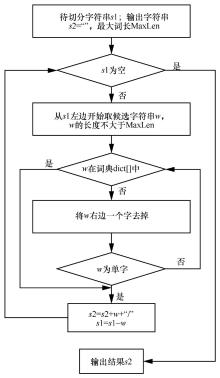
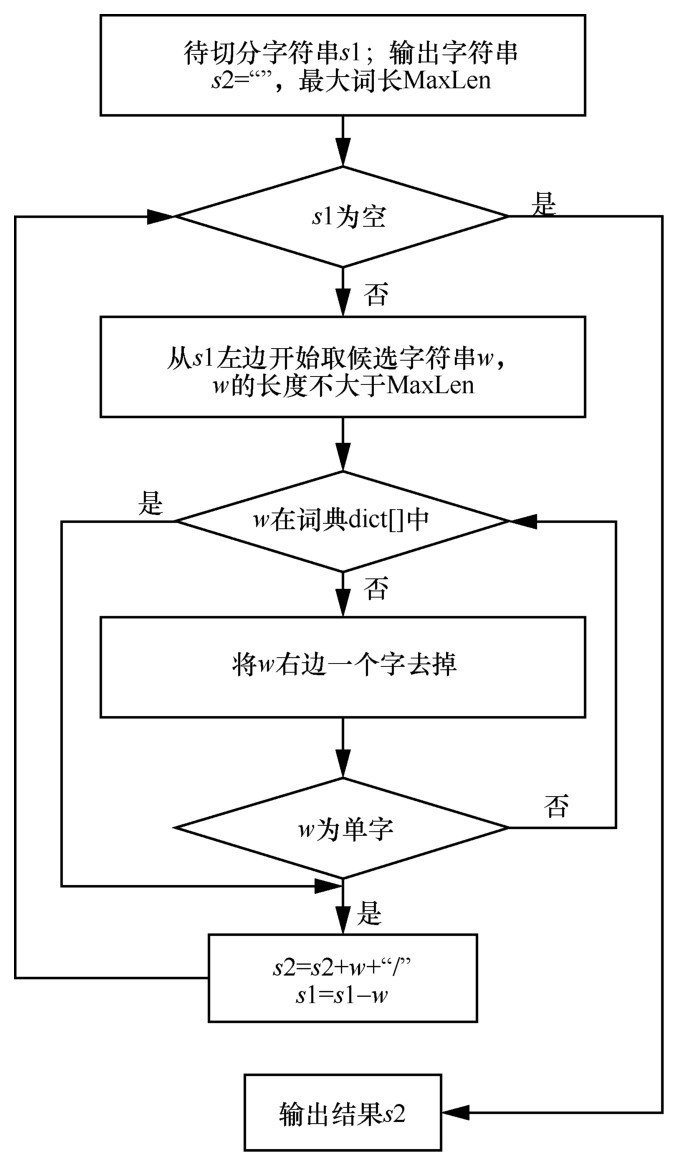
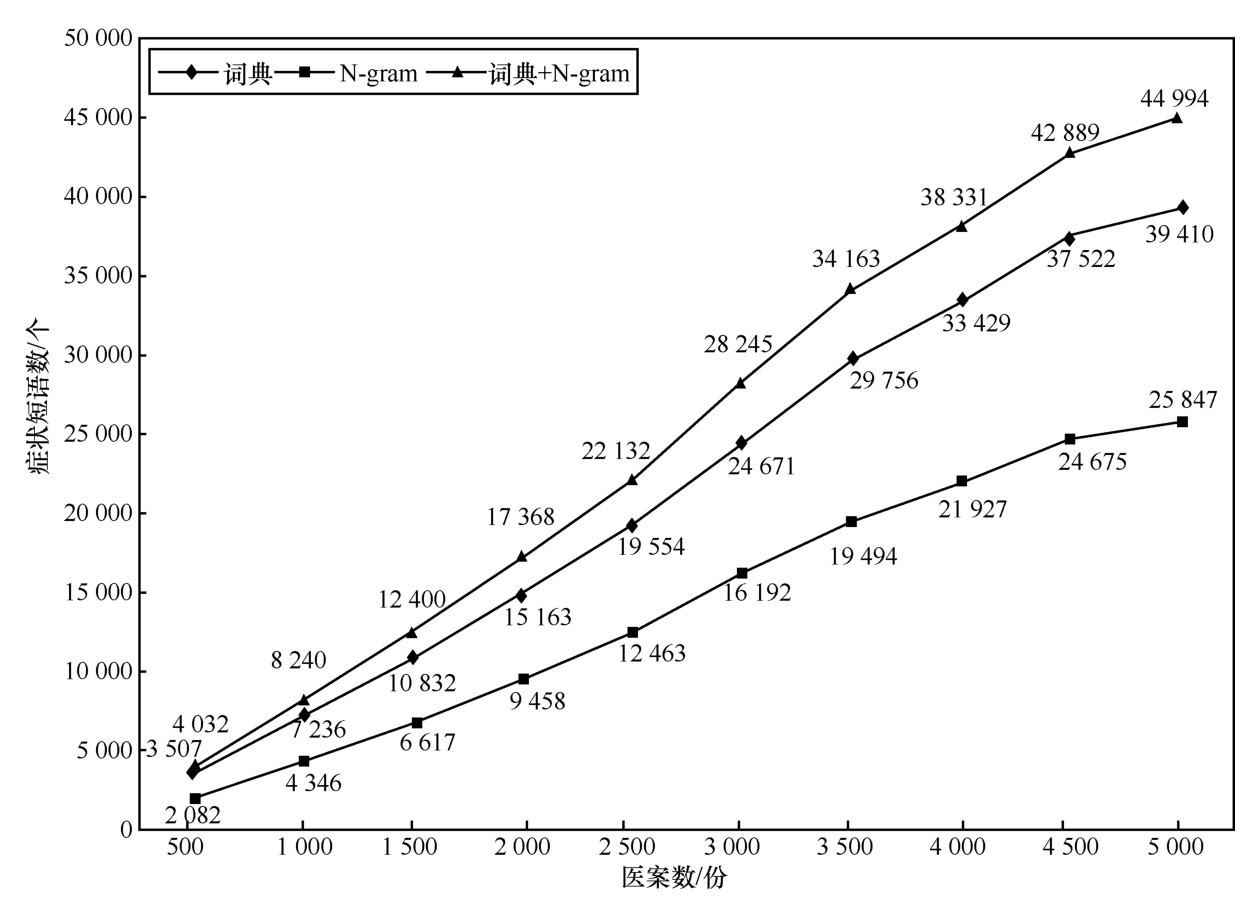
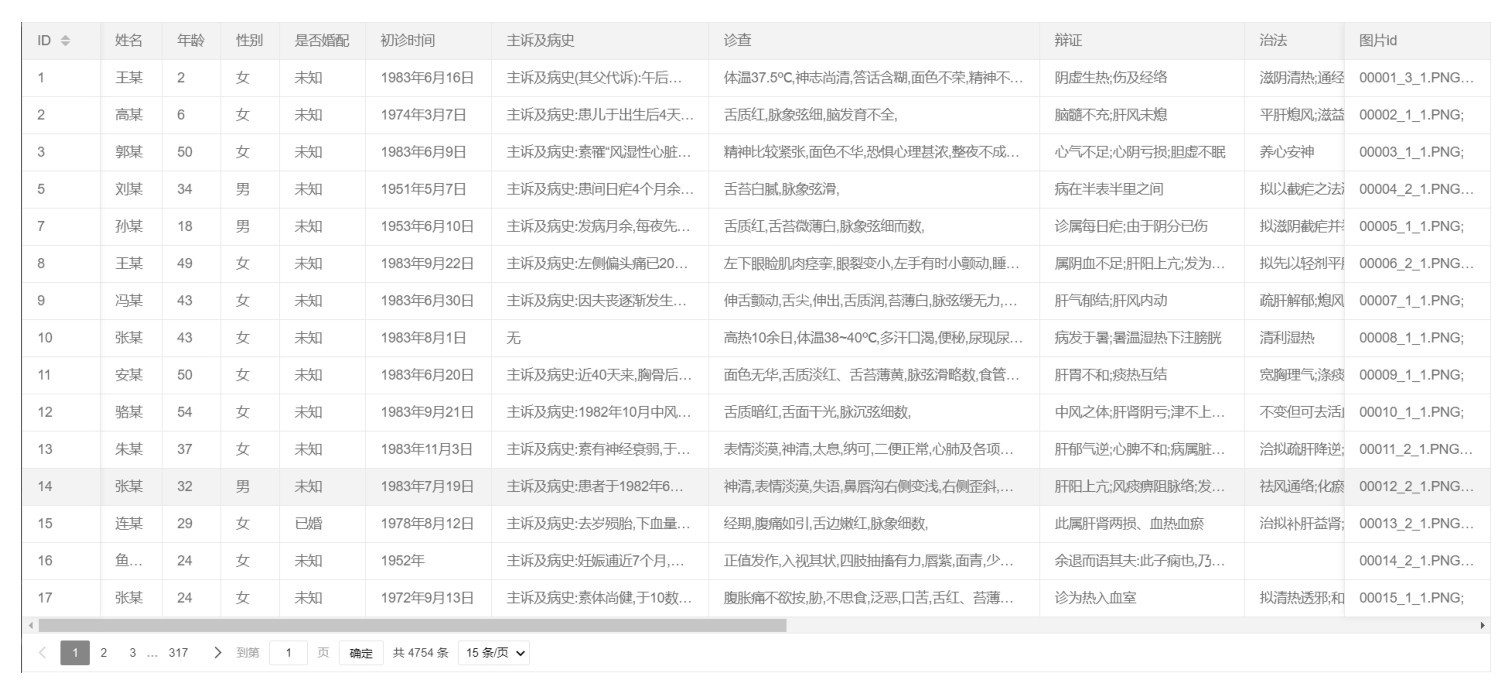
| [1] |
滕文静, 孙长岗, 李雁 . 浅谈不同中医医案研究方法对临床思维建立的重要性[J]. 中华中医药杂志, 2018,33(3): 811-815.
|
|
TENG W J , SUN C G , LI Y . Discussion on the importance about different research methods of traditional Chinese medicine cases to the establishment of clinical thinking[J]. China Journal of Traditional Chinese Medicine and Pharmacy, 2018,33(3): 811-815.
|
| [2] |
肖晓霞 . 基于机器学习的中医临床症状数据元研究[D]. 长沙:湖南中医药大学, 2018.
|
|
XIAO X X . Research on clinical symptom data elements of traditional Chinese medicine based on machine learning[D]. Changsha:Hunan University of Chinese Medicine, 2018.
|
| [3] |
翟凤文, 赫枫龄, 左万利 . 字典与统计相结合的中文分词方法[J]. 小型微型计算机系统, 2006,27(9): 1766-1771.
|
|
ZHAI F W , HE F L , ZUO W L . Chinese word segmentation based on dictionary and statistics[J]. Journal of Chinese Computer Systems, 2006,27(9): 1766-1771.
|
| [4] |
蒋建洪, 赵嵩正, 罗玫 . 词典与统计方法结合的中文分词模型研究及应用[J]. 计算机工程与设计, 2012,33(1): 387-391.
|
|
JIANG J H , ZHAO S Z , LUO M . Analysis and application of Chinese word segmentation model which consist of dictionary and statistics method[J]. Computer Engineering and Design, 2012,33(1): 387-391.
|
| [5] |
唐琳, 郭崇慧, 陈静锋 . 中文分词技术研究综述[J]. 数据分析与知识发现, 2020,4(S1): 1-17.
|
|
TANG L , GUO C H , CHEN J F . Review of Chinese word segmentation studies[J]. Data Analysis and Knowledge Discovery, 2020,4(S1): 1-17.
|
| [6] |
何晗 . 自然语言处理入门[M]. 北京: 人民邮电出版社, 2019.
|
|
HE H . Introduction natural language processing[M]. Beijing: Posts &Telecom Press, 2019.
|
| [7] |
张帆, 刘晓峰, 孙燕 . 中医医案文献自动分词研究[J]. 中国中医药信息杂志, 2015,22(2): 38-41.
|
|
ZHANG F , LIU X F , SUN Y . Study on automatic word segmentation for traditional Chinese medical record literature[J]. Chinese Journal of Information on Traditional Chinese Medicine, 2015,22(2): 38-41.
|
| [8] |
李明浩, 刘忠, 姚远哲 . 基于LSTM-CRF的中医医案症状术语识别[J]. 计算机应用, 2018,38(S2): 42-46.
|
|
LI M H , LIU Z , YAO Y Z . LSTM-CRF based symptom term recognition on traditional Chinese medical case[J]. Journal of Computer Applications, 2018,38(S2): 42-46.
|
| [9] |
王永炎, 陶广正 . 中国现代名中医医案精粹第5集[M]. 北京: 人民卫生出版社, 2010.
|
|
WANG Y Y , TAO G Z . The essence of medical record from famous modern TCM doctor-episode 5[M]. Beijing: People’s Medical Publishing House, 2010.
|
| [10] |
MARTIN J H . Speech and language processing:an introduction to natural language processing,computational linguistics,and speech recognition[M]. Upper Saddle River: Pearson/Prentice Hall, 2009: 30-31.
|
| [11] |
吴旭东 . 正向最大匹配分词算法的分析与改进[J]. 科技传播, 2011,3(20): 164-165.
|
|
WU X D . Analysis and improvement of forward maximum matching word segmentation algorithm[J]. Public Communication of Science & Technology, 2011,3(20): 164-165.
|
| [12] |
李灿东 . 中医诊断学(新世纪第4版)[M]. 北京: 中国中医药出版社, 2016.
|
|
LI C D . Diagnostics of traditional Chinese medicine (new century 4th edition)[M]. Beijing: China Press of Traditional chinese Medicine, 2016.
|
| [13] |
成战鹰, 王肖龙 . 诊断学基础(第2版)[M]. 北京: 人民卫生出版社, 2016.
|
|
CHENG Z Y , WANG X L . Fundamentals of diagnostics (2nd edition)[M]. Beijing: People’s Medical Publishing House, 2016.
|
| [14] |
BIRD S , KLEIN E , LOPER E . Natural language processing with Python[M]. California: O’Reilly Media Inc., 2009.
|