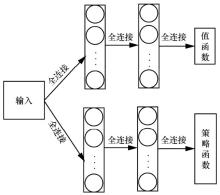
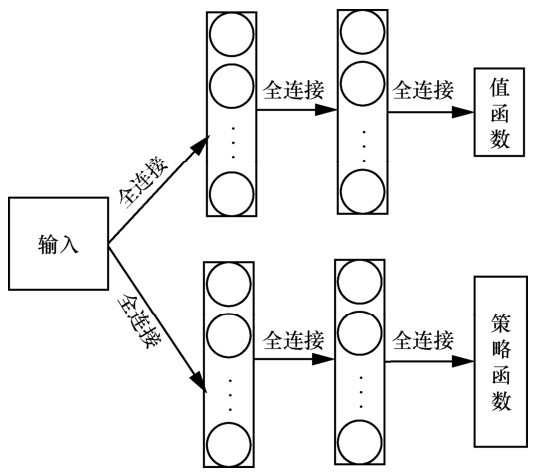
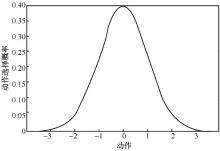
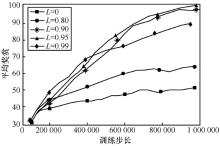
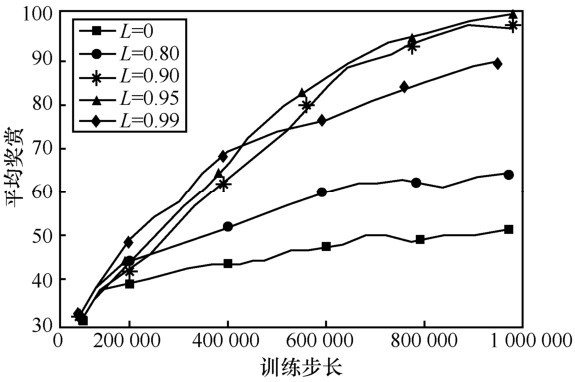
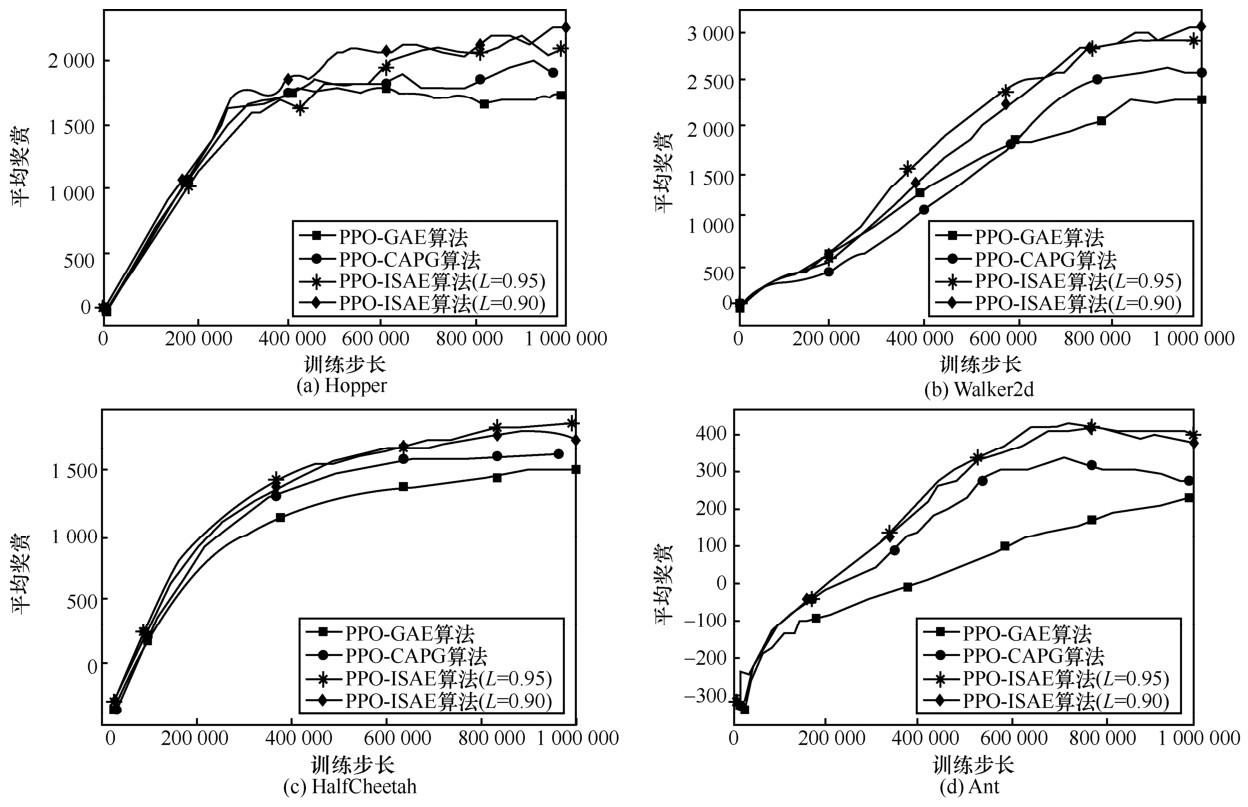
| [1] |
SUTTON R S , BARTO A G . Introduction to reinforcement learning[M]. Cambridge: MIT pressPress, 1998.
|
| [2] |
刘全, 傅启明, 龚声蓉 . 最小状态变元平均奖赏的强化学习方法[J]. 通信学报, 2011,32(1): 66-71.
|
|
LIU Q , FU Q M , GONG S R . Reinforcement learning algorithm based on minimum state method and average reward[J]. Journal on Communications, 2011,32(1): 66-71.
|
| [3] |
TANG J , DENG C , HUANG G B . Extreme learning machine for multilayer perceptron[J]. IEEE Transactions on Neural Networks and Learning Systems, 2016,27(4): 809-821.
|
| [4] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . Imagenet classification with deep convolutional neural networks[C]// Advances in Neural Information Processing Systems. 2012: 1097-1105.
|
| [5] |
VEERIAH V , VAN S H , SUTTON R S . Forward actor-Critic for nonlinear function approximation in reinforcement learning[C]// Conference on Autonomous Agents and Multiagent Systems. 2017: 556-564.
|
| [6] |
LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015,521(7553): 436-444.
|
| [7] |
MNIH V , KAVUKCUOFLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533.
|
| [8] |
MNIH V , BADIA A P , MIRZA M ,et al. Asynchronous methods for deep reinforcement learning[C]// International Conference on Machine Learning. 2016: 1928-1937.
|
| [9] |
VAN H , GUEZ A , SILVER D . Deep reinforcement learning with double Q-learning[C]// Thirtieth AAAI Conference on Artificial Intelligence. 2016: 2094-2100.
|
| [10] |
WANG Z , SCHAUL T , HESSEL M ,et al. Dueling network architectures for deep reinforcement learning[C]// International Conference on Machine Learning. 2016: 1995-2003.
|
| [11] |
SAMEJIMA K , DOYA K , KAWATO M . Inter-module credit assignment in modular reinforcement learning[J]. Neural Networks, 2003,16(7): 985-994.
|
| [12] |
SINGH S P , SUTTON R S . Reinforcement learning with replacing eligibility traces[J]. Machine Learning, 1996,22(1-3): 123-158.
|
| [13] |
WATKINS C J C H . Learning from delayed rewards[D]. Cambridge:King’s College, 1989.
|
| [14] |
SUTTON R S . Temporal credit assignment in reinforcement learning[D]. Amherst:University of Massachusetts, 1984.
|
| [15] |
VAN S H , MAHMOOD A R , PILARSKI P M ,et al. True online temporal-difference learning[J]. The Journal of Machine Learning Research, 2016,17(1): 5057-5096.
|
| [16] |
HO J , ERMON S . Generative adversarial imitation learning[C]// Advances in Neural Information Processing Systems. 2016: 4565-4573.
|
| [17] |
MNIH V , BADIA A P , MIRZA M ,et al. Asynchronous methods for deep reinforcement learning[C]// International Conference on Machine Learning. 2016: 1928-1937.
|
| [18] |
SCHULMAN J , LEVINE S , ABBEEL P ,et al. Trust region policy optimization[C]// International Conference on Machine Learning. 2015: 1889-1897.
|
| [19] |
CHUA K , CALANDRA R , MCALLISTER R ,et al. Deep reinforcement learning in a handful of trials using probabilistic dynamics models[C]// Advances in Neural Information Processing Systems. 2018.
|
| [20] |
FUJITA Y , MAEDA S . Clipped action policy gradient[C]// International Conference on Machine Learning. 2018: 1592-1601.
|
| [21] |
THODOROFF P , DURAND A , PINEAU J ,et al. Temporal regularization for Markov decision process[C]// Advances in Neural Information Processing Systems. 2018: 1779-1789.
|
| [22] |
DOYA K . Reinforcement learning in continuous time and space[J]. Neural Computation, 2000,12(1): 219-245.
|
| [23] |
HESSEL M , MODAYIL J , VAN H H ,et al. Rainbow:combining improvements in deep reinforcement learning[C]// Thirty-Second AAAI Conference on Artificial Intelligence. 2018: 3215-3222.
|