |
| [10] | Yan YAN, Yiming CONG, Mahmood Adnan, Quanzheng SHENG. Statistics release and privacy protection method of location big data based on deep learning [J]. Journal on Communications, 2022, 43(1): 203-216. |
| [11] | Hongtao LI, Xiaoyu REN, Jie WANG, Jianfeng MA. Continuous location privacy protection mechanism based on differential privacy [J]. Journal on Communications, 2021, 42(8): 164-175. |
| [12] | Hui LIU, Xinyan LIU, Yan XU, Hong ZHONG, Meng WANG. Privacy protection of warning message publishing protocol in VANET [J]. Journal on Communications, 2021, 42(8): 120-129. |
| [13] | Wenbo ZHANG, Wenhua HUANG, Jingyu FENG. Secure communication mechanism for VSN based on certificateless signcryption [J]. Journal on Communications, 2021, 42(7): 128-136. |
| [14] | Guangjun LIU, Wangmei GUO, Jinbo XIONG, Ximeng LIU, Changyu DONG. Lightweight privacy protection data auditing scheme for regenerating-coding-based distributed storage [J]. Journal on Communications, 2021, 42(7): 220-230. |
| [15] | Jie CUI, Xuefeng CHEN, Jing ZHANG, Lu WEI, Hong ZHONG. Bus cache-based location privacy protection scheme in the Internet of vehicles [J]. Journal on Communications, 2021, 42(7): 150-161. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||