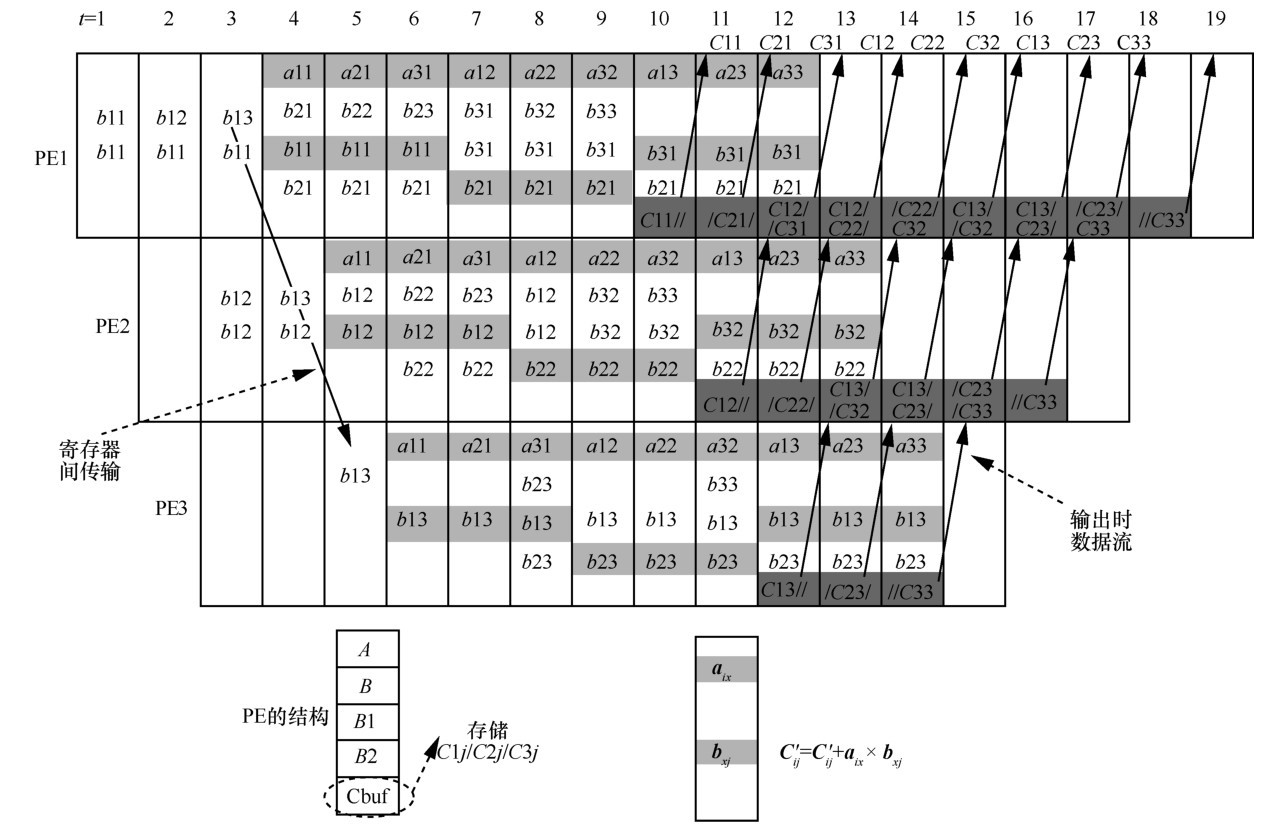
| [10] |
CHEN Y H , KRISHNA T , EMER J S ,et al. Eyeriss:an energy-efficient reconfigurable accelerator for deep convolutional neural networks[J]. IEEE Journal of Solid-State Circuits, 2017,52(1): 127-138.
|
| [11] |
刘勤让, 刘崇阳 . 利用参数稀疏性的卷积神经网络计算优化及其FPGA加速器设计[J]. 电子与信息学报, 2018,40(6): 1368-1374.
|
|
LIU Q R , LIU C Y . Calculation optimization for convolutional neural networks and FPGA-based accelerator design using the parameters sparsity[J]. JEIT, 2018,40(6): 1368-1374.
|
| [12] |
LIU X , HAN S , MAO H ,et al. Efficient sparse-winograd convolutional neural networks[C]// International Conference on Learning Representations. 2017.
|
| [13] |
JANG J W , CHOI S B , PRASANNA V K . Energy-and time-efficient matrix multiplication on FPGAs[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2005,13(11): 1305-1319.
|
| [14] |
MATAM K K , LE H , PRASANNA V K . Energy efficient architecture for matrix multiplication on FPGAs[C]// International Conference on Field Programmable Logic and Applications. 2013: 1-4.
|
| [15] |
JIA Y , SHELHAMER E , DONAHUE J ,et al. Caffe:convolutional architecture for fast feature embedding[C]// The 22nd ACM International Conference on Multimedia. 2014: 675-678.
|
| [16] |
JIA Y Q . Optimzing conv in caffe[R].
|
| [17] |
MOONS B , DE BRABANDERE B , VAN GOOL L ,et al. Energy-efficient convnets through approximate computing[C]// Applications of Computer Vision. 2016: 1-8.
|
| [18] |
田翔, 周凡, 陈耀武 ,等. 基于 FPGA 的实时双精度浮点矩阵乘法器设计[J]. 浙江大学学报(工学版), 2008,42(9): 1611-1615.
|
|
TIAN X , ZHOU F , CHEN Y W ,et al. Design of field programmable gate array based real-time double-precision floating-point matrix multiplier[J]. Journal of Zhejiang University (Engineering Science), 2008,42(9): 1611-1615.
|
| [19] |
HAN S , POOL J , TRAN J ,et al. Learning both weights and connections for efficient neural network[C]// Annual Conference on Neural Information Processing Systems. 2015: 1135-1143.
|
| [1] |
HAN S , MAO H , DALLY W J . Deep compression:compressing deep neural networks with pruning,trained quantization and huffman coding[J]. Fiber, 2015,56(4): 3-7.
|
| [2] |
QIU J , WANG J , YAO S ,et al. Going deeper with embedded FPGA platform for convolutional neural network[C]// International Symposium on Field-Programmable Gate Arrays. 2016: 26-35.
|
| [3] |
SABOUR S , FROSST N , HINTON G E . Dynamic routing between capsules[C]// Annual Conference on Neural Information Processing Systems. 2017.
|
| [4] |
HAN S , LIU X , MAO H ,et al. EIE:efficient inference engine on compressed deep neural network[J]. ACM Sigarch Computer Architecture News, 2016,44(3): 243-254.
|
| [5] |
CHEN W , WILSON J , TYREE S ,et al. Compressing neural networks with the hashing trick[C]// International Conference on Machine Learning. 2015: 2285-2294.
|
| [6] |
MA Y , CAO Y , VRUDHULA S ,et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks[C]// International Symposium on Field-Programmable Gate Arrays. 2017: 45-54.
|
| [7] |
LI N , TAKAKI S , TOMIOKAY Y ,et al. A multistage dataflow implementation of a deep convolutional neural network based on FPGA for high-speed object recognition[C]// 2016 IEEE Southwest Symposium on Image Analysis and Interpretation. 2016: 165-168.
|
| [8] |
SUDA N , CHANDRA V , DASIKA G ,et al. Throughput-optimized openCL-based FPGA accelerator for large-scale convolutional neural networks[C]// International Symposium on Field-Programmable Gate Arrays. 2016: 16-25.
|
| [9] |
XIAO Q , LIANG Y , LU L ,et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs[C]// The 54th Annual Design Automation Conference. 2017: 62-67.
|
| [20] |
LAI B C C , LIN J L . Efficient designs of multi-ported memory on FPGA[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2017,25(1): 139-150.
|
| [21] |
CHEN J , LI J . The research of peer-to-peer network security[C]// The International Conference on Information Computing and Automation. 2015: 590-592.
|

 ),周俊,王孝龙
),周俊,王孝龙