

Telecommunications Science ›› 2017, Vol. 33 ›› Issue (3): 59-66.doi: 10.11959/j.issn.1000-0801.2017046
• research and development • Previous Articles Next Articles
Zhendong WU,Shucheng PAN,Jianwu ZHANG
Revised:2017-02-13
Online:2017-03-01
Published:2017-04-05
Supported by:CLC Number:
Zhendong WU,Shucheng PAN,Jianwu ZHANG. Continuous speech speaker recognition based on CNN[J]. Telecommunications Science, 2017, 33(3): 59-66.

"

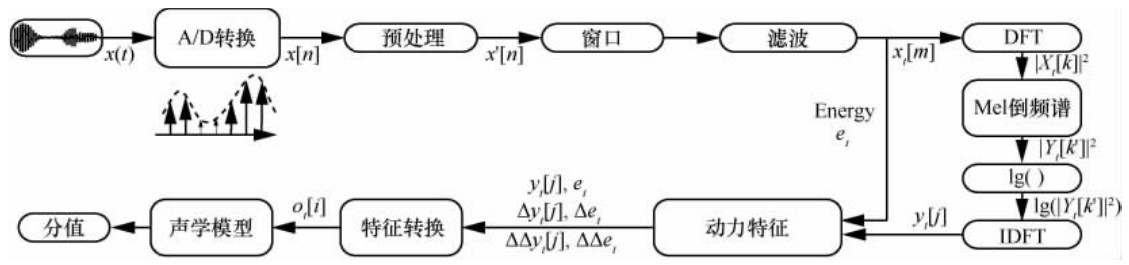
"
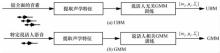
"
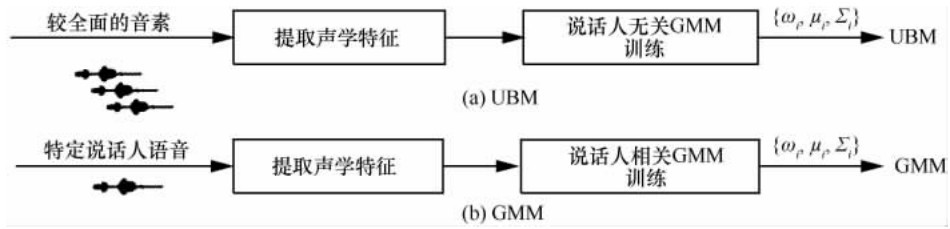
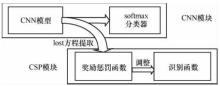
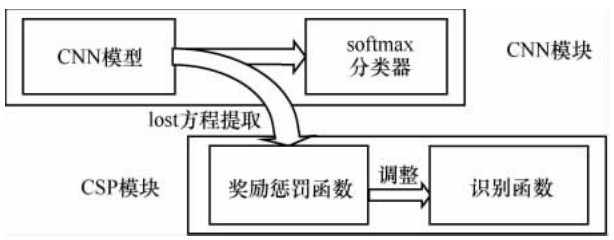
"
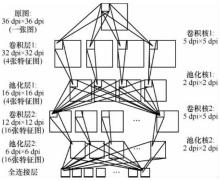
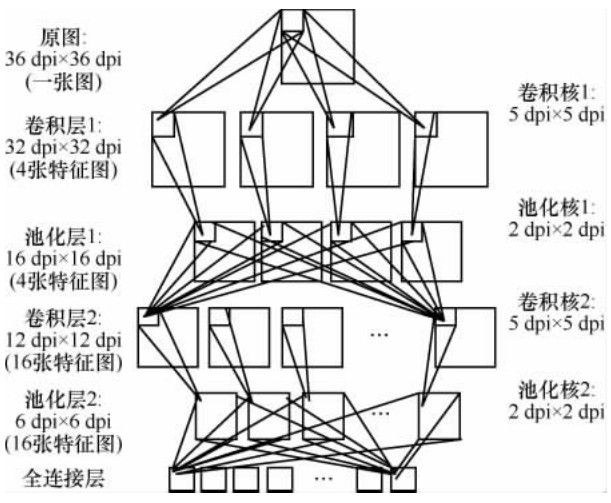
"
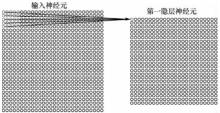
"

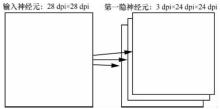
"
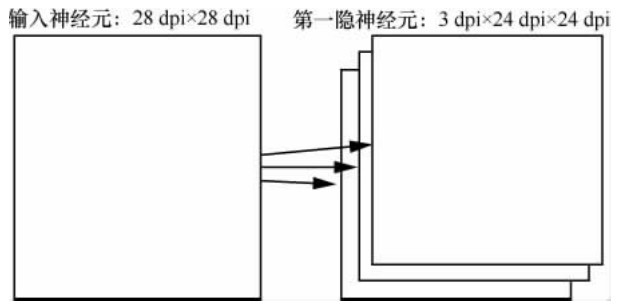
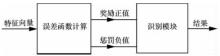
"
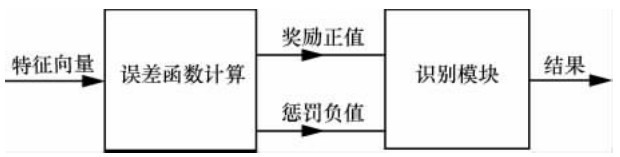

"


"

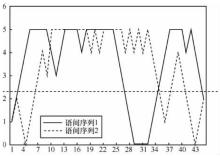
"
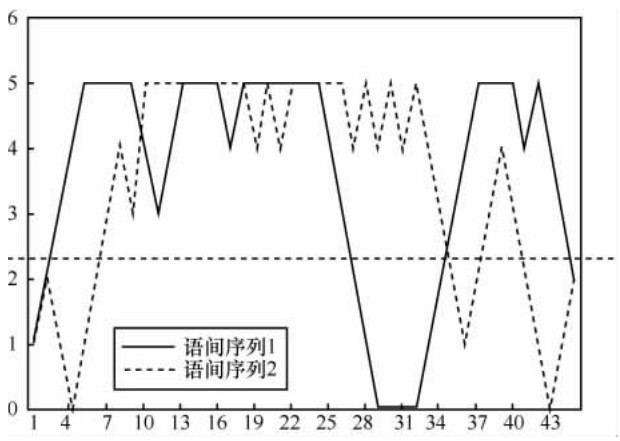
| [1] | SU D , WU X , XU L . GMM-HMM acoustic model training by a two level procedure with Gaussian components determined by automatic model selection[C]// 2010 IEEE International Conference on Acoustics Speech and Signal Processing, March 14-19, 2010, Dallas, TX, USA. New Jersey: IEEE Press, 2010: 4890-4893. |
| [2] | JOACHIMS T . Making large-scale SVM learning practical[J]. Technical Reports, 1998,8(3): 499-526. |
| [3] | REYNOLDS D A , QUATIERI T F , DUNN R B . Speaker verification using adapted gaussian mixture models[J]. Digital Signal Processing, 2000,10(1-3): 19-41. |
| [4] | HEBERT M . Text-dependent speaker recognition[M]. Heidelberg:Springer, 2008: 743-762. |
| [5] | VOGT R J , LUSTI C J , SRIDHARAN S . Factor analysis modeling for speaker verification with short utterances[J]. Journal of Substance Abuse Treatment, 2008,10(1): 11-16. |
| [6] | VOGT R , BAKER B , SRIDHARAN S . Factor analysis subspace estimation for speaker verification with short utterances[C]// INTERSPEECH 2008, Conference of the International Speech Communication Association, Sept 6-10, 2008, Brisbane,Australia. [S.l.: s.n.], 2008: 853-856. |
| [7] | KANAGASUNDARAM A , VOGT R , DEAN D , et al. i-Vector based speaker recognition on short utterances[C]// INTERSPEECH 2011(DBLP), August 27-31. 2011, Florence, Italy. [S.l.: s.n.] 2011. |
| [8] | LARCHER A , BOUSQUET P , KONG A L , et al. i-Vectors in the context of phonetically-constrained short utterances for speaker verification[C]// ICASSP, March 25-30, 2012, Kyoto, Japan. New Jersey: IEEE Press, 2012: 4773-4773. |
| [9] | HINTON G E , SALAKHUTDINOV R R . Reducing the dimensionality of data with neural networks[J]. Science, 2006,313(5786): 504-507. |
| [10] | ZOU M , CONZEN S D . A new dynamic Bayesian network (DBN) approach for identifying gene regulatory networks from time course microarray data[J]. Bioinformatics, 2005,21(1): 71-79. |
| [11] | RUMELHART D E , MCCLELLAND J L . Parallel distributed processing[M]// Cambridge: The MIT Press, 1986: 45-76. |
| [12] | ZORRIA SSATINE F , TANNOCK J D T . A review of neural networks for statistical process control[J]. Journal of Intelligent Manufacturing, 1998,9(3): 209-224. |
| [13] | CHEN S H , HWANG S H , WANG Y R . An RNN-based prosodic information synthesizer for Mandarin text-to-speech[J]. IEEE Transactions on Speech & Audio Processing, 1998,6(3): 226-239. |
| [14] | TAN T , QIAN Y , YU D , et al. Speaker-aware training of LSTM-RNNS for acoustic modeling[C]// 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, March 20-25, 2011, Shanghai, China. New Jersey: IEEE Press, 2016: 5280-5284. |
| [15] | GALES M J F . Maximum likelihood linear transformations for HMM-based speech recognition[J]. Computer Speech &Language, 1998,12(2): 75-98. |
| [16] | RAMASWAMY G N , GOPALAKRISHAN P S . Compression of acoustic features for speech recognition in network environments[C]// 1999 IEEE International Conference on Acoustics, Speech and Signal Processing, May 15, 1998, Seattle, WA, USA. New Jersey: IEEE Press, 1998: 977-980. |
| [17] | PAN J , LIU C , WANG Z , et al. Investigation of deep neural networks (DNN) for large vocabulary continuous speech recognition: why DNN surpasses GMMS in acoustic modeling[C]// 2012 International Symposium on Chinese Spoken Language Processing, Dec 5-8, 2012, Kowloon Tong, China. New Jersey: IEEE Press, 2012: 301-305. |
| [18] | HUANG Z , TANG J , XUE S , et al. Speaker adaptation of RNN-BLSTM for speech recognition based on speaker code[C]// IEEE International Conference on Acoustics, Speech and Signal Processing, March 20-25, 2016, Shanghai, China. New Jersey: IEEE Press, 2016: 5305-5309. |
| [19] | SAATCI E , TAVASANOGLU V . Multiscale handwritten character recognition using CNN image filters[C]// 2002 International Joint Conference on Neural Networks, May 12-17, 2002, Honolulu, HI, USA. New Jersey: IEEE Press, 2002: 2044-2048. |
| [20] | LIU K , ZHANG M , PAN Z . Facial expression recognition with CNN ensemble[C]// International Conference on Cyberworlds, Sept 28-30, 2016, Chongqing, China. New Jersey: IEEE Press, 2016: 163-166. |
| [21] | JURISIC F , FILKOVIC I , KALAFATIC Z . Multiple-dataset traffic sign classification with OneCNN[C]// Iapr Asian Conference on Pattern Recognition, Nov 3-6, 2015, Kuala Lumpur,Malaysia. New Jersey: IEEE Press, 2015: 614-618. |
| [22] | ZHANG L , LIN L , LIANG X , et al. Is faster R-CNN doing well for pedestrian detection?[M]. Heidelberg: Springer-Verlag: 443-457. |
| [23] | ZHENG Y , LI Z , ZHANG C . A hybrid architecture based on CNN for image semantic annotation[M]//SHI Z Z, VADERA S,LI G. Intelligent Information Processing Ⅷ, Heidelberg:Springer, 2016: 81-90. |
| [24] | PARMAKSIZOGLU S , ALCI M . A novel cloning template designing method by using an artificial bee colony algorithm for edge detection of CNN based imaging sensors[J]. Sensors, 2011,11(5): 5337-5359. |
| [1] | Min LU, Juan HU, Xianchao ZHANG, Weijian DING, Guangxue YUE. Personalized recommendation model based on users multi-features fusion [J]. Telecommunications Science, 2023, 39(5): 101-115. |
| [2] | Bin ZHUGE, Zhenghu YIN, Wenxue SI, Lei YAN, Ligang DONG, Xian JIANG. Student knowledge tracking based multi-indicator exercise recommendation algorithm [J]. Telecommunications Science, 2022, 38(9): 129-143. |
| [3] | Jie ZHOU, Bernardo Esono Esono Mikue, Xueying WANG, Huiting ZHOU, Hong LUO. PAPR optimization based on SLM and PTS algorithms in NC-OFDM systems [J]. Telecommunications Science, 2022, 38(7): 63-74. |
| [4] | Panpan LI, Zhengxia XIE, Guangxue YUE, Xin LIU. Research progress and trends of deep learning based wireless communication receiving method [J]. Telecommunications Science, 2022, 38(2): 1-17. |
| [5] | Qing SHEN, Wenbin GUO, Jungang LOU, Qiangguo YU. Personalized recommendation model with multi-level latent features [J]. Telecommunications Science, 2022, 38(2): 71-83. |
| [6] | Zhihong CHEN, Mingxiao WANG. Application of computer vision in intelligent security [J]. Telecommunications Science, 2021, 37(8): 142-147. |
| [7] | Boheng TANG, Xingang CHAI. Cloud-edge collaboration based computer vision inference mechanism [J]. Telecommunications Science, 2021, 37(5): 72-81. |
| [8] | Shujun SUN, Shengliang PENG, Yudong YAO, Xi YANG. A survey of deep learning based modulation recognition [J]. Telecommunications Science, 2021, 37(5): 82-90. |
| [9] | Shuang PENG, Xiaodong WANG, Zongju PENG, Fen CHEN. Fast QTMT partition decision based on deep learning [J]. Telecommunications Science, 2021, 37(4): 73-81. |
| [10] | Daoyun HU, Jin QI, Qianchun LU, Feng LI, Hongqiang FANG. Research and application of traffic engineering algorithm based on deep learning [J]. Telecommunications Science, 2021, 37(2): 107-114. |
| [11] | Jie ZHANG, Lihua YANG, Zenghao WANG, Bo HU, Qian NIE. A novel deep learning based time-varying channel prediction method [J]. Telecommunications Science, 2021, 37(1): 39-47. |
| [12] | Yuanning LI,Baifeng NING,Zhaojie DONG. Patrol image analysis framework and deep learning method for power grid [J]. Telecommunications Science, 2020, 36(8): 167-174. |
| [13] | Tingting ZHANG,Jianwu ZHANG,Chunsheng GUO,Huahua CHEN,Di ZHOU,Yansong WANG,Aihua XU. A survey of image object detection algorithm based on deep learning [J]. Telecommunications Science, 2020, 36(7): 92-106. |
| [14] | Rui GUO,Fanchun RAN. Polar codes decoding algorithm based on convolutional neural network [J]. Telecommunications Science, 2020, 36(6): 119-124. |
| [15] | Shaomin WANG,Zheng WANG,Hua REN. Research on fusion model based on deep learning for text content security enhancement [J]. Telecommunications Science, 2020, 36(5): 25-30. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||